手写操作系统(5)——CPU工作模式与虚拟地址
CPU工作模式
按照CPU功能升级迭代的顺序,CPU的一共有三种工作模式:实模式、保护模式、长模式。
在不同的工作模式下,CPU执行程序的方式不同,至于有什么不同以及为什么会造成不同,接着往下看。
实模式(Real Mode)
实模式,何为实?
一是指运行的指令是真实的,没有权限区分;
二是指运行的地址是真实的,与内存地址一一对应,并且可以操控任意位置的内存。
内存寻址
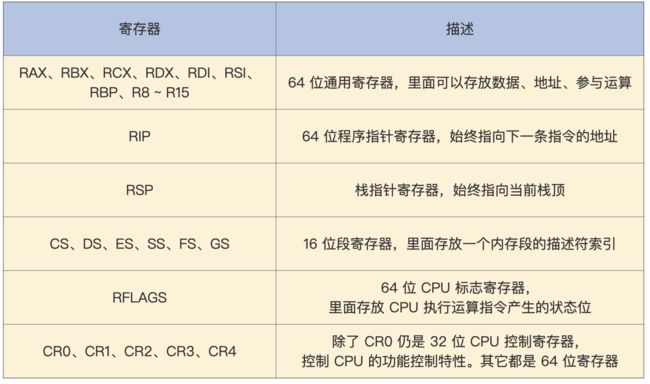
在理解实模式运行过程之前,先来看看在X86 CPU实模式下的寄存器有哪些:
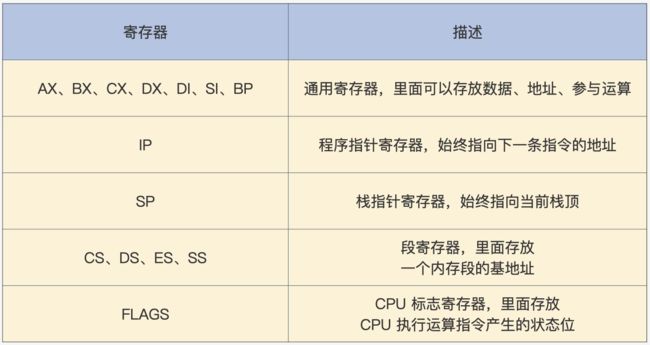
上面这些寄存器有什么用?
当CPU运行某段指令时,需要先将指令从存储介质,如内存、硬盘中取出放到对应的寄存器中,CPU才可以执行这段指令。而取出指令或指令所需的数据时,也需要寄存器来确定内存地址,一般是**段基地址+偏移地址,**以8086CPU(16位寄存器,20位内存寻址)为例,访问内存地址数据如下:
这就是早期的分段式内存管理模式,代码段由CS+IP来确定,栈段由SS+SP来确定。
执行中断
所谓中断即是中断执行当前的指令,转而去执行指定的指令。中断分为硬件中断和软中断。
硬件中断是某个设备的中断控制器给CPU发送特定的电信号,CPU对其作出应答,并获取中断控制器发送的中断号。
**中断号是什么?**往下看。
软件中断就是CPU执行的指令为**INT 常数。**这个常数也是上文所说的中断号。
中断号可以看作是“excel表格”的行号,当CPU获取到中断号时,就会去加载一个特定“表格”指定行的内容,并根据其内容执行相应的指令。
上文所说的“excel表格”就是存放在内存中的中断向量表(在BIOS阶段加载到内存的),这个表的地址和长度由特定寄存器IDTR指向,表中一条记录由代码段地址和代码段内偏移地址组成,如下:
在实模式下,中断即是保存CS、IP(当前指令执行到哪了)及相关数据到栈中,然后根据中断号去中断向量表中装载新的内容到CS、IP寄存器中,从而实现中断响应。
保护模式
从前面的介绍了解到,实模式对于指令和地址不加区分,这其实会造成很大的隐患——如果某个程序恶意修改某个内存地址的内容从而造成系统崩溃怎么办?
