大文件分片上传、分片进度以及整体进度、断点续传(一)
大文件分片上传
效果展示
前端
思路
前端的思路:将大文件切分成多个小文件,然后并发给后端。
页面构建
先在页面上写几个组件用来获取文件。
<body>
<input type="file" id="file" />
<button id="uploadButton">点击上传button>
body>
功能函数:生成切片
切分文件的核心函数是 slice,没错,就是这么的神奇啊
我们把切好的 chunk 放到数组里,等待下一步的包装处理
/**
* 默认切片大小 10 MB
*/
const SIZE = 10 * 1024 * 1024;
/**
* 功能:生成切片
*/
function handleCreateChunk(file, size = SIZE) {
const fileChunkList = [];
let cur = 0;
while (cur < file.size) {
fileChunkList.push({
file: file.slice(cur, cur + size),
});
cur += size;
}
return fileChunkList;
}
功能函数:请求逻辑
在这里简单封装一下 XMLHttpRequest
/**
* 功能:封装请求
* @param {*} param0
* @returns
*/
function request({ url, method = 'post', data, header = {}, requestList }) {
return new Promise((resolve, reject) => {
let xhr = new XMLHttpRequest();
xhr.open(method, url);
Object.keys(header).forEach((item) => {
xhr.setRequestHeader(item, header[item]);
});
xhr.onload = function (e) {
resolve({
data: e.target.response,
});
};
xhr.send(data);
});
}
功能函数:上传切片
/**
* 功能: 上传切片
* 包装好 FormData 之后通过 Promise.all() 并发所有切片
*/
async function uploadChunks(hanldleData, fileName) {
const requestList = hanldleData
.map(({ chunk, hash }) => {
const formData = new FormData();
formData.append('chunk', chunk);
formData.append('hash', hash);
formData.append('filename', fileName);
return formData;
})
.map((formData) => {
request({
// url: 'http://localhost:3001/upload',
url: 'upload',
data: formData,
});
});
await Promise.all(requestList);
}
/**
* 功能:触发上传
*/
document.getElementById('uploadButton').onclick = async function () {
// 切片
const file = document.getElementById('file').files[0];
console.log(file);
const fileName = file.name;
const fileChunkList = handleCreateChunk(file);
// 包装
const hanldleData = fileChunkList.map(({ file }, index) => {
return {
chunk: file,
hash: `${fileName}_${index}`,
};
});
await uploadChunks(hanldleData, fileName);
};
可以在请求中看到有很多个请求并发的上传
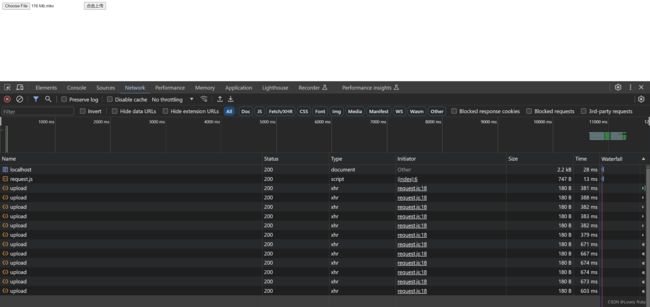
后端
后端的思路是:
- 把 Node 暂存的
chunk文件转移到我想处理的地方(也可以直接处理,看你的)- 创建写入流,把各个
chunk合并,前端会给你每个 chunk 的大小,还有hash值来定位每个chunk的位置
获取 chunk 切片文件
先把上传的接口写好,
const Koa = require('koa');
const Views = require('koa-views');
const Router = require('koa-router');
const Static = require('koa-static');
const { koaBody } = require('koa-body');
const fs = require('fs');
const fse = require('fs-extra');
const app = new Koa();
const router = new Router();
app.use(Views(__dirname));
app.use(Static(__dirname));
app.use(
koaBody({
multipart: true,
formidable: {
maxFields: 1000 * 1024 * 1024,
},
})
);
router.get('/', async (ctx) => {
await ctx.render('index.html');
});
/**
* 功能:上传接口
* - 从 ctx.request.body 中获取 hash 以及 filename
