Linux - 进程间通信
进程通信
初步理解进程通信
所谓进程之间的通信,就是两个进程之间的 数据层面的交互。
我们之前说过,父子进程之间是有一些数据通信的,子进程可以看到一些父进程 允许 子进程访问的数据,比如 父进程的 环境变量,子进程可以直接继承;
但是,子进程只能访问数据,一旦父进程,或者是子进程对这个数据进行了修改,那么都会发生写时拷贝。
所以,上述只是特殊情况,进程和进程之间是具有独立性的,一个进程的运行,如果是不是 在 运行逻辑上,依赖于某一个进程的话,那么,进程和进程之间是独立运行的。一个进程挂掉,是不影响其他进程的 运行的。
所以,进程的独立性,对于进程运行之间的耦合性有了显著的降低,但是,对于进程间通信来说,就有点麻烦了。
这也不能怪进程的设计上有缺陷,我们发现,进程的独立性所带来的好处是非常多的,而进程的设计理念就是为了实现 不同 代码的 独立执行。
因为有进程独立性的存在,导致进程通信的成本增加了。
对于一个进程对另一个进程发送出的数据,有很多种,如在述举例:
- 基本数据:比如 字符串,整形数据,报文······
- 指令/命令数据:可以发送命令性数据,实现对另一个进行的控制,实现控制另一个进程的,比如进程的创建,终止,等待,替换····
- 协同数据:一个进程想用另一个进程去帮助这个进程 去做一些任务,当另一个进程不做任务的时候,让这个进程等待,或者是停止下来等等的这些操作。
- 通知数据:子进程 死亡之前,要变成僵尸进程,等待父进程 回收数据;也会说,A 进程 可以告诉 B 进程 发生什么事情···· 等等这些。
- ······················
通过上述对于 进程之间具有独立性的简单描述,就可以知道,进程之间通信是有成本的!!
这个成本就体现在,他要在不破坏进程之间的独立性的前提之下,实现进程之间的数据的交互。
而,进程通信的本质就是 -- 必须要让不同进程之间,看到同一份“资源”。(这个资源可以理解为 特定形式的一种内存空间)
那么这块 “资源” 由谁去提供呢?答案就是操作系统了。
操作系统在内存当中开辟一块新的空间,这块空间就是这两个 进程共用的 “资源”。如果进程 A 想给 进程 B 发送数据,那么 只需要往这个 由 操作系统新开辟的空间当中写入要传递的数据,进程 B 直接去读取就可以了。
但是,操作系统为什么要想上述一样做呢?
如果是进程 A 想给 进程 B 发送数据 的话,进程A 直接共享 在自己的 进程地址空间当中映射的 物理存储位置 不就可以了吗?
上述的 进程 直接共享自己空间当中存储的 数据 给 其他进程,这种方式是不可行的,因为这种方式 破坏了进程之间的独立性。
想想,如果进程直接把自己空间当中的数据直接共享出去,不就相当于是直接把自己家的地址直接共享了吗?