但是凡事皆应该有限度,CPU执行代码也不例外。
保护模式就是对CPU执行指令的权限、内存地址加以限制,从而保证计算机运行稳定。
内存寻址
保护模式下对CPU指令和地址加以限制是通过一些额外的寄存器来实现的,:

**为了区分哪些指令(如 in、out、cli)和哪些资源(如寄存器、I/O 端口、内存地址)**可以被访问,CPU 实现了特权级。CPU特权级共分为4级,R0~R3,其中R0具有最高权限,可以执行所有指令,而后的R123依次递减,如下:

为了实现对内存段的保护,我们需要对各内存段进行区分,我们将其称为段描述符,并放置在内存中,一个段描述符64位,其中包含段基地址、段长度、段权限、类型、可读、可写等,其格式如下:
将多个这样的段描述符组合在一起便有了全局段描述符表GDT,该表的基地址和长度(表明该表的起始和界限)由CPU的GDTR寄存器指出,如下图所示。
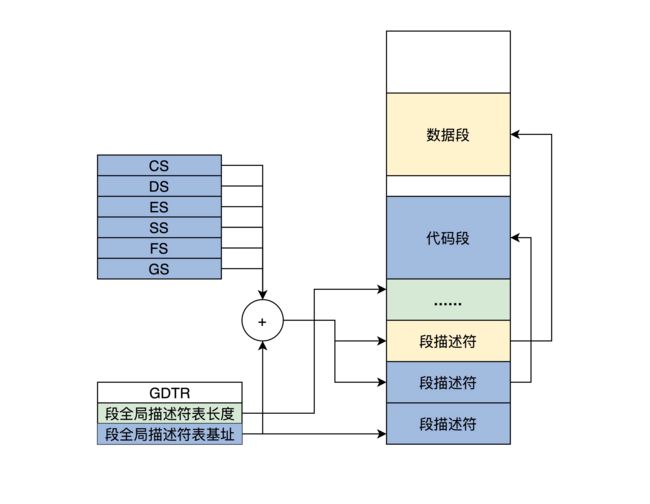
实模式下进行内存访问时CS、DS、ES等段寄存器中存储的是段基地址,但是在保护模式下,进行内存访问时需要通过一个段选择子(Selector)来决定是否有权利访问及具体的访问位置。
段选择子主要有三个部分:**段描述符索引、TI、请求特权级,**如下图所示(暂不考虑前面64位的影子寄存器):

根据段描述符索引索引及GDT表中的全局描述符表基址就可以找到该内存的段描述符。
PS:这里的设计很好的节约了空间,由于每个段描述符是64位8字节,因此每个索引之间的差距就是8字节(1000 2000 3000``````),因此低三位可以用作他途(不用的话总为0,浪费了),存储TI和RPL。在实际计算的时候对索引左移三位就可以了。
TI表示该内存段描述符是在GDT中还是在LDT中,LDT可以看成是GDT的子集,是某个任务所需内存段描述符的集合表。LDT所在内存段地址也是通过GDT中的段选择子找到的,如果说GDT是一级查询表,LDT就是二级查询表。详情可见:LDT详解。
RPL表示请求访问内存的执行程序的当前权限级别(CPL),CPL是由CS和SS的RPL组成的,通常RPL=CPL。而后只有当RPL<=段描述符中的DPL时,才能够访问。
PS:特权级越低,特权越大(R0)。
影子寄存器又称为段描述符高速缓冲寄存器,是为了避免每次都访问GDT而采用硬件提速的方式来缓存对应的段描述符。
平坦模型与分页
内存分段模型相较于内存分页模型有很多缺陷(使用率、置换等),因此现代操作系统常用的是内存分页模型。不过X86 CPU需要在分段的前提下根据需要进行分页,而平坦模型则是通过让分段“虚假”,从而达到必定分页的目的:
可知,32位的寄存器最高寻址空间为4GB,因此一个段长度最大也只能为4GB,如果将所有段的基地址设为0,长度设为0xfffff,段长度的粒度设为4KB,则所有段都指向同一个地址空间:0~4GB-1(1M个4K大小的地址空间)。
执行中断
同内存访问一样,在保护模式下执行中断也需要进行权限判断,因此需要像段描述符一样扩展中断向量表中的信息,将扩展后的中断向量中的信息称为中断描述符(中断门),其格式如下:
