ORers‘ Bling Chat | 【高光聊天记录集锦-01】:运小筹读者群里那些热烈的讨论
ORers' Bling Chat | 【高光聊天记录集锦-01】:运小筹读者群里那些热烈的讨论
-
- 前言
- 1. 关于置信水平如何取值的问题
- 2. 关于各类solver的讨论
- 3. 关于最小冲突集、冲突集的讨论
- 4. 关于MP论文的讨论
- 5. 关于gurobi的log (1)
- 5. 关于gurobi的log (2)
- 6. 关于双层规划的讨论
- 7. 关于特征工程方面的讨论
- 8. 关于gurobi约束写法的讨论
- 9. 关于gurobi多次求解结果不同的讨论
- 10. 关于RL推导的讨论
- 11. 关于gurobi中变量lb的设定
- 12. 各类资源
-
-
- 2.1 片段
- 2.2 推送
- 2.3 招聘&会议(选取部分有链接的)
-
前言

一直以来,运小筹的读者们都在运筹优化领域及其相关领域保持着较高的活跃度,不论是工作日,还是节假期,甚至大年三十、大年初一,热心的读者们都在群里进行着热烈而有趣的讨论,这让我们倍觉鼓舞。在帮助别人的同时,我们自己也在不断学习,不断进步。通过群聊中的讨论,小编们觉得时时刻刻都能学到新的知识,也是心花怒放呢。在这里,我们感受到了浓厚的学习氛围,找到了大批同路人,也结识了一批好朋友。
推文自然是小编们跟大家分享技术笔记的一个途径,但是我们高质量、高频率、涉及范围广的聊天记录也是不亚于推文信息量的一种有效地学习途径。因此,小编们决定不定期将高质量、精彩、有趣、有用、有料、有技术细节的聊天记录通过匿名的形式整理出来分享给大家,供大家闲来无事读来玩玩。哈哈。
这里特此声明,群聊内容不保证100%正确,不保证100%可信,如有错误,纯属正常,另外,希望发现错误的小伙伴们不吝赐教,在留言区留言哦。
注:为方便理解问题,整理过程中有筛选合并等,敬请谅解
1. 关于置信水平如何取值的问题
Discussant(按发言先后)
- A同学: 电力系统研究生
- B教授:某高校老师
- C博士:运小筹小编
- D同学:运筹优化方向研究生
- E教授:某高校老师
- F博士:运筹优化方向博士生
- A同学:麻烦问下大家,如何确定机会约束的置信水平呢
- B教授:自己主观确定,灵敏度分析,各种置信水平下做例子分析
- A同学:我们老师说,灵敏度是事后检验的,不能用,要事前确定的
- C博士:确定置信水平?这个,不就是自己去涉及多个做数值实验,90%, 95%。 97.5%什么的做数值实验啊,不理解你的问题,什么叫确定置信水平,为什么要确定?那不是个参数嘛,来自于决策者的接受度呀,来自于决策者的接受度呀,来自于决策者的接受度呀,就是概率上一般认为,5%就是一个小概率事件了,那小概率事件总得给一个边界吧
- A同学:老师说,能不能出个理论啥的,不要自己瞎拍,老师说,能不能出个理论啥的,不要自己瞎拍
- C博士:就是,显著性水平为啥是95%,引起了一段争议呢,没有定论的,这个就是一个约定俗成的,很多统计类的软件也是这么做的吧
- A同学:置信水平和正不正态有关系嘛
- C博士:没关系,只看概率分布函数cover的面积,面积之和=1嘛。落在其余部分的5%就行,所以置信区间为95%的区间也不是唯一的,你可以挪来挪去,都是95%置信区间
- A同学:嗯嗯,这个我知道,我是要一个单边的,机会约束里,老师让我去说到底应该取什么数值
- C博士:你是说机会约束里那个\epsilon的取值呗,那个概率95,90%到底是哪个最好,哈哈,那我无能为力了
- (C博士无奈,D同学登场,发现确实有意义)
- D同学:你可以在数值实验那块补充一个灵敏度分析,看看置信度取值的影响,如果有影响,就得出管理学见解,如果没影响就把这一块放到附录里面去,不知这样是否可行,你机会约束最后怎么解决的,用SAA吗
- A同学:不是的,我是正态的,正态直接解析出来。
