Redis-Redis 高级数据结构 HyperLogLog与事务
Redis 高级数据结构 HyperLogLog
HyperLogLog(Hyper [ˈhaɪpə(r)] ) 并不是一种新的数据结构 ( 实际类型为字符串类 型) ,而是一种基数算法 , 通过 HyperLogLog 可以利用极小的内存空间完成独立总数的统计,数据集可以是 IP 、 Email 、 ID 等。
如果你负责开发维护一个大型的网站,有一天产品经理要网站每个网页每天 的 UV 数据,然后让你来开发这个统计模块,你会如何实现?
如果统计 PV 那非常好办,给每个网页一个独立的 Redis 计数器就可以了, 这个计数器的 key 后缀加上当天的日期。这样来一个请求, incrby 一次,最终 就可以统计出所有的 PV 数据。
但是 UV 不一样,它要去重,同一个用户一天之内的多次访问请求只能计 数一次。这就要求每一个网页请求都需要带上用户的 ID ,无论是登陆用户还是 未登陆用户都需要一个唯一 ID 来标识。
一个简单的方案,那就是为每一个页面一个独立的 set 集合来存储所有当 天访问过此页面的用户 ID 。当一个请求过来时,我们使用 sadd 将用户 ID 塞 进去就可以了。通过 scard 可以取出这个集合的大小,这个数字就是这个页面 的 UV 数据。
但是,如果你的页面访问量非常大,比如一个爆款页面几千万的 UV ,你需 要一个很大的 set 集合来统计,这就非常浪费空间。如果这样的页面很多,那 所需要的存储空间是惊人的。为这样一个去重功能就耗费这样多的存储空间,值 得么?其实需要的数据又不需要太精确,1050w 和 1060w 这两个数字对于老板 们来说并没有多大区别,So ,有没有更好的解决方案呢?
这就是 HyperLogLog 的用武之地, Redis 提供了 HyperLogLog 数据结构就是 用来解决这种统计问题的。HyperLogLog 提供不精确的去重计数方案,虽然不精 确但是也不是非常不精确, Redis 官方给出标准误差是 0.81% ,这样的精确度已经 可以满足上面的 UV 统计需求了。
操作命令
HyperLogLog 提供了 3 个命令 : pfadd 、 pfcount 、 pfmerge 。
例如 08-15 的访问用户是 u1 、 u2 、 u3 、 u4 , 08-16 的访问用户是 u-4 、 u-5 、 u-6、 u-7
pfadd
pfadd key element [element …]
pfadd 用于向 HyperLogLog 添加元素 , 如果添加成功返回 1:
pfadd 08-15:u:id "u1" "u2" "u3" "u4"
pfcount
pfcount key [key …]
pfcount 用于计算一个或多个 HyperLogLog 的独立总数,例如 08-15:u:id 的独
立总数为 4:
pfcount 08-15:u:id
如果此时向插入 u1 、 u2 、 u3 、 u90 ,结果是 5:
pfadd 08-15:u:id "u1" "u2" "u3" "u90"
pfcount 08-15:u:id
如果我们继续往里面插入数据,比如插入 100 万条用户记录。内存增加非常
少,但是 pfcount 的统计结果会出现误差。
以使用集合类型和 HperLogLog 统计百万级用户访问次数的占用空间对比:
数据类型 1 天 1 个月 1 年
集合类型 80M 2.4G 28G
HyperLogLog 15k 450k 5M
可以看到, HyperLogLog 内存占用量小得惊人,但是用如此小空间来估算如
此巨大的数据,必然不是 100% 的正确,其中一定存在误差率。前面说过, Redis
官方给出的数字是 0.81% 的失误率。
pfmerge
pfmerge destkey sourcekey [sourcekey ... ]
pfmerge 可以求出多个 HyperLogLog 的并集并赋值给 destkey ,请自行测试。
原理概述
数学原理
HyperLogLog 基于概率论中伯努利试验并结合了极大似然估算方法,并做了
