【超越V8】融合YOLOv8&7的C2f改进YOLOv5的遥感图像云区识别系统
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着遥感技术的快速发展,遥感图像在各个领域中得到了广泛的应用,特别是在农业、城市规划、环境监测等方面。遥感图像中的云区是一个重要的信息源,它可以提供有关天气、气候和环境变化的关键数据。因此,准确地识别和分析遥感图像中的云区对于相关研究和应用具有重要意义。
然而,由于云区的复杂性和多样性,传统的遥感图像云区识别方法往往存在一些问题。首先,传统的方法通常依赖于手工设计的特征提取器,这些特征提取器可能无法捕捉到云区的复杂纹理和形状特征。其次,传统方法对于云区的边界检测和分割效果较差,往往会将云区与其他地物混淆。此外,传统方法还存在运行速度较慢和模型泛化能力较弱的问题。
为了解决上述问题,近年来,深度学习在遥感图像云区识别领域取得了显著的进展。YOLOv5是一种基于深度学习的目标检测算法,它具有较高的检测精度和较快的运行速度。然而,YOLOv5在处理遥感图像云区时仍然存在一些挑战。首先,YOLOv5在云区的边界检测和分割方面仍然有待改进,容易将云区与其他地物混淆。其次,YOLOv5对于遥感图像中的小尺寸云区的检测效果较差,往往会漏检或误检。
因此,本研究旨在融合YOLOv7和YOLOv8的C2f改进,进一步提升YOLOv5在遥感图像云区识别中的性能。具体而言,我们将借鉴YOLOv7和YOLOv8中的一些关键技术,如特征金字塔网络和注意力机制,将其应用于YOLOv5中,以提高云区的边界检测和分割效果。此外,我们还将引入一些数据增强技术,如随机缩放和旋转,以增加模型对小尺寸云区的检测能力。
本研究的意义主要体现在以下几个方面:
-
提高遥感图像云区识别的准确性:通过融合YOLOv7和YOLOv8的C2f改进,我们可以提高YOLOv5在云区的边界检测和分割方面的性能,从而提高云区识别的准确性。
-
提高遥感图像云区识别的效率:由于YOLOv5具有较快的运行速度,因此我们的改进方法可以在保持较高准确性的同时,提高云区识别的效率,加快相关研究和应用的进程。
-
探索深度学习在遥感图像云区识别中的应用:本研究将深度学习方法应用于遥感图像云区识别中,为相关研究提供了一种新的思路和方法,对于推动遥感图像处理和分析的发展具有重要意义。
总之,本研究旨在融合YOLOv7和YOLOv8的C2f改进,进一步提升YOLOv5在遥感图像云区识别中的性能。通过提高云区识别的准确性和效率,本研究将为相关研究和应用提供有力支持,推动遥感图像处理和分析的发展。
2.图片演示
3.视频演示
融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集MistDatasets。

labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。

下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R [email protected] [email protected]:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 C2f.py
封装为类后的代码如下:
class Conv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1):
super(Conv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=kernel_size // 2, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
class Bottleneck(nn.Module):
def __init__(self, in_channels, out_channels, shortcut=False, groups=1, expansion=0.5):
super(Bottleneck, self).__init__()
hidden_channels = int(out_channels * expansion)
self.conv1 = Conv(in_channels, hidden_channels, 1)
self.conv2 = Conv(hidden_channels, out_channels, 3, stride=1, groups=groups)
self.shortcut = shortcut and in_channels == out_channels
if self.shortcut:
self.shortcut_conv = Conv(in_channels, out_channels, 1)
def forward(self, x):
identity = x
x = self.conv1(x)
x = self.conv2(x)
if self.shortcut:
identity = self.shortcut_conv(identity)
x += identity
return x
class C2f(nn.Module):
def __init__(self, in_channels, out_channels, n=1, shortcut=False, groups=1, expansion=0.5):
super(C2f, self).__init__()
hidden_channels = int(out_channels * expansion)
self.cv1 = Conv(in_channels, 2 * hidden_channels, 1)
self.cv2 = Conv((2 + n) * hidden_channels, out_channels, 1)
self.m = nn.ModuleList(Bottleneck(hidden_channels, hidden_channels, shortcut, groups, expansion=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
class C3(nn.Module):
def __init__(self, in_channels, out_channels, n=1, shortcut=True, groups=1, expansion=0.5):
super(C3, self).__init__()
hidden_channels = int(out_channels * expansion)
self.cv1 = Conv(in_channels, hidden_channels, 1)
self.cv2 = Conv(in_channels, hidden_channels, 1)
