tensorflow2中的遮盖和填充(padding&mask)以及dnamic_rnn学习笔记
1. 写在前面
最近在用deepctr代码风格复现DIN模型的时候, 无意间发现了tf文档里面有关于变长序列的遮盖和填充的相关知识点,今天抽了一下午的时间快速学习了一下,结合着复现DIN模型时遇到的一个坑, 做了几个小实验感受了一下这个知识点的具体使用情况。 另外, 又顺便复习了下tf1中的动态RNN(dynammic_rnn), 因为这两天复现DIEN时在兴趣抽取层那里卡住了, 我一直好奇兴趣抽取层那里是怎么计算呢? 原始的行为序列padding之后,经过GRU得到的隐藏状态的输出后,是不是就没法识别出之前padding的情况了? 所以这块实现想用动态RNN来做,就学习了下,后面看看好使不。 这篇文章就是先把这下午学到的一点新东西进行整理了。
2. keras中的遮盖与填充
首先,说明一下这东西的使用场景, 一般遮盖和填充的操作会用到变长的序列中,比如nlp里面输入的句子长度会不一样, 推荐里面的用户行为序列长度也会不一样等。 但是神经网络确要求每个输入样本序列是等长的, 于是乎,就得需要填充策略,先把序列都弄成一样长的。 但是在神经网络具体计算的时候,得告诉它一下哪些数据我是经过填充的,这样好将这些数据跳过去, 这就是遮盖了。看看文档上的说法:
-
遮盖的作用是告知序列处理层输入中有某些时间步骤丢失,因此在处理数据时应将其跳过。
-
填充是遮盖的一种特殊形式,其中被遮盖的步骤位于序列的起点或开头。填充是出于将序列数据编码成连续批次的需要:为了使批次中的所有序列适合给定的标准长度,有必要填充或截断某些序列。
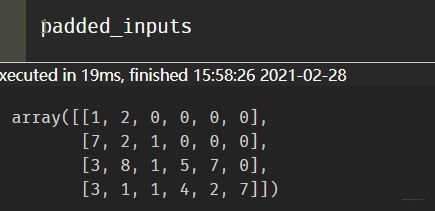
知道了使用场景之后, 我这里直接上个数据的例子了:比如原始的数据数据长这样, 可以想象成4个用户的历史行为点击商品id, 或者4个句子里面的单词在词典中的位置。
raw_inputs = [
[1, 2],
[7, 2, 1],
[3, 8, 1, 5, 7],
[3, 1, 1, 4, 2, 7],
]
假设我们原始的输入数据长这个样子, 我们看看有哪些方式可以填充。 好吧,没有哪些了, 我见到过最常用的方式,就是tf.keras.preprocessing.sequence.pad_sequences,比如:
padded_inputs = tf.keras.preprocessing.sequence.pad_sequences(
raw_inputs, padding="post"
)
print(padded_inputs)
## 这时候结果 都变成一样长了
[[1 2 0 0 0 0]
[7 2 1 0 0 0]
[3 8 1 5 7 0]
[3 1 1 4 2 7]]
所以关于填充,我们可以用这种方式,当然也可以手动实现, 列表推导式就可以搞定。

下面主要是遮盖这块。
既然所有样本现在都具有了统一长度,那就必须告知模型,数据的某些部分实际上是填充,应该忽略。这种机制就是遮盖。
在keras模型中引入输入掩码有三种方式
- 添加一个
keras.layers.Masking层。 - 使用
mask_zero=True配置一个keras.layers.Embedding层。 - 在调用支持
mask参数的层(如 RNN 层)时,手动传递此参数。
在说这三种之前,我还发现了一个可以获得mask的两种方式:
tf.sequence_mask([len(seq) for seq in raw_inputs], maxlen=max([len(seq) for seq in raw_inputs]))
## 结果:
<tf.Tensor: shape=(4, 6), dtype=bool, numpy=
array([[ True, True, False, False, False, False],
[ True, True, True, False, False, False],
[ True, True, True, True, True, False],
[ True, True, True, True, True, True]])>
第二种方式就是tf.not_equal。但这种方式的前提是原数据不能有0.
mask - tf.not_equal(keys[:, :, 0], 0)
好了, 下面开始介绍文档中提到的三种方式了。
2.1 掩码生成层: Embedding和Masking
这里参考了官方文档,给出了embedding层的mask方法, 设置mask_zero=True.
