【Go语言 map源码分析】
map底层数据结构
我们在之前学习C++中的map时知道了 map的底层其实是有两种数据结构 这取决于我们要求它有序还是无序
- 如果说我们要求map是有序的它的底层数据结构就是红黑树
- 如果说我们要求map是无序的它的底层数据结构就是哈希表
但是Go语言中的map数据结构有点特殊 如下图
- 当我们创建一个map对象的时候 实际上就是创建一个指针指向hmap结构体
- 每个hmap结构体中包含若干个bucket
- 每个bucket都是一个指向bmap结构体对象的指针
- 每个bmap最多只能存放八个键值对 当到第九个的时候便会通过overflow指向下一个bmap
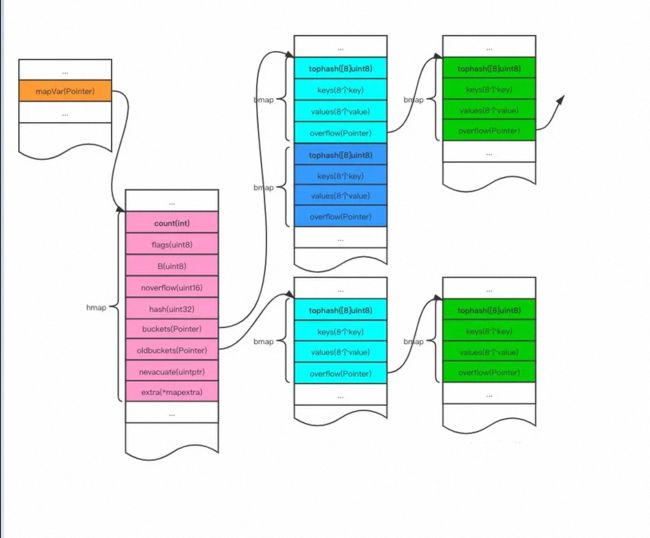
其中hmap 和 bmap的go语言源码如下
type hmap struct {
count int
// 代表哈希表中的元素个数,调用len(map)时,返回的就是该字段值。
flags uint8
// 状态标志(是否处于正在写入的状态等)
B uint8
// buckets(桶)的对数
// 如果B=5,则buckets数组的长度 = 2^B=32,意味着有32个桶
noverflow uint16
// 溢出桶的数量
hash0 uint32
// 生成hash的随机数种子
buckets unsafe.Pointer
// 指向buckets数组的指针,数组大小为2^B,如果元素个数为0,它为nil。
oldbuckets unsafe.Pointer
// 如果发生扩容,oldbuckets是指向老的buckets数组的指针,老的buckets数组大小是新的buckets的1/2;非扩容状态下,它为nil。
nevacuate uintptr
// 表示扩容进度,小于此地址的buckets代表已搬迁完成。
extra *mapextra
// 存储溢出桶,这个字段是为了优化GC扫描而设计的
}
//每个bucket是一个bmap结构体,bmap 结构体如下
type bmap struct{
tophash [8]uint8
keys [8]keytype
// keytype 由编译器编译时候确定
values [8]elemtype
// elemtype 由编译器编译时候确定
overflow uintptr
// overflow指向下一个bmap,overflow是uintptr而不是*bmap类型,保证bmap完全不含指针,是为了减少gc,溢出桶存储到extra字段中
}
插入元素的步骤
当我们向map中存储一个键值对的时候 会经过下面的步骤
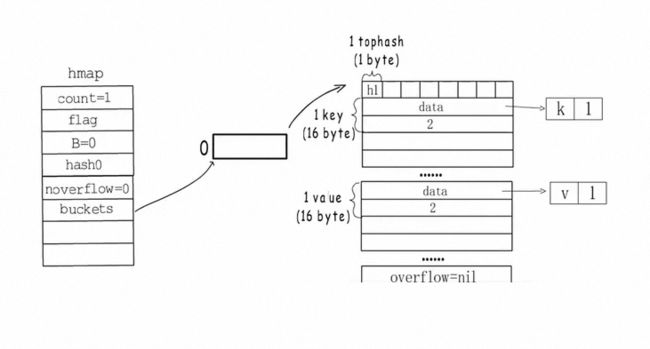
- 通过k的哈希值和buckets长度取余 定位到key在哪一个bucket中
- hash值的高八位存储在bucket的tophash[i]中 用来快速判断key是否存在
- 当一个bucket满时 通过overflow指针连接到下一个bucket
bmap 结构体字段说明
type bmap struct{
tophash [8]uint8
keys [8]keytype
// keytype 由编译器编译时候确定
values [8]elemtype
// elemtype 由编译器编译时候确定
overflow uintptr
// overflow指向下一个bmap,overflow是uintptr而不是*bmap类型,保证bmap完全不含指针,是为了减少gc,溢出桶存储到extra字段中
}
tophash用来快速查找key是否在该bucket中 一般会使用key的哈希值的高八位作为tophash值 存放在该字段中 当然它也会存储一些状态值来表示当前桶的状态- bmap中的key和value是各自放在一起的 存放形式如下
