面试多线程八股文十问十答第一期
面试多线程八股文十问十答第一期
作者:程序员小白条,个人博客
相信看了本文后,对你的面试是有一定帮助的!
⭐点赞⭐收藏⭐不迷路!⭐
1.ThreadLocal如何实现线程安全
- Java的ThreadLocal是一个线程本地变量,它提供了一种简单的机制来实现线程封闭(Thread confinement)。ThreadLocal为每个线程提供了一个独立的副本,每个线程都可以访问自己的副本,从而避免了线程安全问题。
- ThreadLocal实现线程安全的核心是每个线程都有自己的变量副本,每个线程访问的都是自己的变量副本,从而避免了多线程之间的竞争和冲突。当多个线程共享同一个对象时,如果没有采取线程安全的措施,就会出现多个线程同时修改同一个对象的情况,从而导致数据不一致或者出现异常。
- ThreadLocal的作用:实现线程范围内的局部变量,即ThreadLocal在一个线程中是共享的,在不同线程之间是隔离的。
在Java中,使用ThreadLocal实现线程安全的具体步骤如下:
- 在类中创建ThreadLocal变量,每个线程都可以访问这个变量的副本。
- 在需要访问共享变量的方法中,通过ThreadLocal.get()方法获取当前线程的变量副本。
- 如果当前线程没有创建过变量副本,那么就通过ThreadLocal.set()方法创建一个变量副本。
- 在方法执行结束时,通过ThreadLocal.remove()方法删除当前线程的变量副本。
- 通过ThreadLocal实现线程安全的好处是可以简化线程安全的处理过程,避免了显式的同步操作,提高了代码的可读性和可维护性。但是需要注意的是,ThreadLocal只能保证线程内部的线程安全,无法保证多个线程之间的线程安全。在多线程环境下,仍然需要采取其他措施来保证多个线程之间的数据同步和一致性。
- 也就是说,每个线程访问的是自己独立的变量副本,但是多个线程之间共享的数据还是存在竞争和冲突的可能性。如果需要保证多个线程之间的数据同步和一致性,仍然需要采取其他措施,例如使用synchronized关键字或者使用锁机制等。因此,需要根据实际的业务场景和需求来选择合适的线程安全措施,不能仅仅依靠ThreadLocal来实现线程安全。
2.子线程如何获得父线程的ThreadLocal
在Java中,子线程无法直接访问父线程的ThreadLocal变量,因为ThreadLocal是线程封闭的,每个线程都拥有自己独立的变量副本。
但是,如果在创建子线程时将父线程的ThreadLocal变量传递给子线程,子线程就可以访问父线程的ThreadLocal变量了。具体实现方法如下:
1.在父线程中创建并初始化ThreadLocal变量。
2.在创建子线程时,将父线程的ThreadLocal变量作为参数传递给子线程。
3.在子线程中通过参数获取父线程的ThreadLocal变量,并使用该变量。
public class ParentThread {
// 创建父线程的ThreadLocal变量
public static ThreadLocal threadLocal = new ThreadLocal();
public static void main(String[] args) {
// 设置父线程的ThreadLocal变量
threadLocal.set("Hello World!");
// 创建子线程并将父线程的ThreadLocal变量传递给子线程
Thread childThread = new Thread(new ChildThread(threadLocal.get()));
childThread.start();
}
}
class ChildThread implements Runnable {
private String value;
public ChildThread(String value) {
this.value = value;
}
public void run() {
// 在子线程中获取父线程的ThreadLocal变量
String parentValue = this.value;
System.out.println("Parent Thread Local Value: " + parentValue);
}
}
3.线程能同时访问类中的两个Synchronized的同步方法吗?这两个同步方法能互相访问吗?
