Python语言的数据结构
在我们的Python语言当中所谓的数据结构其实就是一些存储数据的类型。就比如说我们C语言当中的数组和结构体一样。我们Python语言当中的数据类型包括列表,元组,字典,集合,字符串五种形式。我们使用这四种不同的数据类型可以对数据进行不同的处理操作。接下来我们就依次来认识一下Python语言中的数据类型。
1.列表
列表可以说是我们见得最多的Python数据结构之一了。列表的实质和我们C语言中的数组很相似。C语言中的数组可以存储一串相同的数据到我们指定的内存当中,我们可以通过下表引用的方式进行数组元素的处理。而我们Python语言当中的列表能够将我们不同的数组存储到我们的内存当中。我们同样可以使用下表索引的方式找到我们指定的元素。和我们的C语言不同的是,我们的列表可以通过正方向索引也可以通过负方向进行索引。正方向索引是从0开始到我们数组元素个数-1的位置。而我们的负方向索引可以从负一一直到我们的负元素个数进行依次检查。我们的列表由方括号引出一系列的数据,数据之间必须使用逗号进行分隔。列举一个简单的代码示例如下:

就像我们上面运行结果所显示的那样,我们从正方向找到元素和从我们的负方向找到我们的元素的效果都是一样的。
在我们的Python代码当中我们的列表不仅仅可以进行数据的存储,我们的Python语言还自带了一系列的功能以便于我们对列表进行一系列相关的处理工作。
对于列表的操作有很多种,我们可以通过列表的使用函数(方法)扩充我们列表的内容。具体的代码如下:
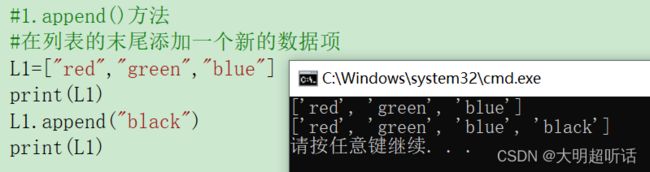
#1.append()方法
#在列表的末尾添加一个新的数据项
L1=["red","green","blue"]
print(L1)
L1.append("black")
print(L1)
#2.insert()方法
#在特定下标的位置处插入一个元素
L1=["red","green","blue"]
print(L1)
L1.insert(1,"yellow")
print(L1)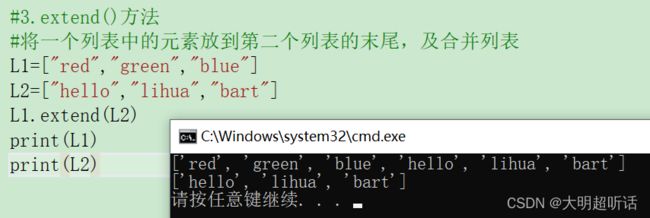
#3.extend()方法
#将一个列表中的元素放到第二个列表的末尾,及合并列表
L1=["red","green","blue"]
L2=["hello","lihua","bart"]
L1.extend(L2)
print(L1)
print(L2)
#4.remove()方法
#删除列表当中第一个与X匹配的元素
L1=["red","green","blue"]
L1.remove("green")
print(L1)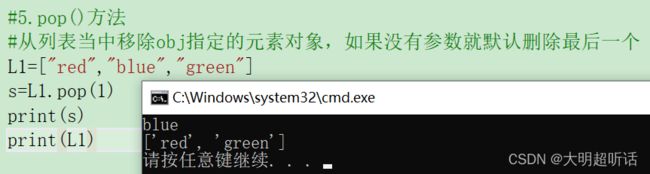
#5.pop()方法
#从列表当中移除obj指定的元素对象,如果没有参数就默认删除最后一个
L1=["red","blue","green"]
s=L1.pop(1)
print(s)
print(L1)

#6.index()方法
#用于返回列表中第一个与x匹配的元素的下标的位置。
L1=["red","blue","green"]
s=L1.index("blue")
print(s) 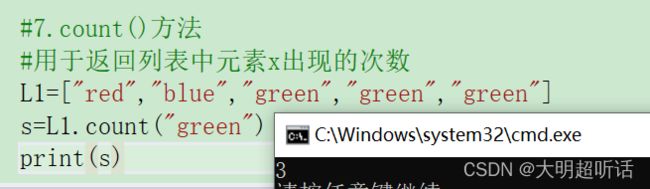
#7.count()方法
#用于返回列表中元素x出现的次数
L1=["red","blue","green","green","green"]
s=L1.count("green")
print(s)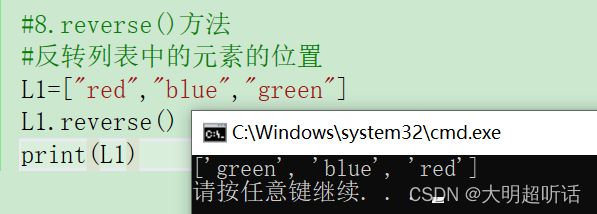
#8.reverse()方法
#反转列表中的元素的位置
L1=["red","blue","green"]
L1.reverse()
print(L1) 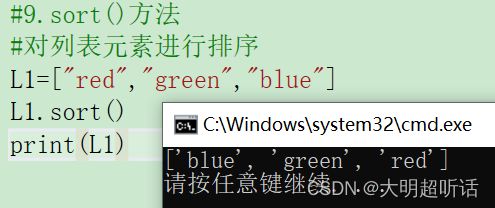
#9.sort()方法
#对列表元素进行排序
L1=["red","green","blue"]
L1.sort()
print(L1)在介绍完我们的列表之后我们再来认识一下和我们的列表很相似的数据结构——元组。
2.元组
说到元组肯定最先需要点明的就是我们元组和列表之间的差异。我们列表当中的数据对象都是可以改变的,我们可以通过相关的操作对我们列表当中的数据进行改写。而我们的元组中的元素不能被修改,我们只可以对元组中的元素进行找到等相关操作。
说完元组和列表的差异,我们就正式来认识一下元组的书写方式,首先我们的元组是由两个圆括号构成,圆括号当中可以存放一系列的数据,数据之间必须使用逗号进行分隔。那么我们同样使用一段代码加深我们对于元组的认识:

