Python微服务架构设计&使用asyncio提升性能
文章目录
- 1 引言
- 2 微服务概念
- 3 backend-for-frontend 模式
- 4 实施产品列表 API
-
- 4.1 实现基础服务
- 4.2 实现BFF服务
- 4.3 重试失败的请求
- 4.4 断路器模式
- 5 总结
1 引言
许多 Web 应用程序都被构建为单体应用程序,单体应用程序通常是包含多个模块的大中型应用程序,这些模块作为一个单元独立部署和管理。虽然这种模型本质上没有任何问题(单体应用程序非常好,甚至更可取,因为它们通常更简单),但确实存在缺点。即使你对单体应用程序只进行了小幅更改,也需要重新部署整个应用程序,那些没有更改的部分也需要重新部署。
例如,一个单一的电子商务应用程序可能具有订单管理和产品列表两个端点,这意味着对产品端点的调整需要重新部署订单管理代码。而微服务架构可帮助消除这些痛点,我们可为订单和产品创建单独的服务,此后一项服务的更改不会影响另一项服务。
在本篇文章中,我们将更多地了解微服务及其背后的原理,并学习一种称为 backend-for-frontend(简称 BFF)的模式,将其应用于电子商务微服务架构,然后将通过 FastAPI 和 SQLAlchemy 实现它。学习如何使用并发来帮助提高应用程序的性能,还将学习如何正确处理故障,并使用断路器模式进行重试,以构建更强大的应用程序。
2 微服务概念
首先,让我们定义什么是微服务。这是一个相当棘手的问题,因为没有标准化的定义,而在业界关于微服务有很多不同的定义。通常,微服务遵循一些指导原则:
它们是松散耦合,且能够独立部署的
它们有自己独立的堆栈,包括数据模型
它们通过 REST 或 gRPC 等协议相互通信
它们遵循’单一职责’原则,也就是说一个微服务应该’只做一件事,并把它做好’
让我们将这些原则应用于电子商务商铺的具体示例,在像这样的应用程序中,用户向组织提供运输和支付信息,然后购买产品。如果是单体架构,一般由一个应用程序和一个数据库来管理用户数据、账户数据(例如他们的订单和运输信息)以及产品。而对于微服务架构,将有多个服务,每个服务都有自己的数据库来处理不同的问题。可能有一个带有独立数据库的产品 API,它只处理产品相关的数据;还可能有一个带有独立数据库的用户 API,它处理用户账户相关的信息。
为什么选择这种架构风格而不是单体架构呢?毫无疑问单体架构对于大多数应用来说都非常好,它们更易于管理。进行代码更改后,需要运行所有测试套件以确保看似很小的更改不会影响系统的其他区域,运行测试后,将应用程序部署为一个单元。如果应用程序在负载下表现不佳,这种情况下,你可以水平或垂直扩展,部署更多应用程序实例或部署到更强大的机器以支持额外用户。虽然管理单体架构在操作上更简单,但这种简单性往往也是其最大的缺点。具体使用哪种模式,需要你自己根据情况进行权衡,可以考量的点有以下几个。
代码复杂性
随着应用程序的增长和获得更多新功能,它的复杂性也在增加,数据模型可能变得更加耦合,导致无法预料和难以理解的依赖关系。技术问题越来越大,使开发变得更慢、更复杂。虽然任何开发中的系统都是如此,但具有多个关注点的大型代码库可能加剧这种情况。
可扩展性
在单体架构中,如果你需要扩展,则需要添加整个应用程序的更多实例,这可能导致技术成本效率低下。在电子商务应用程序的环境中,你获得的订单通常比浏览产品的人少得多。在单体架构中,扩大规模以支持更多查看你产品的人的同时,你也扩大了订单处理能力(而订单处理能力的增加,其实是对资源的浪费)。但在微服务架构中,可只扩展查阅产品服务,并保持订单服务不变。
团队和技术栈独立性
随着开发团队的壮大,新挑战也随之出现。想象一下,你有 5 个团队在同一个单一的代码库上工作,每个团队每天提交几次代码。那么合并冲突将成为每个人都需要处理的日益严重的问题,跨团队协调部署也是如此。而对于独立的、松散耦合的微服务来说这不再是问题,如果一个团队拥有一项服务,可以在很大程度上独立地处理和部署该服务。如果需要,这也允许团队使用不同的技术栈,一种服务可以使用 Java,另一种使用 Python。
asyncio 如何提供帮助
微服务通常需要通过 REST 或 gRPC 等协议相互通信,由于我们可能同时与多个微服务通信,这开启了并发运行请求的可能性,创造了比同步应用程序更高的效率。
除了从异步堆栈中获得的资源效率优势,还获得了异步 API 的错误处理优势,例如 wait 和 gather,它允许我们从一组协程或任务中聚合异常。如果一组特定的请求花费的时间太长或者该组的一部分出现异常,我们可以轻松地处理它们。到现在我们已经了解了微服务背后的基本原理,让我们学习一种常见的微服务架构模式,并看看如何实现它。
3 backend-for-frontend 模式
在微服务架构中构建 UI 时,通常需要从多个服务中获取数据来创建特定的 UI 视图。例如正在构建用户订单历史 UI,可能必须从订单服务中获取用户的订单历史,并将它和来自产品服务的产品数据合并。根据要求,可能还需要来自其他服务的数据。
换句话说,因为微服务讲究单一职责,每一个子服务都是原子服务、独立进程、隔离部署、去中心化,一个服务只干一件事情。要想满足某个用户场景,可能需要调用几个、甚至十几个微服务,才能将数据组装出来。如果没有 BFF,那么这一步就只能让客户端来做,但这其实会非常困难,原因树下:
1)客户端到每个微服务之间直接通讯,强耦合,这种情况下很难做到微服务的大规模重构。浏览器还好,如果是移动端的话,你的接口外网在用,有人请求的时候要保证他的服务质量。否则的话,你只能强迫用户升级 APP,但这会让用户的体验变差。一个好的 APP,应该是不管什么版本都能正常使用,不能因为升级,就导致老版本的 APP 无法使用。所以,如果客户端到微服务之间强耦合,那么你在升级服务的时候就要小心了,要保证能够兼容老版本的 APP。
2)需要多次请求,客户端聚合数据,工作量大,要调用这么多的服务,每个部门的接口长得还都不一样,沟通成本太大了,不符合康威定律。另外客户端聚合数据会导致延迟高,因为客户端是直接面向用户的,一定要讲究效率。
3)不同的机型需要单独进行适配,像手机、平板,操作系统有安卓、IOS,每个手机也有不同的尺寸,不同的尺寸某个字段有的需要、有的不需要,非常恶心。面向「端」的 API 适配,耦合到了内部服务。
4)统一逻辑无法收敛,比如安全认证、限流等等。
因此以上四个原因就决定了数据组装这一步必须由后端、也就是服务端全部做掉,然后面向不同的用户场景提供一个统一的 API,以后客户端只需要和 BFF 团队对接即可, BFF 来统一调用底层的微服务。所以 BFF 的全称是 Backend For Frontend,也就是面向前端的后端,还是很形象的。