我们想的是,其他进程不知道我当前共享数据的进程存储数据的位置,不想被人知道在进程自己 “家” 当中存储的数据。
共享数据的进程,指向把数据直接放到 每一个 共享的位置处,由需要的进程自己接收。
所以,一个进程向另一个进程访问数据的操作,就转变为了 一个进程向操作系统访问数据的过程了。本质上就是访问 操作系统。
那么,操作系统不能直接让进程访问到 其中的内存,万一这个进程是病毒木马,或者当前用户对进程的操作有误····· 等等这些都是可能会对 操作系统,甚至是计算机造成不好的影响的。
所以,进程(这里进程其实就是代表的是用户了)要想访问到操作系统,就得使用 操作系统提供的 各种 -- 系统调用接口。
而,当前在 系统当中运行的 进程肯定是不止一个的,那么,进程之间的通信,就变得很复杂了,在同一时间段内,可能有有多个进程都想要通信。
所以,操作系统为了满足当前进程之间的需求,就要在内存当中开辟很多个大小不一的 空间(“资源”),供多个进程之间通信的使用。
那么操作系统为了能更好的管理好这些个“资源”,就会使用 --- 先描述,再组织。这个方法。
也就是把管理一个“资源”所要用到的 各种属性,用一个 结构体对象来存储,多个“资源”,肯定是对应了很多个 结构体对象;此时,用某种数据结构,把这些 结构体对象 链接起来。操作系统只需要管理好这个 数据结构,就可以管理好 所有的 结构体对象;管理好所有的结构体对象,就可以管理好 所有的 “资源”。
一般操作系统,会有一个独立的通信模块(IPC 通信模块),这个模块其实是隶属于 文件系统的。
操作系统 从底层实现,到用户层 ,其实是 由很多人去写的,也就是说由很多人来写进程之间的通信这一模块的内容,所以就衍生出了很多的版本,不同发行的版本之间 标准。
出现了各种的解决方案的话,我们需要从中选出 效率高,使用方便的一种方案,或者是几个方案。所以,就要定制标准,大家都按照 这个标准来实现,那么大家虽然在一些细节上的实现不太一样的,但是大体上还是按照一个标准来实现的。
所以,进程间通信是有标准的。
我们可以想想,每个人都是可以使用不同厂家生产出来的,不同硬件设备,不同软件设计 的 设备,但是,尽管有很大的差异,每个人都可以使用的不同的设备,和不同设备的人进行通信;
也就是不同的设备之间,尽管有在硬件 和 软件的设计之上,有很大不同,但是都是可以进行继承之间的通信的。为什么呢?
因为,不管是哪一个行业,总是会有一群“佼佼者” ,走在这个行业的最前端,他们就可以制定出规则,供我们进行适配使用。
如果没有这些标准,设备和设备之间就很难进行通信,也就没有今天这种互联网局势。
在进程通信当中就有两个标准: system V && posix
管道
一个文件是可以被进程所打开的,那么,一个文件能不能被多个进程打开并访问呢?
如果一个文件可以被多个进程打开并访问,那么这个文件不就相当于是一个 公共资源 了吗?
一个进程从文件当中写数据,另一个进程从该文件当中读取数据,只要保证往文件当中写数据的 进程 他写完数据,马上刷新缓冲区当中的数据到 磁盘上,另一个进程就可以访问到这个数据。
但是,虽然上述的这种方式是可以实现的,但是,基于文件的来实现的通信有一个致命的问题 --- “公共资源” 在外设上。
也就是说,需要把数据写到外设上,那么,从把数据写到外设上 -- 到把数据从外设上读取到内存当中,用于进程的接收。
在这个过程当中一定会伴随着一个 数据读取的 效率问题。
比如:外设当中的存储效率根本比不上 内存当中的存储效率,也就是说,其实,在缓冲区出来之前,其实内存是要放慢速度等待 外存写入数据的。·······
所谓 “管道” 呢,其实就是一种基于文件的一种通信方式。
它的思想其实和上述所说的文件 作为 “共享资源” 的思想差不多,只不过,他不把数据刷新到 磁盘上,管道通信 只需要建立好 双方的通信信道,进程往其中写入数据,另一个进程进行读取即可,不需要使用到磁盘,用内存也是可以的。
什么是管道?