分桶优化。
实际上目前还没有发现更好的在大数据场景中准确计算基数的高效算法,因
此在不追求绝对准确的情况下,使用概率算法算是一个不错的解决方案。概率算
法不直接存储数据集合本身,通过一定的概率统计方法预估值,这种方法可以大
大节省内存,同时保证误差控制在一定范围内。目前用于基数计数的概率算法包
括 :
Linear Counting(LC) :早期的基数估计算法, LC 在空间复杂度方面并不算优
秀;
LogLog Counting(LLC) : LogLog Counting 相比于 LC 更加节省内存,空间复杂
度更低;
HyperLogLog Counting(HLL) : HyperLogLog Counting 是基于 LLC 的优化和改进,
在同样空间复杂度情况下,能够比 LLC 的基数估计误差更小。 举个例子来理解 HyperLogLog 算法,有一天 Fox 老师和 Mark 老师玩抛硬币
的游戏,规则是 Mark 老师负责抛硬币,每次抛的硬币可能正面,可能反面,每
当抛到正面为一回合, Mark 老师可以自己决定进行几个回合。最后需要告诉 Fox
老师最长的那个回合抛了多少次以后出现了正面,再由 Fox 老师来猜 Mark 老师
一共进行了几个回合。
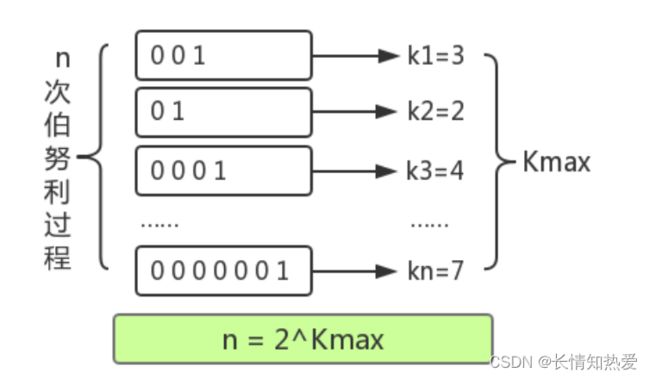
进行了 n 次,比如上图:
第一次 : 抛了 3 次才出现正面,此时 k=3 , n=1
第二次试验 : 抛了 2 次才出现正面,此时 k=2 , n=2
第三次试验 : 抛了 4 次才出现正面,此时 k=4 , n=3
…………
第 n 次试验:抛了 7 次才出现正面,此时我们估算, k=7 , n=n
k 是每回合抛到 1 (硬币的正面)所用的次数,我们已知的是最大的 k 值,
也就是 Mark 老师告诉 Fox 老师的数,可以用 k_max 表示。由于每次抛硬币的结
果只有 0 和 1 两种情况,因此,能够推测出 k_max 在任意回合出现的概率 ,并
由 kmax 结合极大似然估算的方法推测出 n 的次数 n = 2^(k_max) 。概率学把这
种问题叫做伯努利实验。
现在 Mark 老师已经完成了 n 个回合,并且告诉 Fox 老师最长的一次抛了 4
次, Fox 老师此时也胸有成竹,马上说出他的答案 16 ,最后的结果是: Mark 老
师只抛了 3 回合,
这三个回合中 k_max=4 ,放到公式中, Fox 老师算出 n=2^4 ,于是推测 Mark
老师抛了 16 个回合,但是 Fox 老师输了,要负责买奶茶一个星期。
所以这种预估方法存在较大误差,为了改善误差情况, HLL 中引入分桶平均
的概念。
同样举抛硬币的例子,如果只有一组抛硬币实验,显然根据公式推导得到的
实验次数的估计误差较大;如果 100 个组同时进行抛硬币实验,样本数变大,受
运气影响的概率就很低了,每组分别进行多次抛硬币实验,并上报各自实验过程
中抛到正面的抛掷次数的最大值,就能根据 100 组的平均值预估整体的实验次数
了。 分桶平均的基本原理是将统计数据划分为 m 个桶,每个桶分别统计各自的
k_max, 并能得到各自的基数预估值,最终对这些基数预估值求平均得到整体的
基数估计值。 LLC 中使用几何平均数预估整体的基数值,但是当统计数据量较小
时误差较大; HLL 在 LLC 基础上做了改进,采用调和平均数过滤掉不健康的统计
值。
什么叫调和平均数呢?举个例子
求平均工资:
A 的是 1000/ 月, B 的 30000/ 月。采用平均数的方式就是: (1000
+ 30000) / 2 = 15500
采用调和平均数的方式就是: 2/(1/1000 + 1/30000) ≈ 1935.484
可见调和平均数比平均数的好处就是不容易受到大的数值的影响,比平均数
的效果是要更好的。
结合实例理解实现原理
现在我们和前面的业务场景进行挂钩:统计网页每天的 UV 数据。
1.转为比特串
通过 hash 函数,将数据转为比特串,例如输入 5 ,便转为: 101 ,字符串也
是一样。为什么要这样转化呢?