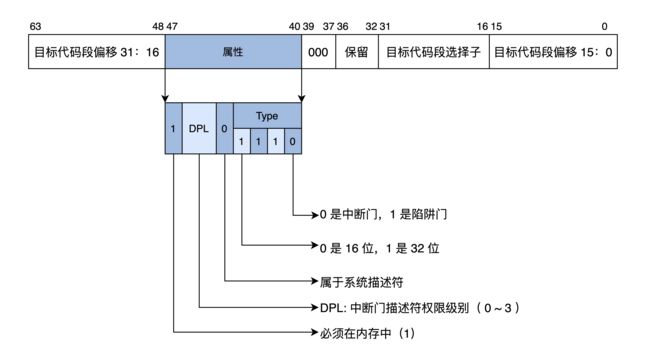
将中断描述符组合放在内存中,即是中断门描述符表IDT,加载在相应的寄存器IDTR中,通过中断号来获取相应的中断门描述符流程如下:

产生中断时,CPU根据中断号去获取相应的中断门描述符,会进行如下判断:
-
中断号是否越界(如X86最大是256)
-
中断/陷阱门(中断门进入中断自动将IF设为0,从而防止嵌套中断//可以人为打开//,而陷阱门不会,因此陷阱门适合处理异常)
-
1表示在内存中
-
进行权限检查,这一步骤详细过程如下:
CPL<=中断门描述符的DPL(必须有足够高的权限才能进行中断),进入下一步;否则抛出一个保护异常;
CPL>=描述符中段选择子的DPL(特权级不能过高,不然还需要中断做什么,而且禁止进行高特权向低特权的转换),进入下一步;否则抛出一个保护异常;
如果CPL=段选择子指向的段描述符中的DPL,则表示同级权限,不用进行栈切换;否则,需要进行栈切换,需要从TSS中加载具体权限的各寄存器值。有关上述权限切换,可以参考:Linux权限切换。
PS:TR是任务寄存器,用于寻址任务状态段(Task State Segment,TSS),TSS存储当前执行任务的相关信息,也是64位8字节。
TR寄存器用于存放当前任务TSS段的16位段选择符、32位基地址、16位段长度和描述符属性值。它引用GDT表中的一个TSS类型的描述符。当执行任务切换时,处理器会把新任务的TSS的段选择符和段描述符自动加载进任务寄存器TR中。
在进行完上述流程之后,CPU才会加载目标中断代码进行中断服务程序的执行。
开启保护模式
X86 CPU加电后自动进入实模式,那么如何切换到保护模式呢?
- 准备全局段描述符GDT
GDT_START:
//CPU硬件要求第一个段描述符为0
knull_dsc: dq 0
//dq表示4个字,8字节
kcode_dsc: dq 0x00cf9e000000ffff
kdata_dsc: dq 0x00cf92000000ffff
GDT_END:
GDT_PTR:
GDTLEN dw GDT_END-GDT_START-1
GDTBASE dd GDT_START
- 让GDTR指向GDT
lgdt [GDT_PTR]
- 设置CR0,开启保护模式
;开启 PE
mov eax, cr0
bts eax, 0; 将CR0.PE =1,即打开保护模式
mov cr0, eax
- 长跳转,刷新CS段寄存器
jmp dword 0x8:_32bits_mode ;//_32bits_mode为32位代码标号即段偏移
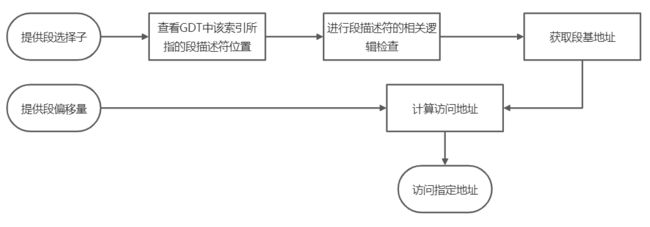
(***)上述0x8:32位_段偏移,是一个长跳转,发现CR0的值为1,因此CPU处于保护模式,这时0x8即为上文中的段选择子:0000 0000 0000 1000,从GDTR中根据索引号8,去获取相应的段描述符,在加上32位_段偏移,最终实现了一次内存访问!