管道 是 Unix 中最古老的进程间通信的形式。因为 Linux 本身就是一种 类UNIX 操作系统。所以,UNIX 支持 管道,Linux 也支持管道。
关于管道的简单定义:我们把一个进程 把数据 写到 另一个进程的 数据流 称之为 -- 管道。
而管道呢,其实在 Linux 当中的命令当中页使用到了:![]()
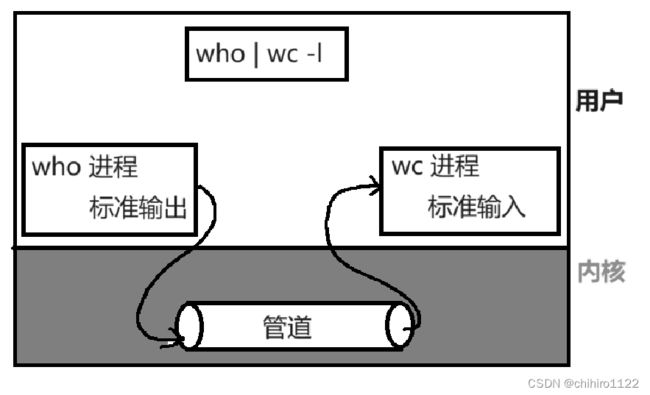
who | wc -l 输出:

因为指令其实就是一个一个的可执行程序,像上述例子,就是 who 这个进程先加载,然后把 who 进程的输出结果,保存到管道当中,此时 wc 可执行程序在变成进程,最后把 who 和 wc 两个进程的执行的结果 结合在一起。
所以,管道其实就是在上述的过程当中,在内存当中模拟实现的一个过程,在磁盘当中,我们是按照一个 文件的方式来进行存储的,一个文件,由自己的文件属性(inode),由操作底层硬件的方法集,还有在内存当中存储的缓冲区。
那么,有人就想,既然在磁盘上,对于此磁盘的操作在效率上不讨好,那么在 内存当中,我们其实也可以 利用在磁盘当中对于文件的管理方式来 在内存当中划分出一块区域,使用管理文件的方式来管理这个块区域。
使用文件的方式来管理内存当中的某一块区域,管理的这一块区域,我们就称之为 --- 内存级文件。
所以,因为 内存级文件,虽然本质上是文件,虽然用户可以看到,但是实际上是在内存当中存储数据的。
所以,在磁盘当中,我们需要有一个 在内存上存储的一个 缓冲区,用于 内存和 磁盘上的交互,但是,对于内存级文件就不存在了。因为 内存级文件的存储区域就是在内存上的。
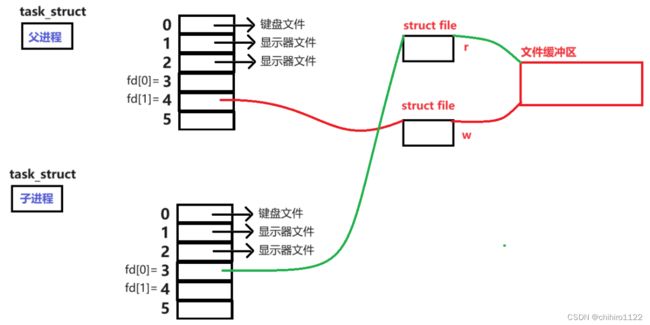
对于父子进程,子进程会继承父进程当中的 file_struct 结构体对象,这个结构体对象当中存储了 当前进程 所打开的 所有文件的 文件对象 的数组(struct file *fd_array[])。这个数组的下标就是 文件的对应的 fd 文件描述符。
对于 file_struct 结构体,相当于是,子进程会直接拷贝一份一模一样的 file_struct 供自己使用。
但是对于 struct_file 这个文件的文件对象,子进程是不会拷贝的。这也好理解,文件是可以被多个进程访问,一个 文件对象就已经够 操作系统管理 这些个文件了。
所以,对于 文件对象,还有缓冲区这些属于文件的 “内容” ,子进程 创建,这些 属于文件的 “内容” 是不会拷贝的,自始至终都只会是一个。
所以,其实,子进程和父进程之间看到,访问到,修改到的都是同一些文件。
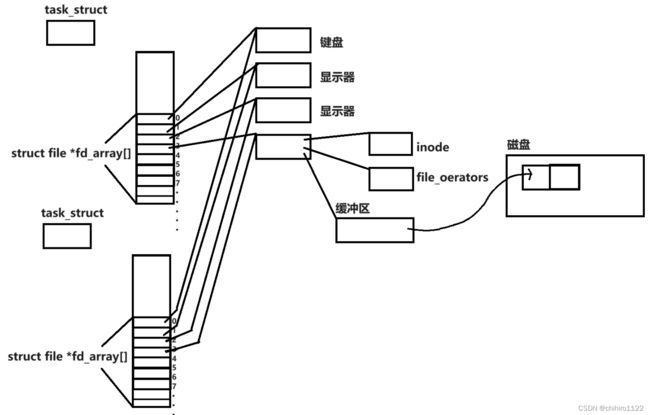
也就是说,只要子进程,或者父进程,自己不 打开 / 关闭 文件,那么两者之前访问的文件都是一样的,甚至连 文件的 fd 文件描述符都是一样的。
而,上述说过了,进程通信的本质就是 要让 两个进程可以访问同一块 “资源” ,像上述,fd 为 3 的文件,就是父子进程 所共同访问的 文件资源了。所以,其实管道就是文件。
但是,你可以发现一个问题,如果在父进程当中,打开上述的共享文件 的方式是只写的,那么子进程也应该继承的是只写的;如果是只读的,那么子进程也应该是只读的。
我们进程之间的通信的话,是一个读 一个写的,这个不就矛盾了吗?
