11.3.1-使用Pythton抓取股票基金数据
文章目录
- 1. 哪些方式获取股票数据
-
- 1.1. yifinance
- 1.2. JoinQuant聚宽
- 1.3. tushare
- 1.4. 自己动手,丰衣足食
- 2. 使用python抓取数据
-
- 2.1. 查看请求报文
- 2.2. 解析返回报文
- 2.3. 数据存储
- 2.4. 开始python代码编写
-
- 2.4.1. 构造时间区间
- 2.4.2. requests调用
- 2.4.3. 数据存储
- 2.5. 完整的代码:
“知识就是力量”这句格言实际上是错误的。正确的表述应该是:“知识运用起来才是力量。”
本文摘要:
都有哪些方法可以获得股票数据?
省钱、相对不省力、定向性强:python抓取数据
1. 哪些方式获取股票数据
1.1. yifinance
发现yfinance和DataReader有相同的问题,就是要挂上V*N才可以连接到服务器。----放弃。
1.2. JoinQuant聚宽
这个之前没有使用,看官网:JQData使用说明 - JoinQuant
有试用和正式账号的区别,试一下注册账号试用能不能满足要求。官网这么描述试用:
聚宽JQData一直致力于提供专业的数据服务,【目前基础数据试用全面开放,流量升级为每天100万条】
试用账号历史范围:前15个月~前3个月 ; 正式账号历史范围:不限制
历史数据范围:试用账号:距今15个月前 至 距今最近3个月 (即不包含最近3个月,且可调取的历史范围最长为1年);正式账号不限制。
看起来,试用账号可能不能获取到最近3个月的数据。试一下再说。
刚入坑就被劝退了啊兄弟们!python api登录不上。(有成功的,可以告知一下查询日线数据,近3个月是否能拿到。ps:在很多官网介绍上都看到了”试用账号历史范围:前15个月~前3个月 “,估计就是量凉了,如果不想花钱,还是换渠道吧。)

有点侥幸心理,看看聚宽的会员费用:(我错了,我是穷鬼!)

1.3. tushare
tushare官网:Tushare数据
概览:
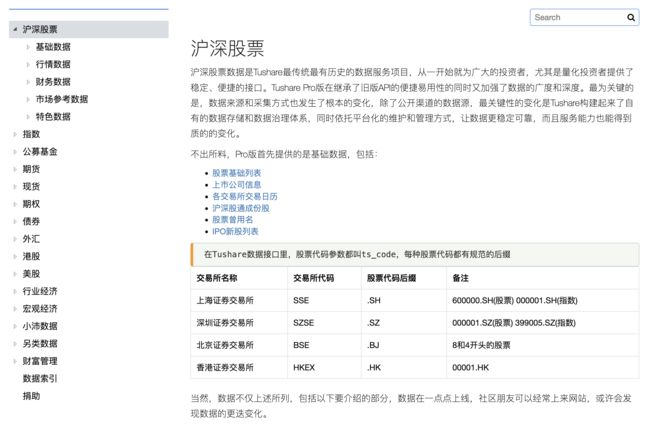
优点:
针对性比较强,主要是股市、经济相关数据。
使用比较简单,有python相关demo、保存数据demo等简单上手的内容
有在线的api调试页面,可以直接调试接口,拿到返回数据。(前提是你的积分是够的。)
覆盖股票、股市、基金,以及宏观经济数据,比如CPI
缺点:
- 收费:比如想看的510300沪深300ETF,需要2000积分(平台上积分是1年有效期)
- 其他真没了,感觉很好用啊~~

1.4. 自己动手,丰衣足食
就是自己用代码撸,下面搞一个。经过测试,代码撸1个基金日线数据出来,只需要100行代码(包含注释)。
2. 使用python抓取数据
先定一个范围:
单次抓取某一只股票的历史数据。(截止到上个交易日)
输入:开始日期,股票代码。
输出:csv文件,包含:日期、成交量、开盘价、收盘价、最高价、最低价
2.1. 查看请求报文
从下面的图,可以分析得出下面的结论:
发起的是get请求,参数都是拼接在url上的。
携带了cookie(这个可能是浏览器的行为,不过为了保证成功率,我们也带cookie)
要分析请求的参数:
symbol: SH510300 ---- 名称
begin: 1693895713149 ---- 是时间戳,13位,百度找一个unix时间戳转换工具即可。比如 时间戳(Unix timestamp)转换工具 - 在线工具 (tool.lu)
period: day ---- 日线数据
type: before ---- 查询此日之前的数据
count: -284 ---- 会返回”begin“日期之前的284天的数据
indicator: kline,pe,pb,ps,pcf,market_capital,agt,ggt,balance ---- 返回这些列,解析主要还是根据返回的数据来做。