- 线程可以同时访问类中的两个Synchronized的同步方法,但是这两个同步方法不能互相访问。
- Synchronized关键字可以保证同一时间只有一个线程进入同步代码块或同步方法,如果一个线程进入了一个Synchronized方法或代码块,其他线程就必须等待该线程执行完毕才能进入该方法或代码块。
- 但是,如果一个线程已经获得了一个Synchronized方法或代码块的锁,它就可以同时访问另一个Synchronized方法或代码块,因为这两个方法使用的是不同的锁。也就是说,如果类中有两个Synchronized方法,这两个方法使用的锁是不同的,因此不会相互影响,线程可以同时访问它们。
- 然而,如果一个Synchronized方法或代码块在执行过程中调用了另一个Synchronized方法或代码块,就会出现锁竞争(在锁一样的情况下)的问题,即第一个Synchronized方法或代码块已经获得了锁,但是第二个Synchronized方法或代码块也需要获得同样的锁才能执行,因此第二个Synchronized方法或代码块就会被阻塞。如果第一个Synchronized方法或代码块等待第二个Synchronized方法或代码块执行完毕才能继续执行,就会出现死锁的情况。因此,两个Synchronized方法或代码块不能互相访问,否则会出现锁竞争和死锁问题。
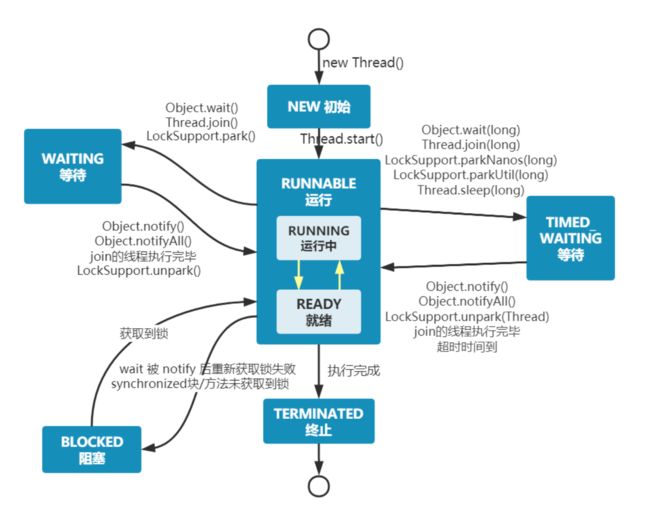
4.sleep()和wait()方法的作用
线程sleep 和wait 的区别:
1、这两个方法来自不同的类分别是Thread和Object
2、最主要是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
3、wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用(使用范围)
4、sleep必须捕获异常,wait必须捕获异常(之前看到网上很多博客都说wait方法不需要抛出异常这个观点是错误的,千万不要被误导了!!!!!!!notify和notifyAll方法确实可以不用抛出异常)
不加抛异常处理的会编译通不过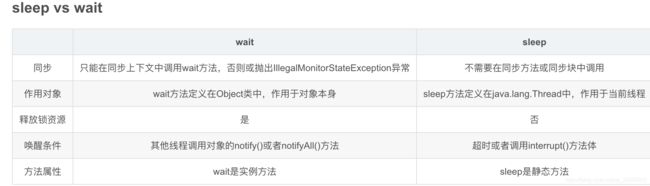
sleep是Thread类的静态方法。sleep的作用是让线程休眠制定的时间,在时间到达时恢复,也就是说sleep将在接到时间到达事件事恢复线程执行。wait是Object的方法,也就是说可以对任意一个对象调用wait方法,调用wait方法将会将调用者的线程挂起,直到其他线程调用同一个对象的notify方法才会重新激活调用者。
共同点:
它们都可以被interrupted方法中断。
Thread.Sleep(1000) 意思是在未来的1000毫秒内本线程不参与CPU竞争,1000毫秒过去之后,这时候也许另外一个线程正在使用CPU,那么这时候操作系统是不会重新分配CPU的,直到那个线程挂起或结束,即使这个时候恰巧轮到操作系统进行CPU 分配,那么当前线程也不一定就是总优先级最高的那个,CPU还是可能被其他线程抢占去。另外值得一提的是Thread.Sleep(0)的作用,就是触发操作系统立刻重新进行一次CPU竞争,竞争的结果也许是当前线程仍然获得CPU控制权,也许会换成别的线程获得CPU控制权。
wait(1000)表示将锁释放1000毫秒,到时间后如果锁没有被其他线程占用,则再次得到锁,然后wait方法结束,执行后面的代码,如果锁被其他线程占用,则等待其他线程释放锁。注意,设置了超时时间的wait方法一旦过了超时时间,并不需要其他线程执行notify也能自动解除阻塞,但是如果没设置超时时间的wait方法必须等待其他线程执行notify。sleep()方法导致了程序暂停执行指定的时间,让出cpu该其他线程,但是他的监控状态依然保持者,当指定的时间到了又会自动恢复运行状态。