是因为要和抛硬币对应上,比特串中,0 代表了反面, 1 代表了正面,如果
一个数据最终被转化了 10010000 ,那么从右往左,从低位往高位看,我们可以
认为,首次出现 1 的时候,就是正面。
那么基于上面的估算结论,我们可以通过多次抛硬币实验的最大抛到正面的
次数来预估总共进行了多少次实验,同样也就可以根据存入数据中,转化后的出
现了 1 的最大的位置 k_max 来估算存入了多少数据。
2.分桶
分桶就是分多少轮。抽象到计算机存储中去,存储的是一个长度为 L 的位
(bit) 大数组 S ,将 S 平均分为 m 组,这个 m 组,就是对应多少轮,然后每
组所占有的比特个数是平均的,设为 P 。容易得出下面的关系:
L = S.length
L = m * p
以 K 为单位, S 占用的内存 = L / 8 / 1024
3、对应
假设访问用户 id 为: idn , n->0,1,2,3....
在这个统计问题中,不同的用户 id 标识了一个用户,那么我们可以把用户
的 id 作为被 hash 的输入。即:
hash(id) = 比特串
不同的用户 id ,拥有不同的比特串。每一个比特串,也必然会至少出现一
次 1 的位置。我们类比每一个比特串为一次伯努利试验。
现在要分轮,也就是分桶。所以我们可以设定,每个比特串的前多少位转为
10 进制后,其值就对应于所在桶的标号。假设比特串的低两位用来计算桶下标 志,总共有 4 个桶,此时有一个用户的 id 的比特串是: 10010110000 11 。它的所
在桶下标为: 1*2^1 + 1*2^0 = 3 ,处于第 3 个桶,即第 3 轮中。
上面例子中,计算出桶号后,剩下的比特串是: 100101 1 0000 ,从低位到高
位看,第一次出现 1 的位置是 5 。也就是说,此时第 3 个桶中, k_max = 5 。 5
对应的二进制是: 101 ,将 101 存入第 3 个桶。
模仿上面的流程,多个不同的用户 id ,就被分散到不同的桶中去了,且每
个桶有其 k_max 。然后当要统计出某个页面有多少用户点击量的时候,就是一
次估算。最终结合所有桶中的 k_max ,代入估算公式,便能得出估算值。
Redis 中的 HyperLogLog 实现
Redis 的实现中, HyperLogLog 占据 12KB( 占用内存为 =16834 * 6 / 8 / 1024 =
12K) 的大小,共设有 16384 个桶,即: 2^14 = 16384 ,每个桶有 6 位,每个桶
可以表达的最大数字是: 25+24+...+1 = 63 ,二进制为: 111 111 。
对于命令: pfadd key value
在存入时, value 会被 hash 成 64 位,即 64 bit 的比特字符串,前 14 位
用来分桶,剩下 50 位用来记录第一个 1 出现的位置。
之所以选 14 位 来表达桶编号是因为分了 16384 个桶,而 2^14 = 16384 ,
刚好地,最大的时候可以把桶利用完,不造成浪费。假设一个字符串的前 14 位
是: 00 0000 0000 0010 ( 从右往左看 ) ,其十进制值为 2 。那么 value 对应转化
后的值放到编号为 2 的桶。
index 的转化规则:
首先因为完整的 value 比特字符串是 64 位形式,减去 14 后,剩下 50 位,
假设极端情况,出现 1 的位置,是在第 50 位,即位置是 50 。此时 index = 50 。
此时先将 index 转为 2 进制,它是: 110010 。
因为 16384 个桶中,每个桶是 6 bit 组成的。于是 110010 就被设置到了
第 2 号桶中去了。请注意, 50 已经是最坏的情况,且它都被容纳进去了。那么
其他的不用想也肯定能被容纳进去。
因为 fpadd 的 key 可以设置多个 value 。例如下面的例子:
pfadd lgh golang
pfadd lgh python
pfadd lgh java
根据上面的做法,不同的 value ,会被设置到不同桶中去,如果出现了在同