- D同学:哦哦,这个置信度有啥创新的,灵敏度分析得出管理学见解这种不也算创新吗
- A同学:嗯嗯,他说这个以前都是工程经验,人为随便给的,他的意思是可以啥精确化计算
- C博士:嗯嗯,不错的想法,你可以衡量一下关于风险的东西,比如,最小化风险啥的,然后整个推导,置信区间的话,确实比较粗略,只考虑了概率,没考虑到具体的取值,如果把这个也考虑进来,可以推一推,然后给一个最小化联合风险的指标,min得到一个东西,那就是你想要的了
- (E教授参与进来,达成共识)
- E教授:关键的问题是 怎么定义最好,我猜你们老师想说的是 可能这个问题 决策者一般告诉你 我们能做到95confidence就好了 然后你就去算最优,但你可以根据这个系统本身告诉决策者 其实可以达到97的confidence的
- A同学:老师,是可以达到97的,97我试过,有解,但是目标函数增大
- C博士:也许是这样的:一般我们是说约束被满足的置信度为95%,此时,\epsilon=0.05,但是有时候我们可能并不只是想让约束成立,我们是想最小化成本或者其他类型的风险,而这个约束成立的置信水平,只是一个附带的东西,是根据别的推出来的。比如,我想我的最大风险最小,至于这个约束成立的概率,不是我最关心的。我根据我的目标函数想要达到的程度,最后推出来,哦,这个\epsilon应该取0.785,这就可以了。但是这个0.785怎么得来的,是根据目标函数和这个的一些关系得到的
- A同学:所以我才想说试不试用灵敏度,看看哪个最好,总有一个最敏感
- C博士:我觉得你老师可能是这个意思,其实关键的一点就是:这个约束成立的概率,并不是你直接关心的事情,而是一个附带的产物,你真正关心的是其他的事
- E教授:举个例子 比如你的这个机会约束是关于时间窗的,那么你可能允许5%的机会不满足时间窗 ,那么应该有一个损益函数 告诉你 如果每一个不满足 可以带来多大的收益和损失,比如一两个 还好 但多了 reputation受影响 损伤就progressive了
- A同学:您和刘博的意思是,还是要引入风险成本,把风险成本加进去
- E教授:嗯 我觉得是的,不然就只能经验去定了
- C博士:对的,加了这个惩罚项,你就可以加入一个风险惩罚。比如,你最终其实是想min 这个惩罚。决策者直接关注的是这个事情,他并不关心约束成立的概率。他可以告诉你,我这个惩罚不能低于1000, 他把这个告诉你,你根据他们的关系推导出来,要满足他的这个要求,这个epsilon就得取0.785,这就成了
- E教授:因为往往一个系统允许一部分违反 主要的几个原因是 一 系统本身就没办法达到100% 这是天生的缺陷,第二 就是 小概率的影响 对目标影响很小 但为了这一部分的满足 需要付出很大的成本,所以我想你老师想你确定一个methodology来定这个,就是 第一 这个约束本身无论做多好 都没办法满足的百分比是多少,再加上 我们是否可以人为再松弛一定的百分比
- C博士:这个可是很难了。这要是能搞,真的强,一个约束无论做多好,都不能满足的部分,这本身就是一个优化问题了,因为还有其他约束的存在
- E教授:这个倒不一定,看约束类型,比如你一个约束是 流平衡约束,那你没办法做到违反
- A同学:嗯嗯,谢谢各位的指点
- (F博士登场,给予建议)
我觉得两个方向可能有创新啊,都会和那个置信度水平相关。
- 随机规划得出的结论不一定是真的如意,就是你用正态分布解析的推导95%置信度水平下的决策,不一定实际上真的能满足。这里的“实际上”是指,你在有限时长的仿真内能统计出来的结果。当然这种不一致的根源可能在于:
(1)随机规划本身的缺陷;
(2)随机量分布刻画不准确。不管是哪一种原因,都需要用到基于数据的仿真来参与评价。那么这个置信度的取值,与仿真得到的结果差距如何最小,可以用simulation based optimization来去解一下。- 目标函数改一下,加入风险的考量。具体形式可以参考金融领域的CVAR定义,和马尔科维茨投资组合优化的目标。总之就让置信度水平就出现在目标里,然后让他作为一个决策变量来去搞(但是这个决策变量的取值范围是有严格限制的,只允许在一个预设值,比如95%,上下波动)。这样我们就构造了一个新的问题,那就有点研究的意思了。
