论文阅读:Intensity-Aware Loss for Dynamic Facial Expression Recognition in the Wild(AAAI2023)
摘要
与基于图像的静态人脸表情识别(SFER)任务相比,基于视频序列的动态人脸表情识别(DFER)任务更接近自然表情识别场景。然而,DFER往往更具挑战性。其中一个主要原因是视频序列通常包含具有不同表情强度的帧,特别是对于真实世界场景中的面部表情,而SFER中的图像经常呈现均匀且高的表情强度。然而,如果同等对待不同强度的表情,网络学习的特征将具有较大的类内差异和较小的类间差异,这对DFER是有害的。为了解决这个问题,我们提出了全局卷积注意块(GCA)来重新缩放特征图的通道。此外,我们在训练过程中引入了强度感知损失(IAL),以帮助网络区分表达强度相对较低的样本。在两个野外动态面部表情数据集上的实验(即,DFEW和FERV39k)表明,我们的方法优于最先进的DFER方法。代码:https://github.com/muse1998/IAL-for-Facial-
Expression-Recognition
动机与贡献

如图1所示,真实的世界中具有不同表情强度的视频序列可能导致类间距离变得小于类内距离的问题。然而,离散标签数据集的监督信息不包含强度相关的先验,例如,DFEW和FERV39k,这导致低强度表达序列通常更容易被错误分类。
本文的贡献如下:
- 通过用全局卷积聚合每个通道中的信息,我们设计了一个即插即用的全局卷积注意力块,可以重新缩放特征图的通道。特别地,GCA块不仅可以像在其他注意力机制中那样抑制不太重要的通道(例如,SE和CBAM),而且还增强了低强度表情中与标签相关的通道。据我们所知,这是第一个专注于离散标签DFER任务中的表情强度问题的工作。
- 我们提出了一个简单但有效的损失函数,称为强度感知损失,它可以迫使网络对最令人困惑的低强度表达序列给予额外的关注。因此,网络可以学习更精确的分类边界。
- 广泛的消融研究和可视化结果证明了我们的方法的有效性。它明显优于基线模型,并在两个流行的野外DFER基准测试中获得了最先进的结果
方法
整体框架
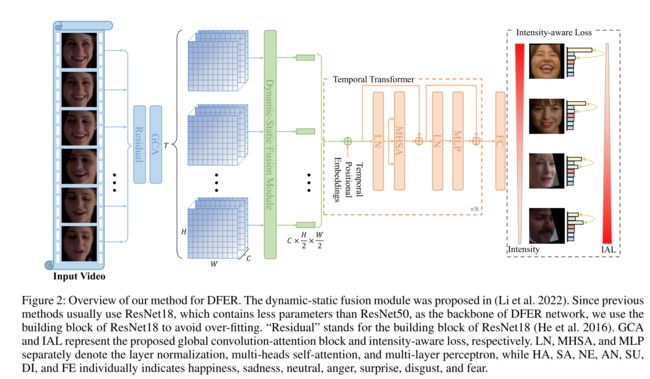
如图2所示,从原始视频中动态采样长度为T的面部表情序列作为输入。然后将输入剪辑 X i n ∈ R T × 3 × H i n × W i n X_{in}∈R^{T×3×H_{in}×W_{in}} Xin∈RT×3×Hin×Win馈送到几个构建块中(He et al. 2016)以提取帧级特征。然后,使用所提出的GCA块来重新缩放特征图的通道(即,抑制较不重要的信道并增强目标相关信道)。然后应用(Li et al.2022)中提出的动态-静态融合模块(DSF),通过融合每个帧的静态特征和相邻帧之间的动态特征来学习空间特征。合并动态和静态特征的帧级特征在被馈送到时间Transformer中以学习帧之间的长距离依赖性之前被展平。随后,将令牌序列的平均值馈送到FC层以获得识别结果。提出的IAL和交叉熵损失都被用来优化网络。
输入
我们的方法需要一个 X i n X_{in} Xin片段,它由 T T T帧RGB图像组成作为输入。输入片段是对原始视频动态采样得到的。具体而言,对于训练片段,将原始序列均等地划分为 U U U段,然后从每个段中随机挑选 V V V帧。至于测试剪辑,我们首先将所有帧分割成 U U U段,然后选择每个段中间的 V V V帧。因此,对于训练集和测试集,采样剪辑的长度都是 T = U × V T = U × V T=U×V。
全局卷积注意块

如图3(a)所示,由SE块生成的注意权重 S s e ∈ ( 0 , 1 ) S_{se}∈(0,1) Sse∈(0,1)用于抑制不太重要的信道。对于输入 X ∈ R T × C × H × W X∈R^{T×C×H×W} X∈RT×C×H×W,其中T是帧数,C是通道数,而H和W分别是特征的高度和宽度。SE块的输出 X X X可以公式化为:
X ~ = S s e ⊗ X , S s e = σ ( W 2 δ ( W 1 Z ) ) , Z c = 1 H × W ∑ i = 1 H ∑ j = 1 W X c ( i , j ) . \begin{array}{c} \tilde{X}=S_{s e} \otimes X, \\ S_{s e}=\sigma\left(W_{2} \delta\left(W_{1} Z\right)\right), \\ Z_{c}=\frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} X_{c}(i, j) . \end{array} X~=Sse⊗X,Sse=σ(W2δ(W1Z)),Zc=H×W1∑i=1H∑j=1WXc(i,j).