embedding = Embedding(input_dim=5000, output_dim=16, mask_zero=True)
mask_output = embedding(padded_inputs)
mask_output._keras_mask
# 结果
<tf.Tensor: shape=(4, 6), dtype=bool, numpy=
array([[ True, True, False, False, False, False],
[ True, True, True, False, False, False],
[ True, True, True, True, True, False],
[ True, True, True, True, True, True]])>
然后介绍Masking()层
masking_layer = Masking()
unmasking_embedding = tf.cast(tf.tile(tf.expand_dims(padded_inputs, axis=-1), [1, 1, 10]), tf.float32)
mask_embedding = masking_layer(unmasking_embedding)
print(mask_embedding._keras_mask)
# 结果
tf.Tensor(
[[ True True False False False False]
[ True True True False False False]
[ True True True True True False]
[ True True True True True True]], shape=(4, 6), dtype=bool)
看了之后,我们可能发现这不so easy吗? 但具体用的时候,还真不敢保证能用上。 比如,在DIN的Attention的实现上,就会用到padding和mask的操作, 但是一开始的时候没弄明白怎么通过上面的方式进行mask的使用。所以还是用的原始的方式:

这里就会发现, 上面的两种层上的使用,都发生在真实数据在前向传播的时候,但我们真实构造网络的时候,就没有真实数据啊, 那这时候应该怎么用层的那种mask方式呢? 下面就是我探索的重点了哈哈。
为了模仿上面的Attention操作,我这里自己写了个带有attention机制的小网络:
先定义att层,也是接收的q, k, 只不过这里的attention采用了最简单的向量内积的方式求分数。
class att(Layer):
def __init__(self):
super(att, self).__init__()
def call(self, inputs, mask):
q, k = inputs
qs = tf.tile(q, multiples=[1, k.shape[1], 1])
qs = tf.reshape(qs, shape=[-1, k.shape[1], k.shape[2]]) # (None, maxlen, embed_dim)
att_score = K.softmax(tf.reduce_sum(qs*k, axis=-1))
# 去掉填充
paddings = tf.zeros_like(att_score)
att_score = tf.where(mask._keras_mask, att_score, paddings)
att_score = tf.expand_dims(att_score, axis=1)
att_out = tf.matmul(att_score, k)
att_out = tf.squeeze(att_out, axis=1)
return att_out
然后搭建了个模型, 当然这是一个多输入多输出的网络:
def model_stru(paddints):
# 第一种masking层的方式可以这样用, 放在embedding层之前,通过这种方式计算mask
unmask = tf.cast(tf.tile(tf.expand_dims(paddints, axis=-1), [1, 1, 10]), tf.float32)
masking_layer = Masking()
mask_embedding = masking_layer(unmask)
# 这里建立了两个输入层,一个embedding层, 一个LSTM层
input_layers1 = Input(shape=(6,))
input_layers2 = Input(shape=(1,))
embedding_layer = Embedding(10, 5, mask_zero=True)
lstm_layer = LSTM(12, return_sequences=True)
# 这里开始写前向传播的逻辑
k = embedding_layer(input_layers1)
#print(k, k.__keras_mask) 这句话会报错 'KerasTensor' object has no attribute '__keras_mask' 据说tf2.4下面的版本可以用,但是tf2.4这里不行了
q = embedding_layer(input_layers2)
att_output = att()([q, k], mask_embedding)
output = Dense(1)(att_output)
lstm_output = lstm_layer(k)
# 这里构造了个多输出
model = Model([input_layers1, input_layers2], [output, k, lstm_output])
return mask_embedding, model
# 模型建立
mask, model = model_stru(padded_inputs) # 这个padded_inputs 是填充后的输入
通过前向传播,传输数据之后,得到了下面的结果:
output, k, lstm_out = model([padded_inputs, item])
这时候,就可以用文档中的两种方式得到mask了:

这里也就是说, 如果想得到mask, 就需要先有数据进行前向传播, 那我们还是没有解决在建立模型的时候用mask啊。 其实解决了, 通过我上面的这个尝试,我得到了三个结论:
- Embedding层的这种获取mask的方式,在建立模型的时候不好用(tf2.4之后,会报错)
- Masking层的这种方式可以用的, 就是我定义att层的时候传入的那个mask,这里面是直接可以通过
mask._keras_mask属性获取序列的mask情况的。 所以现在我比较倾向于这种方式 - 就是DIN那里的老方法, 是根据填充情况单独定义出mask来,这个得保证原先数据中非0才行。注意,这个方法也不可行,上面DIN里面那样写是错误的,之前想错了,以为
mask_zero=True之后, 多出来的0 index会默认是0向量, 但调试了下发现不是, 所以这个写法就错误了。
