LangChain学习指南(一)——Model IO
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、Langchain是什么?
- 二、官方文档Langchain这么长,我怎么看?
- 三、Model IO
-
- 2.1.1prompt
- 2.1.2LLM
- 2.1.3 OutputParsers
前言
本文为笔者学习LangChain时对官方文档文档以及一系列资料进行一些总结~会针对langchain的六大模块进行持续更新,欢迎交流。
一、Langchain是什么?
如今各类ai模型层出不穷,百花齐放,大佬们开发的速度永远遥遥领先于学习者的学习速度。。为了解放生产力,不让应用层开发人员受限于各语言模型的生产部署中…LangChain横空出世界。
Langchain可以说是现阶段必须要学习的一个架构,那么究竟它有什么魔法才会配享如此高的地位呢?会不会学习成本很高?不要担心!Langchain虽然地位很高,但其实它就是一个为了提升构建LLM相关应用效率的一个工具,我们也可以将它理解成一个“说明书",是的,只是一个“说明书”!它标准的定义了我们在构建一个LLM应用开发时可能会用到的东西。比如说在之前写过的AI文章中介绍的prompt,就可以通过Langchain中的PromptTemplate进行格式化:
prompt = """Translate the text \
that is delimited by triple backticks \
into a style that is {style}. \
text: ```{text}```
"""
当我们调用ChatPromptTemplate进行标准化时,该prompt就会被格式化成:
from langchain.prompts import ChatPromptTemplate
prompt_template=ChatPromptTemplate.from_template(prompt)
print(prompt_template,'ChatPromptTemplate')
#输出结果
input_variables=[‘style’, ‘text’]
messages=[HumanMessagePromptTemplate(
prompt=PromptTemplate(input_variables=[‘style’, ‘text’],
template=‘Translate the text that is delimited by triple backticks into a style that is {style}. text: {text}\n’))]
可以看到ChatPromptTemplate可以将prompt中声明的输入变量准确提取出来,使prompt更清晰。当然,Langchain对于propmpt的优化不止这一种方式,它还提供了各类其他接口将prompt进一步优化,这里只是举例一个较为基础且直观的方法,让大家感受一下。
Langchain其实就是在定义多个通用类的规范去优化开发AI应用过程中可能用到的各类技术,将它们抽象成多个小元素,当我们构建应用时,直接将这些元素堆积起来无需在重复的去研究各"元素"实现的细枝末节。
二、官方文档Langchain这么长,我怎么看?
毋庸置疑的是想要学习Langchain最简单直接的方法就是阅读官方文档,先贴一个链接 官方文档
通过文档目录可以看到,Langchain由6个module组成,分别是Model IO、Retrieval、Chains、Memory、Agents和Callbacks。
Model IO:即AI应用的核心部分,其中包括输入、Model和输出。
Retrieval:检索是与向量数据库相关的,其实就是在向量数据库中搜索与问题相关的文档内容。
Memory:用来为对话形式的model存储历史对话记录,再长对话过程中随时将这些历史对话记录重新加载以保证对话的精确度。
Chains:虽然通过Model IO、Retrieval和Memory这三大模块已经可以初步完成应用搭建,但是仍具有很多的局限性,这时就可以利用chains将其连接起来丰富功能。
Agents:它可以通过用户的输入,理解用户的意图,返回一个特定的动作类型和参数,从而自主调用相关的工具来满足用户的需求。将应用更加智能化。
Callbacks: 回调机制可以调用链路追踪,记录日志,帮助开发者更好的调试LLM模型。
六个module具体的关系如下图所示(图片来源于网络):
好了,说到这我们只要一个一个module去攻破,最后将他们融会贯通,也就成为一名及格的Langchain学习者了。
三、Model IO
这一部分是langchain的核心部分,引用一下之前介绍AI时用过的图(感兴趣的可以移步去看一下 https://km.woa.com/articles/show/586609 介绍了model的一些具体实现)
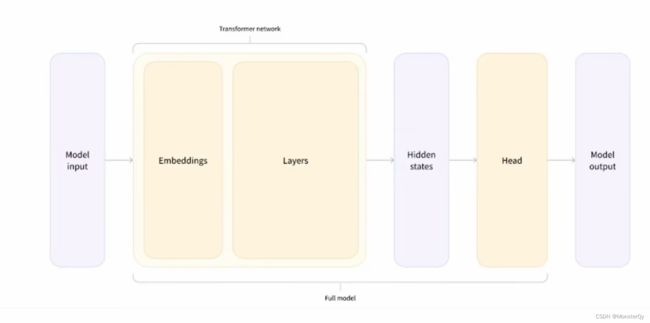
可以看出我们在利用Model IO的时候主要关注的就是输入、处理、输出。Langchain也是根据这一点去划分Model IO这一模块的,在这一模块中,Langchain主要关注的就是Prompt(输入)、Language model(处理)、Output Pasers(输出),Langchain通过一系列的技术手法优化这三步,使得其更加的标准化,我们也无需再关注每一步骤中的具体实现,可以直接通过Langchain提供的库,堆积木式的完善我们应用构建。(贴张官方文档的图,可以更清晰的了解)在这一小节,将主要介绍langchain中常用的一些prompt构建方法。