k1/k2/k3 ... ... v1/v2/v3 ... ...这样子做的好处是会节省空间 - 每个bucket中只能存放八个键值对 如果有了第九个 那么就会再创建一个bucket 使用指针链接起来
为什么说
k1/k2/k3 ... ... v1/v2/v3 ... ...格式会比较省空间
比如说我们的key值有8个字节 value值只占1个字节
那么如果我们要按照 key / value 的方式来存储数据的话考虑到内存对齐 就要浪费额外的7个字节的空间
而我们上面的那种方式天然会内存对齐(一定是8的整数倍) 所以上面那种设计会更加巧妙一点
定位元素大体过程
定位元素过程如下
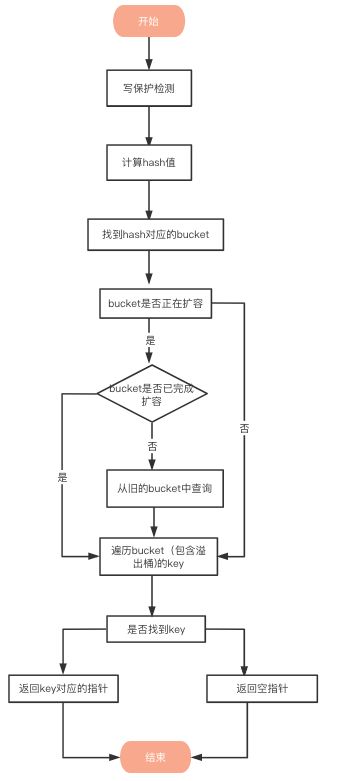
写保护监测
在我们开始定位时 我们首先会检查 map 的标志位 flags 如果此时 map 的写标志位被置1了则说明有其他线程在进行写操作
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
计算哈希值
之后我们就开始计算 key 的哈希值
hash := t.hasher(key, uintptr(h.hash0))
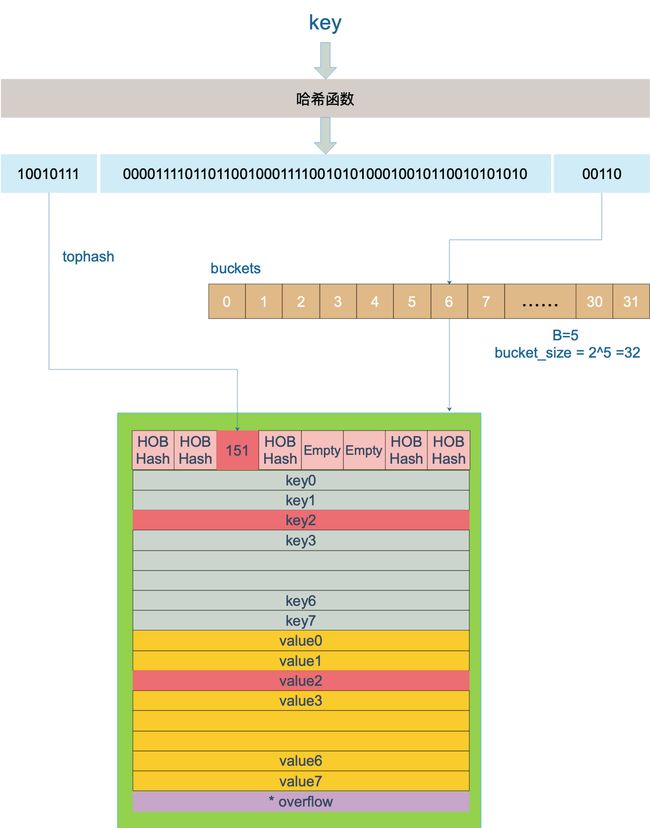
//key经过哈希函数计算后,得到的哈希值如下(主流64位机下共 64 个 bit 位),不同类型的key会有不同的hash函数
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010
找到哈希对应的bucket
- 定位规则 : 哈希值的低B个比特位 用来定位key所存放的bucket
B如何计算
B 是根据哈希表的当前桶的数量 N 来决定的 其目的是确定足够的比特位来唯一地表示哈希表中所有可能的桶索引 通常 B 是能够覆盖从 0 到 N-1 所有索引的最小比特数
如果 N 是 2 的幂 即 N = 2^B 那么 B 可以直接通过下面的公式计算出来:
B = log2(N)
假如说当前正在扩容中 并且还没有扩容完成 那么此时我们就使用旧的 bucket
hash := t.hasher(key, uintptr(h.hash0))
// 桶的个数m-1,即 1<
m := bucketMask(h.B)
// 计算哈希值对应的bucket
// t.bucketsize为一个bmap的大小,通过对哈希值和桶个数取模得到桶编号,通过对桶编号和buckets起始地址进行运算,获取哈希值对应的bucket
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 是否在扩容
if c := h.oldbuckets; c != nil {
// 桶个数已经发生增长一倍,则旧bucket的桶个数为当前桶个数的一半
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
// 计算哈希值对应的旧bucket
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
// 如果旧bucket的数据没有完成迁移,则使用旧bucket查找
if !evacuated(oldb) {
b = oldb
}
}
遍历bucket查找
我们通过哈希值的定位到了要查找的键值对是否在该bucket中之后
接着我们再通过 tophash 来快速在该bucket和该bucket的overflow中找出有没有对应的槽位
这里只会有两种可能
- 找到了空槽位 即哈希表中没有对应的值 返回空指针
- 找到了对应的槽位 即找到了对应的键值对 返回对应的指针
流程如下图
获取key 和 value对应位置
偏移量计算和定位公式如下
// keys的偏移量
dataOffset = unsafe.Offsetof(struct{
b bmap
v int64
}{}.v)
// 一个bucket的元素个数
bucketCnt = 8
// key 定位公式
