CUDA简介——基本概念
1. 引言
使用GPU的主要原因在于GPU的超级算力。
GPU相对CPU的两大优势在于:
- 1)巨大的计算吞吐量
- 2)超级高的内存带宽
下图展示了NVIDA GPU和Intel处理器 的计算吞吐量在过去十来年的增长变化,对应的计算单位为 每秒10亿次浮点运算。
- 绿线表示NVIDA系列GPU在不同时间点的计算吞吐量变化。
- 蓝线表示Intel系列CPU在不同时间点的计算吞吐量变化。
以GeForce GTX TITAN为例:所提供的计算吞吐量,比Intel的Tesla K40 CPU大一个量级。背后的主要差异:
- 在于图像处理器和CPU之间的浮点运算能力。
- GPU专用于计算密集型、高度并行化计算——graphic rendering所用武之处。
- 设计了更多的晶体管,专用于数据处理,而不是data caching和高级控制逻辑。
2. CPU与GPU不同之处

CPU与GPU的不同之处在于:
- CPU设计为让延迟最小化:
- CPU的大多数硅面积专用于:
- Advanced Control Logic
- on-chip Large Cache
- 适于通用程序,如运行某操作系统
- CPU的大多数硅面积专用于:
- GPU设计为让计算吞吐量最大化:
- GPU的大多数硅面积专用于:
- 大量的cores:即大量的Arithmetic Logic Units(ALU)。NVIDIA称其为CUDA cores。
- 适于解决 可表示为数据并行计算的问题——即在很多data elements上并行运行相同的程序。
- 因为每个data element运行的是相同的程序,就降低了对 成熟Control Logic 的要求。
- 由于程序执行在很多data elements之上,相应的内存访问延迟可被calculation隐藏,从而无需big Caches。
- GPU的大多数硅面积专用于:
3. 如何利用大量的CUDA cores?
为充分利用大量的CUDA cores,需将程序中可并行化的部分,分解为大量的线程,这些线程可并行在CUDA cores中运行。
CUDA中的这些线程由特殊的名为kernel的函数定义。
kernel为:
- 运行在GPU之上的函数。
kernel的执行,称为,launching a kernel(启动 a kernel)。当启动a kernel时,会执行kernel函数:
- Kernels以一组并行线程执行。
- 每个thread映射 到 GPU上的单个CUDA core。
3.1 相关概念和术语
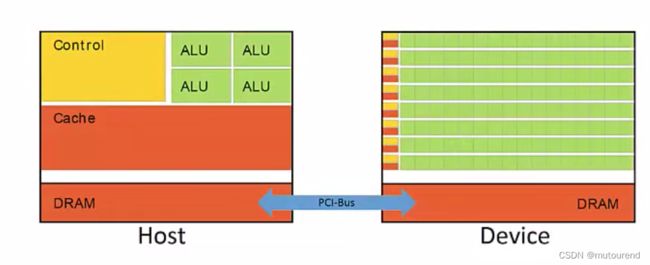
CUDA编程模式中的2大硬件为:【CPU和GPU有各自专用的内存区域。】
- 1)Host:为CPU 及其 on chip memory(也称为计算机RAM)。
- 2)Device:为GPU 及其 专用DRAM。
CPU擅长于运行serial programs,CPU的问题在于当所运行的某部分代码是高度并行化的时候,则这部分代码有可能会称为 程序flow 中的瓶颈。因CPU不是设计用于大规模并行吞吐量场景的,而GPU非常擅长于运行程序中可高度并行化的某部分代码,从而可将这些可高度并行化的代码,卸载给GPU执行。
同时使用Host和Device,称为Heterogeneous parallel programming,这样可同时利用二者的最强优势。
CUDA:
- 为扩展C
- 专门针对NVIDIA GPU设计,支持Heterogeneous parallel programming,的编程语言。
- 为简单C 再加 一些扩展,从而同时支持Host和Device一起运行。
在Heterogeneous parallel programming中:
- Host用于控制program。CUDA program的大部分通常都是像CPU上的传统软件一样串行执行的。
- 对于代码中可高度并行化的部分,可将那部分代码的执行传递给Device。
Host和Device相互通过PCI-Bus来通信。相对于Host和Device,PCI-Bus非常慢。因此,Host和Device之间的数据交换开销是非常昂贵的。因此,仅在Device上执行可高度并行化的那部分代码。
3.2 Threads
Kernels execute as a set of parallel Threads。(Kernels以一组并行Threads执行。)
CUDA threads可利用GPU上的大量CUDA cores,来执行CUDA kernels——具有大量的threads。
CUDA设计为以数千甚至上百万个Threads来执行每个kernel。
CUDA Threads以SIMD(Single Instruction Multiple Data,单指令多数据流)方式执行。
每个thread执行相同的指令,但处理的是不同的数据。NVIDIA称其为SIMT(Single Instruction Multiple Thread)。
Threads类似于data-parallel tasks:
- 每个thread基于某data subset,做相同的操作。
- thread之间的执行是相互独立的。
需注意的是,各threads并不是以相同的速度执行的,取决于:
- 所进入的不同if/else路径。
- 循环中的不同迭代次数,等等。
- 即使每个thread执行相同的指令,其处理data subset也通常是不同的。因此,由同一kernel启动的threads,执行的速度是不同的。
3.2.1 Threads配置
如何将threads匹配到GPU上的cores?
CUDA有相应的threads分层设计,主要分为3层:
- 1)最底层为:Threads:Kernels execute as a set of parallel Threads。(Kernels以一组并行Threads执行。)
- 一个thread,为基于单个data片段来执行一个kernel。
- 当kernel launch时,每个thread,映射到GPU上一个CUDA core。
- 2)中间层为:Blocks:Threads are grouped into Blocks。
- 为将threads分组为blocks。
- 当kernel launch时,blocks映射为相应的CUDA core sets。
- 3)最上层为:Grid:Blocks are grouped into Grids。
- 为将blocks分组为Grids。
- 每个kernel launch,创建一个Grid。一个Grid会映射到整个GPU及其内存。【即,一个kernel launch,执行为一个grid,该grid映射到整个Device。】
即,可看成是blocks由threads组成,grids由blocks组成。因此,每个grid可分解为一组blocks,每个block可分解为一组threads。具体的组成方式可为1D、2D或3D,从而有:
- Grid Dimension:为每个Grid的Block结构。
- Block Dimension:为每个Block的Thread结构。
如上图所示,当launch对应该grid的kernel时,实际在GPU上一共会并行执行72个threads。
参考资料
[1] 2019年5月视频 Intro to CUDA (part 1): High Level Concepts
CUDA系列博客
[1] CUDA入门
[2] CUDA C++ Programming Guide
[3] Cooperative Groups:更灵活的CUDA thread同步