2. 关于各类solver的讨论
- A同学: 研究生
- F博士:运筹优化方向博士生
- H博士: 运筹优化方向博士
- I博士:Gurobi 工作人员
- A同学:有同学用cvxpy做过 优化吗?我遇到的问题其实是, 当矩阵维度上千以后, 每次求解都特别慢。。几分钟, 我想知道是哪里的问题,中证500 的话只500只股票, 500*500的协方差 似乎只要几秒。5000左右标的的话, 我这边就慢到好几分钟了。
- F博士:核心原因就是,他开源,纯cvxpy和scipy做优化,计算性能被商用求解器吊打
- H博士:是凸二次规划吧 ,Gurobi 现在价格不便宜 买liscense的话还是有点肉疼的。金融一般用Mosek比较多,现在凸二次规划 COPT在评测里也是第一了。就是不知道liscense的价格怎么样
- F博士:还可以copt哈哈哈,数值优化方法,如果性能优化不好,收敛可能比较慢。另外,如果希望加速,可以尝试手动输入梯度信息
- I博士:gurobi 的费用对于基金公司来说他们反馈觉得都还好,特别年费更便宜。如果有混合整数问题,性价比会更好一些。
3. 关于最小冲突集、冲突集的讨论
- A同学:*教授,不可行模型最小冲突集,这个技术是杉数科技首创的吗?不知道有没有更详细的介绍?
- J教授:应该老的几个都有吧?manual里有,可以申请一个新版的manual看看,至少gurobi和cplex我记得有?
- A同学:好的,这个功能非常实用
- C博士:computeIIS,其他也有的吧
- B同学:不懂就请教各位大佬,老solver和最近升级的copt寻找出不可行的约束或者冲突的约束,其原理是什么呢
- I博士:这方面gurobi 没有太多提及。但有些做法,比如给约束加松弛变量,然后对不同松弛变量加权重,然后求解松弛后模型,类似这样。估计也就是解一系列模型。机密的程度和算法本身的程度相当。文档中基本不会提及这些。
- F博士:感觉这俩还有点相关,感觉方法有蛮多,一些启发式算法就是根据凸多面体的一些性质来判断,还有一些是构造松弛问题然后寻找矛盾症结的
- 《Identifying Minimally Infeasible Subsystems of Inequalities》、《Deletion Presolve for Accelerating Infeasibility Diagnosis in Optimization Models》、《Generalized filtering algorithms for infeasibility analysis》
- J教授:这几个都要看
4. 关于MP论文的讨论
- C博士: 运小筹小编
- C博士:关于SAA的一篇MP的文章,https://doi.org/10.1007/s10107-021-01753-9、https://doi.org/10.1007/s10107-018-1337-6,还有这个,关于scenario generation的,https://doi.org/10.1007/s10107-019-01442-8。以及姜老师在MP发的robust joint chance constraints的,前些天是谁问这个随机规划的这个来着,正好这篇可以参考
- E教授:谢伟军这一篇文章写得很好的,而且这一篇文章搞懂了就同时搞懂了wasserstein distance处理DRO问题的reformu,lation的原理了,谢伟军很厉害的,你去看看他的发表就知道了 发了好多
- J教授:应该老的几个都有吧?manual里有,可以申请一个新版的manual看看,至少gurobi和cplex我记得有?