一个桶的,即前 14 位值是一样的,但是后面出现 1 的位置不一样。那么比较
原来的 index 是否比新 index 大。是,则替换。否,则不变。
最终地,一个 key 所对应的 16384 个桶都设置了很多的 value 了,每个
桶有一个 k_max 。此时调用 pfcount 时,按照调和平均数进行估算,同时加以偏
差修正,便可以计算出 key 的设置了多少次 value ,也就是统计值,具体的估算
公式如下:
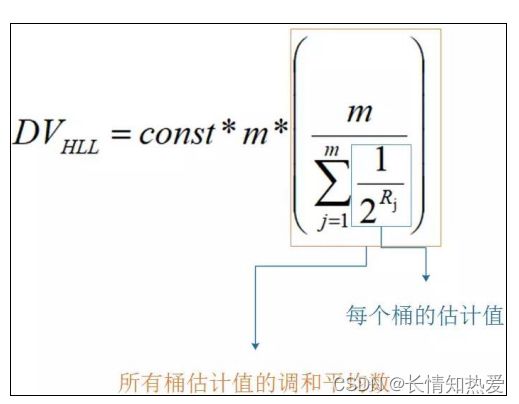
value 被转为 64 位的比特串,最终被按照上面的做法记录到每个桶中去。
64 位转为十进制就是: 2^64 , HyperLogLog 仅用了: 16384 * 6 /8 / 1024 =12K 存
储空间就能统计多达 2^64 个数。
同时,在具体的算法实现上, HLL 还有一个分阶段偏差修正算法。我们就不
做更深入的了解了。
事务
Redis 事务
大家应该对事务比较了解,简单地说,事务表示一组动作,要么全部执行,
要么全部不执行。例如在社交网站上用户 A 关注了用户 B ,那么需要在用户 A 的
关注表中加入用户 B ,并且在用户 B 的粉丝表中添加用户 A ,这两个行为要么全
部执行,要么全部不执行 , 否则会出现数据不一致的情况。
Redis 提供了简单的事务功能,将一组需要一起执行的命令放到 multi 和 exec
两个命令之间。 multi( ['mʌlti]) 命令代表事务开始, exec( 美 [ɪɡˈzek] ) 命令代表事务结
束,如果要停止事务的执行,可以使用 discard 命令代替 exec 命令即可。
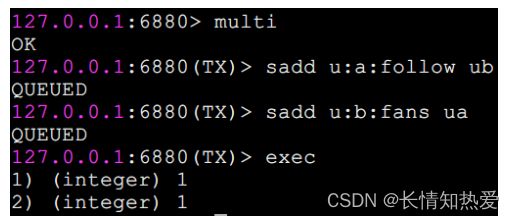
它们之间的命令是原子顺序执行的, 例如下面操作实现了上述用户关注问题。

可以看到 sadd 命令此时的返回结果是 QUEUED ,代表命令并没有真正执行,
而是暂时保存在 Redis 中的一个缓存队列(所以 discard 也只是丢弃这个缓存队
列中的未执行命令,并不会回滚已经操作过的数据,这一点要和关系型数据库的
Rollback 操作区分开)。如果此时另一个客户端执行 sismember u:a:follow ub 返
回结果应该为 0 。

只有当 exec 执行后,用户 A 关注用户 B 的行为才算完成,如下所示 exec 返
回的两个结果对应 sadd 命令。
另一个客户端:

如果事务中的命令出现错误 ,Redis 的处理机制也不尽相同。
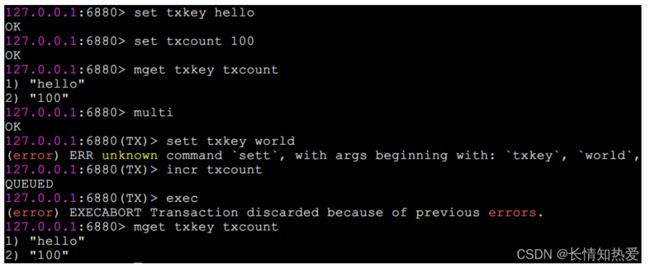
1 、命令错误
例如下面操作错将 set 写成了 sett ,属于语法错误,会造成整个事务无法执
行, key 和 counter 的值未发生变化 :
2. 运行时错误
例如用户 B 在添加粉丝列表时,误把 sadd 命令 ( 针对集合 ) 写成了 zadd 命令 ( 针
对有序集合 ) ,这种就是运行时命令,因为语法是正确的 :
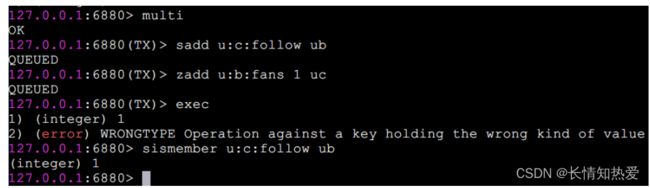
可以看到 Redis 并不支持回滚功能, sadd u:c:follow ub 命令已经执行成功 , 开发人员需要自己修复这类问题。
有些应用场景需要在事务之前,确保事务中的 key 没有被其他客户端修改过,
才执行事务,否则不执行 ( 类似乐观锁 ) 。 Redis 提供了 watch 命令来解决这类问
题。
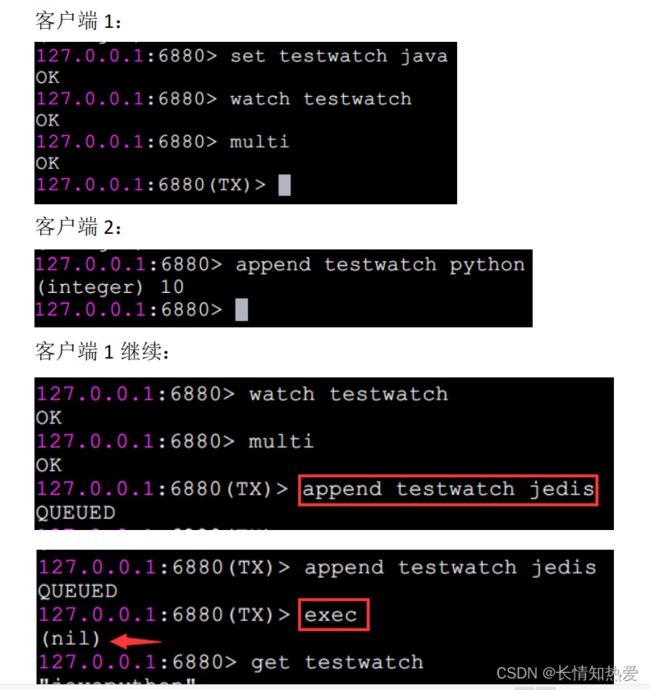
可以看到“客户端 -1 ”在执行 multi 之前执行了 watch 命令,“客户端 -2 ”
在“客户端 -1 ”执行 exec 之前修改了 key 值,造成客户端 -1 事务没有执行 (exec
结果为 nil) 。
Redis 客户端中的事务使用代码参见:
cn.tuling.redis.adv.RedisTransaction
Pipeline 和事务的区别