BFF 可以认为是一种适配服务,将后端的微服务进行适配(主要包括聚合裁剪和格式适配等逻辑),向无线端设备暴露友好统一的 API,方便无线端设备介入,访问后端服务。说白了就是做数据编排的。
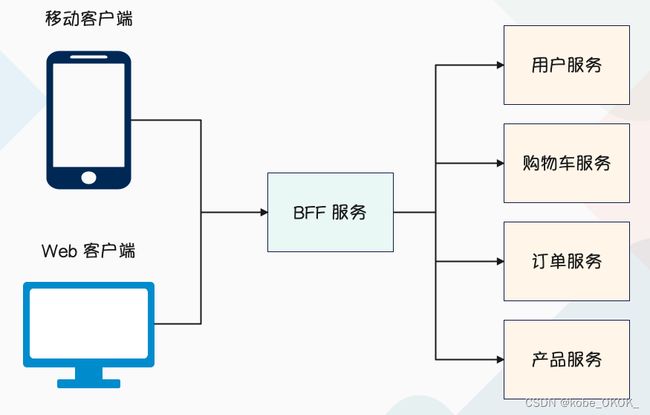
这里再补充一下微服务的分层,微服务一般分为以下几层:
Dao:
数据访问层,封装对数据库的访问,比如增删改查,不涉及业务逻辑,只是按照某个条件获取指定数据并返回。
Service:
专注于业务逻辑的子服务,对于其中需要的数据库操作,都通过 Dao 去实现。
BFF:
用于数据组装,因为一个用户场景需要的数据可能要调用多个微服务,而 BFF 则是针对这些场景将数据组装好,然后直接返回给客户端。也就是说客户端不直接和底层的微服务对接,而是和 BFF 对接,这样就节省了客户端的工作量。
API Gateway:
BFF 是用来调用底层的微服务然后做数据组装的,所以它的业务集成度很高,因为不同业务的公司搭建的微服务肯定是不同的,那么 BFF 所做的事情自然也不一样。但像安全认证、日志监控、熔断限流等等这些逻辑则是通用的,专业的说法叫跨横切面逻辑,也和 BFF 集合在一起了。而这些功能如果要升级,会导致很多的 BFF 也要一起更新,这显然是不合理的,因为 BFF 就是面向业务场景做数据组装的。
于是就引入了网关(API Gateway),把跨横切面的功能可以全部上沉到网关(无状态、无业务逻辑),将业务集成度高的 BFF 层和通用功能服务层进行分层处理。所以网关承担了重要的角色,它是解耦拆分和后续升级迁移的利器。在网关的配合下,单块 BFF 实现了解耦拆分,各业务团队可以独立开发和交互自己的微服务,研发效率大大提升。另外,把跨横切面逻辑从 BFF 上剥离开之后,BFF 的开发人员可以更加专注于业务逻辑交互,实现了架构上的关注分离(Separation of Concerns)。
因此我们的业务流量实际为:移动端 -> 4/7 层负载均衡 -> API Gateway -> BFF -> Mircoservice,网关是所有流量的必经之处,任何流量首先要经过网关。另外 API Gateway 还可以实现监控日志,限流容错等功能。
4 实施产品列表 API
让我们为电子商务商铺的产品页面实现 BFF 模式,在此页面会显示网站上的所有可用产品,以及有关用户购物车和菜单栏中收藏项目的基本信息。为增加销售额,当只有少数商品可被购买时,该页面会发出低库存警告。此外还要展示有关用户最喜欢的产品的信息,以及购物车中的数据。页面模型大致如下:

给定一个具有多个独立服务的微服务架构,需要从每个服务请求适当的数据,并将它们拼接在一起,从而形成一个完整的响应。首先定义需要的基本服务和数据模型,我们总共需要以下服务:
用户收藏服务:该服务将跟踪用户 ID 到他们收藏夹列表中的产品 ID 的映射;
用户购物车服务:该服务将跟踪用户 ID 到他们放入购物车的产品 ID 的映射;
库存服务:该服务将跟踪产品 ID 到该产品的可用库存的映射;
产品服务:包含一些产品信息,例如描述和 sku 等等;
接下来需要实现这些服务来支持 BFF。
4.1 实现基础服务
首先为库存服务实现 FastAPI 应用程序,这是最简单的服务。对于这项服务,我们不会创建单独的数据模型,而是只返回一个 0 到 100 之间的随机数来模拟当前库存。此外在返回的时候,还会添加一个随机延迟来模拟服务间歇性变慢,来演示如何处理产品列表服务中的超时。
"""
文件名: inventory_service.py, 用于实现库存服务
"""
import asyncio
import random
from fastapi import FastAPI, APIRouter
from fastapi.requests import Request
from fastapi.responses import Response
import uvicorn
import orjson
router = APIRouter()
@router.get("/products/{id}/inventory")
async def get_inventory(request: Request):
# 生产中,应该根据 id 去获取库存,但这里我们直接返回一个随机数来模拟
# 所以 product_id 用不上
product_id = request.path_params["id"]
delay = random.randint(0, 5)
await asyncio.sleep(delay)
inventory = random.randint(0, 100)
return Response(orjson.dumps({"inventory": inventory}),
media_type="application/json")
app = FastAPI()
app.include_router(router)
if __name__ == '__main__':
uvicorn.run("inventory_service:app", port=6000)
以上我们就实现了库存服务,非常简单,我们启动起来,并让它监听 6000 端口,一个服务一个进程。
接下来实现用户购物车和用户收藏的服务,两者的数据模型相同,因此服务几乎相同,不同之处在于表名。让我们从’用户购物车’和’用户收藏’这两个数据表模型开始,并往里面插入一些记录。
-- 用户购物车表
CREATE TABLE user_cart (
-- id 应该用整型,但这里为了直观,我们使用字符串
-- 并加上 product_ 、user_ 等前缀,看起来更清晰
user_id VARCHAR(255) NOT NULL,
product_id VARCHAR(255) NOT NULL
);
INSERT INTO user_cart VALUES
("user_001", "product_001"),
("user_001", "product_002"),
("user_001", "product_003"),
("user_002", "product_001"),
("user_002", "product_002"),
("user_002", "product_005");
-- 用户收藏表,和购物车表类似,都负责存储用户 ID 和产品 ID
CREATE TABLE user_favorite (
user_id VARCHAR(255) NOT NULL,
product_id VARCHAR(255) NOT NULL
);
INSERT INTO user_favorite VALUES
("user_001", "product_001"),
("user_001", "product_002"),
("user_001", "product_003"),
