volatile关键字引入(CPU缓存模型,数据一致性,java内存模型)
自Java 1.5版本起,volatile关键字所扮演的角色越来越重要,该关键字也成为并发包的基础,所有的原子数据类型都以此作为修饰,相比synchronized关键字,volatile被称为“轻量级锁”,能实现部分synchronized关键字的语义。
volatile是一个非常重要的关键字,虽然看起来很简单,但是想要彻底弄清楚volatile的来龙去脉还是需要具备Java内存模型、CPU缓存模型等知识的
文章目录
-
- 1 初识volatile关键字
-
- 1.1 入门程序
- 2 CPU Cache模型
-
- 2.1 CPU缓存一致性问题
- 3 Java内存模型
1 初识volatile关键字
1.1 入门程序
public class VolatileFoo {
final static int MAX = 5;
static int init_value = 0;
public static void main(String[] args) {
// 启动一个Reader线程,当发现local_value和init_value不同时,则输出init_value被修改的信息
new Thread(() -> {
int localValue = init_value;
while (localValue < MAX) {
if (init_value != localValue) {
System.out.println("The init_value is update to " + init_value);
//对localValue进行重新赋值
localValue = init_value;
}
}
}, "Reader").start();
// 启动Writer线程,主要用于对init_value的修改,当local_value>=5的时候则退出生命周期
new Thread(() -> {
int localValue = init_value;
while (localValue < MAX) {
System.out.println("The init_value will be changed to " + (++localValue));
init_value = localValue;
try {
//短暂休眠,目的是为了使Reader线程能够来得及输出变化内容
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "Writer").start();
}
}
上面的代码 定义两个线程一个线程负责读取数据,一个线程负责修改数据,运行之后发现:
The init_value will be changed to 1
The init_value is update to 1
The init_value will be changed to 2
The init_value will be changed to 3
The init_value will be changed to 4
The init_value will be changed to 5
并不是期望的结果:Writer线程的每一次修改都会使得Reader线程进行一次输出,Reader线程压根就没有感知到init_value的变化而进入了死循环。这里是存在线程安全问题的,存在INII_VALUE这个共享变量
现在就轮到volatile关键字出场了,使用volatile关键字修饰一下INII_VALUE这个共享变量
volatile static int init_value = 0;
在测试就会的发现,满足我们期望的结果:
The init_value will be changed to 1
The init_value is update to 1
The init_value will be changed to 2
The init_value is update to 2
The init_value will be changed to 3
The init_value is update to 3
The init_value will be changed to 4
The init_value is update to 4
The init_value will be changed to 5
The init_value is update to 5
2 CPU Cache模型
在介绍volatile关键字之前,先介绍一下CPU 的缓存模型
在计算机中,所有的运算操作都是由CPU的寄存器来完成的,CPU指令的执行过程需要涉及数据的读取和写入操作,CPU所能访问的所有数据只能是计算机的主存(通常是指RAM),虽然CPU的发展频率不断地得到提升,但受制于制造工艺以及成本等的限制,计算机的内存反倒在访问速度上并没有多大的突破,因此CPU的处理速度和内存的访问速度之间的差距越拉越大,通常这种差距可以达到上千倍,极端情况下甚至会在上万倍以上。
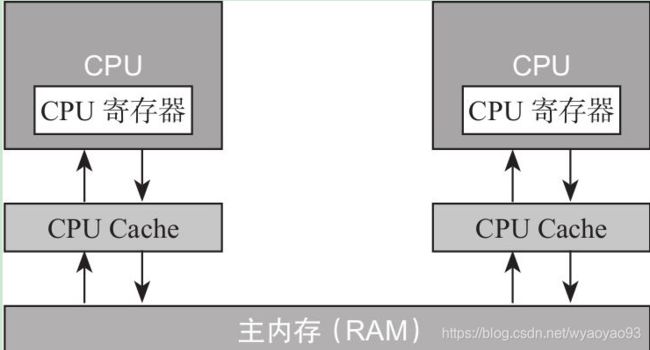
