Python爬虫项目:年份筛选器
(有用的话,点个赞呗!ヽ(✿゚▽゚)ノ完整代码在最下面)
有些网站的分类方式太鸡肋了。
虽然能选择年份,或者靠关键字筛选图书,但是两者不能同时进行。
而常常能搜到很多在2010年,甚至更早出版的的老书,
显然,很多老书是跟不上时代的,我们可能并不想要。
因此,我决定编写一个爬虫程序筛选年份。
开始前的准备
我们要爬一个名叫“搬书匠”的网站
首先,明确目标
我们需要筛选两样东西:
1.书名
2.出版年份
所需参数
为了筛选上述两样东西,我们还需要明确我们的参数。
固定的参数:url
按需更改的参数:你可接受的最低年份、搜索的关键字、检索的页数(尾页)。
url特点
我们去搜索“Python datamining”,看看搬书匠的url会怎么变化?
url总体:
经过观察,我们发现四点:
1,第一部分是固定的
2,第二部分是变化的
第一页↓
第二页↓
3,其中的阿拉伯数字代表页数
4,我们搜索时输入的空格由+代替
开始编写!
(这里用面向对象的方法来编写,方便后期维护。)
创建一个YearAnalyzer类
其中url没有页码和搜索的关键字的部分,是我们固定的参数,一般不会去改它
因此我们把 url的部分设定为类属性。
将url分为两个部分是为了便于拼接我们的页码和搜索关键字。
(这段代码有一大坨请求头,可以忽略)
import requests
import re
class YearAnalyzer:
url_1 = "http://www.banshujiang.cn/e_books/search/page/"
url_2 = "?searchWords="
# 请求头太大坨了,放在这不美观。
# 有需要的话,请去文章最下面拿取
headers = {}
# 对应上文url的两部分
def __init__(self, page: int, year:int, search: str):
self.trailer_page = page
self.search = search
self.year = year
# 分别是是尾页、搜索的关键字、可接受的最低年份
实例方法一:拼接url
说明
编写一个splice_url方法
将页码和搜索的关键字塞入url中
返回一个url_list,为爬虫提供url列表。
代码
def splice_url(self):
url_list = []
for page in range(1, self.trailer_page + 1):
str_page = str(page)
url = ''.join([self.url_1, str_page, self.url_2, self.search])
url_list.append(url)
return url_list实例方法二:采集所有书名和出版年份信息
说明
编写一个get_ori_name_year方法
使用requires库的get方法向网站发起请求,获取html码。
再用正则表达式提取所有的书名和对应年份。
这个方法只需要一个参数: url
print一下我们得到的响应,就会发现,每一本书的书名和出版日期都是放在一块的
因此可直接用zip函数把正则表达式返回的两个列表的元素拼接起来。

代码
def get_ori_name_year(self, url_list):
all_ori_name_year = []
for url in url_list:
response1 = requests.get(url, headers=self.headers)
# 发起请求,获取响应
response = response1.content.decode()
# 解码响应
ori_year_result = re.findall(r"出版年份.*?(\d+)", response)
# 获取所有年份
ori_name_result = re.findall(r'书名.*?href="/e_books.*?>(.*?)', response)
# 获取所有书名
ori_name_year = zip(ori_name_result, ori_year_result)