这里还有种好的方式, 就是tf.sequence_mask的方式,我在DIN和DIEN模型复现里面用到了,可以参考DIEN这篇文章
所以, 我又尝试把上面的2这种方式写到了层里, 因为如果按照上面那个小demo中写的一样的话, 具体训练的时候, 会报错,因为这个直接把输入的维度给写死了(样本个数的维度), 但实际上,这个有个batch_size是可调的, 所以这样写具体训练的时候会报错。下面这个方式就欧克了:
class att(Layer):
def __init__(self):
super(att, self).__init__()
def call(self, inputs, mask):
q, k = inputs
qs = tf.tile(q, multiples=[1, k.shape[1], 1])
qs = tf.reshape(qs, shape=[-1, k.shape[1], k.shape[2]]) # (None, maxlen, embed_dim)
att_score = K.softmax(tf.reduce_sum(qs*k, axis=-1))
# 去掉填充
paddings = tf.zeros_like(att_score)
key_masks = tf.not_equal(k[:, :, 0], 0)
print(mask)
att_score = tf.where(mask, att_score, paddings)
att_score = tf.expand_dims(att_score, axis=1)
att_out = tf.matmul(att_score, k)
att_out = tf.squeeze(att_out, axis=1)
return att_out
def model_stru(paddints):
input_layers1 = Input(shape=(6,))
input_layers2 = Input(shape=(1,))
unmask = tf.cast(tf.tile(tf.expand_dims(input_layers1, axis=-1), [1, 1, 10]), tf.float32)
masking_layer = Masking()
mask_embedding = masking_layer(unmask)
embedding_layer = Embedding(11, 5, mask_zero=True)
k = embedding_layer(input_layers1)
q = embedding_layer(input_layers2)
att_output = att()([q, k], mask_embedding._keras_mask)
output = Dense(1)(att_output)
model = Model([input_layers1, input_layers2], [output])
return model
# 下面是测试代码 tf2.0版本上会过
item = np.array([[3], [2], [1], [8]])
model = model_stru(padded_inputs)
model.compile(loss='mse', optimizer='Adam', experimental_run_tf_function = False)
model.fit([padded_inputs, item], np.array([45, 21, 2, 1]), batch_size=2, epochs=3, )
这个在tf2.0版本上会运行成功, 但是在tf2.4版本上不行, 就想上面的第一种方式一样, 所以我发现,这俩版本之间差距还是蛮大的。
这个就是下午比较大的收获了。关于后面的简单了解下。
2.2 函数式API和序列式API中的掩码传播
在使用函数式 API 或序列式 API 时,由 Embedding 或 Masking 层生成的掩码将通过网络传播给任何能够使用它们的层(如 RNN 层)。Keras 将自动提取与输入相对应的掩码,并将其传递给任何知道该掩码使用方法的层。
例如,在下面的序贯模型中,LSTM 层将自动接收掩码,这意味着它将忽略填充的值:
model = keras.Sequential(
[layers.Embedding(input_dim=5000, output_dim=16, mask_zero=True), layers.LSTM(32),]
)
对以下函数式 API 的情况也是如此:
inputs = keras.Input(shape=(None,), dtype="int32")
x = layers.Embedding(input_dim=5000, output_dim=16, mask_zero=True)(inputs)
outputs = layers.LSTM(32)(x)
model = keras.Model(inputs, outputs)
这也就是上面用了个LSTM测试的原因,可惜没有发现啥新东西,也不知道过没过虑。
2.3 将掩码张量直接传递给层
这里是说,如果想自己设计层的时候,想自动处理掩码,和LSTM那样,需要在call方法中,将掩码生成层的comput_mask()方法传过去。
class MyLayer(layers.Layer):
def __init__(self, **kwargs):
super(MyLayer, self).__init__(**kwargs)
self.embedding = layers.Embedding(input_dim=5000, output_dim=16, mask_zero=True)
self.lstm = layers.LSTM(32)
def call(self, inputs):
x = self.embedding(inputs)
# Note that you could also prepare a `mask` tensor manually.
# It only needs to be a boolean tensor
# with the right shape, i.e. (batch_size, timesteps).
mask = self.embedding.compute_mask(inputs)
output = self.lstm(x, mask=mask) # The layer will ignore the masked values
return output
layer = MyLayer()
x = np.random.random((32, 10)) * 100
x = x.astype("int32")
layer(x)
也就是生成掩码的层(比如上面的embedding)会公开一个compute_mask(input,previous_mask)方法,因此,我们自己定义层的时候, 把这个方法的输出传递给掩码使用层的__call__方法。
2.4 在自定义层中支持mask
上面说的是掩码层的使用层如何怎么写才能处理掩码序列, 而这里是说如何让自己定义的层支持掩码呢?