- A同学::好的,这个功能非常实用
- C博士:computeIIS,其他也有的吧
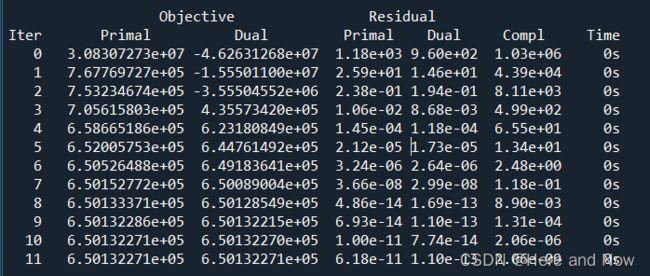
5. 关于gurobi的log (1)
- A同学:想求教一下大家,gurobi求解的结果这几列都代表什么含义呀?找了找文档没有找到
- B同学:安装目录/docs/refman.pdf 当中 logging – Barrier Logging
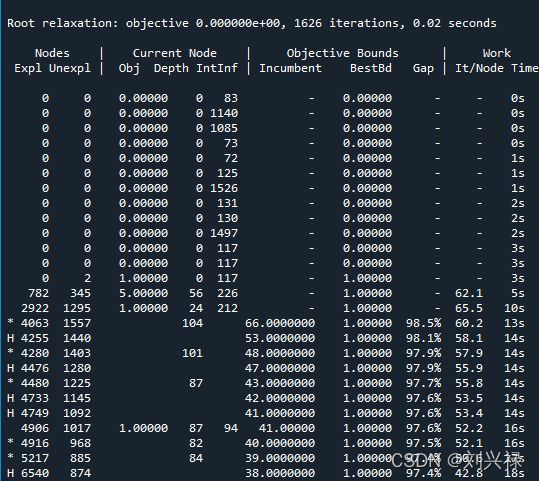
5. 关于gurobi的log (2)
- A同学: 某高校硕士
- 小编: 运小筹小编
- A同学:请问输出的信息是什么意思啊,看不太懂
- 小编:我来解释一下吧,看来也没有其他人自告奋勇来解释一下,哈哈
Nodes部分,是branch and bound的过程统计
-Expl: 就是已经探索过的分支节点的个数,
-Unexpl:就是分支过程中创建的节点,但是还没有被探索的节点的个数
Current Node部分,就是算法正在探索的这个节点的信息
-Obj: 是当前节点的解(一般是小数解)对应的目标函数值
-Depth:是深度
-IntInf: 表示在当前节点的LP relaxation的解中,整数变量取了小数值的
变量的个数。
Objective bounds: 表示目标函数的界限更新的信息
-incumbent: 指的就是current best integer solution,就是到目前为止,找到的最好的整数可行解
-Best Bd: 到目前为止找到的最好的bound,是小数解
-Gap: 就是incumbent和Best Bd之间的间隙或者差距,计算方法是:
Gap = |incumbent - Best Bd| / incumbent * 100%
Work:记录的是在相邻两次report这个log信息的过程中,的单纯形的工作情况- It/Node: 指的是这段时间内,每个node处平均的simplex迭代次数
- Time:指的是,到目前为止,branch and cut算法运行了多少时间。
6. 关于双层规划的讨论
- A同学: 某电力系统研究方向博士生
- (讨论定义)
- A同学:请教各位一个基础问题,双层优化和stackelberg game有什么区别和联系呀?有没有文章或者网页可以准确描述这两者的关系
- B同学:stackelberg game决策有先后顺序,双层优化不限定吧
- C博士:双层规划不限定,没有先后顺序,但是你也得看是啥样的双层规划,很多时候,双层规划的定义也不一样,之前有两种形式的都叫双层规划
- F博士:运小筹推文
- C博士:交通里面,他们经常用这种目标或者优化方向不一致的,我们实验室之前一个师妹他在组会上讲过一些这种双层规划的,leader和follower目标和约束都不一样,但是决策变量有耦合;但是那个推文里的双层规划是两个决策主体的目标和约束是一致的,只是各自的优化方向min or max不一致,以及,如果目标啥的都不一致的话,决策是有个先后顺序的,一般是leader先做决策,follower后做决策,属于斯坦伯格博弈(Stackelberg Game), 决策是序贯形式的
- F博士:对,鲁棒本身属于虚拟的两个主体,其实只关注第一个主体,而且目标一致就不太区分先后,因此在求解上也和两阶段问题很像,但是如果是的确有实际意义的两个主体,那目标肯定不会完全相同,那决策就是有顺序的,是上下层的,可能会用迭代的方式来求解。
- A同学:也就是说,双层规划包含的面更广,考虑序贯决策,需要建模成stackelberg game,我这样理解对么?