2.2. 解析返回报文
返回报文截图如下,简单分析可得如下结论:
第一行数据 1657209600000 —> 2022-07-08
第二行数据 1657468800000 —> 2022-07-11
最后一行数据 1693756800000 —> 2023-09-04(竟然包含了当天的数据,要注意取的时间,如果没收盘,是会变动的。)
然后其他蓝色的数据,我们主要关注收盘价、当日最高价、当日最低价,基本就能满足简单的分析需求了。

2.3. 数据存储
数据存储,我们可以先解析返回,将返回的数据按照固定格式放于内存变量中,最后全部获取到数据之后,通过pandas的df.to_csv函数,写入到csv文件中。
2.4. 开始python代码编写
针对请求,需要做如下的准备工作:
选定一个python get请求的库,python库很丰富,我选了requests
请求报文头 ”begin: 1693895713149 ---- 是时间戳“ 参数构造。
这里引申出一个点:需要构造每个时间区间的点,比如我们以38天为一个时间段,那需要构造begin列表:[‘2012-05-28’, ‘2012-07-05’, ‘2012-08-12’, ‘2012-09-19’…‘2023-07-16’, ‘2023-08-23’]
另外一个,要把 2012-05-28 这样的时间格式,转换成unix时间戳。
请求报文头 ”count: -284 ---- 会返回begin日期之前的284天的数据”,我们可以自己选定每次响应返回的时间区间数量。为了和上面begin例子配合,这里就传38。
请求报文头 “indicator”,是返回哪些指标,我们就默认即可。
分析完毕,开始动工。
一步一步分解:
2.4.1. 构造时间区间
这是一门讲究,这种库也很多,我选用了pandas的date_range函数:
pd.date_range(start=start, end=end, freq=freq)
pd.date_range(start=‘2012-05-08’, end=‘2023-09-01’, freq=‘38D’)
返回的是Timestamp类型列表,形如:[‘2012-05-28’, ‘2012-07-05’, ‘2012-08-12’, ‘2012-09-19’…‘2023-07-16’, ‘2023-08-23’]
而接口入参需要的unix时间戳字符串,进行转换即可:date_unix_time = str(int(time.mktime(item.timetuple()) * 1000))
def date_range(start, end, freq):
"""
构造时间区间,使用pandas函数
:param start: '2012-05-08'
:param end: '2023-09-01'
:param freq: '38D'
:return: ['2012-05-28', '2012-07-05', '2012-08-12', '2012-09-19'....'2023-07-16', '2023-08-23']
"""
# date_range = pd.date_range(start='2022-01-01', end='2022-06-17', freq='38D')
date_range = pd.date_range(start=start, end=end, freq=freq)
return date_range
2.4.2. requests调用
最重要的是使用requests的get方法:
requests.get(url=url, params=data, cookies=cookies_dir, headers=headers)
这里有一些讲究:
伪造user-agent
为了携带cookie方便,我们最好提供一个cookie字符串参数,由代码,将其转换成requests库需要的字典格式
上述实现的代码如下:
def do_request(self, begin_unix_time_str):
data = {
"symbol": self.symbol,
"begin": begin_unix_time_str,
"period": "day",
"type": "before",
"count": "38",
"indicator": "kline,pe,pb,ps,pcf,market_capital,agt,ggt,balance"
}
# 头部,伪装自己为浏览器
headers = {
'user-agent': 'Mozill..................04.1',
}
# cookie字符串,可以省去自己拼接k-v形式
cookies_str = 'device_id=4b698.....................95430'
cookies_dir = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
# 调用请求
index_result = requests.get('https://stock.xueqiu.com/v5/stock/chart/kline.json',
params=data,
cookies=cookies_dir,
headers=headers)
# 打印结果
print('获取到结果\n' + index_result.text)
return index_result.text
2.4.3. 数据存储
这里涉及到2种存储,1是临时写到内存变量进行保存、2是各个时间数据都全部获取完毕后,将结果写入到csv文件中。
def result_save(self, result_text):
# 请求结果字符串转换为json对象
result_json = json.loads(result_text)
last_record = {}
for item in result_json['data']['item']:
record = {}
# 日期格式化
date = time.strftime("%Y-%m-%d", time.localtime(item[0]/1000))
# 自行构造一个uuid,是为了判断此日期的数据有没有存在,存在就不必再保存了,不存在的才保存下来
record['uuid'] = result_json['data']['symbol'] + '|' + date
record['date'] = date
record['volume'] = item[1]
record['open'] = item[2]
record['high'] = item[3]
record['low'] = item[4]
record['close'] = item[5]
record['chg'] = item[6]
record['percent'] = item[7]
record['turnoverrate'] = item[8]
record['amount'] = item[9]
print(record)
if record['uuid'] in self.fetch_days:
print('已有当日数据')
else:
# self.fetch_days是类实例变量
self.fetch_days[record['uuid']] = record['uuid']