# 因为正则表达式findall方法返回的是列表。
# 所以可以用zip()函数把每一个书名和对应的年份拼接起来。
list_ori_name_year = list(map(list, ori_name_year))
# 因为zip函数返回的是一个对象,而直接用list方法的话
# 得到的是[[(书名,年份)]],会多一层列表,这样会让遍历变得麻烦
# 因此这里用list(map(list, zip对象))的方法,将zip对象转化为列表。
all_ori_name_year += list_ori_name_year
# 将遍历的结果加入到总列表
return all_ori_name_year
# 返回一个嵌套了元组的列表 形如:[(书名,对应年份)]实例方法三:筛选满足条件的书籍
说明
编写一个filter方法
遍历所有书名和年份
并写条件判断语句
代码
def filter(self, ori_name_year):
satisfied_name_li = []
satisfied_year_li = []
books_number = 0
for (name, year) in ori_name_year:
if int(year) >= int(self.satisfied_year):
books_number += 1
# -----------------------------------------------------------------
if books_number >= 2:
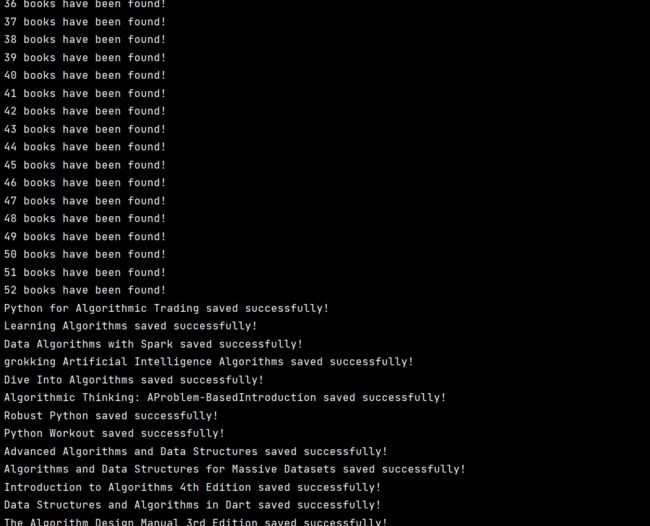
print(books_number, "books have been found!")
# 这部分代码只是为了看有多少本书满足条件,可写可不写
else:
print(books_number, "book has been found!")
# -----------------------------------------------------------------
satisfied_name_li.append(name)
satisfied_year_li.append(year)
satisfied_name_year = zip(satisfied_name_li, satisfied_year_li)
return satisfied_name_year
实例方法四:将搜索结果保存为txt文件
说明
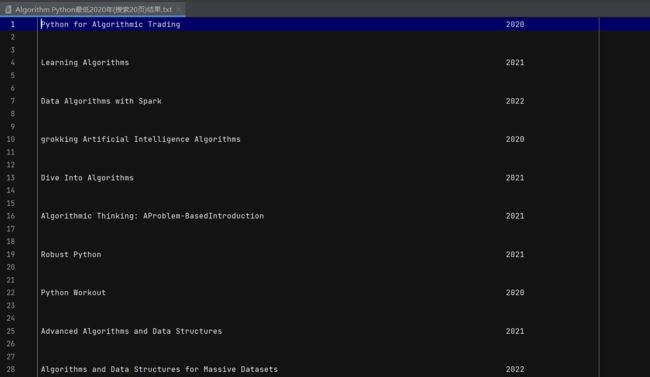
将所有满足条件的书名和年份写入文件
并保存在所在目录下
代码
def save(self, satisfied_name_year):
for name, year in satisfied_name_year:
# 遍历所有筛出的书籍
with open(f"{self.search.replace('+',' ')}最低{self.satisfied_year}年(搜索{self.trailer_page}页)结果.txt", 'a', encoding="UTF-8") as F:
# 把文件名写好,方便看
F.write("{0:<100}{1:<10}{2}".format(name, year, "\n"*3))
# 用format函数,让写入的文段更美观
print(name, "saved successfully!")
# 输出所保存的书名
if not satisfied_name_year:
print("Books not found.")
# 如果没有满足条件的书,则输出对应文本。Main方法
说明
将各个实例方法组合起来
代码
def Main(self):
url_list = self.splice_url()
# 获取url列表
all_ori_name_year = self.get_ori_name_year(url_list)
# 获取所有书名和年份
satisfied_name_year = self.filter(all_ori_name_year)
# 筛选出满足条件的书籍
self.save(satisfied_name_year)
# 保存文件测试!
终于写完啦,现在让我们来测试一下吧!