确实矛盾了,此时就有人想,那么把父进程打开这个共享文件的方式改为 以读写的方式打开的不就可以了吗?
虽然,此时子进程继承的 打开方式也是读写了的,但是 管道在设计之初,并没有把打开的方式设计为 可读可写的。
所以,父进程在打开这个共享文件,就不能想上述一样,按照只读的方式或者是按照 只写的方式打开了。
我们接下来看 管道的原理:
管道的原理
所以,管道不给我们以 可读可写的方式打开的话,那么我们 分别以 读的方式 和 写的方式,两次打开同一个文件不就可以了吗?
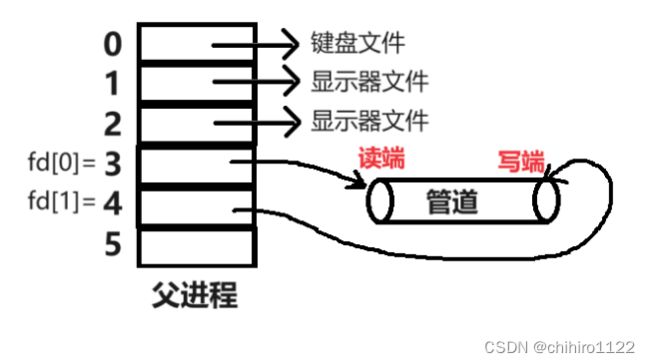
此时创建子进程的话,也是和父进程一样,由两种方式打开同一个文件:

然后,对于通信的发送方 假定是 父进程,接收方是 子进程的话,那么父子进程,只需要保留自己需要的 打开访问的方式的 fd 文件描述符即可,另一个就可以关闭了。比如父进程是发送方,那么只需要保留 以 写的方式 打开的文件的 fd;另一个 以 读的方式打开的文件的 fd 就可以关闭了:
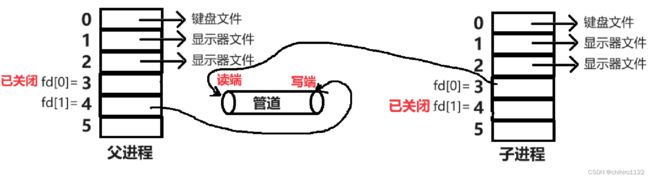
这时,在父子进程之间,就建立了一种 单向的通信信道。
为什么管道不支持 以 可读可写的方式打开文件呢?
我们拿 这个例子距离:
假设现在,我们拿 struct file* fd_array[] 数组当中的两个 fd 文件描述符 指向同一个 以 "r" 的方式打开的文件的 文件对象的话。
因为,一个文件对象 struct file(操作系统用来管理文件的,存储文件属性的结构体对象)当中,由变量存储的是 访问文件的字符串指针,这个指针指向当前 文件对象 访问文件当中的那一个位置。
那么, 如果是 两个 fd 文件描述符 指向同一个 以 "r" 的方式打开的文件的 文件对象的话,就会发生冲突,上一个 fd 访问到某一个位置,那么另一个fd 在访问之时,就是从上一次访问的位置开始访问,而可能不是从开始位置访问。
所以,像上述,父进程当中用两种方式,分别 打开同一个文件,创建两个 fd 的操作,相当于是,此时有两个 文件对象 当中 指向缓冲区的指针 指向 指向同一个缓冲区。一个是 以 只读的方式打卡的;一个是以 只写的方式打开的。
所以,两个文件对象,虽然访问的是同一个 缓冲区,但是,在缓冲区当中访问字符串的指针指向是不一样的。
而,父子进程之间,在设计两者之间的 通信的时候,就是要让 两者之间实现单向通信。为什么呢?
