10分钟带你学会python模块和包的使用
如果你用过 Python,那么你一定用过 import 关键字加载过各式各样的模块。但你是否熟悉 Python 中的模块与包的概念呢?或者,以下几个问题,你是否有明确的答案?
- 什么是模块?什么又是包?
- from matplotlib.ticker import FixedLocator, MultipleLocator 中的
matplotlib 和 ticker 分别是什么?中间的句点是什么意思? - from matplotlib.pyplot import * 中,import * 的背后会发生什么?
模块
为什么要有模块
在Python中,模块是一种组织代码的方式,它将相关的代码封装在一个单独的文件中。模块有助于代码的组织、重用和维护。
以下是一些关于为什么使用Python模块的主要原因:
- 1.代码组织和结构:模块允许你将代码划分为逻辑上相关的单元。每个模块通常都关注特定任务或功能,这使得代码更易于理解和维护。模块还有助于避免全局命名空间的污染,因为在一个模块中定义的变量和函数不会直接影响其他模块。
- 2.重用性:你可以在不同的项目中重用模块,这样可以减少代码的重复编写。Python标准库本身就是由大量的模块组成,它们提供了各种各样的功能,如文件操作、网络通信、数据结构等。
- 3.命名空间的隔离:每个模块都有自己的命名空间,这意味着在一个模块中定义的变量和函数名不会与其他模块发生冲突。这有助于避免命名冲突和提高代码的可维护性。
- 4.封装和抽象:模块提供了封装和抽象的机制。通过将代码放入模块中,你可以将实现细节隐藏起来,仅向外部提供必要的接口。这有助于降低代码的复杂性,同时提高代码的可读性。
- 5.代码的分层和组件化:模块使得代码的分层和组件化更容易实现。你可以将整个项目分解为多个模块,每个模块都负责特定的功能或层次。
- 6.测试和调试:模块化的代码更容易进行单元测试,因为你可以独立地测试每个模块。同时,当出现问题时,模块化的代码结构也更容易进行调试。 模块的识别
模块的识别
通常是通过文件系统和文件命名规则来完成的。以下是一些关于如何识别Python模块的主要方法:
- 1.文件扩展名:模块的源代码文件通常以.py为扩展名。例如,一个名为mymodule的模块的源代码文件可能是mymodule.py。
- 2.文件命名规则:Python模块的文件名应该符合标识符的命名规则。通常,模块的文件名应该是有效的标识符,避免使用特殊字符和关键字。如果文件名不符合标识符规则,导入模块时可能会导致语法错误。
- 3.包结构:如果模块是一个包(包含子模块的目录),则该目录中必须包含一个特殊的__init__.py文件。这个文件可以是空的,也可以包含包的初始化代码。
- 4.模块路径:解释器通过搜索模块路径来找到模块。模块路径包括当前工作目录、标准库目录以及其他用户定义的路径。当你导入一个模块时,解释器会按照一定的顺序搜索这些路径,找到匹配的模块文件。
- 5.导入语句:模块可以通过import语句被导入。例如,如果有一个名为mymodule的模块,你可以使用import mymodule语句导入它。导入语句将在模块路径中搜索指定的模块文件。
下面是一个简单的例子,展示了一个Python模块的基本结构和识别方法。假设有一个名为mymodule.py的模块:
%%writefile mymodule.py
def hello():
print("mymodule.version {}".format(version))
version = "1.0"
if __name__ == "__main__":
hello()
我们将其保存为 mymodule.py,解释器中 import 它。
import mymodule
dir(mymodule)
# 输出
# ['__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__spec__',
'hello',
'version']
# 调用模块函数和变量
mymodule.hello()
print(mymodule.version)
# 输出
mymodule.version 1.0
1.0
print(mymodule.__name__)
%run mymodule.py
# 输出
mymodule
mymodule.version 1.0
可以观察到,mymodule.py 在作为模块引入时,mymodule.__name__ 被设置为文件名 “mymodule”。但若在命令行直接执行 python mymodule.py,则 if 语句块会被执行,此时 __name__ 是 “__main__”。
模块的内部变量和初始化
Python 为每个模块维护了单独的符号表,因此可以实现类似 C++ 中名字空间(namespace)的功能。Python 模块中的函数,可以使用模块的内部变量,完成相关的初始化操作;同时,import 模块的时候,也不用担心这些模块内部变量与用户自定义的变量同名冲突。
import mymodule
version = "2.0"
print(version)
print(mymodule.version)
# 输出
2.0
1.0
值得一提的是,模块的初始化操作(这里指 version= "1.0" 这条语句),仅只在解释器第一次处理该模块的时候执行。也就是说,如果同一个模块被多次 import,它只会执行一次初始化。
from ... import ...