(为了写文章,我把我原来写好的shi重构成了现在这样,
真是累死我了,不过看起来真的优雅许多)
定义一个对象,传入三个可以更改的参数
搜索关键词,检索的页数,最低年份
Analyzer = YearAnalyzer(search="Algorithm Python", page=20, year=2020)
Analyzer.Main()效果展示
看起来很不错!
完整代码
import requests
import re
class YearAnalyzer:
url_1 = "http://www.banshujiang.cn/e_books/search/page/"
url_2 = "?searchWords="
# 对应上文url的两部分
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "Hm_lvt_38a41a4c5062c2a88d0e6083f47105ab=1669429515,1669440146; Hm_lpvt_38a41a4c5062c2a88d0e6083f47105ab=1669448234",
"Host": "www.banshujiang.cn",
"Referer": "http://www.banshujiang.cn/e_books/search/page/2?searchWords=data+mining",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.56}"
}
def __init__(self, page: int, year: int, search: str):
self.trailer_page = page
self.search = search
self.satisfied_year = year
# 分别是是尾页、搜索的关键字、可接受的最低年份
def splice_url(self):
url_list = []
for page in range(1, self.trailer_page + 1):
str_page = str(page)
url = ''.join([self.url_1, str_page, self.url_2, self.search])
url_list.append(url)
return url_list
def get_ori_name_year(self, url_list):
all_ori_name_year = []
for url in url_list:
response1 = requests.get(url, headers=self.headers)
# 发起请求,获取响应
response = response1.content.decode()
# 解码响应
ori_year_result = re.findall(r"出版年份.*?(\d+)", response)
# 获取所有年份
ori_name_result = re.findall(r'书名.*?href="/e_books.*?>(.*?)', response)
# 获取所有书名
ori_name_year = zip(ori_name_result, ori_year_result)
# 因为正则表达式findall方法返回的是列表。
# 所以可以用zip()函数把每一个书名和对应的年份拼接起来。
list_ori_name_year = list(map(list, ori_name_year))
# 因为zip函数返回的是一个对象,而直接用list方法的话
# 得到的是[[(书名,年份)]],会多一层列表,这样会让遍历变得麻烦
# 因此这里用list(map(list, zip对象))的方法,将zip对象转化为列表。
all_ori_name_year += list_ori_name_year
# 将遍历的结果加入到总列表
return all_ori_name_year
# 返回一个嵌套了元组的列表 形如:[(书名,对应年份)]
def filter(self, ori_name_year):
satisfied_name_li = []
satisfied_year_li = []
books_number = 0
for (name, year) in ori_name_year:
if int(year) >= int(self.satisfied_year):
books_number += 1
# -----------------------------------------------------------------
if books_number >= 2:
print(books_number, "books have been found!")
# 这部分代码只是为了看有多少本书满足条件,可写可不写
else:
print(books_number, "book has been found!")
# -----------------------------------------------------------------
satisfied_name_li.append(name)
satisfied_year_li.append(year)
satisfied_name_year = zip(satisfied_name_li, satisfied_year_li)
return satisfied_name_year
def save(self, satisfied_name_year):
for name, year in satisfied_name_year:
# 遍历所有筛出的书籍
with open(f"{self.search.replace('+', ' ')}最低{self.satisfied_year}年(搜索{self.trailer_page}页)结果.txt", 'a',
encoding="UTF-8") as F:
# 把文件名写好,方便看
F.write("{0:<100}{1:<10}{2}".format(name, year, "\n" * 3))
# 用format函数,让写入的文段更美观
print(name, "saved successfully!")
# 输出所保存的书名
if not satisfied_name_year:
print("Books not found.")
def Main(self):
url_list = self.splice_url()
# 获取url列表
all_ori_name_year = self.get_ori_name_year(url_list)
# 获取所有书名和年份
satisfied_name_year = self.filter(all_ori_name_year)
# 筛选出满足条件的书籍
self.save(satisfied_name_year)
# 保存文件
Analyzer = YearAnalyzer(search="Algorithm Python", page=20, year=2020)
Analyzer.Main()