list1=("hello",12,"world",13)
list2=tuple("hello")
print(list1)
print(list2)当我们的元组当中只有一个元素的时候我们需要在前面表明tuple字样,表示我们所列出的数据是一个元组。在对我们的元组介绍完之后,我们再来认识一下我们的集合。
3.字符串
字符串就是一串字符,我们同样可以使用下表正或负索引进行查找指定的字符元素,但是需要记住的是字符串和我们的元组一样,其中放入的数据不能再被改写。所以我们只能对字符串进行查找等操作。同时我们还可以使用Python语言当中的内置函数对字符串进行指定的处理。所示的代码如下:

strings="abcdef"
for i in strings:
print(i)对于字符串的操作我们还有一步重要的操作:切片操作。对于字符串的切片操作和我们的range()函数较为相似。同样拥有三个参数其具体的语法如下:序列名[i:j:k] 其中 i 表示的是开始索引的位置,j表示的是结束索引的位置,k是读取元素时的步长。具体的代码操作如下:

#对于字符串进行分隔操作
strings="abcdef"
print(strings[1:6:2])4.字典
在Python语言当中的,字典dict使用键值的形式来存储数据,所谓的键值指的就是一个标签名对应着一个值,我们可以将其表示成 标签名:键值 的形式。Python中我们可以使用大括号来创建字典,其中键和值之间使用冒号隔开,一个键值对被称为一个条目,每一个条目直接使用逗号隔开。如果大括号里面没有键值对的话就会创建一个空字典。我们可以使用 dict[键]=值的形式向我们字典当中添加新的键值对,如果我们添加的键在字典中已经存在就会将我们添加的操作修改为更新。同样的我们可以使用Python语言的内置函数进行字典内容的查找和修改,其中所示的代码如下:

#对于字典的创建
d1=dict()
print(d1)
d1=[("lihua",1),("zhangsan",2),("lisi",3)]
d2=dict(d1)
print(d2)
d3=dict(red=1,green=2,blue=3)
print(d3)5.集合
集合(set)是Python中的数据结构之一,它与列表相似可以存储多个数据元素,不同之处在于集合由不同的元素组成,并且元素的存放是无序的。需要注意的是,集合中的元素不能是列表,集合,字典等可变对象。(其他的数据结构除了字符串外,均支持前台操作)我们的集合的创建形式和我们的字典很相似也是使用大括号进行创建。值得注意的是,由于集合不允许数据元素重复的特点我们可以使用集合进行数据的去重操作。在这里我们同样可以使用Python函数当中自带的一些函数功能进行集合元素的处理(求交集,并集,补集等)其中使用的代码主要如下:

在了解完Python语言当中的数据结构的使用方法之后,我们就可以对数据进行一些特殊的处理了,比如:单词的统计和单词的去重等处理。我们可以通过一些简单的案例来加深我们对这一部分知识的理解和使用。
综合案例:统计如下一段文章中每一个单词出现的次数。
At half past eight,Mr.Dursley picked up his briefcase,pecked Mrs.Dursley on the cheek,and tried to kiss Dudley good-bye but missed,because Dudley was now having a tantrum and throwing his cereal at the walls."Little tyke",chorrtled Mr.Dursley as he left a tantrum and throwing his cereal at the walls."Little tyke",chortled Mr.Dursley as he left the house.
对于上面的实验操作代码步骤如下:


import re
strings='''At half past eight,Mr.Dursley picked up his briefcase,
pecked Mrs.Dursley on the cheek,and tried to kiss Dudley
good-bye but missed,because Dudley was now having a tantrum
and throwing his cereal at the walls."Little tyke",chorrtled
Mr.Dursley as he left a tantrum and throwing his cereal at the
walls."Little tyke",chortled Mr.Dursley as he left the house.'''
strings=strings.lower() #将字符串中的大写字母全部转换成小写
strings=re.sub('[,.\'"-]',"",strings) #去除标点符号
words_list=strings.split() #文章中所有单词的列表
print("文章中单词总数:",len(words_list))
print(words_list)
words_set=set(words_list)
print("去除重复后单词的个数:",len(words_set))
print(words_set)
dic=dict()
for i in words_set:
dic[i]=words_list.count(i)
print("词频统计结果如下:")
print(dic)以上的程序中,主要按照如下步骤进行处理:
①把文章存储到字符串strings中
②调用lower()函数转换成小写
③用正则表达式的sub方法去除符号,正则表达式在re模块中,因此在程序第一行要导入re模块。正则表达式是一个特殊的字符序列,它能够方便地检查一个字符是否与某种模式匹配。
④利用split方法把字符串strings分割成一个个的单词,存储到列表words_set中
⑤利用集合set去除列表中的重复单词,得到一个单词的集合words_set
⑥利用for循环遍历单词集合words_set,利用文章单词列表words_list的count方法进行次数的统计,并把结果存到字典dict中,其中键是集合words_set中的单词,值是单词出现的次数,最后打印输出。
以上就是我们对于上面的案例的全部的步骤分析。那么我们本次的博客可以就到此结束了,感谢您的观看,再见。