在调用sleep()方法的过程中,线程不会释放对象锁。
而当调用wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify()方法后本线程才进入对象锁定池准备
- sleep可以在任何地方使用,而wait只能在同步方法或者同步块中使用。
5.Lock锁
- synchronized是Java语言的关键字。Lock是一个接口。
- synchronized不需要用户去手动释放锁,发生异常或者线程结束时自动释放锁;Lock则必须要用户去手动释放锁,如果没有主动释放锁,就有可能导致出现死锁现象。
- lock可以配置公平策略,实现线程按照先后顺序获取锁。
- 提供了trylock方法 可以试图获取锁,获取到或获取不到时,返回不同的返回值 让程序可以灵活处理。
- lock()和unlock()可以在不同的方法中执行,可以实现同一个线程在上一个方法中lock()在后续的其他方法中unlock(),比syncronized灵活的多。
6.如何实现所有线程在某个线程发生了之后再执行
1.闭锁CountDownLatch闭锁是典型的等待事件发生的同步工具类,将闭锁的初始值设置1,所有线程调用await方法等待,当事件发生时调用countDown将闭锁值减为0,则所有await等待闭锁的线程得以继续执行。
2.阻塞队列BlockingQueue所有等待事件的线程尝试从空的阻塞队列获取元素,将阻塞,当事件发生时,向阻塞队列中同时放入N个元素(N的值与等待的线程数相同),则所有等待的线程从阻塞队列中取出元素后得以继续执行。
3.信号量Semaphore设置信号量的初始值为等待的线程数N,一开始将信号量申请完,让剩余的信号量为0,待事件发生时,同时释放N个占用的信号量,则等待信号量的所有线程将获取信号量得以继续执行。
4.栅栏CyclicBarrier设置栅栏的初始值为1,当事件发生时,调用barrier.wait()冲破设置的栅栏,将调用指定的Runable线程执行,在该线程中启动N个新的子线程执行。这个方法并不是让执行中的线程全部等待在某个点,待某一事件发生后继续执行。
特别注意:不能用“条件队列”,多个线程阻塞等待在条件队列上,事件发生时调用“条件队列”的notifyAll方法或者signalAll方法虽然能唤醒所有等待线程,但是只有一个线程能够获得该条件队列的锁得以调度执行,其它线程未获得锁仍将继续阻塞等待。
7.如何保证多线程下的i++结果正确
1.使用 synchronized 关键字
public class MyThread implements Runnable {
private int i;
public MyThread(int i) {
this.i = i;
}
@Override
public void run() {
synchronized (this) {
System.out.println(i++);
}
}
}
2.Atomic变量
使用AtomicInteger类来代替int类型,可以保证原子性。AtomicInteger类提供了线程安全的原子操作方法,如incrementAndGet()。
private AtomicInteger i = new AtomicInteger(0);
public void increment() {
i.incrementAndGet();
}
3.Lock对象
使用Lock对象来对共享变量进行同步,保证同一时刻只有一个线程能够访问该变量。
private Lock lock = new ReentrantLock();
public void increment() {
lock.lock();
try {
i++;
} finally {
lock.unlock();
}
}
4.ThreadLocal变量
