用 Python 爬取网页小说
目录
- 1 完整代码
- 2 分析小说第一章的网页
- 3 代码实现
参考博客:完全小白篇-使用Python爬取网络小说
1 完整代码
import requests
import re
from bs4 import BeautifulSoup
# from docx import Document
#创建正则表达式对象,r是为了避免对'/'的错误解析
findTitle = re.compile(r'(.*?)
',re.S)
findContext = re.compile(r'(.*?)
',re.S)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}
# 输入小说第一章网址
def getNovel(url, f):
# 存放下一章的链接
link = url
# 最后一章中,点击“下一章”会回到目录
while(link != "http://yk360.kekikc.xyz/413/"):
# 获取网页源码
data = requests.get(url = link, headers = headers)
#上文我们已经看到是UTF-8的编码格式,这里照搬按此解析即可
data.encoding = 'UTF-8'
#解析得到网站的信息
soup = BeautifulSoup(data.text, 'html.parser')
# print(soup)
# 提取章节名
for item in soup.find_all('div', class_="m-title col-md-12"):
item = str(item)
title = re.findall(findTitle, item)[0]
print(title)
f.write(title + '\n')
# 提取章节内容
for item in soup.find_all('div',id="content"):
item = str(item)
context = re.findall(findContext, item)
for i in range(1, len(context)):
f.write(context[i] + '\n')
f.write('\n\n')
# print(context)
# print(len(context))
# 跳转到下一章
for item in soup.find_all('li', class_="col-md-4 col-xs-12 col-sm-12"):
nextChp = item.find_all('a')
tmpLink = nextChp[0].get('href')
# print(tmpLink)
link = "http://yk360.kekikc.xyz" + tmpLink
#小说第一章的网址
baseurl = "http://yk360.kekikc.xyz/413/57269.html"
with open("output.txt", "w") as f:
getNovel(baseurl, f)
2 分析小说第一章的网页
以 http://yk360.kekikc.xyz/413/57269.html 为例
(1)查看网页编码格式,在 head 标签里能找到

(2)查看章节名存放位置
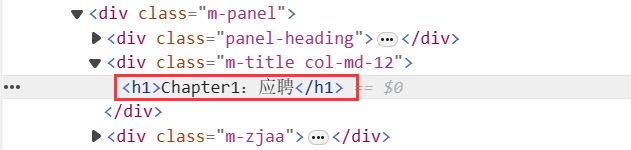
(3)查看章节内容存放位置

(4)查看各章节间的跳转关系,最后一章的下一章是列表页面
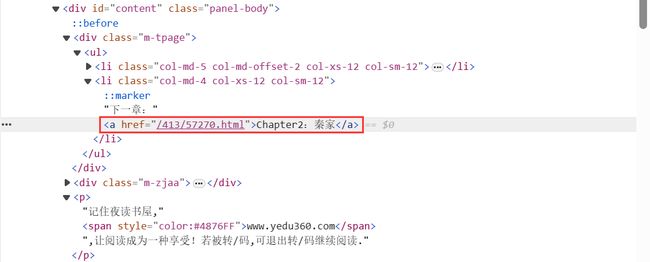
3 代码实现
(1)获取网页源码
设置 requests.get() 中的 headers 参数,用来模拟浏览器进行访问
# 获取网页源码
data = requests.get(url = link, headers = headers)
#上文我们已经看到是UTF-8的编码格式,这里照搬按此解析即可
data.encoding = 'UTF-8'
#解析得到网站的信息
soup = BeautifulSoup(data.text, 'html.parser')
print(soup)
(2)提取章节名
章节名存放在 class 为 m-title col-md-12 的 div 中的 h1 标签里,采用正则提取 findTitle = re.compile(r'(.*?)
',re.S)
for item in soup.find_all('div', class_="m-title col-md-12"):
item = str(item)
title = re.findall(findTitle, item)[0]
print(title)
(3)提取章节内容 (.*?)
章节内容存放在 id 为 content 的 div 中的 p 标签里,采用正则提取 findContext = re.compile(r'
for item in soup.find_all('div',id="content"):
item = str(item)
context = re.findall(findContext, item)
print(context)
(4)跳转到下一章
下一章链接存放在 class 为 col-md-4 col-xs-12 col-sm-12 的 li 中的 a 标签里
for item in soup.find_all('li', class_="col-md-4 col-xs-12 col-sm-12"):
nextChp = item.find_all('a')
tmpLink = nextChp[0].get('href')
print(tmpLink)
link = "http://yk360.kekikc.xyz" + tmpLink
(5)将提取内容存入 TXT 文档中,其中需要注意存放章节内容时,第一个 p 标签内容为广告,需要跳过(所有的 p 标签内容按顺序存入 context 数组中,context 长度等于 p 标签个数)
for i in range(1, len(context)):
f.write(context[i] + '\n')