因为 ,为了简单,单向通信就够用了;不需要再设计双向通信了。
同样的,操作系统在实现进程之间通信,就是为了简单,所以直接使用文件系统来进行复用。而不是像之前的 进程管理,文件系统一样,再设计一套 宏大的 结构体,数据结构来进行管理。
所以,像上述这种,单向通信,由一个入口和一个出口,这种我们就把他称之为 --- 管道。
如果要建立双向通信的话,其实就是多一个 反向的 管道。
所以,上面大篇文章当中都说的是 父子进程之间的通信。
如果两个进程之间没有任何关系的话,以上述的通信原理,两个进程之间可不可进行通信呢?
一般是不可以的。如果两个进程之间没有关系,一般是不能 以上述的通信原理 进行通信的。 (我们在下篇博客当中会说到匿名管道,但是这种管道使用比较特殊)
要使用上述的方式去通信的话,进程之间必须是父子关系。
而,可能父进程创建的 子进程不止一个。子进程之间,也就是兄弟进程之间,也是可以进行通信的。
而且,如果 子进程 也创建了 它的 子进程,那么,子进程的子进程 和 父进程之间,也就是 爷爷 和 孙子 进程 之间也是可以进行通信的。
结论:进程间的通信,只能用于 由 血缘关系的进程之间的通信,只不过常用与 父子进程的通信。
通信的系统调用接口
我们在C 语言当中的打开文件是使用 open()函数打开 一个文件的,但是使用 open()函数打开一个文件,这个文件是 磁盘文件,因为在open()函数当中,是需要带上文件的 路径的。
所以,如果想要打开 内存文件 的话,需要 pipe()这个函数实现。
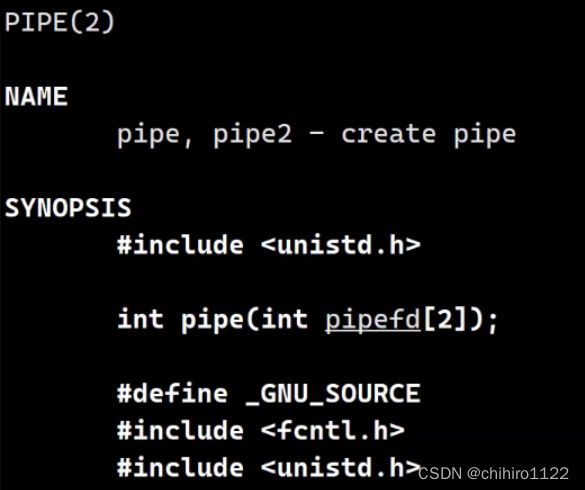
这个 pipe() 函数 的意思就是 : 创建一个 管道。
返回值:
- 如果创建成功,返回0;
- 如果创建失败,返回-1,同时 errno(错误码被设置)
参数:(pipefd[2])
其实,在 C 语言传参当中,数组的传参可以是 arr[] 的方式,在 "[]" 当中,是不需要带上数字的,因为带上编译也会直接忽略掉。此时带上这个 2 就是像提醒你,传入的数组只需要两个元素。
这个 参数是说一个数组,这个数组有两个元素,而且,这个参数是一个输出性参数。
这个输出型参数当中存储的数据就是,我们上述所说的 fd[0] 和 fd[1] ;也就是 一个用于 发送方发送数据 所用到的 fd 文件描述符;另一个是 接收方 接受数据所使用的 fd 文件描述符。
在 pipefd 数组当中 :
- pipefd[0] :读下标;
- pipefd[0] :写下标;
凡是在 0 号下标位置的 fd 对应的文件就是 接收方使用的文件;1 号下标位置的fd 对应的文件就是 发送方使用的文件。
#include
#include
using namespace std;
int main()
{
int pipefd[2] = {0};
int n = pipe(pipefd);
if(n < 0) return 1; // 出错,返回1
cout << "pipefd[0] : " << pipefd[0] << "\npipefd[1] : " << pipefd[1] << endl;
return 0;
} 输出:

模拟父子进程间通信
此时,上述其实就是已经为什么创建好了内存文件了,然后我们来模拟一些 父子之间的 通信:
我们可以使用 sprintf()和 snprintf()函数,printf()函数format 参数就是格式化输出的字符串参数,就会往显示器文件上打印 这个 format 结果 "..." 可变参数包当中的 格式化之后的字符串。
sprintf()函数,会在 str 这个 字符串 参数(其实可以看做是缓冲区)当中复制拷贝一份在 str 当中。
snprintf()和 sprintf()也是一样的,只是,这个 str 的最大长度是 size。也就是一个安全的格式化接口。

#include
#include
#include
#include
#include //stdlib.h
#include
#include
#include
#define N 2
#define NUM 1024
using namespace std;
// child
void Writer(int wfd)
{
string s = "hello, I am child";
pid_t self = getpid();
int number = 0;
char buffer[NUM];
while (true)
{
sleep(1);
// 构建发送字符串
buffer[0] = 0; // 字符串清空, 只是为了提醒阅读代码的人,我把这个数组当做字符串了
snprintf(buffer, sizeof(buffer), "%s-%d-%d", s.c_str(), self, number++);
// cout << buffer << endl;
// 发送/写入给父进程, system call
write(wfd, buffer, strlen(buffer)); // strlen(buffer) + 1???