- F博士:当然这时候要注意,两个主体两个目标,不一定就建模成双层规划,还可以是多目标规划 ,这时候也是没有顺序的,多目标就追求帕累托了,对的,我之前做过一个配置定价优化问题,厂家是最大化利润,消费者是最大化性价比。那就必须求帕累托解,因为两个目标无法融合
- (和随机规划的区别)
- A同学:是否可以简单理解,上层与下层间的目标函数与约束条件互相包含影响,就可以理解为双层优化问题。
- B同学:能不建成双层规划就尽量别建,毕竟很难求解。除非两个主体的决策者明显存在leader follower relationship
- C博士:两阶段随机规划也符合你的描述,但是决策主体只有一个,但是两阶段随机规划并不是双层规划,还是得有两个决策主体的,不管是真实存在的还是假想的,如果只有一个决策主体,那你不管怎么弄,他都是单层的,min min min min ,怎么整都等价于min,鲁棒里面,其实是假想环境或者随机因素在跟你作对的,哈哈
- F博士:两个主体就对应两个最优化符号,不管是share一个目标还是各自管一个目标,这才是双层的本质特征。
- (决策先后顺序 )
- B同学:下层决策者根据上层的决策,从自身利益出发做出最优决策,同时下层的决策会作为参数反馈到上层中去,然后上层根据反馈,又做出新的最优决策,然后下层再调整。如此反复,最终,整个系统达到动态平衡。我觉得两个决策主体是否存在leader follower关系也是一个能否将问题建模成双层规划模型的关键因素
- F博士:原来我也这么认为,但是鲁棒这里其实是不存在所谓的follow的关系的,决策者和风险(虚拟对手)不存在顺序博弈问题
- D同学:那假设上下层都是线性规划问题,那把下层问题通过kkt条件转化到上层,不管两者的目标函数一不一样,都可以这么处理,那怎么体现决策顺序什么的影响?
- K同学:这个game是个bi-level optima问题,可以检索下
- A同学:我搜了wiki和文献,还是没太明白两者的本质区别,看到群里的讨论,针对两个不可调和/有两个目标的主体,可以构建双层模型
如果双层模型中,决策的顺序有先后,可以构建为stackelberg game,我目前理解到这里了,期待有大神做进一步解答- D同学:不知道这里所谓的有先后具体指什么?双层优化基本都是一个主体的决策结果是另一个主体优化问题的参数,那无论谁第一个算的时候都需要给定个初值,那顺序怎么体现?
- J同学:如果上下层都是线性规划,下层转成kkt条件带入上层约束求解,变成单目标问题了,也不需要给定初值迭代。这时候解的是上层的最优目标,体现的就是上层follower的先行优势吧?如果不能转成单目标问题,需要通过迭代求解的话,应该就体现不出先后顺序了吧
- D同学:也可能是两个主体目标不一致吧?那这里的先行优势指的是以上层目标函数作为优化的方向嘛?那假如上下两层都是线性规划的时候,用迭代的方式求解跟用kkt转为上层的方式求解,结果会一样吗
- J同学:这个问题还真没想过
- D同学:而且好像上下层问题迭代求解,在数学上没法保证一定收敛,不知道对不对,虽然电气领域很多顶刊都是这种方式求解的.很多下层是混合整数规划,没法用kkt
- K同学:有的双层优化的,他们那种迭代多次的,不一定是最优的, 有时候可以直接用遗传+CPLEX交替解的,可能不是最优的
- C博士:对的,ADMM不一定收敛
- D同学:trans里很多是,两个主体轮流算,算到最后跟上一次策略基本不变了就算收敛,主要是双层问题下层是混合整数的时候,是没啥很好的办法解决吧
- C博士:那他们有global lower bound和upper bound更新,以及提供gap嘛,收敛了应该是gap到0了才能说理论上收敛了,不变了,就收敛了,这个又不一定,哈哈,兴许是局部最优呢
- K博士:嗯呢,遗传没gap,精确求解可以用benders,在书里可以找到
- (E教授半夜醒来,一锤定音双层规划和 stackelberg game的区别)
- E教授:双层优化问题 是看的关于x和以x为函数的两个目标的加权最优,game模型寻找的是均衡,两个决策者的最优决策只是均衡态的最优,不是加权最优,如果要寻找的决策是整体最优 那么stackelberg game就变成双层优化了,回答完毕 继续睡觉~

7. 关于特征工程方面的讨论
- A同学:问一个特征工程方面的问题,在数据量很小的时候,比如样本只有350多个的时候,有些特征缺失就200多。这个还必要进行处理吗
用均值替换后的这个变量 ,随机森林挑选出的变量重要性,排名还很靠前
