垃圾回收器
垃圾回收器
问题:为什么分代GC算法要把堆分成年轻代和老年代
系统中有部分对象被创建使用后很快就不再使用了,比如订单数据,返回给用户后就不怎么使用了
老年代中会存放长期存活的对象,比如Spring中的bean对象,在程序启动后就不会被回收了
JVM默认设置中,年轻代的大小要远小于老年代的大小
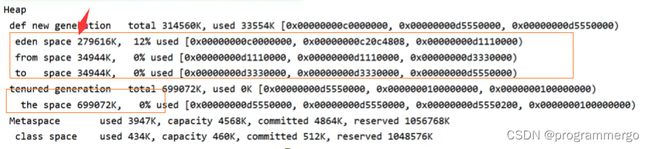
这张图可以看出新生代占堆内存30%左右,而老年代是70%
另外可以通过调整二者比例以提高程序性能
例如订单系统中,如果有大量数据,当新生代较小时就会发生minor gc,这样会加重老年代负担
而订单系统大多是一些用完即扔的数据,没必要放入老年代
所以我们应该尽可能增大新生代比例,多的时候就Minor gc,不用进入老年代了
同时,分代设计下我们可以只进行minor gc,不用对整个堆进行,这样STW就会减少(核心思想,more minor gc, no full gc)
年轻代-Serial垃圾回收器

目前Java程序多跑在服务器端,所以这款回收器使用场景有限
老年代-SerialOld回收器

cpu资源匮乏时推荐使用
==
年轻代-ParNew回收器
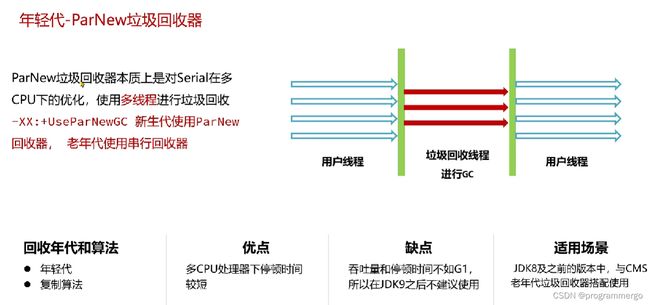
依旧,在gc时用户线程停下
老年代-CMS垃圾回收器

某些情况下会退化成SerialOld串行回收器
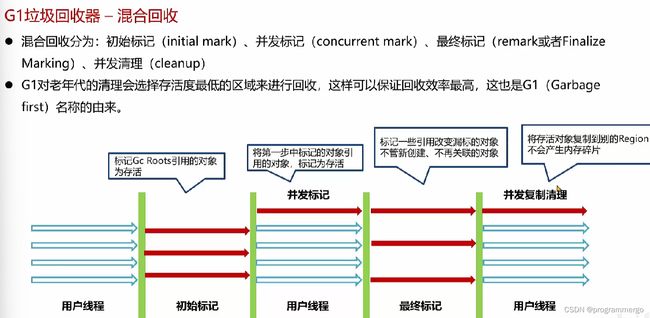
CMS执行步骤(imp)
- 初始标记,stw,用较短时间标记出 GC Roots 能直接关联到的对象
- 并发表及,标记所有的对象,标记出哪些对象需要回收,哪些对象不需要回收,用户线程不需要暂停
- 重新标记,stw,由于并发标记阶段有些对象会发生变化,存在错标漏标等情况,重新标记之
- 并发清理,清理需要被回收的对象

无法处理在并发清理过程中产生的"浮动垃圾",不能做到完全的垃圾回收
如果老年代内存不足无法分配对象,CMS会退化成Serial Old单线程回收老年代
jdk14废弃了cms,推荐使用G1
年轻代-Parallel Scavenage垃圾回收器(PS)

老年代-Parallel Old垃圾回收器

==

这个组合比较关注吞吐量
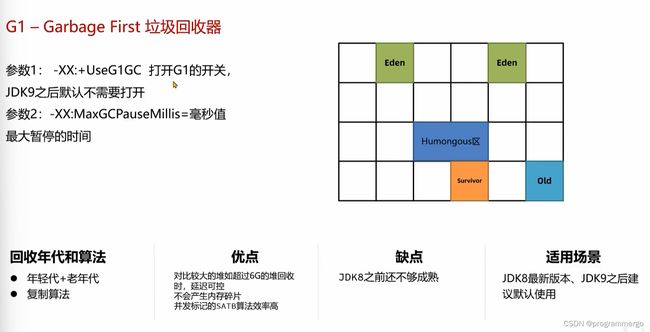
G1垃圾回收器(JDK9之后默认)