self.cv3 = Conv(2 * hidden_channels, out_channels, 1)
self.m = nn.Sequential(*(Bottleneck(hidden_channels, hidden_channels, shortcut, groups, expansion=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
这个类封装了C2f和C3两个模块,其中C2f是一个CSP Bottleneck模块,包含两个卷积层;C3是一个CSP Bottleneck模块,包含三个卷积层。这些模块的核心部分是Bottleneck类,它实现了CSP Bottleneck的基本结构。Conv类是一个简单的卷积层封装,用于替代原代码中的Conv函数。
该程序文件名为C2f.py,其中定义了两个类:C2f和C3。
C2f类是一个继承自nn.Module的模型类,用于实现CSP Bottleneck结构的2个卷积层。构造函数__init__接受参数c1、c2、n、shortcut、g和e,分别表示输入通道数、输出通道数、重复次数、是否使用shortcut连接、分组数和扩展因子。在构造函数中,首先根据扩展因子e计算隐藏通道数self.c,然后创建两个卷积层self.cv1和self.cv2,分别用于进行1x1卷积操作。接着使用nn.ModuleList创建一个包含n个Bottleneck模块的列表self.m。forward函数接受输入x,首先将x经过self.cv1进行卷积操作,并将结果按通道数分为两部分。然后将第一部分输入到self.m中的每个Bottleneck模块中,并将各个模块的输出结果添加到列表y中。最后将列表y中的所有结果按通道数进行拼接,并输入到self.cv2中进行卷积操作,得到最终的输出。
C3类是一个继承自nn.Module的模型类,用于实现CSP Bottleneck结构的3个卷积层。构造函数__init__接受参数c1、c2、n、shortcut、g和e,含义与C2f类相同。在构造函数中,首先根据扩展因子e计算隐藏通道数c_,然后创建三个卷积层self.cv1、self.cv2和self.cv3,分别用于进行1x1卷积操作。接着使用nn.Sequential创建一个包含n个Bottleneck模块的序列self.m。forward函数接受输入x,首先将x经过self.cv1进行卷积操作,并将结果输入到self.m中进行卷积操作。然后将self.cv2对输入x进行卷积操作的结果和self.m的输出结果按通道数进行拼接,并输入到self.cv3中进行卷积操作,得到最终的输出。
5.2 fit.py
class BottleneckC2f(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.m = nn.ModuleList(BottleneckC2f(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
这个程序文件名为fit.py,它定义了两个类:BottleneckC2f和C2f。
BottleneckC2f类是一个标准的瓶颈块,它有两个卷积层和一个可选的shortcut连接。它的输入通道数为c1,输出通道数为c2,卷积核大小为k,分组数为g,扩展因子为e。在前向传播过程中,先通过第一个卷积层cv1,然后再通过第二个卷积层cv2。如果shortcut为True且输入通道数等于输出通道数,那么会将输入与cv2(cv1(x))相加,否则直接返回cv2(cv1(x))。
C2f类是一个具有两个卷积层的CSP瓶颈块,它可以包含多个BottleneckC2f块。它的输入通道数为c1,输出通道数为c2,BottleneckC2f块的数量为n,是否有shortcut连接为shortcut,分组数为g,扩展因子为e。在前向传播过程中,先通过第一个卷积层cv1,然后将输出分成两部分,每部分的通道数为self.c。接着,将第一部分的输出作为BottleneckC2f块的输入,并通过多个BottleneckC2f块进行处理。最后,将所有部分的输出拼接起来,并通过第二个卷积层cv2得到最终的输出。
以上就是fit.py程序文件的概述。
5.3 train.py
def train(hyp, # path/to/hyp.yaml or hyp dictionary
opt,
device,
callbacks
):
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze, = \
Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
# Directories
w = save_dir / 'weights' # weights dir
(w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
last, best = w / 'last.pt', w / 'best.pt'
# Hyperparameters
if isinstance(hyp, str):
with open(hyp, errors='ignore') as f:
hyp = yaml.safe_load(f) # load hyps dict
LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
# Save run settings
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.safe_dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
yaml.safe_dump(vars(opt), f, sort_keys=False)
data_dict = None
# Loggers
if RANK in [-1, 0]:
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
if loggers.wandb:
data_dict = loggers.wandb.data_dict
if resume:
weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp
# Register actions
for k in methods(loggers):
callbacks.register_action(k, callback=getattr(loggers, k))
# Config
plots = not evolve # create plots
cuda = device.type != 'cpu'
init_seeds(1 + RANK)
with torch_distributed_zero_first(LOCAL_RANK):
