飞桨领航团零基础Python速成营–面向对象学习笔记
课程链接:https://aistudio.baidu.com/aistudio/course/introduce/7073
python的特点
- 简洁性 实现同样的功能,python代码的行数往往是java的1/5。
- 易读性 代码像纯英语一样易于理解。
- 可扩展性,开源,任何人都可以做出自己的贡献。
课节一
1. 运算符优先性和结合性

2. 起名法则
简单地理解,标识符就是一个名字,就好像我们每个人都有属于自己的名字,它的主要作用就是作为变量、函数、类、模块以及其他对象的名称
Python 中标识符的命名不是随意的,而是要遵守一定的命令规则,比如说:
标识符是由字符(A~Z 和 a~z)、下划线和数字组成,但第一个字符不能是数字。 标识符不能和 Python 中的保留字相同。 Python中的标识符中,不能包含空格、@、% 以及 $ 等特殊字符。 在 Python 中,标识符中的字母是严格区分大小写的
3. 组合数据类型
列表:list
#list是一种有序的集合,可以随时添加和删除其中的元素
list1 = [1, 2, 3, 4, 5 ]
list2 = ["a", "b", "c", "d","e","f"]
list3 = ['physics', 'chemistry', 1997, 2000]
元组:tuple
#tuple一旦初始化就不能修改
tuple1 = (1, 2, 3, 4, 5 )
tuple2 = ("a", "b", "c", "d","e","f")
tuple3 = ('physics', 'chemistry', 1997, 2000)
字典:dict
#使用键-值(key-value)存储,具有极快的查找速度
word = {'apple':'苹果','banana':'香蕉'}
scores = {'小张':100, '小李':80}
grad = {4:'很好',3: '好',2:'中',1:'差',0:'很差'}
4.流程控制
if语句:

for 条件一 : (冒号)
执行语句(缩进)
elif 条件二:
执行语句
…
else:
执行语句
light = '红灯'
if light == '红灯':
print('停')
elif light == '绿灯':
print('行')
else:
print('等一等')
while语句
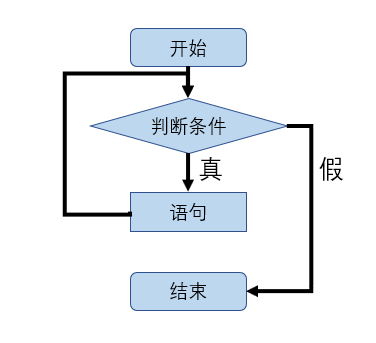
while 条件:
执行语句
# 从1数到9
number = 1
while number<10: # 注意边界条件
print(number)
number+=1
课节二
1.字符串常用函数
大小写函数:
.title():单词首字母大写
.upper():全大写
.lower():全小写
.capitalize():字符串第一个字母大写
删除函数:
.rstrip():删除右空格
.lstrip():删除左空格
.strip():删除空格
其它常用函数:
.endswith():以什么字符串结尾
.count():得到某字符的个数(不一定是单字符)
.find():返回从左第一个制定字符的索引,找不到返回0
.index():返回从左第一个指定字符的索引,找不到报错
.split():按照指定的内容分割字符串(以列表形式)
.replace( 替换前, 替换后, [替换个数]):从左到右替换指定的元素,可以指定替换的个数,默认全部替换(但字符串未变)
2.字符串的格式化输入
format:当指定了 s类型 ,只能传字符串值,如果传其他类型值不会自动转换
当你不指定类型时,任何类型都能成功,如无特殊必要(比如限制float的小数位),可以不用指定类型
f+string:可读性更强

#以f+string为例
name = '张三'
hight = 170.4
score_math = 95
score_english = 89
print(f"大家好!我叫{name},我的身高是{hight:.3f} cm, 数学成绩{score_math}分,英语成绩{score_english}分")
3.列表生成式
使得代码更加简洁
#数字型
list0=[1,2,3,4,5]
#创建新列表为list1,各元素为list0的100倍,即list1=[100,200,300,400,500]
list1=[n*100 for n in list0]
print(list1) #注意list0没有被修改
#字符串型
快速创建列表list2,为['app_0','app_1','app_2','app_3','app_4','app_5','app_6','app_7','app_8','app_9']
list2=[f'app_{n}' for n in range(10)] #或者
list2=['app_%d'%n for n in range(10)]
#增加条件
#创建新列表为list3,元素为1~100内的奇数
list0=list(range(100)) #list0包含0~99
list0=[n+1 for n in list0] #修改为1~100
list3=[n for n in list0 if n%2!=0]
#创建list0,元素为list1~3的交集
list1 = [1,3,6,7,12,32,65,]
list2 = [2,3,5,6,12]
list3=[1,3,12,15]
list0=[n for n in list1 if n in list2 and n in list3]
#创建list0,包含'xyz'和'abc'的全排列
list0=[m+n for m in 'xyz' for n in 'abc']'''
课节三
函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