PS:虽然我们想让CS段寄存器更新,CS段寄存器无法通过mov等直接赋值的操作进行赋值,指令集没有设计这样的功能,只能通过跳转等方法来改变它。
PS:汇编中jmp是跳转指令,
jmp short 标号 段间跳转 -128-127
jmp far ptr 标号 超段转移 跳转包含目标地址
jmp reg 16位寄存器
jmp word ptr 内存单元地址 段内转移
jmp dword ptr 内存单元地址 ( 段间间接转移) 高字地址存放cs 低字节存放ip。
jmp 1000H:2000H 段间直接转移,段码和偏移量直接给出
小结
我们来看看在保护模式下进行一次段偏移的流程是如何进行的:
长模式
长模式最早是由AMD指定的标准。相比于保护模式,长模式进一步将地址拓宽到了64位,并弱化了内存的段管理机制,采用页面管理的方式并引进了MMU进行内存地址转换。
内存寻址
长模式下的寄存器最大可使用64位,最小可使用8位,如下:
长模式下段描述符格式如下:
在长模式下,CPU 不再对段基址和段长度进行检查,只对 DPL 权限进行相关的检查。
开启长模式
来看看如何实现保护模式切换到长模式:
- 准备长模式全局段描述符
ex64_GDT:
null_dsc: dq 0 ;第一个段描述符CPU硬件规定必须为0
c64_dsc:dq 0x0020980000000000 ;64位代码段
;无效位填0
;D/B=0,L=1,AVL=0 ;P=1,DPL=0,S=1;T=1,C=0,R=0,A=0
;段长度和段基址都是无效的填充为 0,CPU 不做检查。
;但是上面段描述符的 DPL=0,这说明需要最高权限即 CPL=0 才能访问。
d64_dsc:dq 0x0000920000000000 ;64位数据段
;数据段的话,G、D/B、L 位都是无效的
eGdtLen equ $ - null_dsc ;GDT长度
eGdtPtr:dw eGdtLen - 1 ;GDT界限
dq ex64_GDT
- 准备MMU页表
mov eax, cr4
bts eax, 5 ;CR4.PAE = 1
mov cr4, eax ;开启 PAE
mov eax, PAGE_TLB_BADR ;页表物理地址,假设页表数据已经准备好了
mov cr3, eax
;上面的操作是为了指定页表位置
提一句,长模式有关内存的保护都由MMU来进行,而MMU主要根据页表对内存地址进行转换,CPU的CR3寄存器指向页表。
- 加载GDT到GDTR寄存器
lgdt [eGdtPtr]
- 开启长模式
;开启 64位长模式
mov ecx, IA32_EFER
rdmsr
bts eax, 8 ;IA32_EFER.LME =1
wrmsr
;开启 保护模式和分页模式
mov eax, cr0
bts eax, 0 ;CR0.PE =1
bts eax, 31
mov cr0, eax
- 加载段寄存器,刷新CS寄存器
jmp 08:entry64 ;entry64为程序标号即64位偏移地址
同保护模式的作用。
虚拟地址
基本概念
在多道程序的场景下,关于内存有四个核心问题:
-
多个程序之间如何保证内存地址不冲突?由操作系统决定还是多个程序来决定?