简单来说,
1、 pipeline 是客户端的行为,对于服务器来说是透明的,可以认为服务器无
法区分客户端发送来的查询命令是以普通命令的形式还是以 pipeline 的形式发送
到服务器的;
2 而事务则是实现在服务器端的行为,用户执行 MULTI 命令时,服务器会将
对应这个用户的客户端对象设置为一个特殊的状态,在这个状态下后续用户执行
的查询命令不会被真的执行,而是被服务器缓存起来,直到用户执行 EXEC 命令
为止,服务器会将这个用户对应的客户端对象中缓存的命令按照提交的顺序依次
执行。
3、应用 pipeline 可以提服务器的吞吐能力,并提高 Redis 处理查询请求的能
力。
但是这里存在一个问题,当通过 pipeline 提交的查询命令数据较少,可以被
内核缓冲区所容纳时, Redis 可以保证这些命令执行的原子性。然而一旦数据量
过大,超过了内核缓冲区的接收大小,那么命令的执行将会被打断,原子性也就
无法得到保证。因此 pipeline 只是一种提升服务器吞吐能力的机制,如果想要命
令以事务的方式原子性的被执行,还是需要事务机制,或者使用更高级的脚本功
能以及模块功能。
4、可以将事务和 pipeline 结合起来使用,减少事务的命令在网络上的传输
时间,将多次网络 IO 缩减为一次网络 IO 。
Redis 提供了简单的事务,之所以说它简单,主要是因为它不支持事务中的
回滚特性 , 同时无法实现命令之间的逻辑关系计算,当然也体现了 Redis 的“ keep
it simple ”的特性。
Redis 7.0 前瞻
2022 年 2 月初, Redis 7.0 迎来了首个候选发布( RC )版本。这款内存键值
数据库迎来了“重大的性能优化”和其它功能改进,性能优化包括降低写入时复
制内存的开销、提升内存效率,改进 fsync 来避免大量的磁盘写入和优化延迟表
现。
Redis 7.0-rc1 的其它一些变动,包括将“ Redis 函数”作为新的服务器端脚
本功能,细粒度 / 基于键的权限、改进子命令处理 / Lua 脚本 / 各种新命令。
此外也提供了一些安全改进。
我们从分析 Redis 主从复制中的内存消耗过多和堵塞问题,以及 Redis 7.0
( 尚未发布 ) 的共享复制缓冲区方案是如何解决这些问题的。
Redis 主从复制原理
我们先简单回顾一下 Redis 主从复制的基本原理。 Redis 的主从复制主要分
为两种情况:
全量同步
主库通过 fork 子进程产生内存快照,然后将数据序列化为 RDB 格式同步
到从库,使从库的数据与主库某一时刻的数据一致。
命令传播
当从库与主库完成全量同步后,进入命令传播阶段,主库将变更数据的命令
发送到从库,从库将执行相应命令,使从库与主库数据持续保持一致。
Redis 复制缓存区相关问题分析
多从库时主库内存占用过多

如上图所示,对于 Redis 主库,当用户的写请求到达时,主库会将变更命
令分别写入所有从库复制缓冲区( OutputBuffer) ,以及复制积压区
(ReplicationBacklog) 。全量同步时依然会执行该逻辑,所以在全量同步阶段经常
会触发 client-output-buffer-limit ,主库断开与从库的连接,导致主从同步失败,
甚至出现循环持续失败的情况。
该实现一个明显的问题是内存占用过多,所有从库的连接在主库上是独立的,
也就是说每个从库 OutputBuffer 占用的内存空间也是独立的,那么主从复制消
耗的内存就是所有从库缓冲区内存大小之和。如果我们设定从库的
client-output-buffer-limit 为 1GB ,如果有三个从库,则在主库上可能会消耗 3GB
的内存用于主从复制。另外,真实环境中从库的数量不是确定的,这也导致 Redis
实例的内存消耗不可控。
OutputBuffer 拷贝和释放的堵塞问题
Redis 为了提升多从库全量复制的效率和减少 fork 产生 RDB 的次数,会尽
可能的让多个从库共用一个 RDB ,从代码 (replication.c) 上看: 当已经有一个从库触发 RDB BGSAVE 时,后续需要全量同步的从库会共享