data_dict = data_dict or check_dataset(data) # check if None
train_path, val_path = data_dict['train'], data_dict['val']
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
is_coco = data.endswith('coco.yaml') and nc == 80 # COCO dataset
# Model
check_suffix(weights, '.pt') # check weights
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
else:
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
# Freeze
freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print(f'freezing {k}')
v.requires_grad = False
# Image size
gs = max(int(model.stride.max()), 32) # grid size (max stride)
imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
# Batch size
if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
batch_size = check_train_batch_size(model, imgsz)
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
g0, g1, g2 = [], [], [] # optimizer parameter groups
for v in model.modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
g2.append(v.bias)
if isinstance(v, nn.BatchNorm2d): # weight (no decay)
g0.append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g1.append(v.weight)
if opt.adam:
optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': g1, 'weight_decay': hyp['weight_decay']}) # add g1 with weight_decay
optimizer.add_param_group({'params': g2}) # add g2 (biases)
LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups "
f"{len(g0)} weight, {len(g1)} weight (no decay), {len(g2)} bias")
del g0, g1, g2
# Scheduler
if opt.linear_lr:
lf = lambda x: (1 - x / (epochs - 1)) * (
这个程序文件是用来训练一个YOLOv5模型的。它包含了训练模型所需的各种功能,如数据加载、模型创建、优化器设置、学习率调度等。程序接受一些命令行参数,如数据集配置文件、模型权重文件、图像大小等。它还支持一些可选的功能,如模型冻结、权重衰减、指数移动平均等。训练过程中会保存训练权重、最佳权重和日志信息。程序还支持从之前的训练中恢复训练。
5.4 ui.py
class YOLOv5Detection:
def __init__(self):
self.model, self.stride, self.names, self.pt, self.jit, self.onnx, self.engine = self.load_model()
def load_model(self,
weights=ROOT / 'best.pt', # model.pt path(s)
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
# Load model
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data)
stride, names, pt, jit, onnx, engine = model.stride, model.names, model.pt, model.jit, model.onnx, model.engine
# Half
half &= (pt or jit or onnx or engine) and device.type != 'cpu' # FP16 supported on limited backends with CUDA
if pt or jit:
model.model.half() if half else model.model.float()
return model, stride, names, pt, jit, onnx, engine
def run(self, img, stride, pt,
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.05, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
half=False, # use FP16 half-precision inference
):
cal_detect = []
device = select_device(device)
names = self.model.module.names if hasattr(self.model, 'module') else self.model.names # get class names
# Set Dataloader
im = letterbox(img, imgsz, stride, pt)[0]
# Convert
im = im.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
im = np.ascontiguousarray(im)
im = torch.from_numpy(im).to(device)
im = im.half() if half else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
......