- 函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
函数内容以冒号起始,并且缩进。 - return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
调用函数:
位置实参:实参与形参顺序一一对应,数量一一对应
关键字实参:数量一一对应
默认值形参:先列出没有默认值的形参
def match(alphabet,number):
print(alphabet+"\t"+number)
#调用:
#位置实参:
match('a',"1") #注意次序,一一对应
#==>a 1
#关键字实参:
match(number='1',alphabet='a') #此时可以不用考虑顺序
#==>a 1
#默认值形参:
def match(alphabet,number='1'): #直接规定number为1,调用时可不输入number的值
print(alphabet+"\t"+number)
#注意:使用默认值时,在形参列表中必须先列出没有默认值的形参
作用域:
1.局部变量 作用域:在函数内
2.全局变量 作用域:在函数外
函数优先使用局部变量 在没有局部变量的情况下, 使用全局变量
#global关键字
def change_my_name():
global name
print('我的名字曾经是', name)
name = '李四'
print('我的名字现在是', name)
name = '张三'
change_my_name()
name
匿名函数lambda
python 使用 lambda 来创建匿名函数。
lambda 只是一个表达式,函数体比 def 简单很多。
lambda 的主体是一个表达式,而不是一个代码块。仅仅能在 lambda 表达式中封装有限的逻辑进去。
lambda 函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
注意: lambda 函数只能写一行
# 加法运算 接受两个参数,返回参数之和
add = lambda arg1, arg2: arg1 + arg2
add(1,2)
装饰器
装饰器最大的优势是用于解决重复性的操作,其主要使用的场景有如下几个:
计算函数运行时间
给函数打日志
类型检查
当然,如果遇到其他重复操作的场景也可以类比使用装饰器。
#这是一个装饰器
def arg_decorator(func):
def wrapper(*args, **kw):
print(f'{func.__name__} is working...')
func(*args, **kw)
return wrapper
课节四
类和对象(一)
class关键字:
代码通常称为类的方法,数据通常称为类的属性,实例化的对象称为实例
创建过程:
第一部分:class定义类的关键字,Athlete符合python标识符命名规则,:表示类内容的开始
def init(self,a_name,a_dob=None,a_times=[]):
第二部分:def定义函数的关键字,init 方法是一个特殊方法会在实例化对象时自动调用,我们会在这个方法中对数据进行赋值。self作为类中函数的第一个参数,方便该方法调用该类的其他属性和方法。
第三部分:自定义的属性和方法
#创建一个Athlete类
class Athlete:
def __init__(self,a_name,a_dob=None,a_times=[]):
self.name = a_name
self.dob = a_dob
self.times = a_times
def top3(self):
return sorted(set([sanitize(t) for t in self.times]))[0:3]
def sanitize(self,time_string):
if '-' in time_string:
splitter = '-'
elif ':' in time_string:
splitter = ':'
else:
return (time_string)
(mins,secs) = time_string.split(splitter)
return (mins+'.'+secs)
#创建一个实例:
james = Athlete(james_name,james_dob,james_times)
类属性
所有对象共享的数据
定义:
在 init 之上,或者说在类的范围内与方法同等级别,书写变量名=值
调用:
类名.类属性
类方法
所有对象共享的方法
定义:
方法定义时,使用@classmethod标记
调用:
类名.类方法
对象.类方法
设置私有属性和方法
在属性和方法名前加 __ (两个下划线)
课节五
类和对象(二)
子类
定义:
class 子类名(父类名):
情况1,如果子类有新增的属性,那么需要在子类__init方法中,调用父类的__init__
情况2,如果子类没有新增的属性,子类不需要写__init__方法
使用:
对象名 = 子类名(参数)
继承的好处:代码重用,升级功能(重写),新增功能(新的方法)
#创建Athlete的子类Rugby
class Rugby(Athlete):
def __init__(self,a_name,a_bod,a_squat,a_times):
Athlete.__init__(self,a_name,a_bod,a_times)
#新增一个属性squat
self.squat = a_squat
#改变函数top3
def top3(self):
return sorted([self.sanitize(t) for t in self.times])[-3:]
多继承
#创建Child类,同时继承Father和mather类
class Father():
