PyLMKit(2):快速开始大模型应用开发
快速开始
- GitHub:https://github.com/52phm/pylmkit
- PyLMKit 官方教程
- PyLMKit应用(online application)
- English document
- 中文文档
0.下载安装
pip install -U pylmkit --user
1.设置 API KEY
- 一个方便的方法是创建一个新的.env文件,并在其中配置所有的API密钥信息,从而方便地使用不同的模型。.env文件的格式如下:
# OpenAI
openai_api_key = ""
# 百度-千帆
QIANFAN_AK = ""
QIANFAN_SK = ""
# 阿里-通义
DASHSCOPE_API_KEY = ""
# 科大讯飞-星火
spark_appid = ""
spark_apikey = ""
spark_apisecret = ""
spark_domain = "generalv3"
# 清华-智谱AI
zhipu_apikey = ""
# 百川
baichuan_api_key = ""
baichuan_secret_key = ""
# 腾讯-混元
hunyuan_app_id = ""
hunyuan_secret_id = ""
hunyuan_secret_key = ""
加载.env文件的方法如下(建议将.env文件放置在与您运行的.py文件相同的路径下)。
from dotenv import load_dotenv
# load .env
load_dotenv()
- 另一种方法是通过os.environ进行配置,下面是一个例子:
import os
# openai
os.environ['openai_api_key'] = ""
# 百度
os.environ['qianfan_ak'] = ""
os.environ['qianfan_sk'] = ""
2.LLM模型使用
LLM模型可以使用PyLMKit导入,也支持使用LangChain导入模型。导入其他模型例子:
from pylmkit.llms import ChatQianfan # 百度-千帆
from pylmkit.llms import ChatSpark # 讯飞-星火
from pylmkit.llms import ChatZhipu # 清华-智谱
from pylmkit.llms import ChatHunyuan # 腾讯-混元
from pylmkit.llms import ChatBaichuan # 百川
from pylmkit.llms import ChatTongyi # 阿里-通义
from pylmkit.llms import ChatOpenAI # OpenAI
model = ChatOpenAI()
# 普通模式
res = model.invoke(query="如何学习python?")
print(res)
# 流式模式
res = model.stream(query="如何学习python?")
for i in res:
print(i)
3.角色扮演应用
- 角色模板
用户可根据自身情况调整角色模板。在模板中,{memory} 表示上下文记忆的位置,{search} 表示搜索引擎的内容,{query} 表示用户输入的问题。
- 返回值
该算法返回两个值:“response”和“reference”。“response”表示返回的内容,“reference”表示引用信息,例如使用搜索引擎时对网页的引用。
from dotenv import load_dotenv
from pylmkit.app import RolePlay
from pylmkit.llms import ChatOpenAI
from pylmkit.memory import MemoryHistoryLength
from pylmkit.llms import ChatQianfan
# load .env
load_dotenv()
# load llm model
model = ChatOpenAI()
# model = ChatQianfan(model="ERNIE-Bot-turbo")
# memory type
memory = MemoryHistoryLength(memory_length=500)
# roleplay: Enable memory and search functions.
# rp = RolePlay(
# role_template="{memory}\n {search}\n User question :{query}",
# llm_model=model,
# memory=memory,
# online_search_kwargs={'topk': 2},
# )
# roleplay: Only activate memory function.
rp = RolePlay(
role_template="{memory}\n User question :{query}",
llm_model=model,
memory=memory,
online_search_kwargs={},
return_language='中文'
)
while True:
query = input("input...")
response, refer = rp.invoke(query)
print(response)
4.Streamlit Web 运行角色扮演应用
- 步骤1: 创建一个新的.py文件,例如main.py。
from pylmkit import BaseWebUI
from dotenv import load_dotenv
from pylmkit.app import RolePlay
from pylmkit.llms import ChatOpenAI
from pylmkit.memory import MemoryHistoryLength
from pylmkit.llms import ChatQianfan
# load .env
load_dotenv()
# load llm model
model = ChatOpenAI()
# model = ChatQianfan(model="ERNIE-Bot-turbo")
# memory type
memory = MemoryHistoryLength(memory_length=web.param(label="记忆长度", type='int', value=500), # 添加页面交互参数
streamlit_web=True
)
# roleplay: Only activate memory function.
rp = RolePlay(
role_template="{memory}\n User question :{query}",
llm_model=model,
memory=memory,
online_search_kwargs={},
return_language='中文'
)
# init web
web = BaseWebUI()
web.run(
obj=rp.invoke, # Designated main function.
input_param=[{"label": "User input", "name": "query", "type": "chat"}, # type, chat text string bool float ...
],
output_param=[{'label': 'response content', 'name': 'ai', 'type': 'chat'},
{'label': 'refer info', 'name': 'refer', 'type': 'refer'} # type, chat refer text string bool float ...
]
)
- 步骤2: 运行web程序
在与main.py相同目录的终端命令行中,输入
streamlit run main.py
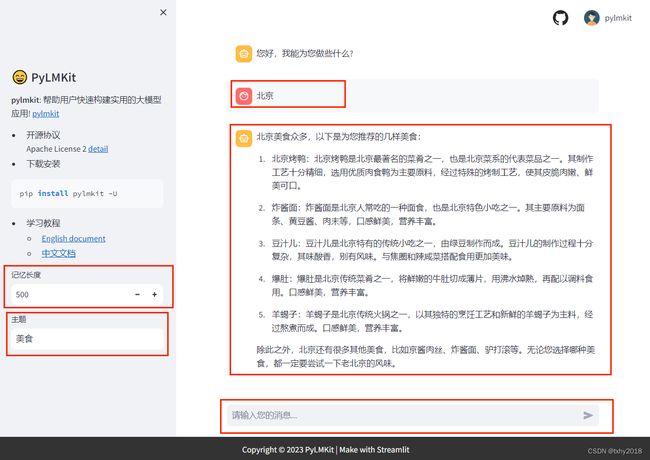
页面类似效果如下
5.GitHub项目地址
觉得不错,可以帮忙点个 star 哦
GitHub - 52phm/pylmkit: pylmkit: Help users quickly build practical large model applications!