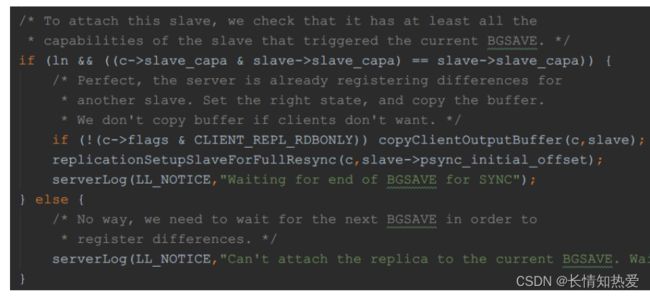
这次 BGSAVE 的 RDB ,为了从库复制数据的完整性,会将之前从库的
OutputBuffer 拷贝到请求全量同步从库的 OutputBuffer 中。
其中的 copyClientOutputBuffer 可能存在堵塞问题,因为 OutputBuffer 链表
上的数据可达数百 MB 甚至数 GB 之多,对其拷贝可能使用百毫秒甚至秒级的
时间,而且该堵塞问题没法通过日志或者 latency 观察到,但对 Redis 性能影响
却很大。
同样地,当 OutputBuffer 大小触发 limit 限制时, Redis 就是关闭该从库链
接,而在释放 OutputBuffer 时,也需要释放数百 MB 甚至数 GB 的数据,其耗
时对 Redis 而言也很长。
ReplicationBacklog 的限制
我们知道复制积压缓冲区 ReplicationBacklog 是 Redis 实现部分重同步的
基础,如果从库可以进行增量同步,则主库会从 ReplicationBacklog 中拷贝从库
缺失的数据到其 OutputBuffer 。拷贝的数据量最大当然是 ReplicationBacklog 的
大小,为了避免拷贝数据过多的问题,通常不会让该值过大,一般百兆左右。但
在大容量实例中,为了避免由于主从网络中断导致的全量同步,又希望该值大一
些,这就存在矛盾了。
而且如果重新设置 ReplicationBacklog 大小时,会导致 ReplicationBacklog
中的内容全部清空,所以如果在变更该配置期间发生主从断链重连,则很有可能
导致全量同步。
Redis7.0 共享复制缓存区的设计与实现
简述
每个从库在主库上单独拥有自己的 OutputBuffer ,但其存储的内容却是一样
的,一个最直观的想法就是主库在命令传播时,将这些命令放在一个全局的复制
数据缓冲区中,多个从库共享这份数据,不同的从库对引用复制数据缓冲区中不
同的内容,这就是『共享复制缓存区』方案的核心思想。实际上,复制积压缓冲
区( ReplicationBacklog )中的内容与从库 OutputBuffer 中的数据也是一样的,所 以该方案中, ReplicationBacklog 和从库一样共享一份复制缓冲区的数据,也避
免了 ReplicationBacklog 的内存开销。
『共享复制缓存区』方案中复制缓冲区 (ReplicationBuffer) 的表示采用链表
的表示方法,将 ReplicationBuffer 数据切割为多个 16KB 的数据块
(replBufBlock) ,然后使用链表来维护起来。为了维护不同从库的对
ReplicationBuffer 的使用信息,在 replBufBlock 中存在字段:
refcount : block 的引用计数
id : block 的唯一标识,单调递增的数值
repl_offset : block 开始的复制偏移
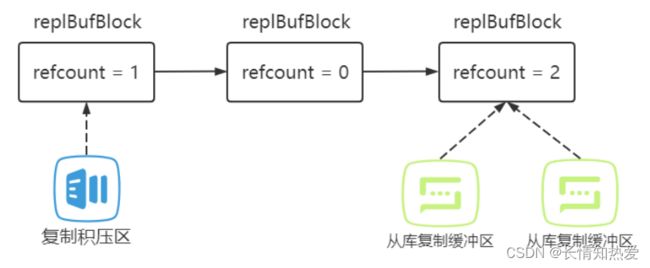
ReplicationBuffer 由多个 replBufBlock 组成链表,当 复制积压区 或从库对
某个 block 使用时,便对正在使用的 replBufBlock 增加引用计数,上图中可以
看到,复制积压区正在使用的 replBufBlock refcount 是 1 ,从库 A 和 B 正在使
用的 replBufBlock refcount 是 2 。当从库使用完当前的 replBufBlock (已经将数
据发送给从库)时,就会对其 refcount 减 1 而且移动到下一个 replBufBlock ,
并对其 refcount 加 1 。
堵塞问题和限制问题的解决
多从库消耗内存过多的问题通过共享复制缓存区方案得到了解决,对于
OutputBuffer 拷贝和释放的堵塞问题和 ReplicationBacklog 的限制问题是否解决
了呢?