模块提供了类似名字空间的限制,不过 Python 也允许从模块中导入指定的符号(变量、函数、类等)到当前模块。导入后,这些符号就可以直接使用,而不需要前缀模块名。
from mymodule import hello, version
hello()
print(version)
# mymodule.version 1.0
# 1.0
值得一提的是,被导入的符号,如果引用了模块内部的变量,那么在导入之后也依然会使用模块内的变量,而不是当前环境中的同名变量。
from mymodule import hello, version
version = "2.0"
hello()
print(version)
# mymodule.version 1.0
# 2.0
也有更粗暴的方式,导入模块内的所有公开符号(没有前缀 _ 的那些)。不过,一般来说,除了实验、排查,不建议这样做。因为,通常你不知道模块定义了哪些符号、是否与当前环境有重名的符号。一旦有重名,那么,这样粗暴地导入模块内所有符号,就会覆盖掉当前环境的版本。从而造成难以排查的错误。
模块搜索路径
之前我们都在讨论模块的好处,但是忽略了一个问题:Python 怎样知道从何处找到模块文件?
如果你熟悉命令行,那么这个问题对你来说就不难理解。在命令行中执行的任何命令,实际上背后都对应了一个可执行文件。命令行解释器(比如 cmd, bash)会从一个全局的环境变量 PATH 中读取一个有序的列表。这个列表包含了一系列的路径,而命令行解释器,会依次在这些路径里,搜索需要的可执行文件。
Python 搜寻模块文件,也遵循了类似的思路。比如,用户在 Python 中尝试导入 import mymodule,那么
- 首先,Python 会在内建模块中搜寻 mymodule;
- 若未找到,则 Python 会在当前工作路径(当前脚本所在路径,或者执行 Python 解释器的路径)中搜寻 mymodule;
- 若仍未找到,则 Python 会在环境变量 PATH 中指示的路径中搜寻 mymodule;
- 若依旧未能找到,则 Python 会在安装时指定的路径中搜寻 mymodule;
- 若仍旧失败,则 Python 会报错,提示找不到 mymodule这个模块。
import mymodule1
ModuleNotFoundError Traceback (most recent call last)
Cell In[13], line 1
----> 1 import mymoudle1
ModuleNotFoundError: No module named 'mymoudle1'
pyc 文件
.pyc 文件是 Python 中的字节码文件,它们是 Python 解释器将源代码编译后存储的文件。当你运行一个 Python 脚本时,解释器会首先将源代码编译成字节码,然后执行这些字节码。
在 Python 中,当你导入一个模块时,解释器会检查是否存在对应的 .pyc 文件。如果存在,且时间戳比源文件更新,解释器就会加载这个 .pyc 文件,而不是重新编译源代码。这可以提高模块加载速度,因为字节码的加载比源代码的编译更快。
.pyc 文件的位置通常与源代码文件相同,并在需要时由解释器自动生成和更新。例如,如果你有一个名为 example.py 的 Python 脚本,当你第一次执行 example.py 时,Python 解释器会在同一目录下生成 example.pyc 文件。
这些 .pyc 文件与平台无关,并且可以在不同的 Python 解释器版本之间共享,因为它们只包含了字节码,而不涉及特定于平台的代码。
尽管 .pyc 文件可以加快模块加载速度,但它们不是必需的。如果没有 .pyc 文件,Python 解释器将仍然能够执行源代码,只是加载模块时会重新生成新的 .pyc 文件。
值得注意的是,.pyc 文件不包含你源代码的原始文本,因此不能直接从中反推出完整的源代码内容。
包
在 Python 中,一个包(Package)是一个包含多个模块的命名空间,用于组织和管理相关的模块。包实际上是一个包含了特殊的 init.py 文件的目录。这个 init.py 文件可以为空,也可以包含包的初始化代码或设置。通过使用包,你可以将相关的模块组织在一起,使得代码更加结构化和易于维护。
科学计算领域,SciPy, NumPy, Matplotlib 等第三方工具,都是用包的形式发布的。
目录结构