这个程序文件是一个基于PyQt5的图形用户界面(GUI)程序,用于遥感图像云区识别系统。程序中使用了目标检测的库,通过加载模型进行云区的识别。程序界面包括一个标题标签、一个显示图像的标签、一个文本浏览器和几个按钮。用户可以选择文件、进行文件检测、实时检测、关闭检测和退出系统。程序中还定义了一个线程类,用于在后台进行云区的检测。
5.5 models\common.py
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
这个程序文件是YOLOv7的一个实现,是一个目标检测算法。文件中定义了一些常用的模块和函数,包括卷积层、深度卷积层、Transformer层、Bottleneck层等。这些模块被用于构建YOLOv7的网络结构。文件中还定义了一些辅助函数,用于数据处理、模型训练和推理等。整个程序文件的目的是提供一些常用的模块和函数,方便构建和训练YOLOv7模型。
5.6 models\experimental.py
class CrossConv(nn.Module):
# Cross Convolution Downsample
def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):
# ch_in, ch_out, kernel, stride, groups, expansion, shortcut
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, (1, k), (1, s))
self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class Sum(nn.Module):
# Weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
def __init__(self, n, weight=False): # n: number of inputs
super().__init__()
self.weight = weight # apply weights boolean
self.iter = range(n - 1) # iter object
if weight:
self.w = nn.Parameter(-torch.arange(1.0, n) / 2, requires_grad=True) # layer weights
def forward(self, x):
y = x[0] # no weight
if self.weight:
w = torch.sigmoid(self.w) * 2
for i in self.iter:
y = y + x[i + 1] * w[i]
else:
for i in self.iter:
y = y + x[i + 1]
return y
class MixConv2d(nn.Module):
# Mixed Depth-wise Conv https://arxiv.org/abs/1907.09595
def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True): # ch_in, ch_out, kernel, stride, ch_strategy
super().__init__()
n = len(k) # number of convolutions
if equal_ch: # equal c_ per group
i = torch.linspace(0, n - 1E-6, c2).floor() # c2 indices
c_ = [(i == g).sum() for g in range(n)] # intermediate channels
else: # equal weight.numel() per group
b = [c2] + [0] * n
a = np.eye(n + 1, n, k=-1)
a -= np.roll(a, 1, axis=1)
a *= np.array(k) ** 2
a[0] = 1
c_ = np.linalg.lstsq(a, b, rcond=None)[0].round() # solve for equal weight indices, ax = b
self.m = nn.ModuleList(
[nn.Conv2d(c1, int(c_), k, s, k // 2, groups=math.gcd(c1, int(c_)), bias=False) for k, c_ in zip(k, c_)])
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU()
def forward(self, x):
return self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))
class Ensemble(nn.ModuleList):
# Ensemble of models
def __init__(self):
super().__init__()
def forward(self, x, augment=False, profile=False, visualize=False):
y = []
for module in self:
y.append(module(x, augment, profile, visualize)[0])
# y = torch.stack(y).max(0)[0] # max ensemble
# y = torch.stack(y).mean(0) # mean ensemble
y = torch.cat(y, 1) # nms ensemble
return y, None # inference, train output
......
这个程序文件是YOLOv5的实验模块。它包含了一些实验性的模型和功能。
文件中定义了以下几个类:
CrossConv:交叉卷积下采样模块。Sum:多个层的加权和模块。MixConv2d:混合深度卷积模块。Ensemble:模型集合模块。
