PyLMKit(3):基于角色扮演的应用案例
角色扮演应用案例RolePlay
0.项目信息
- 日期: 2023-12-2
- 作者:小知
- 课题: 通过设置角色模板并结合在线搜索、记忆和知识库功能,实现典型的对话应用功能。这个功能是大模型应用的基础功能,在后续其它RAG等功能中都会用到这个功能。
- 功能与作用:RolePlay角色扮演是一种基础功能,也是重要的功能。现在在各大大模型企业的APP中可以看到很多关于短视频文案、小红书文案、高情商朋友圈等这些功能的底层逻辑是基于角色扮演中设置不同的角色模板实现的。
- GitHub:https://github.com/52phm/pylmkit
- PyLMKit官网教程
- PyLMKit应用(online application)
- English document
- 中文文档
PyLMKit RolePlay
1.下载安装
# 下载安装
pip install pylmkit -U --user
2.设置API KEY
应用哪个大模型,就提前设置好该大模型对应的 API KEY
import os
# openai chatgpt
os.environ['openai_api_key'] = ""
# 百度
os.environ['qianfan_ak'] = ""
os.environ['qianfan_sk'] = ""
# 阿里
os.environ["DASHSCOPE_API_KEY"] = ""
# 科大讯飞-星火
os.environ["spark_appid"] = ""
os.environ["spark_apikey"] = ""
os.environ["spark_apisecret"] = ""
os.environ["spark_domain"] = "generalv3"
# 智谱AI
os.environ['zhipu_apikey'] = ""
或者在.env文件中批量加载设置好的API KEY,加载方法如下:
from dotenv import load_dotenv
# load .env
load_dotenv()
3.加载大语言模型
导入大语言模型,在本案例中使用百度千帆大模型作为例子进行介绍。
from pylmkit.llms import ChatQianfan # 百度-千帆
from pylmkit.llms import ChatSpark # 讯飞-星火
from pylmkit.llms import ChatZhipu # 清华-智谱
from pylmkit.llms import ChatHunyuan # 腾讯-混元
from pylmkit.llms import ChatBaichuan # 百川
from pylmkit.llms import ChatTongyi # 阿里-通义
from pylmkit.llms import ChatOpenAI # OpenAI
model = ChatQianfan()
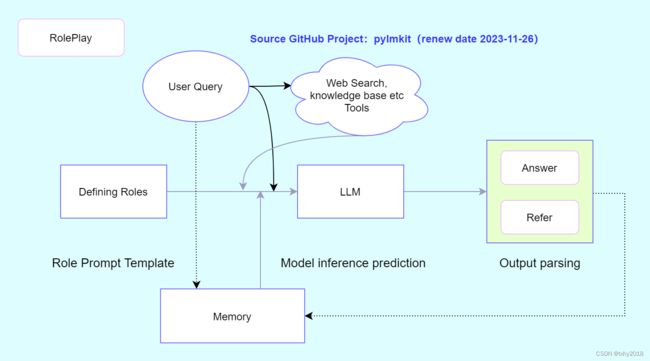
4.选择记忆功能
PyLMKit 设计了四种记忆功能,分别如下:
- MemoryHistoryLength:记忆历史长度,强调使用近期多长的记忆内容;
- MemoryConversationsNumber:记忆对数数,强调使用近期N组对话作为记忆的内容;
- MemorySummary:记忆摘要,强调精简提取记忆;
- 暂未公布
本案例使用MemoryHistoryLength记忆功能,使得大语言模型能到根据该历史记忆记住上下文内容,以便连贯回答用户的问题。(更多关于记忆的用法,可以在后续memory专题中查阅)
from pylmkit.memory import MemoryHistoryLength
memory = MemoryHistoryLength(memory_length=500, streamlit_web=False) # 在python中运行
# memory2 = MemoryHistoryLength(memory_length=500, streamlit_web=True) # 在streamlit web中运行
5.设计角色模板
大语言模型是一种一对多关系的模型架构,其中一表示大语言模型,而多表示下游任务,比如写作、客服、分析数据等这些都属于下游任务。
因此需要我们通过设计提示词模板去引导大语言模型高效且有质量地完成指定下游任务。
在设计角色模板之前,我们先来了解PyLMKit中一些必须固定的关键词:
- {query}:表示这是用户输入的提问内容;
- {search}:表示线上实时搜索引擎搜索返回的内容;
- {memory}:表示记忆的内容;
- {ra}:表示知识库搜索返回的内容。
下面我们来看一个角色模板的例子:
# 它们所在的位置,表示它们内容所嵌入的位置
role_template = "{memory}\n {search}\n 用户提问:{query}"
# 当然,你还可以进一步设计模板
role_template = "历史对话内容:{memory}\n 搜索的相似内容:{search} {ra}\n 请结合上述内容回答问题:{query}"
model.invoke(query="如何学习python?")