("user_003", "product_001"),
("user_003", "product_002"),
("user_003", "product_003");
然后我们在数据库中创建这些表,这里我使用的是我云服务器上的 MySQL。值得一提的是,微服务讲究的是隔离,每个服务要独占一个 DB。这里我为了简便,就不单独创建了,所有表都在 shopping 这个数据库下面。
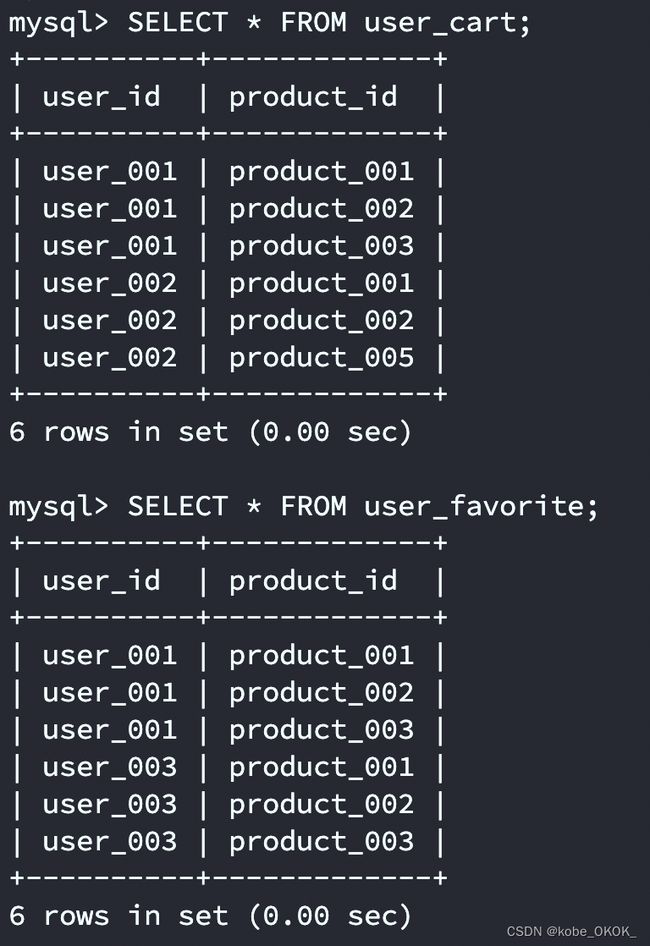
两张表创建完毕,然后我们来实现相关服务,我们首先实现用户收藏服务。
"""
文件名: user_favorite_service.py, 用于实现用户收藏服务
"""
from functools import partial
from fastapi import APIRouter, FastAPI
from fastapi.requests import Request
from fastapi.responses import Response
from sqlalchemy.ext.asyncio import create_async_engine, AsyncEngine
from sqlalchemy import text
from sqlalchemy.engine import URL
import orjson
import uvicorn
router = APIRouter()
async def create_database_engine(app: FastAPI):
engine = create_async_engine(
URL.create("mysql+asyncmy", username="root", password="123456",
host="82.157.146.194", port=3306, database="shopping")
)
app.state.engine = engine
async def destroy_database_engine(app: FastAPI):
engine: AsyncEngine = app.state.engine
await engine.dispose()
@router.get("/users/{id}/favorites")
async def favorites(request: Request):
user_id = request.path_params["id"]
query = text(
"SELECT product_id FROM user_favorite WHERE user_id = :user_id"
).bindparams(user_id=user_id)
engine: AsyncEngine = request.app.state.engine
# 为了简便,这里就不做异常捕获了
async with engine.connect() as conn:
rows = await conn.execute(query)
columns = rows.keys()
results = [dict(zip(columns, row)) for row in rows]
return Response(orjson.dumps(results), media_type="application/json")
app = FastAPI()
app.router.on_startup.append(partial(create_database_engine, app))
app.router.on_shutdown.append(partial(destroy_database_engine, app))
app.include_router(router)
if __name__ == '__main__':
uvicorn.run("user_favorite_service:app", port=6001)
用户收藏服务实现完毕,也很简单,里面的涉及的知识在上一篇文章都学过。然后用户收藏服务,我们监听的是 6001 端口。接下来创建用户购物车服务,和收藏服务相似,主要区别在于和 user_cart 表进行交互。
"""
文件名: user_cart_service.py, 用于实现用户购物车服务
"""
from functools import partial
from fastapi import APIRouter, FastAPI
from fastapi.requests import Request
from fastapi.responses import Response
from sqlalchemy.ext.asyncio import create_async_engine, AsyncEngine
from sqlalchemy import text
from sqlalchemy.engine import URL
import orjson
import uvicorn
router = APIRouter()
async def create_database_engine(app: FastAPI):
engine = create_async_engine(
URL.create("mysql+asyncmy", username="root", password="123456",
host="82.157.146.194", port=3306, database="shopping")
)
app.state.engine = engine
async def destroy_database_engine(app: FastAPI):
engine: AsyncEngine = app.state.engine
await engine.dispose()
@router.get("/users/{id}/cart")
async def favorites(request: Request):
user_id = request.path_params["id"]
query = text(
"SELECT product_id FROM user_cart WHERE user_id = :user_id"
).bindparams(user_id=user_id)
engine: AsyncEngine = request.app.state.engine
async with engine.connect() as conn:
rows = await conn.execute(query)
columns = rows.keys()