* - 从 ctx.request.files 中拿到分片数据
* - 然后再把 node 帮我们临时存放的 chunk 文件的 filepath 拿到,之后移动到我们想要存放的路径下
* - filepath 和 hash 是一一对应的关系
*/
router.post('/upload', async (ctx) => {
const { hash, filename } = ctx.request.body;
const { filepath } = ctx.request.files?.chunk;
const chunkPath = `${__dirname}/chunkPath/${filename}`;
if (!fse.existsSync(chunkPath)) {
await fse.mkdirs(chunkPath);
}
await fse.move(filepath, `${chunkPath}/${hash}`);
ctx.body = {
code: 1,
};
});
app.use(router.routes());
app.listen(3000, () => {
console.log(`server start: http://localhost:3000`);
});
写完这些就可以拿到 chunk

合并接口
先写一个接口,用来拿到 hash、文件名
/**
* 功能: merge 接口
* - hasMergeChunk 变量是上面用来记录的
* - mergePath 定义一下合并后的文件的路径
*/
router.post('/merge', async (ctx) => {
// console.log(ctx.request.body);
const { fileName, size } = ctx.request.body;
hasMergeChunk = {};
const mergePath = `${__dirname}/merge/${fileName}`;
if (!fse.existsSync(`${__dirname}/merge`)) {
fse.mkdirSync(`${__dirname}/merge`);
}
await mergeChunk(mergePath, fileName, size);
ctx.body = {
data: '成功',
};
});
合并分片的功能函数
然后开始合并
/**
* 功能:合并 Chunk
* - 1. chunkDir: 是 chunks 文件们所在的文件夹的路径
* - 2. chunkPaths: 是个 Array,数组中包含所有的 chunk 的 path
* - 3. 因为 每个 chunk 的 path 命名是通过 hash 组成的,所以我们先排序一下,
* - 算是为 createWriteStream 中的 start 做准备
* - 4. 为每个 chunk 的 path 创建写入流,写到 mergePath 这个路径下。因为已经
* - 排序了,所以 start 就是每个文件的 index * eachChunkSize
* @param {*} mergePath
* @param {*} name
* @param {*} eachChunkSize
*/
async function mergeChunk(mergePath, name, eachChunkSize) {
const chunkDir = `${__dirname}/chunkPath/${name}`;
const chunkPaths = await fse.readdir(chunkDir);
chunkPaths.sort((a, b) => a.split('_')[1] - b.split('_')[1]);
await Promise.all(
chunkPaths.map((chunk, index) => {
const eachChunkPath = `${chunkDir}/${chunk}`;
const writeStream = fse.createWriteStream(mergePath, {
start: index * eachChunkSize,
});
return pipeStream(eachChunkPath, writeStream);
})
);
console.log('合并完成');
fse.rmdirSync(chunkDir);
console.log(`删除 ${chunkDir} 文件夹`);
}
接着就是写入流
/**
* 功能:创建 pipe 写文件流
* - 1. [首先了解一下什么是输入输出流](https://www.jmjc.tech/less/111)
* - 2. hasMergeChunk 变量用于记录一下那些已经合并完成了,也可以写成数组,都行。
* - 3. 可以检测输出流的 end 事件,表示我这个 chunk 已经流完了,然后写一下善后逻辑。
* @param {*} path
* @param {*} writeStream
* @returns
*/
let hasMergeChunk = {};
function pipeStream(path, writeStream) {
return new Promise((resolve) => {
const readStream = fse.createReadStream(path); // 输出流
readStream.pipe(writeStream); // 输出通过管道流向输入
readStream.on('end', () => {
hasMergeChunk[path] = 'finish';
fse.unlinkSync(path); // 删除此文件
resolve();
console.log(`合并 No.${path.split('_')[1]}, 已经合并${Object.keys(hasMergeChunk).length}`);
});
});
}
至此一个基本的逻辑上传就做好了!
