进程的创建:fork()
引入
创建进程的方式我们已经学习了一个!在我们运行指令(或者运行我们自己写的可执行程序)的时候不就是创建了一个进程嘛?那个创建进程的方式称为指令级别的创建子进程!
那如果我们想要在代码中创建进程该怎么办呢?
fork()
fork 函数的使用,见见猪跑
这是一个系统调用函数,我们可以使用 man 指令来查看函数的说明文档!


介绍:这个函数可以为调用这个函数的进程创建一个进程,我们把这个新创建出来的进程叫做子进程,调用这个函数的进程称为父进程!
返回值:如果成功创建子进程,子进程的PID将被返回给父进程,0 将被返回给子进程;如果创建子进程失败,-1 将返回给父进程,错误码将被设置!
好的,我们不管这么多,先来用一用!
#include在上面的代码中,我们创建了一个子进程,让子进程循环打印自己的 pid 和 ppid,让父进程循环打印自己的 pid 我们来验证一下通过 fork 函数创建出来的进程到底是不是调用该函数进程的子进程。
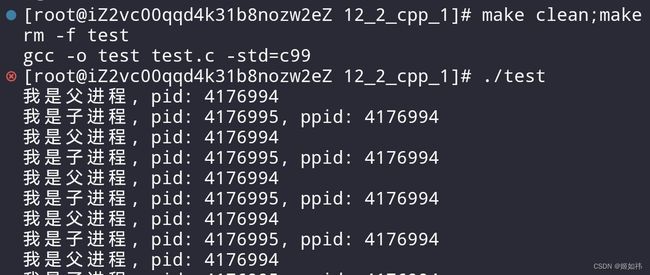
我们看到子进程的
ppid是 4176994,父进程的pid是4176994。说明我们的结论没有问题呢!
看到这里,你可能会有很多问题~不着急我们一个一个来解决!
问题一:
为什么
fork要给子进程返回 0,给父进程返回子进程的pid?
你想啊!一个进程只能调用一次 fork 函数嘛?显然不是的!我循环调用 fork 一百次,那么父进程应该如何区分这么多的子进程呢?那还不得靠返回值啦!
因此,fork 函数返回不同的值就是为了让父进程能够区分自己创建的子进程,从而让不同的执行流执行不同的代码!
问题二:
fork函数究竟在干什么?干了什么?
我们在进程的概念部分知道了:进程 = PCB (进程控制块, Linux 环境下叫 task_struct) + 代码和数据。这也就意味着,task_struct 中必然维护着指针信息,能够通过 task_struct 找到进程的代码和数据!因为 linux 操作系统对进程的管理,本质上是对 task_struct 的管理。CPU 要执行进程的代码必须能通过 task_struct 找到进程的代码和数据!
在 fork 创建子进程的时候,操作系统首先为子进程创建 task_struct 结构体,并初始化结构体中的属性~但是,在初始化指向子进程代码和数据的指针的时候,应该怎么办呢?因为子进程并没有自己的代码和数据哇!那操作系统就说啦,子进程不是父进程创建的嘛,就让这个指针指向父进程的代码和数据吧!
于是,我们得出了一个重要的结论:fork 之后,父子进程的代码共享。
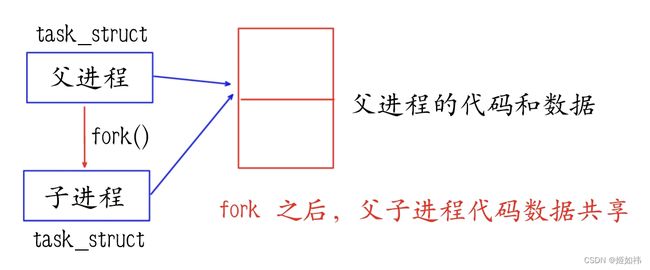
父进程为什么要创建子进程,不就是想让子进程来帮忙的嘛!因此,为了让父子进程执行不同的代码,就需要通过 fork 不同的返回值来实现!
问题三:
一个变量怎么会有不同的内容?如何理解?
在任何操作系统中,进程在运行的时候具有独立性!
其实根据常识也能证明:你的电脑上同时运行着 QQ 和 微型这两个进程!突然 QQ 这个进程挂掉了!QQ 挂掉了会影响微信这个进程的运行嘛?显然是不会的!

在来看这张图,我们说 fork 之后,父子进程的代码和数据是共享的,我们又说进程之间是互相独立的!假设我们的子进程想要修改父进程中的数据怎么办呢?这种操作会被允许嘛?
我们先来写一个代码看看结论!
#include在上面的代码中我们定义了一个全局变量 g_val 在父子进程中每隔一秒打印 g_val 的值。在子进程中 3 秒之后将 g_val 修改了,我们观察父子进程打印 g_val 的结果有什么变化!

我们看到在子进程中,g_val 变成了 200,父进程中 g_val 还是 100。这是为什么呢?我们知道进程之间是具有独立性的!因为数据可能会被修改,这就注定了父子进程之间的数据是不能共享的!
那怎么办呢?在创建子进程的时候将父进程的数据拷贝一份给子进程?这样做的确没有任何问题!但是如果子进程都不对父进程的数据做修改,这不就白白给子进程拷贝了一份数据嘛!造成内存负担
于是操作系统说:当子进程要修改父进程的数据时,我再给你子进程拷贝数据吧!这个行为被称为:父子进程数据层面的写时拷贝。当操作系统检测到子进程要修改父进程的数据时,会为子进程重新分配一块内存空间!
因为代码不可能被修改,父子进程代码共享并不影响进程之间的独立性!
问题四:
一个函数是如何做到返回两次的?怎么理解?
首先,fork 是一个函数,在这个函数中负责为调用他的进程创建子进程,这个函数体的实现一定包含但不限于以下操作:
- 创建子进程的
task_struct。 - 填充
task_struct的内容。 - 父子进程指向相同的代码。
- 修改子进程的状态。等等
当 fork 这个函数执行到 return 语句的时候,此时子进程一定已经被创建出来了!并且父子进程指向了相同的代码!而 return 本身也是代码哇!我们的代码:pid_t id = fork(),return 的本质不就是在向 id 这个变量中写入吗 (return 返回时,先把返回值写到 cpu 中的寄存器中,最后再把寄存器中的值拷贝到你接收到的变量中!)?子进程此时要修改 id 中的内容,是不是就得发生写时拷贝!因此,同一个 id 变量会有两个不同的值。
问题五:
如果父子进程被创建好,谁先运行?
答案是:不清楚,谁先运行由调度器决定!
问题六:
同一个变量名存储不同的数据,如何做到?
这个问题仙子阿没打讲解,我们等到学习进程地址空间的时候再说吧!