results = [dict(zip(columns, row)) for row in rows]
return Response(orjson.dumps(results), media_type="application/json")
app = FastAPI()
app.router.on_startup.append(partial(create_database_engine, app))
app.router.on_shutdown.append(partial(destroy_database_engine, app))
app.include_router(router)
if __name__ == '__main__':
uvicorn.run("user_cart_service:app", port=6002)
最后我们实现产品服务,首先创建一张产品表:product,里面记录产品 ID、产品名称等信息。
CREATE TABLE product (
product_id VARCHAR(255) NOT NULL,
product_name VARCHAR(255) NOT NULL,
price DOUBLE NOT NULL
);
INSERT INTO product VALUES
("product_001", "苹果", 30.0),
("product_002", "香蕉", 25.3),
("product_003", "荔枝", 40.5),
("product_004", "草莓", 45.5),
("product_005", "木瓜", 15.0),
("product_006", "蓝莓", 70.0),
("product_007", "西瓜", 12.0);
然后实现产品服务,这里就不再基于 id 返回了,直接提供一个 /products 接口,访问之后直接将所有商品信息全部返回。
"""
文件名: product_service.py, 用于实现产品服务
"""
from functools import partial
from fastapi import APIRouter, FastAPI
from fastapi.requests import Request
from fastapi.responses import Response
from sqlalchemy.ext.asyncio import create_async_engine, AsyncEngine
from sqlalchemy import text
from sqlalchemy.engine import URL
import orjson
import uvicorn
router = APIRouter()
async def create_database_engine(app: FastAPI):
engine = create_async_engine(
URL.create("mysql+asyncmy", username="root", password="123456",
host="82.157.146.194", port=3306, database="shopping")
)
app.state.engine = engine
async def destroy_database_engine(app: FastAPI):
engine: AsyncEngine = app.state.engine
await engine.dispose()
@router.get("/products")
async def favorites(request: Request):
query = text("SELECT product_id, product_name FROM product")
engine: AsyncEngine = request.app.state.engine
async with engine.connect() as conn:
rows = await conn.execute(query)
columns = rows.keys()
results = [dict(zip(columns, row)) for row in rows]
return Response(orjson.dumps(results), media_type="application/json")
app = FastAPI()
app.router.on_startup.append(partial(create_database_engine, app))
app.router.on_shutdown.append(partial(destroy_database_engine, app))
app.include_router(router)
if __name__ == '__main__':
uvicorn.run("product_service:app", port=6003)
产品服务业实现完毕,代码都是高度相似的,监听的端口是 6003。
4.2 实现BFF服务
基础的微服务实现完毕之后,我们来构建 BFF 服务。我们说 BFF 是做数据组装的,针对不同的用户场景要调用多个下游的子服务。但是服务的响应时间至关重要,因为用户等待的时间越长,他们继续浏览页面的可能性就越小,购买产品的可能性就更小。因此我们构建的 BFF 要尽快向用户返回响应,即使数据没获取完也要返回,具体规则如下:
API 等待产品服务的时间不能超过 1 秒,如果时间超过 1 秒,我们应该响应超时错误(HTTP 代码 504),因此 UI 不会无限期挂起。
用户购物车和收藏夹数据是可选的,如果能在1 秒内处理完毕则最好,但如果不能,我们应该只返回拥有的产品数据。
产品的库存数据也是可选的,如果不能获取它,只需要返回产品数据即可。
可为自己提供一些方法来绕过慢速服务或崩溃,以及其他存在网络问题的服务,这会使得服务以及使用它的用户界面更具弹性。虽然它可能并不总是拥有全部的数据来提供完整的用户体验,但足以创造一种可用的体验,即使结果是产品服务的灾难性失败,也不会让用户陷入无限期的等待中。
接下来定义我们的响应,导航栏所需的只是购物车和收藏夹列表中的商品数量,因此针对它们我们返回一个标量值即可。由于购物车或收藏夹服务可能会超时或出现错误,我们将允许此值为 null。对于产品数据,只需要返回产品 ID、产品名称、库存即可。这意味着将收到类似于以下内容的响应:
{
"cart_items": 1,
"favorite_items": null,
"products": [{"product_id": "product_004", "product_name": "草莓", "inventory": 4},