cout << number << endl;
}
}
// father
void Reader(int rfd)
{
char buffer[NUM];
while(true)
{
buffer[0] = 0;
// system call
ssize_t n = read(rfd, buffer, sizeof(buffer)); //sizeof != strlen
if(n > 0)
{
buffer[n] = 0; // 0 == '\0'
cout << "father get a message[" << getpid() << "]# " << buffer << endl;
}
else if(n == 0)
{
printf("father read file done!\n");
break;
}
else break;
// cout << "n: " << n << endl;
}
}
int main()
{
int pipefd[N] = {0};
int n = pipe(pipefd);
if (n < 0)
return 1;
// cout << "pipefd[0]: " << pipefd[0] << " , pipefd[1]: " << pipefd[1] << endl;
// child -> w, father->r
pid_t id = fork();
if (id < 0)
return 2;
if (id == 0)
{
// child
close(pipefd[0]);
// IPC code
Writer(pipefd[1]);
close(pipefd[1]);
exit(0);
}
// father
close(pipefd[1]);
// IPC code
Reader(pipefd[0]);
pid_t rid = waitpid(id, nullptr, 0);
if(rid < 0) return 3;
close(pipefd[0]);
sleep(5);
return 0;
} 输出:
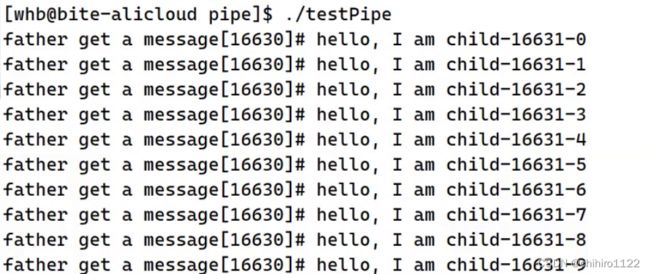
我们在上述代码当中,子进程的代码块并没有像屏幕上输出任何的消息,只有父进程向屏幕上打印了消息。
子进程只是把自己的消息,一次一次的往 共享文件当中写入,当 父进程 调用 read ()函数读取共享文件当中的内容,然后把 读取到的内容输出到 显示器文件当中。
子进程 一次次的 写入,父亲进程 就会一直读取,输出到 屏幕上。
思考 进程间通信的意义
在 之前谈到 父子进程的博客的当中,我们说过,父子进程 使用 if 语句分开的 代码块,同样可以访问到 之前共享的 局部变量,和 全局变量。
也就是说,如果我们在 全局当中定义一个字符串,那么这个字符串,不管是 父进程还是 子进程,都是可以拿到的,那么为什么要像上述代码当中,大费周章的 创建一个共享文件,也就是创建一个管道来实现的 父子进程间的通行的呢?
实际上,像我们上述所说的 之前共享的 局部变量,和 全局变量,像全局变量当中的字符串都是属于 静态数据,而 共享的局部变量虽然不是静态数据,但是,这两者只要是 父子进程其中任何一个 进程 进行了修改,都会发生写时拷贝。
此时,那么两者就不可能进行通信。
而,像上述,访问内存级的文件,为什么不能使用 C 库当中的文件操作函数接口,比如是 fopen()这些函数呢?
