【Pytorch入门】DAY2 数据集的使用,DataLoader使用
1. torchvision中数据集的使用



以CIFAR10为示例
import torchvision
train_set=torchvision.datasets.CIFAR10(root='./dataset',train=True,download=True)
test_set=torchvision.datasets.CIFAR10(root='./dataset',train=False,download=True)
print(test_set[0])
print(test_set.classes)
img,target=test_set[0]
print(img)
print(target)#3 猫
print(test_set.classes[target])#cat
img.show()
# print(test_set[0])
writer=SummaryWriter('p10')
for i in range(10):
img,target=test_set[i]
writer.add_image('test_set',img,i)
writer.close()#读写关闭
查找下载网址
按住ctrl 查看CIFAR10的源代码,可以找到下载的网址

如图所示的链接即为下载网址

2. DataLoader的使用
batch_size() 每次抓几张
shuffle() 打乱 true两次排的顺序不一样,默认false
num_workers() 单进程还是多进程,默认0-主进程【windows下>0,会出现错误,BrokenPipError–设置为0看一下会不会解决问题】
drop_last() 例如共100张牌,每次取三张,最后剩一张,判断除不尽的时候是否舍去。True-舍去,False-不舍去
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#测试数据集
test_data=torchvision.datasets.CIFAR10('./dataset',train=False,transform=torchvision.transforms.ToTensor())
test_loader=DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
#取四个数据集进行打包
#测试数据集中第一张图片及target
img,target=test_data[0]
# print(img.shape)torch.Size([3, 32, 32])
# print(target)3 3通道可以理解为RGB
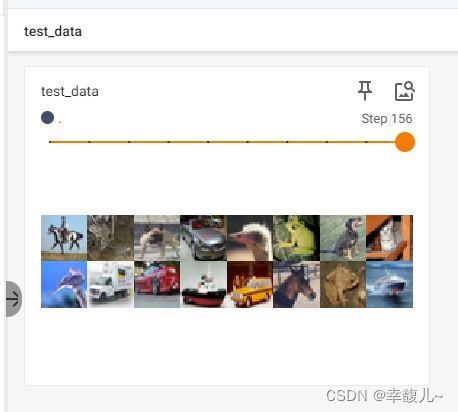
writer =SummaryWriter('dataloader')
step=0
for data in test_loader:
imgs,targets=data
# print(imgs.shape)
# print(targets)
writer.add_images('test_data',imgs,step)
step=step+1
writer.close()

最后一步时,因为不足64张,但是设置了drop_last=False,因此不舍去。
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#测试数据集
test_data=torchvision.datasets.CIFAR10(‘./dataset’,train=False,transform=torchvision.transforms.ToTensor())
test_loader=DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=True)
#取四个数据集进行打包
#测试数据集中第一张图片及target
img,target=test_data[0]
print(img.shape)torch.Size([3, 32, 32])
print(target)3 3通道可以理解为RGB
writer =SummaryWriter(‘dataloader’)
step=0
for data in test_loader:
imgs,targets=data
# print(imgs.shape)
# print(targets)
writer.add_images(‘test_data_drop_last’,imgs,step)#修改drop_last=True时,要注意修改名称
step=step+1
writer.close()
最后不足64张舍去