{"product id": "product_003", "product_name": "荔枝", "inventory": 65}]
}
这种情况下,用户的购物车中有一件商品。而他们可能有最喜欢的商品,但得到的结果却是 null,这是因为访问收藏服务时出现问题。最后,有两种产品要展示,它们的库存分别 4 件和 65 件。
那么应该如何实现这个功能呢?首先肯定需要通过 HTTP 与 REST 服务进行通信,我们可以使用 aiohttp 的 Web 客户端功能或 httpx。然后是如何对它们进行分组并管理超时,首先应该考虑可以同时运行的最多请求,可以同时运行的越多,理论上就可以越快地向客户返回响应。在我们的例子中,不能在获得产品 ID 之前查询库存,因此不能同时运行它,但是产品、购物车和收藏的服务并不相互依赖,这意味着可使用诸如 wait 的异步 API 同时运行它们。使用带有超时的 wait 将提供一个 done 集合,我们可在其中检查哪些请求以错误的方式完成,哪些请求在超时后仍在运行,从而让我们有机会处理所有失败。然后,一旦有了产品 ID 以及用户收藏和购物车数据,就可以将最终响应拼接在一起,并将其发送回客户端。
我们将创建一个端点 /products/all 来执行此操作,以返回相关数据,而不同的用户执行该操作得到的结果显然是不同的,那么用户 ID 体现在什么地方呢?通常我们希望在 URL、请求头或 cookie 中存储用户的 ID 信息,因此我们可以在向下游服务发出请求时使用它。但对于当前来说,为了简单,我们就将用户 ID 硬编码在程序中。
在生产上,会从网关透传一个 token 过来,BFF 会拿着 token 去调用一系列下游子服务。而在子服务中会验证 token,从而拿到用户相关的信息。
"""
文件名: bff_service.py, 数据聚合服务,
用于调用下游的一系列子服务, 然后将数据组装起来
"""
from typing import Dict, Set, Awaitable, Optional
import asyncio
from fastapi import APIRouter, FastAPI
from fastapi.requests import Request
from fastapi.responses import Response
import uvicorn
import orjson
import httpx
INVENTORY_BASE = "http://localhost:6000" # 库存
USER_FAVORITE_BASE = "http://localhost:6001" # 用户收藏
USER_CART_BASE = "http://localhost:6002" # 用户购物车
PRODUCT_BASE = "http://localhost:6003" # 产品
USER_ID = "user_003"
router = APIRouter()
def build_response(data: Dict, status_code) -> Response:
"""基于 data 和 status_code 构建响应体"""
return Response(orjson.dumps(data),
status_code=status_code,
media_type="application/json")
@router.get("/products/all")
async def all_products(request: Request):
async with httpx.AsyncClient() as client:
products = asyncio.create_task(client.get(f"{PRODUCT_BASE}/products"))
favorites = asyncio.create_task(client.get(f"{USER_FAVORITE_BASE}/users/{USER_ID}/favorites"))
cart = asyncio.create_task(client.get(f"{USER_CART_BASE}/users/{USER_ID}/cart"))
tasks = [products, favorites, cart]
# 并行运行三个请求,超时时间为 1 秒
done, pending = await asyncio.wait(tasks, timeout=1.0)
# 如果获取产品信息的任务超时,则直接返回错误
if products in pending:
[task.cancel() for task in tasks]
return build_response({"error": "访问产品服务超时"}, status_code=504)
# 如果获取产品信息的任务执行出错了,同样直接返回错误
if products in done and products.exception() is not None:
[task.cancel() for task in tasks]
return build_response({"error": "访问产品服务出现错误"}, status_code=500)
# 否则说明产品服务访问正常,通过 await products.result() 拿到请求返回的 httpx.Response
# 然后通过 content 得到响应体,并通过 orjson 库解析成字典
# 其实可以直接调用 json() 拿到字典的,但 httpx 在解析的时候使用的是内置的 json 库,效率不高
# 所以我个人更习惯先获取字节流,然后用 orjson 库解析
product_infos = orjson.loads((await products.result()).content) # 所有商品信息
# 将商品传递到 get_product_inventory 协程函数中,获取该商品对应的库存
tasks = [asyncio.create_task(get_product_inventory(client, product_info))
for product_info in product_infos]
_, pending = await asyncio.wait(tasks, timeout=1)
[task.cancel() for task in pending]
# 然后再获取用户购物车和用户收藏
cart_items = await get_items_count(cart, done, pending)
favorite_items = await get_items_count(favorites, done, pending)