G1的整个堆会被划分成多个大小相等的区域Region,区域不要求是连续的
Eden,Survivor,Old
Region的大小通过对空间大小/2048计算得到,也可以通过参数-XX:G1heapRegionSize-32m指定(其中32m指定region大小为32M),Region Size必须是2的指数幂.取值范围从1M到32M(2的幂次方)
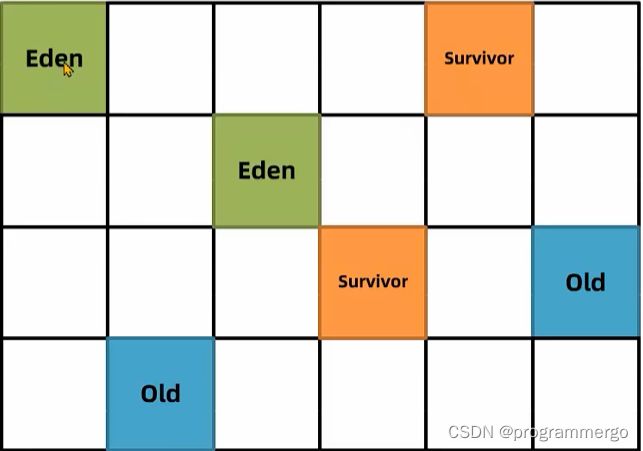
G1中垃圾回收有两种方式
- 年轻代回收(Young GC)
- 混合回收(Mixed GC)
G1Young GC
- Young GC回收Eden区和Survivor区中不用的对象 会产生STW
- G1中可以通过参数-XX:MaxGCPauseMillis=n(默认200)设置每次垃圾回收时的最大暂停时间的毫秒数,G1垃圾回收器会尽可能保证这个值
执行流程:
新创建的对象会存放在Eden区 当G1判断年轻代区不走(max默认60%%),无法分配对象时需要回收时会执行YoungGC
标记出Eden和Survivor区域中存活对象
根据配置的最大暂停时间选择某些区域将存活对象复制到一个新的Survivor区中(年龄+1),清空这些区域
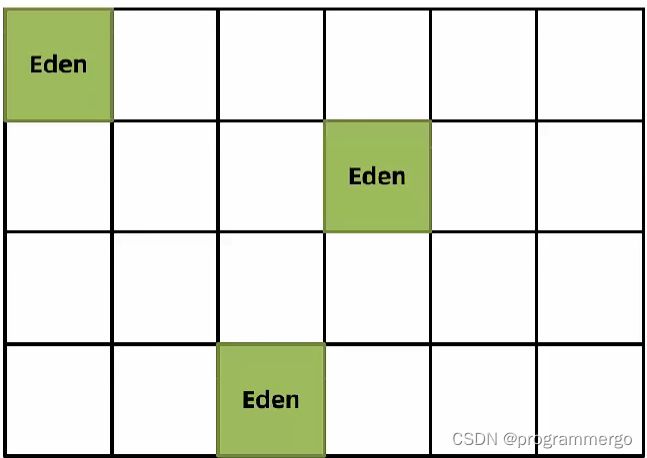
->
->
后续Young GC时与之前相同,只不过Survivor区中存活对象会被搬到另一个Survivor区
当某个存活对象的年龄达到阈值(default 15),将被放入老年代
部分对象如果大小超过Region的一半,会直接放入老年代称为Humongous区
比如堆内存4G,每个Region是2M,只要一个大对象超过了1M就被放入Humongous区,如果对象过大会横跨多个Region
如何保证设置的max:

G1混合回收
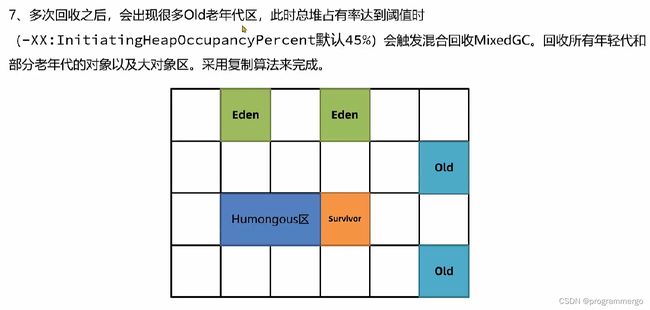
执行流程:
==

==
==

==

==
年轻代回收

==
并发标记过程

最终标记
![]()
清理阶段

垃圾回收器的选择