-
如何保证多个程序之间不会访问彼此的内存?保护模式?
-
如何解决内存容量的问题?即内存装不下了。
-
每台计算机的内存是不一样的,如何保证程序在这些计算机上兼容运行?
解决上述问题的一个方案是:每个程序都享有一个从0到最大内存的地址空间,这个地址是程序之间独立的,每个程序所私有的。
上述方案就是虚拟地址空间。
如何形象化地理解虚拟地址空间?关键就在于映射。
假设实际物理内存地址空间大小从0~999。
我们让程序A、B、C觉得自己能够使用的内存地址空间也为0~999,它们可以随意访问这些地址。
等等……这样三个程序难道不会冲突么?要是三个程序同时访问599地址怎么办?
关键来了,那就是地址映射表。三个程序分别有三个表,其中索引为每个程序访问的地址,结果为实际物理内存地址,假设程序A的映射表如下:
| 索引(虚拟地址) | 结果(实际地址) |
|---|---|
| 599 | 123 |
| 123 | 599 |
| … | … |
每个程序都有一个上面这样的映射表,表示自己的地址与实际地址的一一对应关系,我们将这个映射表称为页表。不用考虑会不会出现两个程序映射的实际地址是一样的情况,放心,不存在的,操作系统已经协调好嘞!
PS:程序自身的地址其实是由链接器生成的,链接阶段就是对多个模块进行地址的重排和引用。
页表
值得注意的是,如果页表中存储的是每一个虚拟地址到物理地址的映射关系,那么整个内存只能全部用来存储这个映射关系了。
整个地址空间存储的都是每个虚拟地址对应的实际地址,那么内存还有空余么?
我们采用一种折中的方式,**将地址空间分成一个一个小块,**每一块的大小可以为1KB、2KB、4KB甚至1GB等,其中小块也称为页,这就是分页模型。将原本每一个地址与地址的映射关系,改为虚拟也与物理页的对应关系,于是这样的映射关系如下:

MMU下一节会讲,简单理解它就是一个加快映射的硬件。
经过上面的讨论,也许会认为分页模型就是简单的一张表,从而实现虚拟地址到物理地址的转换,但实际设计中却并没有这么简单。
假设有4GB的内存(32位机),将分页大小设为4KB,于是一共有1M个内存页。
那么存储这些对应关系需要多少内存?
如果一个页表映射关系4B,1MB个内存页映射就需要4MB连续的内存空间,当以后内存地址空间增大,用于存储映射关系的空间还会继续膨胀,浪费内存空间。
因此,实际的页表使用一般是采用分级的思想,类似于查字典,先查部首或者拼音首字母,再查询接下来的部分,如下图是一个三级页表的概念图:
以一次三级页表查询为例,将虚拟地址分为了四段:
-
第一次,MMU使用虚拟地址第一段的中间页目录索引去访问顶级页目录,获得了中级页目录的地址;
-
第二次,MMU使用第二段的页表地址索引去访问中级页目录,获得了页表的地址;
-
第三次,MMU使用第三段的物理页地址去访问页表,获得了物理内存页的地址;
-
第四次,MMU使用第四段的偏移地址在物理内存页找到真实的内存地址,从而完成一次内存访问。
从上述流程可以看出,多级页表有一个显著缺点——增加内存访问次数。
原本我只想访问一个内存地址,但是由于三级页表的存在,我需要先进行多次中间页表的获取,才能够进行最终的内存访问。
它的优点也很明显,每一级页表所占用的空间减小,可以离散存储页表,并且在某种程度上节省页表的内存空间。
PS:因为对于一些页,甚至不需要构建它的完整页表,因为没有使用。
比如hello world程序,这样一个几kb的程序却需要4MB的内存空间是很浪费的。如果采用二级页表,那么一级页表只需要4KB的空间用来索引二级页表的地址,像hello world这样的程序可能只需要一个物理页,那么只需要一条记录就可以了,故对于二级页表也只要4KB就足够了,而一级页表中的其他表项可能为空,所以这样只需要8KB就能解决问题。
但是如果因为节约内存而增加内存访问次数,似乎总感觉有点不得劲……
工程师为了解决这个问题,给MMU配了一个伙伴——TLB(快表,或者叫做页表缓存、旁路转址缓存),它是CPU的一个cache,主要工作就是缓存最近使用的页表,不用再次去查询内存,由于cache速度跟CPU相差无几,因此页表的查询效率有了很大的提升。
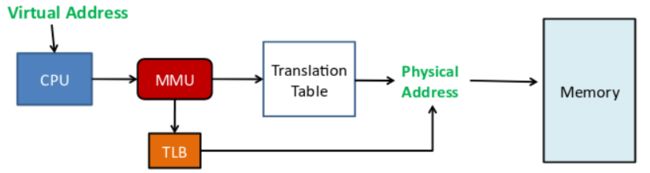
MMU
上面提到了MMU,那么MMU到底是什么?