self.data_of_days.append(record)
last_record = record
return last_record
将数据存储到csv
# 数据存储到csv
df = pd.DataFrame(this_class.data_of_days)
# 默认自然序号的index会保存到csv文件
df.to_csv("{}-{}-{}.csv".format(security, start_date, end_date))
2.5. 完整的代码:
为了防止被封,要自行替换一下某球的 user-agent 和 cookies
import json
import time
import requests as requests
import pandas as pd
def date_range(start, end, freq):
"""
构造时间区间,使用pandas函数
:param start: '2012-05-08'
:param end: '2023-09-01'
:param freq: '38D'
:return: ['2012-05-28', '2012-07-05', '2012-08-12', '2012-09-19'....'2023-07-16', '2023-08-23']
"""
# date_range = pd.date_range(start='2022-01-01', end='2022-06-17', freq='38D')
date_range = pd.date_range(start=start, end=end, freq=freq)
return date_range
class SecurityHistory:
"""
cookies_str 是要注意可能会过期,如果过期了,就重新通过浏览器手机模拟器获取一下。
"""
def __init__(self, symbol) -> None:
super().__init__()
self.symbol = symbol
self.fetch_days = {}
self.data_of_days = []
def do_request(self, begin_unix_time_str):
data = {
"symbol": self.symbol,
"begin": begin_unix_time_str,
"period": "day",
"type": "before",
"count": "38",
"indicator": "kline,pe,pb,ps,pcf,market_capital,agt,ggt,balance"
}
# 头部,伪装自己为浏览器
headers = {
'user-agent': 'Mozilla/5.0 (iP.........这里要自行替换................./604.1',
}
# cookie字符串,可以省去自己拼接k-v形式
cookies_str = 'device_id=4b..........................6987895430'
cookies_dir = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
# 调用请求
index_result = requests.get('https://stock.xueqiu.com/v5/stock/chart/kline.json',
params=data,
cookies=cookies_dir,
headers=headers)
# 打印结果
print('获取到结果\n' + index_result.text)
return index_result.text
def result_save(self, result_text):
# 请求结果字符串转换为json对象
result_json = json.loads(result_text)
last_record = {}
for item in result_json['data']['item']:
record = {}
# 日期格式化
date = time.strftime("%Y-%m-%d", time.localtime(item[0]/1000))
# 自行构造一个uuid,是为了判断此日期的数据有没有存在,存在就不必再保存了,不存在的才保存下来
record['uuid'] = result_json['data']['symbol'] + '|' + date
record['date'] = date
record['volume'] = item[1]
record['open'] = item[2]
record['high'] = item[3]
record['low'] = item[4]
record['close'] = item[5]
record['chg'] = item[6]
record['percent'] = item[7]
record['turnoverrate'] = item[8]
record['amount'] = item[9]
print(record)
if record['uuid'] in self.fetch_days:
print('已有当日数据')
else:
# self.fetch_days记录获取过数据的日期、data_of_days记录日线数据。
self.fetch_days[record['uuid']] = record['uuid']
self.data_of_days.append(record)
last_record = record
return last_record
if __name__ == '__main__':
security = 'SH510300'
start_date = '2012-05-28'
end_date = time.strftime("%Y-%m-%d", time.localtime())
# 构造请求时间区间
datetime_range = date_range(start=start_date, end=end_date, freq='38D')
this_class = SecurityHistory(security)
for item in datetime_range:
date_unix_time = str(int(time.mktime(item.timetuple()) * 1000)) # item是Timestamp类型 2012-05-28 00:00:00
# 调用请求接口获取数据
result_text = this_class.do_request(date_unix_time) # date_unix_time='1338134400000'
# 保存每日数据,这里存放在内存,并去重
this_class.result_save(result_text)
# 休眠,防止请求过于频繁被封
time.sleep(3)
# 数据存储到csv
df = pd.DataFrame(this_class.data_of_days)
# 默认自然序号的index会保存到csv文件
df.to_csv("{}-{}-{}.csv".format(security, start_date, end_date))