使用ThreadLocal变量来对共享变量进行封装,每个线程都拥有自己的副本,可以保证线程安全。
private ThreadLocal threadLocal = new ThreadLocal() {
@Override
protected Integer initialValue() {
return 0;
}
};
public void increment() {
threadLocal.set(threadLocal.get() + 1);
}
8.volatile是怎么知道多线程下数据变更的
volatile 关键字用于标记一个变量是 volatile 的,这意味着这个变量的值可能会被多个线程同时修改,因此需要及时更新到内存中,以确保其他线程能够及时看到值的变化。
- 当一个线程访问一个 volatile 变量时,Java 虚拟机会自动将该变量的值复制到线程本地内存中,以便其他线程能够访问该变量的值。当一个线程修改了 volatile 变量的值后,Java 虚拟机也会自动将修改后的值复制回线程本地内存中,以便其他线程能够更新他们的本地内存。
- 由于 volatile 变量的值会被及时更新到内存中,因此其他线程可以及时看到该变量的值发生变化。如果一个变量不是 volatile 的,那么其他线程只能读取该变量的先前值,而不能直接读取最新的值,因为这样需要从磁盘或者其他慢速存储介质中读取数据,会降低程序的性能。
- 需要注意的是,虽然 volatile 能够确保多线程下数据变更的正确性,但它并不能保证线程的安全性。如果在多线程环境下,修改一个非 volatile 变量的值可能会引起竞态条件等问题,因此需要谨慎使用 volatile 关键字。
9.线程池的执行流程和线程池的拒绝策略和核心配置参数

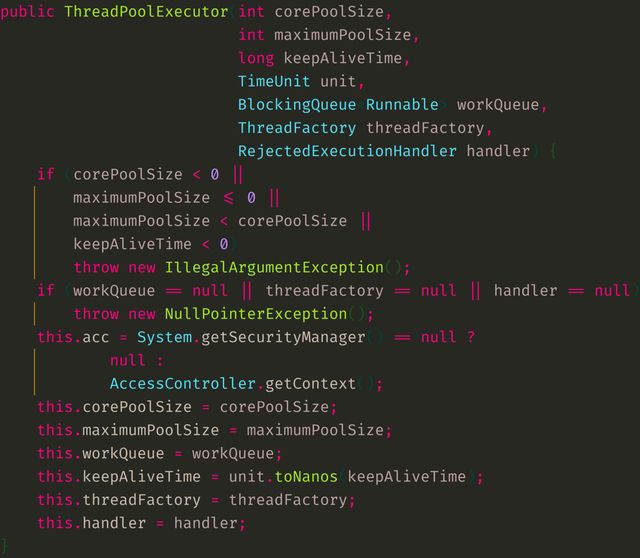
corePoolSize:核心线程数
maxiumPoolSize:最大线程数
keepAliveTime:空闲存活时间
unit: 时间单位
workQueue:任务队列
threadFactory: 线程工厂
handler:拒绝策略
线程池的执行流程有 3 个重要的判断点
- 判断当前线程数和核心线程数.
- 判断当前任务队列是否已满.
- 判断当前线程数是否已达最大线程数.
如果在经过上诉三个过程后, 得到的结果都是 true , 那么就会执行线程池的拒绝策略.
二. 拒绝策略当任务过多且线程池的任务队列已满时, 此时就会执行线程池的拒绝策略, 线程池的拒绝策略默认有以下 4 种:
AbortPolicy:中止策略,线程池会抛出异常并中止执行此任务.CallerRunsPolicy:调用方运行策略,把任务交给添加此任务的(main)线程来执行.DiscardPolicy:放弃最新策略,忽略此任务,忽略最新的一个任务.DiscardOldestPolicy:放弃最旧策略,忽略最早的任务,最先加入队列的任务.
- AbortPolicy(中止策略)功能: 当触发拒绝策略时,直接抛出拒绝执行的异常,中止策略的意思也就是打断当前执行流程
- CallerRunsPolicy(调用者运行策略)功能:当触发拒绝策略时,只要线程池没有关闭,就由提交任务的当前线程处理.
- DiscardPolicy(丢弃策略)功能:直接静悄悄的丢弃这个任务,不触发任何动作.
- DiscardOldestPolicy(弃老策略)功能:如果线程池未关闭,就弹出队列头部的元素,然后尝试执行.
一般情况下,任务分为IO密集型和CPU密集型。
CPU密集型:一般设置为cpu核数+1
IO密集型:一般设置为2n,以IO能力为主。
10.线程创建的几种方法
- 继承Thread
- 实现Runnable接口
- 实现Callable接口,结合 FutureTask使用
- 利用该线程池ExecutorService、Callable、Future来实现