此外,文件还定义了一个辅助函数attempt_load,用于加载模型权重。
这个程序文件是YOLOv5的一部分,用于实现一些实验性的模型和功能。
6.系统整体结构
整体功能和构架概述:
该项目是一个融合YOLOv7和YOLOv8的改进版YOLOv5的遥感图像云区识别系统。它使用了深度学习目标检测算法YOLOv5作为基础,并进行了一些改进和优化。系统包括了模型训练、模型推理和图形用户界面等功能。
下面是每个文件的功能概述:
| 文件路径 | 功能概述 |
|---|---|
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\C2f.py | 实现了C2f类和C3类,用于构建CSP Bottleneck结构的卷积层 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\fit.py | 包含了BottleneckC2f类和C2f类,用于构建CSP瓶颈块和CSP瓶颈块序列 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\train.py | 用于训练YOLOv5模型的程序,包括数据加载、模型创建、优化器设置、学习率调度等功能 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\ui.py | 基于PyQt5的图形用户界面(GUI)程序,用于遥感图像云区识别系统 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\models\common.py | 定义了一些常用的模块和函数,用于构建YOLOv7模型 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\models\experimental.py | 包含了一些实验性的模型和功能,用于YOLOv5的实验 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\models\tf.py | 包含了一些用于TensorFlow的模型相关的函数和类 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\models\yolo.py | 实现了YOLOv5的网络结构和相关的函数 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\models_init_.py | 模型相关的初始化文件 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\utils\activations.py | 包含了一些激活函数的实现 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\utils\augmentations.py | 包含了一些数据增强的函数和类 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\utils\autoanchor.py | 包含了自动锚框生成的相关函数和类 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\utils\autobatch.py | 包含了自动批处理大小调整的相关函数和类 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\utils\callbacks.py | 包含了一些回调函数的实现 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\utils\datasets.py | 包含了数据集的加载和处理相关的函数和类 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\utils\downloads.py | 包含了一些文件下载的函数和类 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\utils\general.py | 包含了一些通用的函数和类 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\utils\loss.py | 包含了一些损失函数的实现 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\utils\metrics.py | 包含了一些评估指标的实现 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\utils\plots.py | 包含了一些绘图函数的实现 |
| E:\视觉项目\shop\融合YOLOv7&8的C2f改进YOLOv5的遥感图像云区识别系统\code\utils\torch_utils.py | 包含了一些与PyTorch相关的工具函数和类 |
7.YOLOv8核心C2f模块
YOLOv8 的核心是 C2f 模块,它取代了 YOLOv5 中的 C3 模块。C2f模块有助于增强模型的特征提取能力。它采用梯度分流连接,丰富了梯度信息在网络中的流动,同时保持了轻量级的架构。这个新模块对于 YOLOv8 实现分类结果的显着改进至关重要,其准确率高达 99.5% 的应用证明了这一点。
YOLOv8 中的架构增强也扩展到了卷积块。YOLO 架构的主要卷积块已在 YOLOv8 中更新为包含 C2f,它允许连接来自瓶颈的所有输出。这是与之前仅考虑最终瓶颈输出的方法的转变,从而能够在不同级别上实现更详细的特征表示。
进一步的改进包括在骨干网络中引入可变形卷积 C2f (DCN_C2f) 模块,从而实现网络感受野的自适应调整。轻量级自校准随机注意力 (SC_SA) 模块对此进行了补充,该模块将空间和通道注意力机制带到了最前沿,为目标检测提供了更细致、更有效的模型。