- F博士:这特征你还要他干啥 ,问题是也许在其他数据集上效果就不一定好了。而且均值替代本身就掺入了噪音,那个importance里其实有蛮多水分的。
- A同学:用均值填充后,用RFE来筛选
- F博士:ML不能光看可操作性(效果),还得看可解释性。一个如此稀疏的特征,我是不太相信他真正能work的,你如果一定要用这个特征,就现在他不缺失的那些样本上训练一个监督学习模型,如果准确率足够高,用它的结果来填充那些缺失样本。总之,你要尽量保证你填充的值贴近真实值,那么无论什么特征选择方法认定它有效,才是真的有效。当然,类似地,可以尝试矩阵补全(但矩阵补全是有一定限制条件的,具体可以自己去查)


8. 关于gurobi约束写法的讨论
- A同学:约束包括决策变量的norm项可以直接使用。如果要加入norm(X-X’)呢,其中X是决策变量(向量),X’就是一个向量(每个分量都是数)咋写呢。
- I博士:对于表达式,引入辅助变量=表达式,然后把辅助变量放在norm函数里

9. 关于gurobi多次求解结果不同的讨论
(关于原理的讨论)
- A同学:请问gurobi求解规划问题时,在求解过程中会有随机的成分吗?如果多次求解某一个规划问题时,或者更换电脑时,除了最优值保持不变外,会由于多重最优解而导致产生不同最优解的情况出现吗?
- E教授:如果不是唯一最优解的话 是有可能产生不同的解的
A同学:说明求解算法有随机性吗,如果对于线性规划的单纯形法也是存在这个问题的么,刚才对同一个问题进行建模,一个是gurobi直接建模求解,一个是pyomo建模然后调用gurobi来求解,所有参数都保持默认,但是出现了最优解不同的情况。即使Method都设置为 0(primal simplex),最优解仍然是不一样的- C博士:线性规划?最优值一样的吧,单纯形法里面,选择入基变量或者出基变量的时候是会有一些随机性的啊,比如,他们可能采取了不同的入基选择标准,以及出基的时候,也有可能由于同样的最小比值啥的吧
- B博士:正常来讲精确算法其中的选择等行为的规则定下后,怎么算都是一样的。你大概率是Gurobi自己用启发式逼近下界成功了,这个是gurobi里我知道的有启发式的地方,在log前面会用H标出来
- C博士:如果是MIP的话,内部是有几十种启发式的
- A同学:但是多次运行用gurobi建模并求解的文件后,最优解都是一样的,以为求解过程中会有一套固定的入基选择机制
我看这个Xn属性只对MIP问题有效,我就是一个普通的线性规划问题
- C博士:嗯嗯,这个Xn是MIP的,存储多个解的
- B同学:线性规划最优值一样最优解不一样是因为退化?
- C博士:不一定的,如果目标函数的方向和某两个或者多个corner point连接的边平行了,会出现多个最优解
(两个文件的比较)
- A同学:这是两者都设置Method=0生成的log文件
C博士:这输入也不一样啊
这个RHS range指的是右端项常数的范围
- W教授:row是约束,column是变量,非零是指约束矩阵,nonzeros指约束矩阵不为0的数量
- A同学:之前因为在gurobi写了一个冗余的约束循环,导致了多了一些约束,现在删除了之后,还是提示多了一个约束,而且最优解仍然不同
- F博士:你这模型可能有数值问题,另外,如果你要验证随机性问题,可以尝试手动固定随机数种子,这跟退不退化没关系,而且求解器一般会尽量避免数值问题
- A同学:而且有个很神奇的现象,我把目标函数都改为了常数1,gurobi的 Objective range 是 [0e+00, 0e+00],但是pyomo建模之后的 Objective range为 [1e+00, 1e+00]
是这个参数吗
- F博士:我之前想的是编程环境里的,当然你固定这个也可以,就跟写dl一样,torch和numpy里的随机数种子都可以同时固定
- A同学:我的约束条件系数变化不是很大,而且没有出现warning警告,也可能会出现数值问题吗?这个有什么好的解决方法呢,不知道数值问题产生的具体原因
- F博士:你这系数矩阵最低到最高,数量级差了太多了,我怀疑有,一般到这个量级就是报警了,grb的报警功能太谨慎,有时候不要完全信
- W博士:这二个模型的fingerprint 不一致,说明这二个模型总有些不同,比如约束的次序。这些差别会导致结果不同。如果fingerprint一致,那么设置method=0,1,2,这些确定值,在同台机器上,在设置非时间为标准的终止条件下,应该会相同结果。