角色模板决定大语言模型回答的质量,因此角色模板需要反复打磨,以设计一个高质量的角色模板,对问题的解决效果可以达到事半功倍。
另外,值得注意的是,如果你设计的角色模板的关键词,不在[query, search, ra, memory]中,那么你需要额外添加新的变量和变量值,例如:
role_template = "{memory}\n 请为我推荐{query}的{topic}"
# 额外的关键字,可以像 topic="美食" 一样添加,多个也是一样的步骤进行添加
model.invoke(query='北京', topic="美食")
role_template = "{memory}\n 请为我推荐{query}的{topic}"
6.加载角色扮演应用
RolePlay角色扮演是一种基础功能,也是重要的功能。现在在各大大模型企业的APP中可以看到很多关于短视频文案、小红书文案、高情商朋友圈等这些功能的底层逻辑是基于角色扮演中设置不同的角色模板实现的。
from pylmkit.app import RolePlay
rp = RolePlay(
role_template=role_template, # 角色模板
llm_model=model, # 大语言模型
memory=memory, # 记忆
# online_search_kwargs={},
online_search_kwargs={'topk': 2, 'timeout': 20}, # 搜索引擎配置,不开启则可以设置为 online_search_kwargs={}
return_language="中文"
)
7.在python中运行
while True:
query = input("User query:")
topic = input("User topic:")
response, refer = rp.invoke(query, topic=topic)
print("\nAI:", response)
print("\nRefer\n:", refer)
User query:北京
User topic:美食
2023-12-02 01:28:27 - httpx - INFO - HTTP Request: POST https://duckduckgo.com "HTTP/2 200 OK"
2023-12-02 01:28:29 - httpx - INFO - HTTP Request: GET https://links.duckduckgo.com/d.js?q=%E5%8C%97%E4%BA%AC&kl=wt-wt&l=wt-wt&s=0&df=&vqd=4-45222965241755774163610013696327482249&o=json&sp=0&ex=-1 "HTTP/2 200 OK"
AI: 北京有很多美食,以下是为您推荐的一些美食:
1. 北京烤鸭:是北京最著名的传统美食,具有独特的皮脆肉嫩、肥而不腻的口味。
2. 炸酱面:是一道非常受欢迎的主食,面条劲道,炸酱味道浓郁,可以搭配各种蔬菜和肉类。
3. 炒肝:是一种传统早点,主要原料是猪大肠和猪肝,口感鲜美,适合早餐食用。
4. 羊肉串:是北京街头巷尾最常见的烧烤之一,肉质鲜嫩,味道鲜美。
5. 豆汁儿:是北京传统特色小吃之一,由绿豆制作而成,味道独特,需要慢慢品尝。
6. 爆肚:是北京传统小吃,口感鲜美,特别适合夏天食用。
7. 涮羊肉:是一种传统的火锅美食,口感鲜美,涮出的羊肉非常嫩滑。
除此之外,北京还有各种烤肉、烧麦、饺子、包子、馄饨等美食,您可以根据自己的口味选择尝试。
Refer
: [1] **https://zh.wikipedia.org/wiki/北京市** 北京古迹众多,著名的有紫禁城、天坛、颐和园、圆明园、北海公园等;胡同和四合院作为北京老城的典型民居形式,已经是北京历史重要的文化符号 。北京是中国重要的旅游城镇,被《米其林旅游指南》评为"三星级旅游推荐"(最高级别)目的地 。
[2] **https://baike.baidu.com/item/北京市/126069** 北京市(Beijing),简称"京",古称燕京、北平,中华民族的发祥地之一,是中华人民共和国首都、直辖市、国家中心城市、超大城市,国务院批复确定的中国政治中心、文化中心、国际交往中心、科技创新中心,中国历史文化名城和古都之一,世界一线城市。截至2023年10月,北京市下辖16个区,总 ...
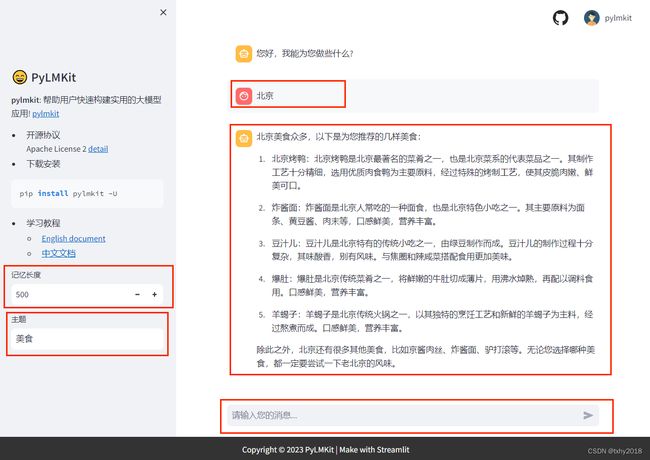
8.在streamlit web中运行
要在终端中运行:假设你的.py文件名为main.py,那么在终端运行:
streamlit run main.py
main.py
# main.py
# main.py
from pylmkit import BaseWebUI
from dotenv import load_dotenv
from pylmkit.app import RolePlay
from pylmkit.llms import ChatOpenAI
from pylmkit.memory import MemoryHistoryLength
from pylmkit.llms import ChatQianfan
load_dotenv()
web = BaseWebUI(language='zh') # 中文网站
model = ChatQianfan(model="ERNIE-Bot-turbo")
memory = MemoryHistoryLength(memory_length=web.param(label="记忆长度", type='int', value=500), # 添加页面交互参数
streamlit_web=True
)
role_template = "{memory}\n 请为我推荐{query}的{topic}"
rp = RolePlay(
role_template=role_template, # 角色模板
llm_model=model, # 大语言模型
memory=memory, # 记忆
# online_search_kwargs={},
online_search_kwargs={'topk': 2, 'timeout': 20}, # 搜索引擎配置,不开启则可以设置为 online_search_kwargs={}
return_language="中文"
)
web.run(
obj=rp.invoke,
input_param=[{"name": "query", "label": "地点", "type": "chat"},
{"name": "topic", "label": "主题", "type": "text"},
],
output_param=[{'label': '结果', 'name': 'response', 'type': 'chat'},
{'label': '参考', 'name': 'refer', 'type': 'refer'}
]
)
页面效果如下:
9.GitHub项目地址
觉得不错,可以帮忙点个 star 哦
GitHub - 52phm/pylmkit: pylmkit: Help users quickly build practical large model applications!