Python 要求每一个「包」目录下,都必须有一个名为 __init__.py 的文件。从这个文件的名字上看,首先它有 __ 作为前后缀,我们就知道,这个文件肯定是 Python 内部用来做某种识别用的;其次,它有 init,我们知道它一定和初始化有关;最后,它有 .py 作为后缀名,因此它也是一个 Python 模块,可以完成一些特定的工作。
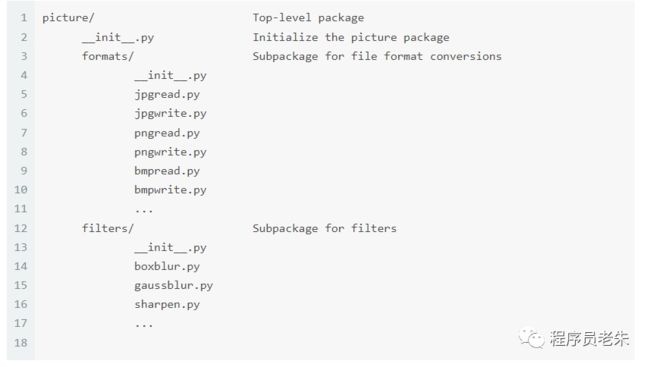
此处 picture 目录下有 __init__.py,因此 Python 会将其作为一个 Python 包;类似地,子目录 formats 和 filters 就成了 picture 下的子包。这里,子包的划分以功能为准。formats 下的模块,设计用于处理不同格式的图片文件的读写;而 filters 下的模块,则被设计用于实现各种滤镜效果。
使用 Python 包
Python 包的使用和模块的使用类似,是很自然的方式。以我们的 picture 包为例,若你想使用其中具体的模块,可以这样做。
import picutre.filters.gaussblur
如此,你就导入了picture包中 filters 子包中的 gaussblur 模块,你就能使用高斯模糊模块提供的功能了。具体使用方式,和使用模块也保持一致。
picture.filters.gaussblur.gaussblur_filter(input, output)
这看起来很繁琐,因此你可能会喜欢用 from ... import ... 语句,跳过过多的名字限制。
from picture.filters import gaussblur
这样一来,你就可以直接按如下方式使用高斯模糊这一滤镜了。
gaussblur.gaussblur_filter(input, output)
init.py文件
为什么要设计 __init__.py,而不是自动地把任何一个目录都当成是 Python 包?
这主要是为了防止重名造成的问题。比如,很可能用户在目录下新建了一个子目录,名为 collections;但 Python 有内建的同名模块。若不加任何限制地,将子目录当做是 Python 包,那么,import collections 就会引入这个 Python 包。而这样的行为,可能不是用户预期的。从这个意义上说,设计 __init__.py 是一种保护措施。
接下来的问题是,__init__.py 具体还有什么用?
首先来说,__init__.py 可以执行一些初始化的操作。这是因为,__init__.py 作为模块文件,会在相应的 Python 包被引入时首先引入。这就是说,import picture 相当于是 import picture.__init__。因此,__init__.py 中可以保留一些初始化的代码。比如:引入依赖的其他 Python 模块。
前面没有有介绍对 Python 包的 from picture import * 的用法。这是因为,从一个包中导入所有内容,这一行为是不明确的;必须要由包的开发者指定。我们可以在 __init__.py 中定义名为 __all__ 的 Python 列表。这样一来,就能使用 from picture import * 了。
具体来说,我们可以在 picture/__init__.py 中做如下定义。
# __init__.py
import collections # import the built-in package
__all__ = ["formats", "filters"]
此时,若我们在用户模块中 from picture import *,则首先会引入 Python 内建的 collections 模块,而后引入 picture.formats 和picture.filters这两个 Python 子包了。
在包内使用相对层级引用其他模块
在引入 Python 包中的模块时,我们用句点 . 代替了斜线(或者反斜线)来标记路径的层级(实际上是包和模块的层级)。
在 Python 包的内部,我们也可以使用类似相对路径的方式,使用相对层级来简化包内模块的互相引用。
比如,在 gaussblur.py 中,你可以通过以下四种方式,引入 boxblur.py,而它们的效果是一样的。
# gaussblur.py
import boxblur
from . import boxblur
from ..filters import boxblur
from .. import filters.boxblur as boxblur