首先来看 OutputBuffer 拷贝和释放的堵塞问题问题, 这个问题很好解决,
因为 ReplicationBuffer 是个链表实现,当前从库的 OutputBuffer 只需要维护共
享 ReplicationBuffer 的引用信息即可。所以无需进行数据深拷贝,只需要更新引
用信息,即对正在使用的 replBufBlock refcount 加 1 ,这仅仅是一条简单的赋值
操作,非常轻量。 OutputBuffer 释放问题呢?在当前的方案中释放从库
OutputBuffer 就变成了对其正在使用的 replBufBlock refcount 减 1 ,也是一条赋
值操作,不会有任何阻塞。
对于 ReplicationBacklog 的限制问题也很容易解决了,因为
ReplicatonBacklog 也只是记录了对 ReplicationBuffer 的引用信息,对
ReplicatonBacklog 的拷贝也仅仅成了找到正确的 replBufBlock ,然后对其
refcount 加 1 。这样的话就不用担心 ReplicatonBacklog 过大导致的拷贝堵塞问
题。而且对 ReplicatonBacklog 大小的变更也仅仅是配置的变更,不会清掉数据。 ReplicationBuffer 的裁剪和释放
ReplicationBuffer 不可能无限增长, Redis 有相应的逻辑对其进行裁剪,简
单来说, Redis 会从头访问 replBufBlock 链表,如果发现 replBufBlock refcount
为 0 ,则会释放它,直到迭代到第一个 replBufBlock refcount 不为 0 才停止。
所以想要释放 ReplicationBuffer ,只需要减少相应 ReplBufBlock 的 refcount ,会
减少 refcount 的主要情况有:
1、当从库使用完当前的 replBufBlock 会对其 refcount 减 1 ;
2、当从库断开链接时会对正在引用的 replBufBlock refcount 减 1 ,无论是
因为超过 client-output-buffer-limit 导致的断开还是网络原因导致的断开;
3、当 ReplicationBacklog 引用的 replBufBlock 数据量超过设置的该值大小
时,会对正在引用的 replBufBlock refcount 减 1 ,以尝试释放内存;
不过当一个从库引用的 replBufBlock 过多,它断开时释放的 replBufBlock
可能很多,也可能造成堵塞问题,所以 Redis7 里会限制一次释放的个数,未及
时释放的内存在系统的定时任务中渐进式释放。
数据结构的选择
当从库尝试与主库进行增量重同步时,会发送自己的 repl_offset ,主库在每
个 replBufBlock 中记录了该其第一个字节对应的 repl_offset ,但如何高效地从
数万个 replBufBlock 的链表中找到特定的那个?
从链表的性质我们知道,链表只能直接从头到位遍历链表查找对应的
replBufBlock ,这个操作必然会耗费较多时间而堵塞服务。有什么改进的思路?