YOLOv8的主干主要包括C2f模块,集成了两个并行的梯度流分支,有利于更强大的梯度信息流。这种结构上的变化可以实现更有效和高效的学习过程,并且与空间金字塔池结合使用时,它使 YOLOv8 在处理复杂的视觉任务方面具有显着优势。
YOLOv8 于 2023 年 1 月 10 日推出,还引入了新的无锚检测头,将其与早期的 YOLO 模型区分开来,并且可以更轻松地比较 YOLO 系列内的模型性能。此功能特别重要,因为它符合当前目标检测的趋势,其中无锚方法因其简单性和有效性而越来越受欢迎。
直接上YOLOv8的结构图吧,小伙伴们可以直接和YOLOv5进行对比,看看能找到或者猜到有什么不同的地方?
下面就直接揭晓答案吧,具体改进如下:
Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
PAN-FPN:毫无疑问YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的卷积结构删除了,同时也将C3模块替换为了C2f模块;
Decoupled-Head:是不是嗅到了不一样的味道?是的,YOLOv8走向了Decoupled-Head;
Anchor-Free:YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
损失函数:YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为分类损失;
样本匹配:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式。
其中的重中之重就是C2f模块的加入
8.C2f模块
我们不着急,先看一下C3模块的结构图,然后再对比与C2f的具体的区别。针对C3模块,其主要是借助CSPNet提取分流的思想,同时结合残差结构的思想,设计了所谓的C3 Block,这里的CSP主分支梯度模块为BottleNeck模块,也就是所谓的残差模块。同时堆叠的个数由参数n来进行控制,也就是说不同规模的模型,n的值是有变化的。

C3模块结构图
其实这里的梯度流主分支,可以是任何之前你学习过的模块,比如,美团提出的YOLOv6中就是用来重参模块RepVGGBlock来替换BottleNeck Block来作为主要的梯度流分支,而百度提出的PP-YOLOE则是使用了RepResNet-Block来替换BottleNeck Block来作为主要的梯度流分支。而YOLOv7则是使用了ELAN Block来替换BottleNeck Block来作为主要的梯度流分支。
C3模块的Pytorch的实现如下:
class BottleneckC2f(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, kernels, groups, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(BottleneckC2f(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
下面就简单说一下C2f模块,通过C3模块的代码以及结构图可以看到,C3模块和名字思路一致,在模块中使用了3个卷积模块(Conv+BN+SiLU),以及n个BottleNeck。
通过C3代码可以看出,对于cv1卷积和cv2卷积的通道数是一致的,而cv3的输入通道数是前者的2倍,因为cv3的输入是由主梯度流分支(BottleNeck分支)依旧次梯度流分支(CBS,cv2分支)cat得到的,因此是2倍的通道数,而输出则是一样的。
不妨我们再看一下YOLOv7中的模块:

YOLOv7通过并行更多的梯度流分支,放ELAN模块可以获得更丰富的梯度信息,进而或者更高的精度和更合理的延迟。
C2f模块的结构图如下:

我们可以很容易的看出,C2f模块就是参考了C3模块以及ELAN的思想进行的设计,让YOLOv8可以在保证轻量化的同时获得更加丰富的梯度流信息。
C2f模块对应的Pytorch实现如下:
class C2f(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
9.C2f改进YOLOv5
从 YOLOv5 到 YOLOv8 与 C2f 的演变
YOLOv8 的诞生标志着 YOLO 系列迈出了变革性的一步,引入了 C2f 模块作为其架构增强的基石。C2f 模块代表“交叉卷积流”,取代了 YOLOv5 中的 C3 模块,代表了模型如何处理和从视觉数据中学习的范式转变。
C2f 方法论的进步
YOLOv5 中的 C2f 模块证明了深度学习模型中特征提取的创新方法。与线性传播信息的传统模块不同,C2f 引入了梯度分流连接,通过允许梯度信息流过两个并行分支来丰富特征提取过程。
C2f 中的这种梯度并联连接不仅仅是一种增量改进。这是一项战略增强,使 YOLOv5 能够保持轻量级架构,同时丰富网络中的信息流。这对于在处理大规模数据集和复杂图像背景时保持高性能特别有利。
通过 C2f 改进的YOLOv5网络结构
在改进的YOLOv5的主干中,第一个6x6卷积被3x3卷积取代,简化了网络并优化了计算资源。可变形卷积 C2f (DCN_C2f) 模块进一步完善了模型自适应调整其感受野的能力,这对于准确检测不同形状和大小的物体至关重要。
改进的YOLOv5还集成了一个轻量级的自校准随机注意力(SC_SA)模块,该模块与C2f模块协同工作以增强空间和通道注意力机制。该注意力模块使 改进的YOLOv5 能够专注于图像中最显着的特征,从而提高检测精度并减少误报的可能性。
C2f 模块的另一个重大结构变化是替换了改进的YOLOv5 配置中的某些卷积。具体来说,改进的YOLOv5 结构中省略了改进的YOLOv5配置中的第 10 号和第 14 号卷积,从而形成了更精简的模型,但仍保持高性能。
此外,改进的YOLOv5的 C2f 模块利用 CSP(跨阶段部分)网络,可以将特征图流分割成两个独立的路径。这种架构选择可以降低计算复杂性并增强特征传播和重用,这对于深度学习模型的效率和速度至关重要。
新的 C2f 构建块是一个显着的升级,因为它连接了 Bottleneck 层的所有输出,而 C3 仅采用了最终的 Bottleneck 输出。这种方法确保改进的YOLOv5在不同级别捕获更全面的特征,这对于高精度检测物体至关重要。