def talk(self):
print("---爸爸的表达能力---")
class Mather():
def smart(self):
print("---妈妈聪明的头脑---")
class Child(Father,Mather):
pass
child1 = Child()
child1.talk()
child1.smart()
课节六
文件操作及常用模块使用
导入模块:import关键字
打开文件:open关键字
import sys
#读取整个文件内容
f = open('work/train_data_cor.txt')
line = f.readline()
while(line != ''):
print(line)
line = f.readline()
f.close()
对象转json
- 导入json模块
- dumps函数
import json
class Athlete(json.JSONEncoder):
def __init__(self,a_name,a_dob=None,a_times=[]):
self.name = a_name
self.dob = a_dob
self.times = a_times
def top3(self):
return sorted(set([self.sanitize(t) for t in self.times]))[0:3]
def sanitize(self,time_string):
if '-' in time_string:
splitter = '-'
elif ':' in time_string:
splitter = ':'
else:
return (time_string)
(mins,secs) = time_string.split(splitter)
return (mins+'.'+secs)
with open('work/train_data_cor.txt') as f:
data = f.readline().strip().split(',')
ath = Athlete(data.pop(0),data.pop(0),data)
print(ath)
ath_json = json.dumps(ath.__dict__)
实例:作业六
题目:
数据如下:
stu1.txt 孙同学,2020-5-21,20,‘男’,77,56,77,76,92,58,-91,84,69,-91
stu2.txt 赵同学,2020-11-3,24,‘女’,65,68,72,95,-81,71,86,91,57,91
stu3.txt 王同学,2021-8-7,25,‘男’,87,78,90,-76,88,47,100,65,69,100
stu4.txt 李同学,2021-8-10,29,‘男’,92,54,85,71,-91,68,77,68,95,95
以上四个txt文档在work路径下可以找到。
定义Student类,包括name、dob、age、gender和score属性,包括top3方法用来返回学生的最大的3个成绩(可重复)、sanitize方法用来将负的分数变为正的分数,负的分数可能是输入错误。声明stu_list对象组数用于存储所有的学生对象。最后输出所有的学生信息包括姓名、生日、年龄、性别、最高的3个分数。
第一题的输出结果如下,供参考:

答案:
# 请在此处完成代码
def get_stu_list(filename):
with open(filename) as f:
line = f.readline()
return line.strip().split(',')
class Student():
def __init__(self,name,dob,age,gender,score):
self.name=name
self.dob=dob
self.age=age
self.gender=gender
self.score=score
def top3(self):
return sorted([self.sanitize(t) for t in self.score])[-3:]
def sanitize(self,score_string):
score=abs(int(score_string))
return score
def print_stu(stu):
print(f'姓名:{stu.name} 生日:{stu.dob} 年龄:{stu.age} 性别:{stu.gender} 分数:{stu.top3()}')
st1_data=get_stu_list('work/stu1.txt')
st2_data=get_stu_list('work/stu2.txt')
st3_data=get_stu_list('work/stu3.txt')
st4_data=get_stu_list('work/stu4.txt')
st1=Student(st1_data.pop(0),st1_data.pop(0),st1_data.pop(0),st1_data.pop(0),st1_data)
st2=Student(st2_data.pop(0),st2_data.pop(0),st2_data.pop(0),st2_data.pop(0),st2_data)
st3=Student(st3_data.pop(0),st3_data.pop(0),st3_data.pop(0),st3_data.pop(0),st3_data)
st4=Student(st4_data.pop(0),st4_data.pop(0),st4_data.pop(0),st4_data.pop(0),st4_data)
print_stu(st1)
print_stu(st2)
print_stu(st3)
print_stu(st4)