return {"cart_items": cart_items, "favorite_items": favorite_items,
"products": product_infos}
# 获取商品对应的库存
async def get_product_inventory(client: httpx.AsyncClient, product_info):
response = await asyncio.create_task(
client.get(f"{INVENTORY_BASE}/products/{product_info['product_id']}/inventory")
)
product_info["inventory"] = orjson.loads(response.content)["inventory"]
# 计算用户购物车的商品数量和用户收藏的商品数量
async def get_items_count(task: asyncio.Task,
done: Set[Awaitable],
pending: Set[Awaitable]) -> Optional[int]:
if task in done and task.exception() is not None:
return len(orjson.loads((await task.result()).content))
elif task in pending:
task.cancel()
else:
print(f"获取信息失败,错误原因:{task.exception()}")
app = FastAPI()
app.include_router(router)
if __name__ == '__main__':
uvicorn.run("bff_service:app", port=6004)
此时 4 个子服务和 1 个 BFF 服务就搭建好了,然后客户端只需要和 BFF 来对接,由 BFF 来调用子服务。所以在生产上,子服务是不对外暴露的,并且服务之前也不使用 HTTP+JSON,而是用 gRPC+protobuf。
我们访问一下试试:
import requests
print(requests.get("http://localhost:6004/products/all").json())
"""
{'error': '访问产品服务超时'}
"""
print(requests.get("http://localhost:6004/products/all").json())
"""
{'cart_items': 0, 'favorite_items': 3,
'products': [{'product_id': 'product_001', 'product_name': '苹果', 'inventory': 100},
{'product_id': 'product_002', 'product_name': '香蕉'},
{'product_id': 'product_003', 'product_name': '荔枝'},
{'product_id': 'product_004', 'product_name': '草莓'},
{'product_id': 'product_005', 'product_name': '木瓜'},
{'product_id': 'product_006', 'product_name': '蓝莓'},
{'product_id': 'product_007', 'product_name': '西瓜'}]}
"""
print(requests.get("http://localhost:6004/products/all").json())
"""
{'cart_items': 0, 'favorite_items': 3,
'products': [{'product_id': 'product_001', 'product_name': '苹果'},
{'product_id': 'product_002', 'product_name': '香蕉'},
{'product_id': 'product_003', 'product_name': '荔枝'},
{'product_id': 'product_004', 'product_name': '草莓', 'inventory': 31},
{'product_id': 'product_005', 'product_name': '木瓜'},
{'product_id': 'product_006', 'product_name': '蓝莓'},
{'product_id': 'product_007', 'product_name': '西瓜'}]}
"""
结果没有任何问题,此时我们算是搭建了一个属于自己的微服务,并且还使用了 BFF。一旦有了 BFF,客户端就只需要调用一次 BFF 提供的接口即可,而不需要亲自调用多个子服务,而且生产上的子服务都是不对外暴露的,即使是客户端也无法访问。
最重要的是,我们将超时时间控制的很好,确保我们无论何时都能快速给出一个合理的响应。虽然我们已经创建了一些相当强大的功能,但仍有一些方法可以使问题更加具有弹性。
4.3 重试失败的请求
如果 BFF 在调用某个子服务时报错了,我们的做法是忽略掉该服务的返回,而是继续往下运行程序。虽然这是有道理的,但服务问题可能只是暂时的,比如导致错误的原因是很快消失的网络故障,或者正在使用的负载均衡器存在临时问题,或者其他的什么临时性问题。这些情况下,重试几次,并在两次重试之间短暂等待是有意义的。这给了一个清理错误的机会,可以给用户提供更多数据。当然这伴随着让用户等待更长时间的代价,虽然重试不一定总会取得成功的结果,但重试绝对是值得尝试的解决方案。
要实现这个功能,wait_for 协程函数是一个完美选择,它会抛出得到的任何异常,并让我们指定超时。如果超过该超时时间,它会抛出 TimeoutException,并取消已经开始的任务。下面让我们尝试创建一个可重用的重试协程函数 retry 来执行此操作,retry 接收一个协程和一个重试次数。如果传入的协程失败或超时,则重试,直到达到我们指定的次数。
import asyncio
from typing import Callable, Awaitable
class TooManyRetries(Exception):
pass
async def retry(coro: Callable[[], Awaitable],
max_retries: int,
timeout: float,
retry_interval: float):