可以额外使用一个链表用于索引固定区间间隔的 replBufBlock ,每 1000 个
replBufBlock 记录一个索引信息,当查找 repl_offset 时,会先从索引链表中查
起,然后再查找 replBufBlock 链表,这个就类似于跳表的查找实现。 Redis 的 zset
就是跳表的实现:
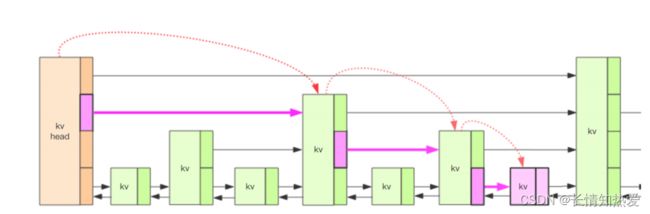
在极端场景下可能会查找超过千次,有 10 毫秒以上的延迟,所以 Redis 7
没有使用这种数据结构。
最终使用 rax 树实现了对 replBufBlock 固定区间间隔的索引,每 64 个记
录一个索引点。一方面, rax 索引占用的内存较少;另一方面,查询效率也是非
常高,理论上查找比较次数不会超过 100 ,耗时在 1 毫秒以内。 rax 树
Redis 中还有其他地方使用了 Rax 树,比如我们前面学习过的 streams 这个
类型里面的 consumer group( 消费者组 ) 的名称还有和 Redis 集群名称存储。
RAX 叫做基数树(前缀压缩树),就是有相同前缀的字符串,其前缀可以作
为一个公共的父节点,什么又叫前缀树?
Trie 树
即字典树,也有的称为前缀树,是一种树形结构。广泛应用于统计和排序大
量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
它的优点是最大限度地减少无谓的字符串比较,查询效率比较高。
Trie 的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开
销以达到提高效率的目的。
先看一下几个场景问题:
1.我们输入 n 个单词,每次查询一个单词,需要回答出这个单词是否在之前
输入的 n 单词中出现过。
答:当然是用 map 来实现。
2.我们输入 n 个单词,每次查询一个单词的前缀,需要回答出这个前缀是之
前输入的 n 单词中多少个单词的前缀?
答:还是可以用 map 做,把输入 n 个单词中的每一个单词的前缀分别存入
map 中,然后计数,这样的话复杂度会非常的高。若有 n 个单词,平均每个单词
的长度为 c,那么复杂度就会达到 nc。
因此我们需要更加高效的数据结构,这时候就是 Trie 树的用武之地了。现在
我们通过例子来理解什么是 Trie 树。现在我们对 cat 、 cash 、 apple 、 aply 、 ok 这
几个单词建立一颗 Trie 树。
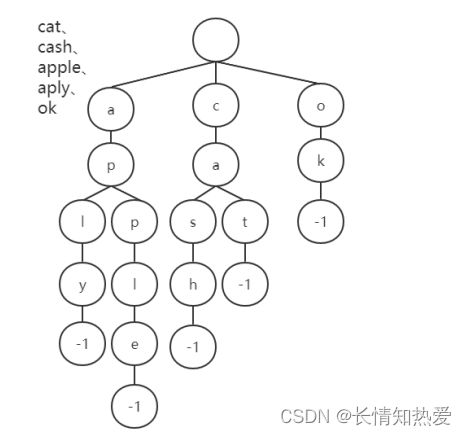
从图中可以看出:
1. 每一个节点代表一个字符
2. 有相同前缀的单词在树中就有公共的前缀节点。
3. 整棵树的根节点是空的。
4. 每个节点结束的时候用一个特殊的标记来表示,这里我们用 -1 来表示结束, 从根节点到-1 所经过的所有的节点对应一个英文单词。
5. 查询和插入的时间复杂度为 O(k) , k 为字符串长度,当然如果大量字符串 没有共同前缀时还是很耗内存的。
所以,总的来说,Trie 树把很多的公共前缀独立出来共享了。这样避免了很
多重复的存储。想想字典集的方式,一个个的 key 被单独的存储,即使他们都有
公共的前缀也要单独存储。相比字典集的方式, Trie 树显然节省更多的空间。
Trie 树其实依然比较浪费空间,比如我们前面所说的“然如果大量字符串没
有共同前缀时”。
比如这个字符串列表:"deck", "did", "doe", "dog", "doge" , "dogs" 。 "deck" 这
一个分支,有没有必要一直往下来拆分吗?还是 "did" ,存在着一样的问题。像这
样的不可分叉的单支分支,其实完全可以合并,也就是压缩。
Radix 树:压缩后的 Trie 树
所以 Radix 树就是压缩后的 Trie 树,因此也叫压缩 Trie 树。比如上面的字符
串列表完全可以这样存储:
同时在具体存储上, Radix 树的处理是以 bit (或二进制数字)来读取的。一
次被对比 r 个 bit 。
比如 "dog", "doge" , "dogs" ,按照人类可读的形式, dog 是 dogs 和 doge 的子
串。
但是如果按照计算机的二进制比对:
dog: 01100100 01101111 01100111
doge: 01100100 01101111 01100111 011 0 0101
dogs: 01100100 01101111 01100111 011 1 0011
可以发现 dog 和 doge 是在第二十五位的时候不一样的。 dogs 和 doge 是在
第二十八位不一样的,按照位的比对的结果, doge 是 dogs 二进制子串,这样在
存储时可以进一步压缩空间。