MMU译作内存管理单元,是一个硬件设备,它大都集成在CPU中,也可以作为独立芯片置于CPU与总线之间,其主要工作是通过虚拟地址与页表(地址转换关系表)获得物理地址。

MMU只能在保护模式或者长模式下才能够开启,在保护模式下也必须使用保护模式平坦模型,使得分段形同虚设,详细内容见之前的保护模式,分段模型下的分页模式如下:

接下来来看看在保护模式和长模式下的MMU是怎么工作的,如何完成地址转换?
保护模式
保护模式下CPU位数为32,地址空间从0~4GB-1。
假设分页大小为4KB,采用二级页表的方式,于是32位的虚拟地址就被划分为3段:页目录索引、页表索引、页内偏移。
它们之间的对应关系为:页目录中有1024个页表,每个页表中有1024页,每页的大小为4KB,则空间为1K*1K*4K=4GB。
保护模式下,页目录存储在CPU的一个CR3寄存器中,MMU正是据此找到页目录的:

CR3寄存器中值、页目录表、页表这三者分别的格式如下:
仔细分析上图三个格式可以看到低10位被用作页面相关属性,这是由于三者每一个都是32位4字节,1024项正好是4KB,从而在物理地址中4K对齐,从而低10位其实不影响其地址计算,可以另做它用,这与保护模式的段选择子的设置有异曲同工之妙。
若是将分页大小设为4MB,则只有一级页表,同样要进行4K对齐,方便查找与设置页面属性。
长模式
长模式下4K的分页模型,将64位的虚拟地址分为了6段:保留段、顶级目录索引、页目录指针索引、页目录索引、页表索引、页内偏移,也就是四级页表结构,见下:
从上图可以看出,每个目录项有512个表项,每个表项的大小为64位8字节,总共可以表示的大小为:0.5K0.5K0.5K0.5K4K=0.25P!但其实实际使用中没有利用这么大的内存,只是有这个潜力。
来看看此时的CR3、顶级页目录项、页目录指针项等的格式:
总之,不管是保护模式还是长模式,在使用分页模型下的虚拟地址时,都是根据自身位数以及层级的关系来确定最终的物理地址的,为方便查找,往往使用4KB对齐的方式。
页缺失
有没有可能MMU出现转换失败?
比如页表中不存在对应关系、或是权限不足等情况?
这些情况是可能存在的,当出现这种情况时,MMU会触发中断——页中断的东西,而后让CPU来处理相应的逻辑,当逻辑处理完毕之后,再由MMU来进行地址转换,这个部分留到第7章来讲。
进程隔离
在分页模型下,由于没有了分段模型对各个段的保护,那么进程之间是如何进行地址隔离的呢?
——每一个进程在运行的时候,页表数据都是不一样的!
也就是说每一个进程都有一个独立的页表,当进程切换时,页表数据也会随之切换,这种方式就将进程的地址进行了隔离,从而不会造成冲突。
如何获取内存视图?