由于两边速度严重的不对等,通过传统FSB直连内存的访问方式很明显会导致CPU资源受到大量的限制,降低CPU整体的吞吐量,于是就有了在CPU和主内存之间增加缓存的设计,现在缓存的数量都可以增加到3级了,最靠近CPU的缓存称为L1,然后依次是L2,L3和主内存,CPU缓存模型如图所示:

由于程序指令和程序数据的行为和热点分布差异很大,因此L1 Cache又被划分成了L1i(i是instruction的首字母)和L1d(d是data的首字母)这两种有各自专门用途的缓存,CPU Cache又是由很多个Cache Line构成的,Cache Line可以认为是CPU Cache中的最小缓存单位,目前主流CPU Cache的Cache Line大小都是64字节
Cache的出现是为了解决CPU直接访问内存效率低下问题的,程序在运行的过程中,会将运算所需要的数据从主存复制一份到CPU Cache中,这样CPU进行计算时就可以直接对CPU Cache中的数据进行读取和写入,当运算结束之后,再将CPU Cache中的最新数据刷新到主内存当中,CPU通过直接访问Cache的方式替代直接访问主存的方式极大地提高了CPU的吞吐能力,有了CPU Cache之后,整体的CPU和主内存之间交互的架构大致如图所示:
2.1 CPU缓存一致性问题
既然有缓存,那么就会有缓存一致性问题。
比如i++这个操作,在程序的运行过程中,首先需要将主内存中的数据复制一份存放到CPU Cache中,那么CPU寄存器在进行数值计算的时候就直接到Cache中读取和写入,当整个过程运算结束之后再将Cache中的数据刷新到主存当中:
- 读取主内存的i到CPU Cache中。
- 对i进行加一操作。
- 将结果写回到CPU Cache中。
- 将数据刷新到主内存中。
上述过程如果是在单线程下肯定是不会有问题的。如果在多线程下就会有问题:
每个线程都有自己的工作内存(本地内存,对应于CPU中的Cache),变量i会在多个线程的本地内存中都存在一个副本。如果同时有两个线程执行i++操作,假设i的初始值为0,每一个线程都从主内存中获取i的值存入CPU Cache中,然后经过计算(执行的都是从0开始++)再写入主内存中,这样i在经过了两次自增之后结果还是1,这就是典型的缓存不一致性问题。
为了解决缓存不一致性问题,通常主流的解决方法有如下两种:
- 通过总线加锁的方式
- 通过缓存一致性协议
-
通过总线加锁的方式:
常见于早期的CPU当中,而且是一种悲观的实现方式,CPU和其他组件的通信都是通过总线(数据总线、控制总线、地址总线)来进行的,如果采用总线加锁的方式,则会阻塞其他CPU对其他组件的访问,从而使得只有一个CPU(抢到总线锁)能够访问这个变量的内存。这种方式效率低下,所以就有了第二种方式 -
通过缓存一致性协议:
在缓存一致性协议中最为出名的是Intel的MESI协议,MESI协议保证了每一个缓存中使用的共享变量副本都是一致的,它的大致思想是,当CPU在操作Cache中的数据时,如果发现该变量是一个共享变量,也就是说在其他的CPU Cache中也存在一个副本,那么进行如下操作:- 读取操作,不做任何处理,只是将Cache中的数据读取到寄存器。
- 写入操作,发出信号通知其他CPU将该变量的Cache line置为无效状态,其他CPU在进行该变量读取的时候不得不到主内存中再次获取。
3 Java内存模型
Java的内存模型(Java Memory Mode,JMM)指定了Java虚拟机如何与计算机的主存(RAM)进行工作,理解Java内存模型对于编写行为正确的并发程序是非常重要的。在JDK1.5以前的版本中,Java内存模型存在着一定的缺陷,在JDK1.5的时候,JDK官方对Java内存模型重新进行了修订,JDK1.8及最新的JDK版本都沿用了JDK1.5修订的内存模型。
Java的内存模型决定了一个线程对共享变量的写入何时对其他线程可见,Java内存模型定义了线程和主内存之间的抽象关系:
- 共享变量存储于主内存之中,每个线程都可以访问。
- 每个线程都有私有的工作内存或者称为本地内存。
- 工作内存只存储该线程对共享变量的副本。
- 线程不能直接操作主内存,只有先操作了工作内存之后才能写入主内存。
- 工作内存和Java内存模型一样也是一个抽象的概念,它其实并不存在,它涵盖了缓存、寄存器、编译器优化以及硬件等。
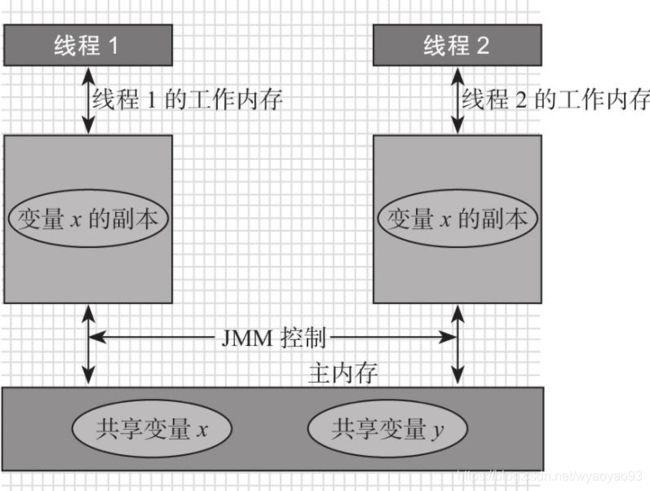
假设主内存的共享变量x为0,线程1和线程2分别拥有共享变量X的副本,假设线程1此时将工作内存中的x修改为1,同时刷新到主内存中,当线程2想要去使用副本x的时候,就会发现该变量已经失效了,必须到主内存中再次获取然后存入自己的工作内容中,这一点和CPU与CPU Cache之间的关系非常类似。
Java的内存模型是一个抽象的概念,其与计算机硬件的结构并不完全一样,比如计算机物理内存不会存在栈内存和堆内存的划分,无论是堆内存还是虚拟机栈内存都会对应到物理的主内存,当然也有一部分堆栈内存的数据有可能会存入CPU Cache寄存器中。图所示的是Jave内存模型与CPU硬件架构的交互图。