Q & A
发送片段之后的合并可能出现错误
这个情况分析了一下是前端的锅啊,前端的 await Promise.all() 并不能保证后端的文件流都写完了。
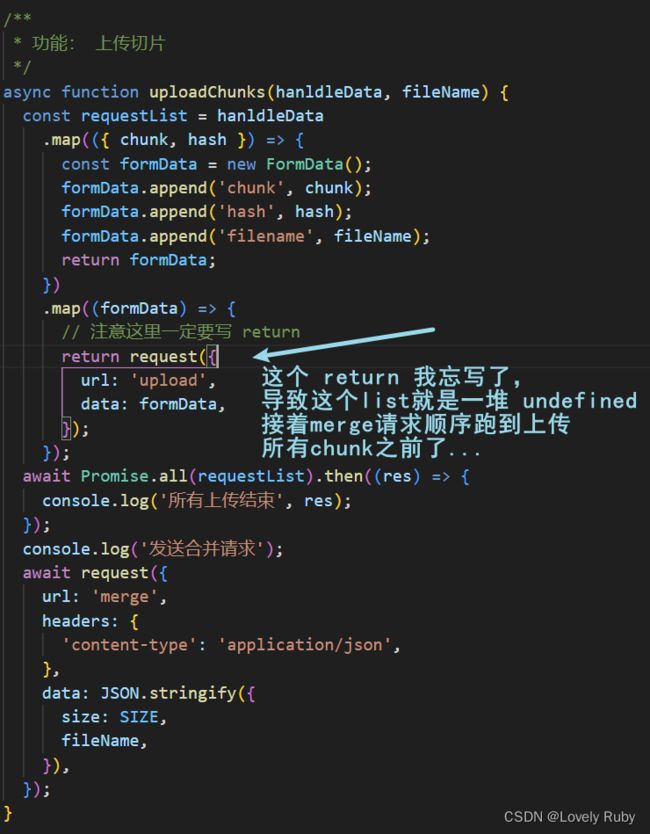
完整代码
前端
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<script src="request.js"></script>
</head>
<body>
<input type="file" id="file" />
<button id="uploadButton">点击上传</button>
<button id="mergeButton">点击合并</button>
</body>
<script>
/**
* 默认切片大小 10 MB
*/
const SIZE = 10 * 1024 * 1024;
/**
* 功能:生成切片
*/
function handleCreateChunk(file, size = SIZE) {
const fileChunkList = [];
let cur = 0;
while (cur < file.size) {
fileChunkList.push({
file: file.slice(cur, cur + size),
});
cur += size;
}
return fileChunkList;
}
/**
* 功能: 上传切片
* - 注意 map 里别忘了写 return
*/
async function uploadChunks(hanldleData, fileName) {
const requestList = hanldleData
.map(({ chunk, hash }) => {
const formData = new FormData();
formData.append('chunk', chunk);
formData.append('hash', hash);
formData.append('filename', fileName);
return formData;
})
.map((formData) => {
return request({
url: 'upload',
data: formData,
});
});
await Promise.all(requestList).then((res) => {
console.log('所有上传结束', res);
});
console.log('发送合并请求');
await request({
url: 'merge',
headers: {
'content-type': 'application/json',
},
data: JSON.stringify({
size: SIZE,
fileName,
}),
});
}
document.getElementById('uploadButton').onclick = async function () {
// 切片
const file = document.getElementById('file').files[0];
const fileName = file.name;
const fileChunkList = handleCreateChunk(file);
// 包装
const hanldleData = fileChunkList.map(({ file }, index) => {
return {
chunk: file,
hash: `${fileName}_${index}`,
};
});
await uploadChunks(hanldleData, fileName);
};
// document.getElementById('mergeButton').onclick = async function () {
// await request({
// url: 'merge',
// headers: {
// 'content-type': 'application/json',
// },
// data: JSON.stringify({
// size: SIZE,
// fileName: '116 Mb.mkv',
// }),
// });
// };
</script>
</html>
后端
const Koa = require('koa');
const Views = require('koa-views');
const Router = require('koa-router');
const Static = require('koa-static');
const { koaBody } = require('koa-body');
const fse = require('fs-extra');
const app = new Koa();
const router = new Router();
app.use(Views(__dirname));
app.use(Static(__dirname));
app.use(
koaBody({
multipart: true,
formidable: {
maxFields: 1000 * 1024 * 1024,
},
})
);
router.get('/', async (ctx) => {
await ctx.render('index.html');
});
/**
* 功能:上传接口
* - 从 ctx.request.body 中获取 hash 以及 filename
* - 从 ctx.request.files 中拿到分片数据
* - 然后再把 node 帮我们临时存放的 chunk 文件的 filepath 拿到,之后移动到我们想要存放的路径下
* - filepath 和 hash 是一一对应的关系
*/
router.post('/upload', async (ctx) => {
const { hash, filename } = ctx.request.body;
const { filepath } = ctx.request.files?.chunk;
const chunkPath = `${__dirname}/chunkPath/${filename}`;