因为,操作系统不相信任何人。我们上述的父进程 和 子进程,操作系统怎么敢让 除自己之外的进程 直接访问到 内存当中的数据呢?
万一 这个进程直接向 内存当中 写入病毒,或者是把 内存写满了, 操作系统释放都不好释放怎么办?
所以,操作系统就告诉 进程,你要想访问内存,必须使用我提供的 系统调用接口,如上述所使用的 write(),read()这个系统调用接口 来访问 内存数据。
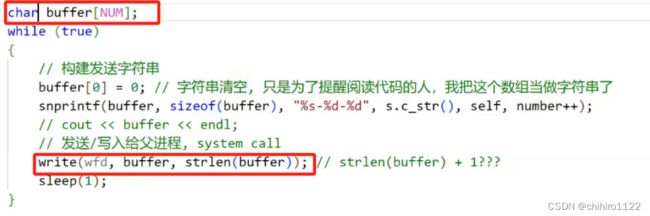
在上述例子的 子进程 代码块当中,我们使用 buffer 这个字符串数组来存储 要格式化的 字符串信息,然后在使用 write()函数 把buffer 当中的字符串拷贝到 共享文件当中。
所以,像上述的 buffer 这个字符串 ,就相当于是 用户级缓冲区。
而我们上述调用 write()函数,就相当于是 把 buffer 缓冲区当中的数据 , 刷新到 文件当中。
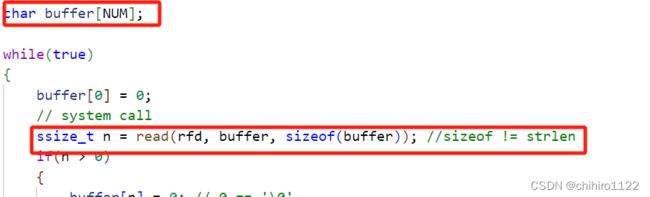
而,在父进程当中,也有一个 buffer数组,使用 read()函数,把 文件当中的数据拷贝到 buffer 数组当中,也相当于是把 文件当中的数据 拷贝到 buffer 这个用户级缓冲区当中。
向上述,在 Reader () 函数当中,父进程并没有 sleep(),但是子进程 sleep 了。你可能会以为,当子进程sleep 之时,父进程 会一直读,读完就结束了。
其实并不是,当你把 子进程当中 sleep 的秒数加到 50 秒,你会发现,子进程每隔50秒往共享文件当中输出信息,但是父进程没有一直再读,然后直接结束而是等待 子进程的输入:

这说明,父子进程之间是会进行 协同的。
我们进行进程之间的通信的时候,本质其实就是 让不同进程看到同一块资源,但是,如果是共享资源的话,就会带来一个问题,就是抢资源的问题。
也就是难免会出现访问冲突的问题,临界资源竞争的问题。
父子进程会进行 同步于互斥 --- 保护管道文件数据的安全。
而,管道是有自己的大小的,,如果我们让 父进程 等待 子进程把 共享文件写满,才进行读取的话。如果父进程当中的 buffer 数组是足够大的,那么他会一次把数据全部读取完。
也就是说,不管子进程当中,分多少次 写入的数据,父进程在读取之时,只是无脑的 直接把数据全部读取出来。
这就是 管道是面向字节流的这个特性。
也就说,管道看到的只是在文件当中存储的字符,他看到的只是字符,所以,它只会直接把 管道当中的数据直接读取出来,至于这个字符应该怎么分割,由用户去做。
验证 管道的大小:
使用 ulimit -a 命令 ,查看操作系统当中对于 很多重要资源的一种限制。
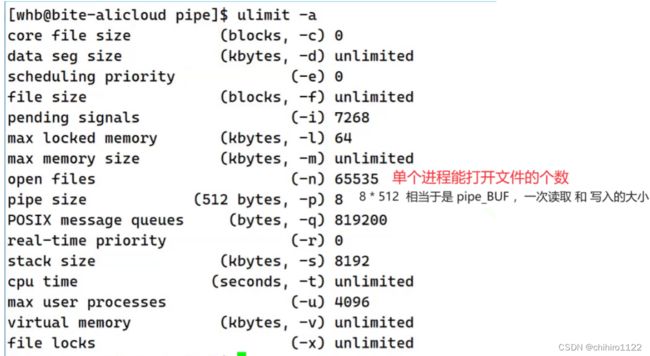
因为管道是基于文件的,所以,像上述的 以"r" 方式打开的 文件对象 和 以"w" 方式打开的 文件对象 的引用计数都是1。
当父子进程退出之时,因为这两个文件对象的 引用计数都是1 ,所以就算我们不进行关闭,操作系统也会帮我们进行关闭。
所以,管道是基于文件的,而文件的生命周期是随着进程的。
就像我们默认打开了 0,1,2 这三个标准输入输出文件,但是我们在最后并没有进行关闭,因为操作系统会帮我们自动关闭。
管道当中的四种情况
如果读写端是正常的,管道如果为空,读端就要进行阻塞。
读写端正常,管道如果被写满了,写端也要进行阻塞。
读端正常读,写端关闭,读端就会读到0,表明读到了文件的(pipe)结尾,不会被阻塞。
#include
#include
#include
#include
#include //stdlib.h
#include
#include
#include
#define N 2
#define NUM 1024
using namespace std;