这二个模型的约束数量和变量数量差1,你可以把二个lp用比较软件比较一下,我比较推荐 compare it 这个比较软件
(关于RHS range的讨论)
- A同学:谢谢王博士,我再核对一下两个模型有什么区别,还想请问一下RHS range这个常数项范围是包含决策变量的范围吗,还是说只针对于约束条件右端系数的上下界
- W博士:好问题。看你怎么写。如果你在定义变量的时候,通过lb=,ub= 设置的,那么这些属于bound 范围,不属于rhs 范围。但如果你后来以约束方式定义变量范围,例如x<=10 写在约束里,那么这个属于rhs 范围,但我不知道pyomo 怎么处理的。我说的仅限直接写gurobi
- A同学:明白了,那如果定义变量的话,按照默认lb=0,ub=正无穷的情况,Bounds range的上界也会提示是0吗
- W博士:我这里记得不一定对,无穷大应该不计入bound 里,你可以测试一下。我记得系数范围仅限有意义的数值。有时候gurobi 问题淹没在信息中我没看到的话,可以发邮件到[email protected]
- A同学:我这两个模型没有在约束里进行变量范围的限定,都直接在变量里进行了非负限定。但是RHS range提示的lb是不同的,那就只可能是约束条件有不同了,我检查一下,看看多的一个约束和变量在哪里

10. 关于RL推导的讨论
- C博士:问小伙伴们一个小问题哈
Dueling Network里面,优势函数A(s, a)的正负应该都是<=0的吧。我根据图1是楞没推出来图3,根据图1,我感觉Q大,但是定理却是V大,哈哈,有强化学习大佬可以解答下疑惑不?
- C博士:我自己觉得advantage function是可正可负的,但是我看了王树森大佬的教程,它里面说,dueling DQN的原文推导有问题,让读者不要跟着原文走,跟着他走,但是根据他的讲义,就是
A*(s, a) <=0恒成立,
max_a A*(s, a) = 0 恒成立,
这样的话,这个advantage function就只能是负的- C博士:我去看了原文的推导,原文自始至终没有说advantage function正负的问题,只说了下面的图中的
- C博士:这里也许树森大佬是对的,确实这个感觉是不成立的
这个博主其实也是没有自己验证的。他基本就是照抄原文拿过来的,所以他可能也没真正发现问题所在,按照他说的it follows V ∗(s) = maxa Q∗(s, a)那就是A(s, a) <=0恒成立以及max_a A(s, a) =0,而不是 E[ A(s, a) ] = 0 (错误的)。- F博士:其实我觉得这个在Bellman expectation equation和Bellman Optimality equation中应该能分别得到验证的, 当然,如果不是期望或最值的话,那肯定是不等的,个人认为是可正可负,但有些帖子说一定是负值。
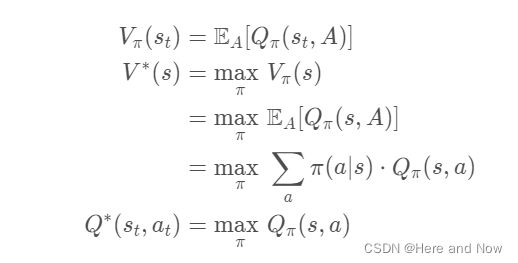

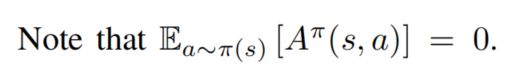

11. 关于gurobi中变量lb的设定
- A同学:求问这个为啥会不可行或者无界呢
- F博士:变量默认下界看看
- A同学:
- C博士:你没设置lb呀,lb默认0,上界默认infty,哦哦, 上面已经回答了,建议不论什么情况,不要使用默认;你看我的所有教程的代码,即使是0-1变量,我都设置了lb和ub,实际上不用设置,但是还是养成好习惯,从过程上就避免这种坑


12. 各类资源
Speaker(按发言先后)
- G同学: 南洋理工硕士生
- C博士:运小筹小编
2.1 片段
- G同学:tutorial、example、tricks、cheatsheet、cookbook、awesome、在学习任何一个领域的内容的时候,这几个关键词都用得上。以python为例,我们可以搜索:python tutorial、python tricks、python cookbook……加上:webinar、workshop、seminar、lecture、slides、review、survey、还有大家共筹各种资源、vip。 搜索的关键词再加一个“lecture notes”,比如scipy看文档的话量有点大,看lecture notes就很精到
- G同学: 多元统计分析_厦门大学(更新中).(转)这个俺完整看过,很下饭, AITIME论道. 、 TechBeat人工智能社区.
