CLIP文章精读
1.论文的方法
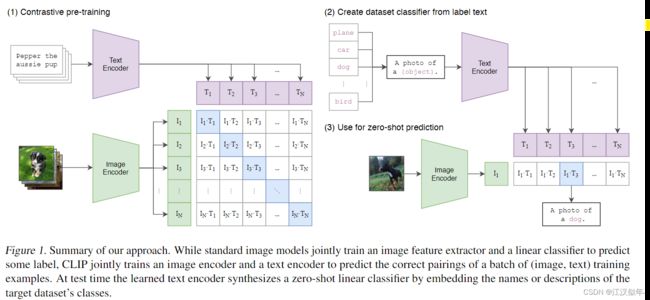
在图像文本align这个领域,之前的典型方法都尝试直接预测image对应的精确text,这个太难了,因为语言描述过于多样性。其他一些工作发现,尽管图像的生成模型可以学习高质量的图像表示,但与具有相同性能的对比模型相比,它们需要超过一个数量级的计算。最近在图像对比表征学习方面的工作发现,对比目标可以比同等的预测目标学习更好的表征。
注意到这些发现,我们探索训练一个系统来解决潜在的更容易的代理任务:即只预测整个文本与哪个图像配对,而不是预测该文本的确切单词。联合训练图像编码器和文本编码器,以最大batch中N个实对的图像和文本嵌入的余弦相似性,同时最小化N2−N个错误对的嵌入的余弦类似性
loss就是交叉熵。这种方法来源于前人很多对比学习的工作,并非原创。
loss的设计:分别针对固定image匹配text和固定text匹配image设计了两个交叉熵loss

2.数据集
传统coco集合只有几十万张图片,但是其它计算机视觉系统有几十亿张图片,但是这些图片的质量参差不齐。经过过滤保留含有NLP的图片只有1500万张,跟Image Net级别差不多。
因此:重新创建了一个4亿的图像文本对数据集。为了覆盖尽量多地视觉概念,搜索图像文本对时要求文本包含50万个query中至少一个,这些query至少再wikipedia中出现过100次。我们大概平衡了类别,使得每个query大概包含了20000个pair。这个数据集的文本单词量级与训练GPT2的数据集近似。
3实验
open ai对clip一个模型的评估系统非常庞大,针对66个不同模型在27个不同数据集上进行1782个不同的评估,用来验证预训练模型的表达能力。基础设施可见一班。
3.1zero-shot
(1)对zero-shot的理解

传统的迁移学习方法:在大的预训练模型上进行小数据的finetune,finetune的过程可能冻结多层参数
zero-shot:以分类任务为例,大模型的训练过程中并没有单独做过分类任务,或者没有见过某个类别的物体,通过语言prompt的方式模型能对该类别进行准确分类。原理是语言prompt能够让模型从见过的样本中抽取出组合特征,比如斑马的整体特征也从见过的大熊猫、老虎、马多种物体的部分特种中组合而来。
(2)实验描述
对clip模型的zeroshot能力进行了广泛的评估,通过promt及其组合能够明显提升分类的效果。
大多数标准图像分类数据集将命名或描述类别的信息视为次要考虑因素,这使得基于自然语言的零样本迁移成为可能。绝大部分数据集仅使用标签的数字ID对图像进行注释,并包含一个将这些ID映射回其英文名称的文件。一些数据集,例如Flowers102和GTSRB,在其发布版本中似乎根本没有包含这种映射,完全阻止了零样本迁移的可能性。
一个常见的问题是多义性。当一个类别的名称是CLIP文本编码器提供的唯一信息时,由于缺乏上下文,它无法区分所指的词义。在某些情况下,同一个单词的多个意义可能被包含在同一个数据集的不同类别中!这在ImageNet中发生,其中既包含建筑起重机,也包含飞行的鹤。另一个例子可以在Oxford-IIIT宠物数据集的类别中找到,其中单词"boxer"从上下文来看,明显是指一种狗的品种,但对于缺乏上下文的文本编码器来说,它同样可能指的是一种运动员类型。
我们遇到的另一个问题是,在我们的预训练数据集中,图像配对的文本通常不仅仅是一个单词。通常,文本是一个完整的句子,以某种方式描述图像。为了弥合这种分布差异,我们发现使用提示模板"A photo of a {label}."作为一个很好的默认选项,有助于明确文本是关于图像内容的。这通常比仅使用标签文本的基准性能要好。例如,仅使用这个提示在ImageNet上可以提高1.3%的准确率。
我们还尝试了通过多个零样本分类器进行集成来提高性能的方法。这些分类器是通过使用不同的上下文提示(例如"A photo of a big {label}“和"A photo of a small {label}”)来计算的。我们在嵌入空间而不是概率空间上构建这种集成。这样,我们可以缓存一组平均文本嵌入,使得集成的计算成本在许多预测中与使用单个分类器时相同。我们观察到,在许多生成的零样本分类器之间进行集成可以可靠地提高性能,并且我们在大多数数据集上使用它。在ImageNet上,我们集成了80个不同的上下文提示,这使性能比上述单个默认提示额外提高了3.5%。综合考虑提示工程和集成,可以将ImageNet的准确率提高近5%。在图4中,我们可视化了在与Li等人所做的无上下文基线方法(直接将类名嵌入)相比,提示工程和集成如何改变一组CLIP模型的性能。
3.2表征能力
对backbone的表征能力进行了广泛而严谨的评估,研究66个不同的模型在27个不同的数据集上1782个不同的评估。证明了其更强的表征能力。
评估表示质量的方法有很多,对于一个“理想”表示应该具备的特性也存在争议(Locatello等,2020年)。一种常见的方法是在从模型中提取的表示上拟合线性分类器,并在各种数据集上测量其性能。另一种方法是测量模型的端到端微调的性能。这增加了灵活性,先前的研究已经有力地证明,在大多数图像分类数据集上,微调的性能优于线性分类(Kornblith等,2019年;Zhai等,2019年)。虽然微调的高性能激发了对其进行实际研究的动机,但出于几个原因,我们仍然选择基于线性分类器的评估方法
我们的工作专注于开发一种高性能的任务和数据集无关的预训练方法。微调可以在微调阶段将表示适应每个数据集,从而弥补并潜在地掩盖了在预训练阶段学习通用和稳健表示失败的问题。相比之下,线性分类器由于其有限的灵活性,更能凸显这些失败,并在开发过程中提供清晰的反馈。
对于CLIP来说,训练监督线性分类器的额外好处是它与其零样本分类器使用的方法非常相似,这使得在第3.1节中可以进行广泛的比较和分析。最后,我们的目标是将CLIP与许多任务中的一套全面的现有模型进行比较。研究66个不同的模型在27个不同的数据集上需要调整1782个不同的评估。微调打开了一个更大的设计和超参数空间,这使得公平评估和计算上的比较多样化的技术变得困难