然而,由于 S s e S_{se} Sse的值属于(0,1),因此SE块只能抑制较不重要的信道。一个合适的注意机制DFER也应该加强的关键通道,这是至关重要的,以加强低强度样本的目标相关的功能。此外,位置信息对于DFER任务也是至关重要的(例如,出现在嘴角或眉毛之间的面部相关特征可以指示完全不同的表情),但是通过全局平均池化生成的通道描述符Z丢失了输入特征的位置信息。
基于这些观点,我们提出了如图2(b)所示的GCA块。对于相同的输入 X ∈ R T × C × H × W X∈R^{T×C×H×W} X∈RT×C×H×W,GCA块的输出可以计算为:
X ~ = S g c a ⊗ X , S g c a = 2 s ⊗ G A P t ( s ) , s = σ ( W 2 δ ( W 1 Z ) ) , Z c = ∑ i = 1 H ∑ j = 1 W X c ( i , j ) × W ^ c ( i , j ) . \begin{array}{c} \tilde{X}=S_{g c a} \otimes X, \\ S_{g c a}=2 \sqrt{s \otimes G A P_{t}(s)}, \\ s=\sigma\left(W_{2} \delta\left(W_{1} Z\right)\right), \\ Z_{c}=\sum_{i=1}^{H} \sum_{j=1}^{W} X_{c}(i, j) \times \hat{W}_{c}(i, j) . \end{array} X~=Sgca⊗X,Sgca=2s⊗GAPt(s),s=σ(W2δ(W1Z)),Zc=∑i=1H∑j=1WXc(i,j)×W^c(i,j).
由于 S g c a S_{gca} Sgca属于(0,2),GCA块不仅可以抑制不太重要的通道,而且还可以增强关键通道。同时,全局卷积可以保留特征的位置信息,这对于DFER至关重要。此外,时间全局平均池化提供了更大的帧间视场。
强度感知损失
当强度收敛到零时,所有非中性表达式趋于接近中性表达式,其可以定义为
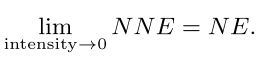
其中NNE和NE分别是非中性和中性表达式。看来把面部表情作为一个回归任务更合适。然而,由于具有连续标签的DFER数据集的注释成本很高,因此此类数据集的规模通常是有限的。此外,注释的强度标准难以统一。为了解决这个问题,我们提出了强度感知损失,以减少低强度样本的DFER任务带来的影响。基于低强度样本可能与其他类别的低强度样本混淆的假设(如图1所示),网络应该格外注意每个样本中最容易混淆的类别。因此,所提出的强度感知损耗可以公式化为,

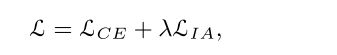
讨论
我们可以发现低强度样本对离散标签DFER提出的挑战,这与基于高强度单个图像的静态表情识别任务不同。因此,我们首先提出了这个问题上的离散标签DFER,并提出了IAL来处理这些低强度的样本,和建议的GCA块被用来增强他们的功能。然而,在准确地发现这些低强度样本并在没有额外监督的情况下增强其特征方面仍有很大的改进空间。在这里,我们提供了几条可以尝试的技术路线,用于未来处理低强度表达样本的工作:通过知识蒸馏方法,基于教师网络的输出找到低强度样本。·以中性表情为原点构建面部表情空间,并通过输入与原点之间的偏移量来测量强度。我们希望这项工作能够激励研究人员提出更有效的解决方案。
本篇论文采用的强度感知损失和LOGO-Former: Local-Global Spatio-Temporal Transformer for DFER(ICASSP2023)论文中提到的紧凑损失正则化思想类似。
在ICASSP2023中,学习判别性的时空特征在野外DFER要求损失函数具有最大化不同类别之间的特征距离的能力。为了实现这一点,文章使用对称Kullback-Leibler(KL)散度 D ( u ) ∣ ∣ p ) + D ( p ∣ ∣ u ) {D(u)||p)+ D(p|| u)} D(u)∣∣p)+D(p∣∣u)来测量分布 u u u和 p p p之间的差异,并对预测分布 p p p施加约束,其中 u u u是 C − 1 C − 1 C−1上的均匀分布, p p p是预测分布,但不包括相应目标 y y y的概率。 u 由 u由 u由softmax函数计算:


结论
在本文中,我们开发了一个即插即用的模块,称为全局卷积注意力块和一个简单但有效的强度感知损失的野生DFER。我们的全局卷积-注意块被设计用于重新缩放特征图的通道,以便可以增强低强度序列的目标相关特征,并抑制不太重要的特征。提出的强度感知损失有助于网络额外关注每个样本最可能混淆的类别(低强度样本通常具有可能混淆的类别)。实验和可视化结果证明了该方法的有效性和优越性。具体来说,我们专注于处理低强度样本在野外动态面部表情识别任务。据我们所知,这是第一个工作集中在离散标签DFER的表情强度问题。我们希望更多的研究人员能够注意到这个问题,并在未来提供更多有趣的解决方案。