# max_retries 指的是第一次执行失败后重试的最大次数
# 所以协程最多执行 max_retries + 1 次
for retry_num in range(0, max_retries + 1):
try:
# 等待指定超时的响应
return await asyncio.wait_for(coro(), timeout=timeout)
except Exception:
if retry_num < max_retries:
print(f"执行出现异常, 现开启第 {retry_num + 1} 次尝试")
await asyncio.sleep(retry_interval)
raise TooManyRetries()
在代码中,首先创建一个自定义异常类,当重试达到最大次数后仍然失败时,将抛出该异常。这将让任何调用者捕获这个异常,并按他们认为合适的方式处理特定问题。retry 协程需要几个参数:第一个参数是一个返回可等待对象的可调用对象,这是我们要重试的协程;第二个参数是想要重试的次数;第三个参数时执行的超时时间;最后一个参数是失败后等待重试的时间间隔。
然后我们创建一个循环,在 wait_for 中包装协程,如果成功完成,则返回结果并退出函数。如果出现错误、超时或其他情况,则捕获异常并记录它,并休眠指定的时间,在休眠完成后再次重试。如果循环结束时没有对协程进行无错误(error-free)调用,则会引发 TooManyRetries 异常。
我们将上面的 retry 放在 utils.py 中,使用的时候直接导入它即可。
可通过创建几个示例进行测试,第一个示例总是抛出异常,第二个总是超时。
import asyncio
from utils import retry, TooManyRetries
async def always_fail():
raise Exception("我失败了")
async def always_timeout():
await asyncio.sleep(1)
async def main():
try:
await retry(always_fail, max_retries=3, timeout=.1, retry_interval=.1)
except TooManyRetries:
print("重试次数过多")
try:
await retry(always_timeout, max_retries=3, timeout=.1, retry_interval=.1)
except TooManyRetries:
print("重试次数过多")
asyncio.run(main())
"""
执行出现异常, 现开启第 1 次尝试
执行出现异常, 现开启第 2 次尝试
执行出现异常, 现开启第 3 次尝试
重试次数过多
执行出现异常, 现开启第 1 次尝试
执行出现异常, 现开启第 2 次尝试
执行出现异常, 现开启第 3 次尝试
重试次数过多
"""
对于两次重试,将超时和重试间隔定义为 100 毫秒,最大重试次数为 3。这意味着给协程 100 毫秒的时间来完成,如果它在这段时间内没有完成,或者失败,我们会等待 100 毫秒,然后再试一次。运行代码,输出结果和预期的一样。
通过上述代码,可为产品 BFF 添加一些简单的重试逻辑。例如,想在认为错误不可恢复之前重试对产品、购物车和收藏服务的请求,可通过在 retry 协程中包装每个请求来实现这一点。比如对每个服务的请求,最多尝试三次,这使我们能够从可能的临时服务问题中恢复。虽然这是一个改进,但还有潜在的问题可能会损害服务,例如:如果产品服务总是超时,会发生什么?
4.4 断路器模式
实现中仍然存在一个问题,即当服务始终慢到一定程度以至于总是超时,至于原因可能是下游服务负载不足、发生其他网络问题或大量其他应用程序出错时。
你可能会问:"应用程序可以很好地处理超时,用户不会等待超过 1 秒就能看到错误或者获得部分数据,这会有什么问题吗?“你问的没错,然而,虽然已将系统设计得健壮且具有弹性,但也要考虑用户体验。例如,如果购物车服务遇到一个问题,一时半会儿修不好,那么每次访问的结果都是等待 1 秒然后超时,这意味着所有用户要浪费 1 秒才能得到服务的结果。这种情况下,由于购物车服务的这个问题可能会持续一段时间,当我们知道这个问题极可能发生时,任何访问 BFF 服务的用户都将被卡在那里等待 1 秒钟,那么有没有一种方法可以让可能失败的调用"短路”,以免给用户造成不必要的延迟呢?
有一个被称为"断路器模式"的方法可以解决上面提出的问题,在 Michael Nygard 写的 Release It 中介绍了这种模式。通过这种模式,可以让我们"翻转一个断路器",当指定数量的错误在一段时间内发生时,可使用它来绕过缓慢的服务,直到问题被解决,从而确保应用程序依旧可为用户提供良好的使用体验。
与电气断路器非常相似,基本断路器模式有两种与之相关的状态(与电气面板上的普通断路器相同):打开状态和关闭状态。对于关闭状态,向服务发出请求,它正常返同。而打开状态发生在电路跳闸时,这种状态下,不用费心去调用服务,因为我们知道它存在问题,正确的做法是立即返回一个错误。断路器模式阻止向糟糕的服务"供电"。除了这两个状态,还有一个"半开"状态,在某个时间间隔后处于打开状态时,就会发生这种情况。这种状态下,我们发出一个请求,以检查服务问题是否已修复。如果已经修复,我们关闭断路器,如果没有修复,我们保持打开状态。为了使我们的示例简单,这里跳过半开状态,只关注关闭和打开状态,如下图所示:
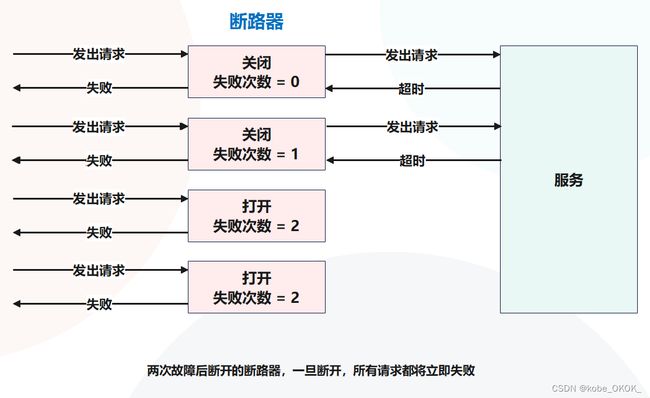
让我们实现一个简单的断路器来了解它是如何工作的,我们将允许使用断路器的用户指定一个时间窗口和最大故障次数。如果在时间窗口内发生的错误超过最大次数,将打开断路器,使其他所有调用都失败。我们将通过一个类来做到这一点,这个类接收我们希望运行的协程,并跟踪断路器是处于打开还是关闭状态。
import asyncio
from datetime import datetime, timedelta
class CircuitOpenException(Exception):
pass
class CircuitBreaker:
def __init__(self, callback,
timeout: float,
time_window: float,
max_failures: int,
reset_interval: float):
# 要执行的协程函数(一般是发起一个请求)
self.callback = callback
# 请求的超时时间
self.timeout = timeout
# 当请求失败时,断路器从关闭到打开所经历的时间
self.time_window = time_window