if (!fse.existsSync(chunkPath)) {
await fse.mkdirs(chunkPath);
}
await fse.move(filepath, `${chunkPath}/${hash}`);
ctx.body = {
code: 1,
};
});
/**
* 功能:创建 pipe 写文件流
* - 1. [首先了解一下什么是输入输出流](https://www.jmjc.tech/less/111)
* - 2. hasMergeChunk 变量用于记录一下那些已经合并完成了,也可以写成数组,都行。
* - 3. 可以检测输出流的 end 事件,表示我这个 chunk 已经流完了,然后写一下善后逻辑。
* @param {*} path
* @param {*} writeStream
* @returns
*/
let hasMergeChunk = {};
function pipeStream(path, writeStream) {
return new Promise((resolve) => {
const readStream = fse.createReadStream(path); // 输出流
readStream.pipe(writeStream); // 输出通过管道流向输入
readStream.on('end', () => {
hasMergeChunk[path] = 'finish';
fse.unlinkSync(path); // 删除此文件
resolve();
console.log(`合并 No.${path.split('_')[1]}, 已经合并${Object.keys(hasMergeChunk).length}`);
});
});
}
/**
* 功能:合并 Chunk
* - 1. chunkDir: 是 chunks 文件们所在的文件夹的路径
* - 2. chunkPaths: 是个 Array,数组中包含所有的 chunk 的 path
* - 3. 因为 每个 chunk 的 path 命名是通过 hash 组成的,所以我们先排序一下,
* - 算是为 createWriteStream 中的 start 做准备
* - 4. 为每个 chunk 的 path 创建写入流,写到 mergePath 这个路径下。因为已经
* - 排序了,所以 start 就是每个文件的 index * eachChunkSize
* - 5. 每个写入流都用 Promise 包装了一下,然后用 await Promise.all() 等待处理完
* @param {*} mergePath
* @param {*} name
* @param {*} eachChunkSize
*/
async function mergeChunk(mergePath, name, eachChunkSize) {
const chunkDir = `${__dirname}/chunkPath/${name}`;
const chunkPaths = await fse.readdir(chunkDir);
chunkPaths.sort((a, b) => a.split('_')[1] - b.split('_')[1]);
await Promise.all(
chunkPaths.map((chunk, index) => {
const eachChunkPath = `${chunkDir}/${chunk}`;
// 创建输入流,并为每个 chunk 定好位置
const writeStream = fse.createWriteStream(mergePath, {
start: index * eachChunkSize,
});
return pipeStream(eachChunkPath, writeStream);
})
);
console.log('合并完成');
fse.rmdirSync(chunkDir);
console.log(`删除 ${chunkDir} 文件夹`);
}
/**
* 功能: merge 接口
* - hasMergeChunk 变量是上面用来记录的
* - mergePath 定义一下合并后的文件的路径
*/
router.post('/merge', async (ctx) => {
// console.log(ctx.request.body);
const { fileName, size } = ctx.request.body;
hasMergeChunk = {};
const mergePath = `${__dirname}/merge/${fileName}`;
if (!fse.existsSync(`${__dirname}/merge`)) {
fse.mkdirSync(`${__dirname}/merge`);
}
await mergeChunk(mergePath, fileName, size);
ctx.body = {
data: '成功',
};
});
app.use(router.routes());
app.listen(3000, () => {
console.log(`server start: http://localhost:3000`);
});
request.js 的封装
/**
* 功能:封装请求
* @param {*} param0
* @returns
*/
function request({ url, method = 'post', data, headers = {}, requestList }) {
return new Promise((resolve, reject) => {
let xhr = new XMLHttpRequest();
xhr.open(method, url);
Object.keys(headers).forEach((item) => {
xhr.setRequestHeader(item, headers[item]);
});
xhr.onloadend = function (e) {
resolve({
data: e.target.response,
});
};
xhr.send(data);
});
}