前面我们一直在讲内存相关的知识,那么当电脑开机的时候,如何获取当前电脑中的物理内存状态呢?比如如何知道物理内存有多少GB?值得注意的是,给出一个物理地址并不能准确地定位到内存空间,内存空间只是映射物理地址空间中的一个子集,物理地址空间中可能有空洞,有 ROM,有内存,有显存,有 I/O 寄存器,所以获取内存有多大没用,关键是要获取哪些物理地址空间是可以读写的内存。
在第4章介绍计算机启动的过程中提到,BIOS启动阶段会设置计算机的中断向量表,恰好其中有一个中断就可以用来获取内存视图,即INT 15H,该中断需要在实模式下运行,因为切换到保护模式时,中断向量表会重设(变成中断门了):
_getmemmap: xor ebx,ebx ;ebx设为0 mov edi,E80MAP_ADR ;edi设为存放输出结果的1MB内的物理内存地址loop: mov eax,0e820h ;eax必须为0e820h;输出结果数据项的大小为20字节=;8字节内存基地址,8字节内存长度,4字节内存类型 mov ecx,20 mov edx,0534d4150h ;edx必须为0534d4150h int 15h ;执行中断 jc error ;如果flags寄存器的C位置1,则表示出错 add edi,20;更新下一次输出结果的地址 cmp ebx,0 ;如ebx为0,则表示循环迭代结束 jne loop ;还有结果项,继续迭代 reterror:;出错处理
上述迭代过程中的中断每次执行都会输出20字节大小的数据项,最后这些数据项形成一个数组,我们用C语言结构体来表示一下这个数据项,便于理解之后的源码:
#define RAM_USABLE 1 //可用内存#define RAM_RESERV 2 //保留内存不可使用#define RAM_ACPIREC 3 //ACPI表相关的#define RAM_ACPINVS 4 //ACPI NVS空间#define RAM_AREACON 5 //包含坏内存typedef struct s_e820{ u64_t saddr; /* 内存开始地址 */ u64_t lsize; /* 内存大小 */ u32_t type; /* 内存类型 */}e820map_t;
补充:缓存
上面提到加快页表查询的硬件cache——TPL快表。
现代计算机,由于程序局部性的存在以及CPU处理速度与内存速度的脱节,cache已经成为标配,并且在多核CPU中,cache还是分级的:

1级2级cache是单个核心独有的,3级cache是多个核心共享的。但是这也会引发一个问题——数据一致性,比如两个核心都对某一个数据进行了修改,由于cache的存在就可能会造成数据不一致。
为了解决这个问题,出现了MESI和MOESI协议。以MESI协议为例,它将cache中的内容分为了四种状态:
-
M(modified,修改的)
-
E(Elusive,独占的)
-
S(Shared,共享的)
-
I(Invalid,无效的)
更详细一点(来自):
最开始只有一个核读取了A数据,此时状态为E独占,数据是干净的;
后来另一个核又读取了A数据,此时状态为S共享,数据还是干净的;
接着其中一个核修改了数据A,此时会向其他核广播数据已被修改,让其他核的数据状态变为I失效,而本核的数据还没回写内存,状态则变为M已修改;
等待后续刷新缓存后,数据变回E独占,其他核由于数据已失效,读数据A时需要重新从内存读到高速缓存,此时数据又共享了。
X86 CPU默认将cache关闭,可以通过将CR0寄存器的CD设置为0(打开cache)、NW设置为0(维护内存数据一致性)。
mov eax, cr0
;开启 CACHE
btr eax,29 ;CR0.NW=0
btr eax,30 ;CR0.CD=0
mov cr0, eax
参考链接
05 | CPU工作模式:执行程序的三种模式
06 | 虚幻与真实:程序中的地址如何转换?
07 | Cache与内存: 程序放在哪儿?
IDTR、TSS、GDT、LDT详解
BTS汇编指令