// child
void Writer(int wfd)
{
string s = "hello, I am child";
pid_t self = getpid();
int number = 0;
char buffer[NUM];
while (true)
{
sleep(1);
// 构建发送字符串
//buffer[0] = 0; // 字符串清空, 只是为了提醒阅读代码的人,我把这个数组当做字符串了
//snprintf(buffer, sizeof(buffer), "%s-%d-%d", s.c_str(), self, number++);
// cout << buffer << endl;
// 发送/写入给父进程, system call
//write(wfd, buffer, strlen(buffer)); // strlen(buffer) + 1???
char c = 'c';
write(wfd, &c, 1); // strlen(buffer) + 1???
number++;
cout << number << endl;
if(number >= 5) break;
}
}
// father
void Reader(int rfd)
{
char buffer[NUM];
while(true)
{
buffer[0] = 0;
// system call
ssize_t n = read(rfd, buffer, sizeof(buffer)); //sizeof != strlen
if(n > 0)
{
buffer[n] = 0; // 0 == '\0'
cout << "father get a message[" << getpid() << "]# " << buffer << endl;
}
else if(n == 0)
{
printf("father read file done!\n");
break;
}
else break;
// cout << "n: " << n << endl;
}
}
int main()
{
int pipefd[N] = {0};
int n = pipe(pipefd);
if (n < 0)
return 1;
// cout << "pipefd[0]: " << pipefd[0] << " , pipefd[1]: " << pipefd[1] << endl;
// child -> w, father->r
pid_t id = fork();
if (id < 0)
return 2;
if (id == 0)
{
// child
close(pipefd[0]);
// IPC code
Writer(pipefd[1]);
close(pipefd[1]);
exit(0);
}
// father
close(pipefd[1]);
// IPC code
Reader(pipefd[0]);
pid_t rid = waitpid(id, nullptr, 0);
if(rid < 0) return 3;
close(pipefd[0]);
sleep(5);
return 0;
} 管道当中读取,必须是 原子性的:
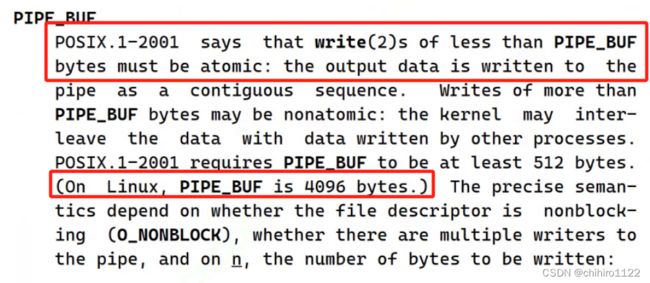
也就是说,上述父进程在读取之时,必须以 4096bytes 来读取,比如:子进程 输入了一个 "helloworld" 字符串,当 在子进程写完一个 hello ,父进程就直接把这个hello 读走了,这是不行的。
所以,需要规定,父进程必须以 "helloworld" 这个字符串 为一次读取,也就是说,要么一次读取 一个 "helloworld" 字符串,要么就不读。