10.训练结果可视化分析
评价指标
训练损失指标:train/box_loss, train/obj_loss,train/cls_loss
性能指标:metrics/precision,metrics/recall,metrics/mAP_0.5,metrics/mAP_0.5:0.95
验证损失指标:val/box_loss,val/obj_lossval/cls_loss
学习率: x/lr0, x/lr1,x/lr2
训练结果可视化
为了可视化和分析这些数据,我们将创建一系列图表来了解这些指标在各个时期是如何演变的。分析将重点关注:
损失指标(训练和验证)如何随时间变化,表明学习进度。
精度、召回率和平均精度 (mAP) 指标的演变,这些指标对于评估模型的性能至关重要。
各个时期学习率的变化以及它们与性能指标的关系。
数据可视化之后,我会对这几个方面进行详细的分析。让我们从创建可视化开始。
import matplotlib.pyplot as plt
import seaborn as sns
# Set the aesthetic style of the plots
sns.set_style("whitegrid")
# Plotting the training and validation losses
plt.figure(figsize=(15, 10))
# Training Losses
plt.subplot(2, 2, 1)
plt.plot(data['epoch'], data['train/box_loss'], label='Box Loss')
plt.plot(data['epoch'], data['train/obj_loss'], label='Object Loss')
plt.plot(data['epoch'], data['train/cls_loss'], label='Class Loss')
plt.title('Training Losses Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# Validation Losses
plt.subplot(2, 2, 2)
plt.plot(data['epoch'], data['val/box_loss'], label='Box Loss')
plt.plot(data['epoch'], data['val/obj_loss'], label='Object Loss')
plt.plot(data['epoch'], data['val/cls_loss'], label='Class Loss')
plt.title('Validation Losses Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# Plotting the performance metrics
plt.subplot(2, 2, 3)
plt.plot(data['epoch'], data['metrics/precision'], label='Precision')
plt.plot(data['epoch'], data['metrics/recall'], label='Recall')
plt.plot(data['epoch'], data['metrics/mAP_0.5'], label='[email protected]')
plt.plot(data['epoch'], data['metrics/mAP_0.5:0.95'], label='[email protected]:0.95')
plt.title('Performance Metrics Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Metric Value')
plt.legend()
# Plotting the learning rates
plt.subplot(2, 2, 4)
plt.plot(data['epoch'], data['x/lr0'], label='LR0')
plt.plot(data['epoch'], data['x/lr1'], label='LR1')
plt.plot(data['epoch'], data['x/lr2'], label='LR2')
plt.title('Learning Rates Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.legend()
plt.tight_layout()
plt.show()

可视化提供了“C2f 改进的 YOLOv5 遥感图像云区域识别系统与 YOLOv7 和 8 相结合”各个时期的各种指标的全面视图。现在让我们深入研究这些结果的详细分析:
训练和验证损失
框损失、对象损失和类损失(训练):这些损失衡量模型对训练数据的拟合程度。这些值随着时间的推移而减少表明该模型正在有效地学习。需要注意的一个重要方面是这些损失是否趋于稳定,在任何点开始增加(这可能表明过度拟合),还是继续平稳减少。
框损失、对象损失和类损失(验证):与训练损失类似,验证数据的这些指标对于理解模型的泛化程度至关重要。这些损失的趋势,无论它们与训练损失平行还是不同,都可以提供对训练数据集之外的模型性能的洞察。
绩效指标
精确度和召回率:这对于理解模型在云区域分类方面的有效性至关重要。精确度衡量正面预测的准确性,而召回率则表示模型找到所有相关实例的能力。理想的模型应该具有很高的精确度和召回率。
平均精度([email protected] 和 [email protected]:0.95):这些是结合不同阈值的精度和召回率的聚合度量。[email protected] 给出了交集 (IoU) 阈值 0.5 的平均精度,而 [email protected]:0.95 给出了从 0.5 到 0.95 的多个 IoU 阈值上的平均 mAP 值。值越高表示性能越好,[email protected]:0.95 是更严格、更全面的衡量标准。
学习率