k :=add(unsafe.Pointer(b),dataOffset+i*uintptr(t.keysize))
// value 定位公式
v:= add(unsafe.Pointer(b),dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
- 第i个key值前面肯定有i个key 所以说位置偏移量要加上
- 同理value值的前面要加上 所有的key便宜和i个value偏移
解决哈希冲突
Go语言也是通过一种特殊的开放定址法 它较为特殊的点在于后面链接的不是一个个元素 而是一个个bucket
负载因子
我们知道负载因子和哈希冲突的概率相关
在Go语言中
- 1.1.7 即更早的版本 默认负载因子为6.5
这个负载因子主要是在空间浪费和减少哈希冲突之间做出了一个取舍 这是经过大量的实验得出的一个较为理想的数字
- 1.1.8版本之后 map 的负载因子是根据实际的哈希表性能来动态调整
map扩容
在向 map 插入新 key 的时候 会进行条件检测 符合下面这 2 个条件 就会触发扩容
- 超过负载 map 元素个数 > 6.5 * 桶个数
- 溢出桶太多
溢出桶太多有两个判定标准
- 当桶总数 < 2^15 时如果溢出桶总数 >= 桶总数 则认为溢出桶过多
- 当桶总数 >= 2^15 时,直接与 2^15 比较 当溢出桶总数 >= 2^15 时 即认为溢出桶太多了
如果说是因为超出负载扩容 那么直接扩两倍
如果是因为溢出桶太多导致的 我们并不直接扩大容量 而是做一遍类似双倍扩容的动作 将松散的键值对排列紧密 节省空间 提高bucket的使用率
需要注意的点
Go map遍历是无序的
使用 range 多次遍历 map 时输出的 key 和 value 的顺序可能不同
这是 Go 语言的设计者们有意为之 旨在提示开发者们 Go 底层实现并不保证 map 遍历顺序稳定 不要依赖 range 遍历结果顺序
主要原因有2点:
- map在遍历时 并不是从固定的0号bucket开始遍历的 每次遍历 都会从一个随机值序号的bucket 再从其中随机的cell开始遍历
- map在扩容后 会发生key值迁移
如果设计者不增加随机数 那么一些熟悉map特性的开发者可能会自以为是的认为map是相对有序的 从而导致一些错误的发生
map是不支持并发读写的
map是不支持并发读写的 如果我们并发的去读写则会产生panic
如何线程安全的使用map
map本身不是线程安全的 如果我们想要其线程安全则要进行同步
- 我们可以使用
sync.Mutex或sync.RWMutex进行加锁 - 使用go官方提供的
sync.Map替代map
map中的key可以取地址吗
不可以 我们上面也说过了 key的地址是会不断发生变化的 所以说下面的这段代码是错误的
type Student struct {
name string
}
func main() {
m := map[string]Student{"people": {"zhoujielun"}}
m["people"].name = "wuyanzu"
}
如果想要修改 我们通常可以这样做
func main() {
m := map[string]Student{"people": {"zhoujielun"}}
// 创建一个副本,修改副本
student := m["people"]
student.name = "wuyanzu"
// 将修改后的副本放回 map 中
m["people"] = student
}
又或者 我们直接将value变成一个地址 这样子就可以直接修改啦
func main() {
m := map[string]*Student{"people": {"zhoujielun"}}
// 由于 map 中存储的是指向 Student 的指针,可以直接修改
m["people"].name = "wuyanzu"
}