- G同学:aws的服务器很好,就是有点贵,而且销毁机器、开新机好快,机器的批量定制化也非常灵活,存算分离aws做的最好。plus,colab pro白买了,连不太大的CNN都急死了,短线还是有。然后,keras的TPU不知道大家用过么,keras也是断线2333, (评论:断线的问题我记得是要设置端口什么的断了也会继续运算?)
- G同学: 智源网站. 智源网站在肉眼可见的进步,搜RL很细致的网站.、Road to MachineLearning .

- C博士:IJOC这几篇新文章感觉都挺不错呀!
- G同学: 机器学习资源.这个每个都含代码
- F教授:微分神作 推荐阅读


2.2 推送
- (1) .鲁棒优化|基于ROME编程入门鲁棒优化:以一个例子引入(一)
- (2) .数学规划求解器COPT4.0的深度解读
- (3) .最新!145页运小筹优化理论学习笔记发布(2021年4月–9月)!
- (4) .优化|Gurobi处理非线性目标函数和约束的详细案例!
- (5) .优化 | 随机规划案例:The value of the stochastic solution
- (6) .最新!213页运小筹优化理论系列笔记发布!
- (7) .一周速递|三名运筹学者获选美国工程院院士,Deepmind实现人类首次AI控制核聚变反应
- (8) .鲁棒优化 | 以Coding入门鲁棒优化:以一个例子引入(二)
- (9) .物流大讲堂345:最优广告插入策略
- (10) .鲜有人知的强大序列预测算法
- (11) .89本期刊被列为预警期刊,5本被列为高风险
- (12) .2022优青(海外)项目开始申请
- (13) .盘点:近两年国自然项目不予受理的主要原因
- (14) .深度学习模型的多Loss调参技巧
- (15) .用 Xy-pic 绘制数学交换图
- (16) .ICLR 2022 | 利用预测信息的在线设施选址算法
- (17) .2021智慧交通创新50强
- (18).纹理织物瑕疵检测中的优化问题
- (19).纹理织物瑕疵检测中的优化问题
2.3 招聘&会议(选取部分有链接的)
- (1) . 海外优青招聘:香港科技大学(广州)
- (2) . 字节跳动 运筹优化算法实习生-电商
- (3) . A类博士年薪25万,5200/月额外津贴,三年内副教授待遇!35万安家房补+30万科启
- (4) . 新疆大学热切期盼博士等高层次人才加入 共创事业新篇
- 安家费都是分三年给,好像如果要买房,可以去申请一次性,没有非升即走,他的博士引进分ABC 三类,你入职是哪一类,你三年完成相对应的KPI就可以啦。如果大家有意向想进电气工程学院的,可以直接联系学院的张老师(箱:[email protected])或者联系我可提供张老师电话
- 他这个人才引进计划是博士学历的入编引进名额,有职称的引进 名额不算在那个里面,应该是可以单独谈的,内地除了985以外,都是叫专任教师
- (5) . 浙江科技学院诚邀全球英才申报2022年国家优青(海外)项目
- (6) . 安家费30-60万 | 玉溪师范学院2022年常年招聘博士公告
- (7) .不好意思打扰大家,今年10月在澳门举办的IEEE ITSC2022(https://www.ieee-itsc2022.org/)上, 我们将会主持一场以CAV+AI (无人车+人工智能)为主题的special session, 重点关注由人工智能赋能的单个及网联无人车控制优化问题。如果大家准备投稿ITSC2022并且论文与题目相关,欢迎大家投稿我们的session。 具体投稿可选择Special Session Paper, 并且输入session code: e7wse。如有任何问题,欢迎随时联系我(wechat:lemma171)或发邮件[email protected]
- 图文整理:勾笑盈,中国科学技术大学,硕士在读
- 审校:刘兴禄,清华大学,博士在读