# 打开断路器之前的 time_window 秒内允许的最大故障次数
self.max_failures = max_failures
# 在没有请求时,断路器自动关闭所需要的时间
self.reset_interval = reset_interval
# 最后一次发出请求的时间
self.last_request_time = None
# 最后一次发出请求(并且失败)的时间
self.last_failure_time = None
# 当前请求的失败次数
self.current_failures = 0
async def request(self, *args, **kwargs):
# 如果当前的失败次数超过了允许失败的最大次数
if self.current_failures >= self.max_failures:
# 如果当前时间距离上一次请求的时间,超过了指定的间隔(reset_interval)
if datetime.now() > self.last_request_time + \
timedelta(seconds=self.reset_interval):
# 那么将开关重置为关闭,当前失败次数重置为 0,并发送请求
self._reset("断路器由打开状态变为关闭状态,发送请求")
return await self._do_request(*args, **kwargs)
else:
# 否则说明距离上一次请求的时间还不长,那么就不要再请求了,因此直接失败
print(f"断路器处于打开状态,请求失败")
raise CircuitOpenException()
# 说明失败次数没有超过允许失败的最大次数
else:
# 如果上一次失败了,并且当前时间距离上一次请求失败的时间,超过了规定时间窗口
if self.last_failure_time and datetime.now() > self.last_failure_time + \
timedelta(seconds=self.time_window):
# 那么依旧对断路器进行重置
self._reset("距离上次失败已经超过了规定的时间窗口")
# 发出请求
print("断路器处于关闭状态,发送请求")
return await self._do_request(*args, **kwargs)
def _reset(self, msg: str):
print(msg)
# 将上次失败的时间重置为 None
self.last_failure_time = None
# 将当前失败的次数重置为 0
self.current_failures = 0
async def _do_request(self, *args, **kwargs):
# 发出请求,记录有多少次失败,以及最后一次失败发生的时间
try:
# 更新上一次请求的时间
self.last_request_time = datetime.now()
return await asyncio.wait_for(
self.callback(*args, **kwargs), timeout=self.timeout)
except Exception as e:
# 请求失败了,那么失败次数 +1
self.current_failures += 1
# 更新请求失败时间
self.last_failure_time = datetime.now()
# 将异常重新抛出去
raise e
我们将上面的代码放在 utils.py 中,后续使用的时候直接导入即可。现在,让我们通过一个简单的示例应用程序来分析断路器。我们创建一个休眠 2 秒的 slow_callback 协程,然后在断路器中使用它,设置一个短暂的超时,这将使断路器很容易被断开。
import asyncio
from utils import CircuitBreaker
async def slow_task():
await asyncio.sleep(2)
async def main():
cb = CircuitBreaker(slow_task, timeout=1.0, time_window=5,
max_failures=2, reset_interval=5)
for _ in range(4):
try:
await cb.request()
except Exception as e:
pass
print(f"等待 5 秒,直到断路器关闭")
await asyncio.sleep(5)
for _ in range(4):
try:
await cb.request()
except Exception as e:
pass
asyncio.run(main())
"""
断路器处于关闭状态,发送请求
断路器处于关闭状态,发送请求
断路器处于打开状态,请求失败
断路器处于打开状态,请求失败
等待 5 秒,直到断路器关闭
断路器由打开状态变为关闭状态,发送请求
断路器处于关闭状态,发送请求
断路器处于打开状态,请求失败
断路器处于打开状态,请求失败
"""
如果你在查看输出的时候,会发现,当请求成功的时候,会有一个 1 秒的时间间隔,因为超时时间是 1 秒钟。而当断路器为关闭状态时,会瞬间返回,因为请求压根就没有得到执行。
现在有了一个简单的实现,可将它与我们的重试逻辑结合起来,并在 BFF 中使用它。由于故意使库存服务变慢,从而模拟真实的延迟服务,因此这是添加断路器的绝佳场所。我们将设置 500 毫秒的超时,并在 1 秒内容忍 5 次失败,之后将在 30 秒后重置断路器。
可以自己测试一下,一旦添加了断路器,你应该会在几次调用后看到产品的 BFF 调用时间在减少。由于正在模拟一个在负载下运行缓慢的库存服务,最终会在几次超时后触发断路器。任何后续调用都不会再向库存服务发出请求,直到断路器重置。面对缓慢且易出错的库存服务,BFF 服务现在更强大,如果需要增加这些调用的稳定性,也可将其应用于其他所有调用。
在这个例子中,实现了一个非常简单的断路器来演示它是如何工作的,以及如何使用 asyncio 构建它。这种模式有几个现有的实现,还有其他许多功能可以调整你的特定需求。如果你正在考虑使用这种模式,请在实现之前花一些时间研究可用的断路器库。
5 总结
与单体架构相比,微服务架构有几个好处,包括但不限于独立的可扩展性和灵活部署特性。
BFF 是一种微服务模式,它聚合了来自多个下游服务的调用。我们已经学习了如何将微服务架构应用到电子商务用例中,如何使用 FastAPI 创建多个独立的服务。
使用 asyncio 实用函数(如 wait)来确保 BFF 服务保持弹性,并对下游服务的故障做出响应。
创建了一个实用程序,管理 HTTP 请求的重试。
实现了一个基本的断路器模式,以确保服务故障不会对其他服务产生负面影响。