实验记录
这是第1000个epoch的实验记录
999
Current learning rate: 1.793662034335766e-46
Epoch: [999][ 0/233] Loss 0.7906 (0.7906) Accuracy 85.000 (85.000)
Epoch: [999][ 10/233] Loss 0.8354 (0.7556) Accuracy 80.000 (82.045)
Epoch: [999][ 20/233] Loss 0.6635 (0.7539) Accuracy 90.000 (83.095)
Epoch: [999][ 30/233] Loss 0.6919 (0.7637) Accuracy 87.500 (82.661)
Epoch: [999][ 40/233] Loss 0.6876 (0.7625) Accuracy 80.000 (82.378)
Epoch: [999][ 50/233] Loss 0.6484 (0.7505) Accuracy 85.000 (82.892)
Epoch: [999][ 60/233] Loss 0.8856 (0.7545) Accuracy 72.500 (83.197)
Epoch: [999][ 70/233] Loss 0.5192 (0.7429) Accuracy 90.000 (83.732)
Epoch: [999][ 80/233] Loss 0.6085 (0.7376) Accuracy 85.000 (83.920)
Epoch: [999][ 90/233] Loss 0.5920 (0.7348) Accuracy 90.000 (83.846)
Epoch: [999][100/233] Loss 0.6609 (0.7344) Accuracy 85.000 (83.861)
Epoch: [999][110/233] Loss 0.8448 (0.7357) Accuracy 82.500 (83.851)
Epoch: [999][120/233] Loss 0.5464 (0.7311) Accuracy 90.000 (84.112)
Epoch: [999][130/233] Loss 0.6136 (0.7290) Accuracy 85.000 (84.256)
Epoch: [999][140/233] Loss 0.9914 (0.7306) Accuracy 72.500 (84.220)
Epoch: [999][150/233] Loss 0.8535 (0.7337) Accuracy 80.000 (84.139)
Epoch: [999][160/233] Loss 0.7984 (0.7332) Accuracy 82.500 (84.208)
Epoch: [999][170/233] Loss 0.9289 (0.7334) Accuracy 77.500 (84.211)
Epoch: [999][180/233] Loss 0.6651 (0.7332) Accuracy 90.000 (84.240)
Epoch: [999][190/233] Loss 0.7719 (0.7347) Accuracy 77.500 (84.254)
Epoch: [999][200/233] Loss 0.6129 (0.7330) Accuracy 90.000 (84.216)
Epoch: [999][210/233] Loss 0.6792 (0.7331) Accuracy 85.000 (84.254)
Epoch: [999][220/233] Loss 0.7982 (0.7349) Accuracy 85.000 (84.140)
Epoch: [999][230/233] Loss 1.0734 (0.7323) Accuracy 70.000 (84.210)
Test: [ 0/59] Loss 1.0610 (1.0610) Accuracy 62.500 (62.500)
Test: [10/59] Loss 1.0532 (0.9247) Accuracy 57.500 (64.091)
Test: [20/59] Loss 1.0839 (0.9222) Accuracy 55.000 (65.119)
Test: [30/59] Loss 0.8049 (0.9300) Accuracy 72.500 (65.000)
Test: [40/59] Loss 1.0154 (0.9280) Accuracy 70.000 (65.732)
Test: [50/59] Loss 0.8913 (0.8988) Accuracy 62.500 (67.451)
Current Accuracy: 67.836
The best accuracy: 68.43456268310547
An epoch time: {:.1f}s363.69196105003357