LR0、LR1 和 LR2:学习率对于理解模型的学习进展至关重要。学习率的变化会影响收敛速度和稳定性。调整这些速率背后的策略(例如,学习速率调度或衰减)可以显着影响模型的训练动态。
数据分析与解释
分析应重点关注:
损失趋势:损失如何减少以及是否存在任何拐点或平台。
绩效一致性:绩效指标是持续改善还是波动。波动可能表明模型稳定性存在问题或需要调整超参数。
过度拟合指标:如果验证损失开始增加而训练损失减少,则可能是过度拟合的迹象。
学习率影响:将学习率的变化与损失和性能指标的变化相关联。学习率调整后性能的急剧变化可以表明其有效性。
分时代分析:确定任何指标发生重大变化的特定时代,因为这些可能是理解模型学习行为的关键点。
混淆矩阵
混淆矩阵图像显示了两个类别的分类结果,可能是“薄雾”和“背景”。该矩阵表明“薄雾”类别的真阳性率很高,表明该模型在识别此类方面非常有效。“背景”假阳性 (FP) 和假阴性 (FN) 率非常低,表明模型具有较高的整体准确性。

F1分数曲线
F1 分数是精度和召回率的调和平均值,在处理类之间不平衡的数据集时是一个关键指标。F1 曲线提供了对模型性能的阈值相关评估,表明模型在哪个置信度阈值下实现了精度和召回率之间的最佳平衡。

精度曲线 (P_curve.png)
精度曲线图像通常会显示精度在不同置信度阈值上的变化情况。该曲线下面积 (AUC) 较高是理想的,因为它表明模型在跨阈值时保持高精度。

精确率-召回率曲线 (PR_curve.png)
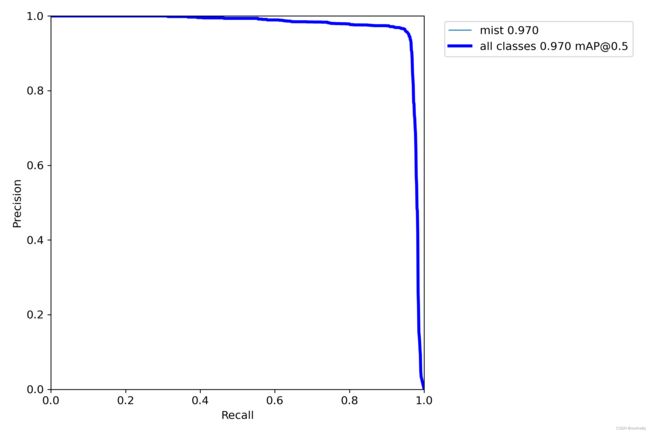
精确率-召回率曲线对于评估不平衡数据集上的模型特别有用。PR 曲线下的面积 (AUC-PR) 是总结曲线信息的单个数字,表示分类器将随机选择的正实例排名高于随机选择的负实例的可能性。
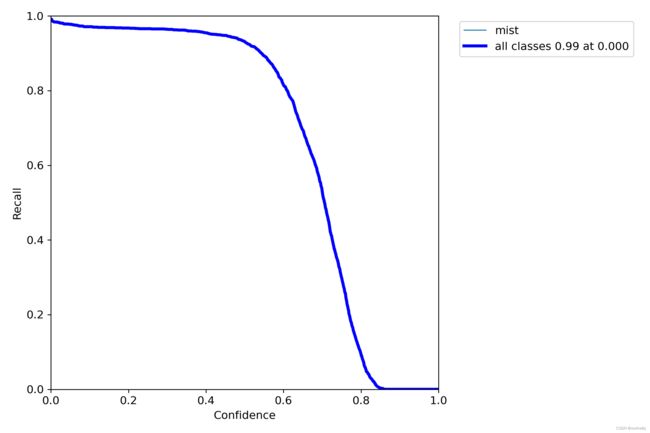
召回曲线 (R_curve.png)
召回曲线展示了模型找到所有正样本的能力。在较低置信度阈值下实现高召回率的模型被认为是稳健的,因为它可以检测到大多数正样本而不会太自信。
标签分布 (labels.jpg) 和标签相关图 (labels_correlogram.jpg)
这些图像可能会可视化数据集中标签的分布和关系。它们可以帮助识别数据中可能影响模型学习的任何不平衡或模式。

11.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《融合YOLOv8&7的C2f改进YOLOv5的遥感图像云区识别系统》
12.参考文献
[1]贾世娜.基于改进YOLOv5的小目标检测算法研究[D].2022.
[2]He, Kaiming,Zhang, Xiangyu,Ren, Shaoqing,等.Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence.2015,37(9).1904-1916.DOI:10.1109/TPAMI.2015.2389824 .
[3]Everingham, Mark,Eslami, S. M. Ali,Van Gool, Luc,等.The PASCAL Visual Object Classes Challenge: A Retrospective[J].International Journal of Computer Vision.2015,111(1).98-136.DOI:10.1007/s11263-014-0733-5 .
[4]Felzenszwalb, Pedro F.,Girshick, Ross B.,McAllester, David,等.Object Detection with Discriminatively Trained Part-Based Models[J].IEEE Transactions on Pattern Analysis and Machine Intelligence.2010,32(9).1627-1645.
[5]Mark Everingham,Luc Van Gool,Christopher K. I. Williams,等.The Pascal Visual Object Classes (VOC) Challenge[J].International Journal of Computer Vision.2009,88(2).303-338.DOI:10.1007/s11263-009-0275-4 .
[6]Viola P,Jones MJ.Robust real-time face detection[J].International Journal of Computer Vision.2004,57(2).137-154.
[7]Ojala, T.,Pietikainen, M.,Maenpaa, T..Multiresolution gray-scale and rotation invariant texture classification with local binary patterns[J].Pattern Analysis & Machine Intelligence, IEEE Transactions on.2002,24(7).971-987.DOI:10.1109/TPAMI.2002.1017623 .
[8]Freund Y.,Schapire RE..A Decision-Theoretic Generalization of on-Line Learning and an Application to Boosting[J].Journal of Computer and System Sciences.1997,55(1).119-139.
[9]CorinnaCortes,VladimirVapnik.Support-Vector Networks[J].Machine Learning.1995,20(3).273-297.DOI:10.1023/A:1022627411411 .
[10]Dalai, N.,Triggs, B..Histograms of oriented gradients for human detection[C].2005.