您可能需要编写生成掩码的层(如 Embedding),或者需要修改当前掩码的层。
例如,任何生成与其输入具有不同时间维度的张量的层(如在时间维度上进行连接的 Concatenate 层)都需要修改当前掩码,这样下游层才能正确顾及被遮盖的时间步骤。
为此,您的层应实现 layer.compute_mask() 方法,该方法会根据输入和当前掩码生成新的掩码。
以下是需要修改当前掩码的 TemporalSplit 层的示例。
class TemporalSplit(keras.layers.Layer):
"""Split the input tensor into 2 tensors along the time dimension."""
def call(self, inputs):
# Expect the input to be 3D and mask to be 2D, split the input tensor into 2
# subtensors along the time axis (axis 1).
return tf.split(inputs, 2, axis=1)
def compute_mask(self, inputs, mask=None):
# Also split the mask into 2 if it presents.
if mask is None:
return None
return tf.split(mask, 2, axis=1)
first_half, second_half = TemporalSplit()(masked_embedding)
print(first_half._keras_mask)
print(second_half._keras_mask)
这个目前不知道咋用, 后面还有几个, 比如在兼容层上启用掩码传播,编写需要掩码信息的层等, 都没有用过,这里就先不整理了,具体的可以参考官方文档,等用到了在做一波尝试。
下面再整理一个有意思的事情。
3. tf1版本中的dynamic_rnn
还是接着上面的变长序列,填充之后的样子:
假设经过个embedding之后的处理: embedding的维度是10维
unmasking_embedding = tf.cast(tf.tile(tf.expand_dims(padded_inputs, axis=-1), [1, 1, 10]), tf.float32)
上面这个就变成了一个【4,6,10】的三维张量, 这里6是时间步长, 10是embedding维度,4是样本个数。显然这个是经过了填充的。
如果这个东西是过正常的LSTM网络的话,会是这个样子:
rnn_out = LSTM(12, return_sequences=True)(unmasking_embedding)
这里先介绍下LSTM后面的参数汇总return_sequences和return_state的区别哈:
- 如果后面既不指明
return_sequences,也不指明return_state的话,此时返回值仅仅是最后一个时间步的隐藏状态值 - 而如果指明了
return_sequences之后,返回的是所有时间步的隐藏状态h的值,这个在many-to-many结构中是非常有用的。这哥们控制的是h的输出。 - 如果指明了
return_state之后,返回的是最后一个时间步的隐藏状态h, 最后一个时间步的隐藏状态h和最后一个时间步的隐藏状态c, 控制的是c的输出。
这里的rnn_out的维度我们就很清楚了[4, 6, 12], 这里看下其中的一个时间步的输出值:
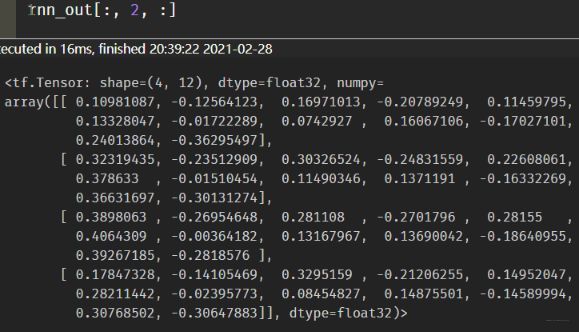
这里会发现4个样本在第二个时间步的h都是有输出值的。 这其实不太合理的,因为我们上面的第一个样本来说,第二个时间步的时候是填充的值,本来是没有这个的啊,所以这个时候不应该有h的值的。这个如果不明显,我们再看第三个时间步的输出:
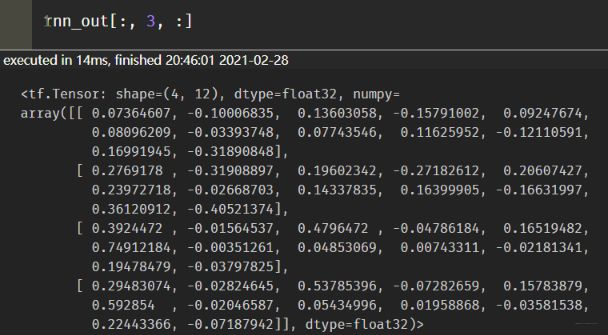
这里依然会发现每个样本都会有值, 而第一个第二个样本的第三个时间步其实是用了填充的。
那怎么让它合理呢? 也就是填充的时间步的值不让他有呢?这里我探索了两个方法, 一个是在这个基础上把之前的那种mask拿过来进行遮盖。比如我这样测试了下:
# 这里的t._keras_mask也可以换成其他能得到mask的方式
mask_rnn_out = tf.expand_dims(tf.cast(tf.where(k._keras_mask, 1, 0), tf.float32), axis=2) * rnn_out
这时候再看结果:
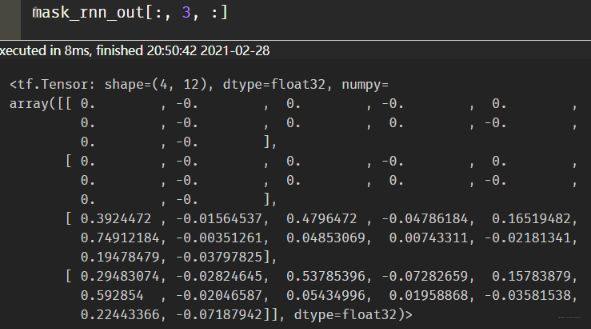
这样就比较合理了。 当然如果再搭建具体网络的时候,还是建议用Masking层的方式传mask,因为这里还是先有的输入,再进行的计算。
第二种比较不错的方式,就是直接使用tf1中保留的dynamic_rnn的方式。关于这个东西的具体介绍,可以参考这篇博客
cell = tf.compat.v1.nn.rnn_cell.BasicLSTMCell(12, state_is_tuple=True)
output, laststate = tf.compat.v1.nn.dynamic_rnn(cell, unmasking_embedding, dtype=tf.float32, sequence_length=[2,3,5,6])
这里我直接写了用法, 这个东西是V1保留的,在tf2中没有了这东西。 首先, 得先定义一个基础的cell,这个可以是LSTM,也可以是GRU。 然后就是直接调用这个东西就好了,需要传入cell的类型, 接收的输入,还要指明类型和每个样本的真实序列长度(要不然没法计算啊,谁知道每个多长)。 这个函数的返回值有两个,output表示的是所有时间步h值, 而laststate是最后一个时间步的h和c。 我们运行下这个, 得到的output依然是[4,6, 12]的张量。 看下第三个时间步时的h。
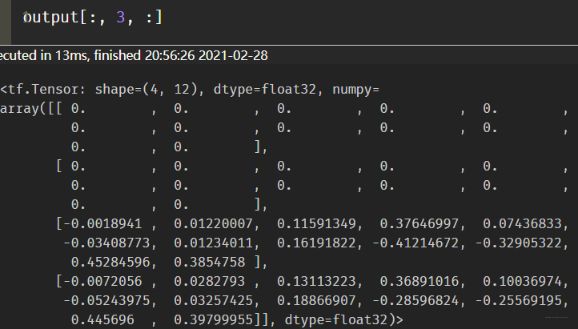
这个动态的RNN就是直接把填充的那部分值的隐藏状态不计算了,给过滤掉,只保留有效的。所以对于变长的序列,过RNN的话,这也是一种不错的方式。
最后还探索了一个东西,叫做Time Distributed, 这个也是keras的一个层。
4. Time Distributed
这个东西的主要用途在于Many-to-Many: 比如输入的shape为(1,5,1), 输出的shape为(1,5,1)的话就可以这么写:
model = Sequential()
model.add(LSTM(3, input_shape=(length, 1), return_sequences=True))
model.add(TimeDistributed(Dense(1)))
根据上面解读,return_sequences=True,使得LSTM的输出为每个timestep的hidden state,shape为(1, 5, 3)。
现在需要将这个(1,5,3)的3D tensor变为(1,5,1)的结果,需要3个Dense Layer分别作用于每个time step的输出。 而使用了TimeDistributed后,则把一个相同的Dense layer去分别作用,可以使得网络更为紧凑,参数更少的作用。如果是在many-to-one的情况,return_sequence=False,则LSTM的输出为最后一个time step的hidden state,shape为(1, 3)。此时加上一个Dense layer, 不用使用TimeDistributed,就可以将(1, 3)变换为(1, 1)。
当然这个东西不仅可以包装Dense层,还可以包装卷积啥的各种层, 可以减少参数量,相当于用这个一个层多次作用。关于更详细的用法,参考这篇博客