2.1.1prompt
在 https://km.woa.com/articles/show/588368 中介绍过prompt对于开发llm应用的重要性,Langchain对于其优化主要是致力于将其优化成为可移植性高的prompt,以便更好的支持各类LLM,无需在切换model时修改prompt。 通过官方文档可以看到,propmpt在langchain被分成了两大类一是prompt template另一类则是selectors,首先是propmpt template,这个其实很好理解就是利用langchain接口将prompt按照template进行一定格式化,针对prompt进行变量处理以及提示词的组合。selectors则是指可以根据不同的条件去选择不同的提示词,或者在不同的情况下通过selector选择不同的example去进一步提高prompt支持能力。
1.模版格式:
在prompt中有两种类型的模版格式,一是f-string,这是十分常见的一类prompt,二是jinja2。
f-string 是 Python 3.6 以后版本中引入的一种特性,用于在字符串中插入表达式的值。语法简洁,直接利用{}花括号包裹变量或者表达式,即可执行简单的运算,性能较好,但是只限用在py中。
#使用 Python f 字符串模板:
from langchain.prompts import PromptTemplate
fstring_template = """Tell me a {adjective} joke about {content}"""
prompt = PromptTemplate.from_template(fstring_template)
print(prompt.format(adjective="funny", content="chickens"))
# Output: Tell me a funny joke about chickens.
jinja2常被应用于网页开发,与 Flask 和 Django 等框架结合使用。它不仅支持变量替换,还支持其他的控制结构(例如循环和条件语句)以及自定义过滤器和宏等高级功能。此外,它的可用性范围更广,可在多种语境下使用。但与 f-string 不同,使用 jinja2 需要安装相应的库。
#使用 jinja2 模板:
from langchain.prompts import PromptTemplate
jinja2_template = "Tell me a {{ adjective }} joke about {{ content }}"
prompt = PromptTemplate.from_template(jinja2_template, template_format="jinja2")
print(prompt.format(adjective="funny", content="chickens"))
# Output: Tell me a funny joke about chickens.
总结一下,如果只需要基本的字符串插值和格式化,首选f-string ,因为它的语法简洁且无需额外依赖。但如果需要更复杂的模板功能(例如循环、条件、自定义过滤器等),jinja2 更合适。
2.Propmpt Template:
在prompt template中比较核心需要掌握的几个概念:
1.基本提示模版:大多是字符串或者是由对话组成的数组对象。 对于创建字符串类型的prompt要了解两个概念,一是input_variables 属性,它表示的是prompt所需要输入的变量。二是format,即通过input_variables将prompt格式化。比如利用PromptTemplate进行格式化。
from langchain.prompts import PromptTemplate #用于 PromptTemplate 为字符串提示创建模板。
#默认情况下, PromptTemplate 使用 Python 的 str.format 语法进行模板化;但是可以使用其他模板语法(例如, jinja2 )
prompt_template = PromptTemplate.from_template("Tell me a {adjective} joke about {content}.")
print(prompt_template.format(adjective="funny", content="chickens"))
上述例子就是将两个input_variables分别设置为funny和chickens,然后利用format分别进行赋值。若在template中声明了input_variables,利用format进行格式化时就一定要赋值否则会报错,当在template中未设置input_variables,则会自动忽略。当对对话类型的prompt进行format的时候,可以利用ChatPromptTemplate进行:
#ChatPromptTemplate.from_messages 接受各种消息表示形式。
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?"
)
print(messages)
可以看到,ChatPromptTemplate会根据role,对每一句进行标准格式化。除了此类方法,也可以直接指定身份模块如SystemMessage, HumanMessagePromptTemplate进行格式化,这里不再赘述。
2.部分提示词模版:在生成prompt前就已经提前初始化部分的提示词,实际进一步导入模版的时候只导入除已初始化的变量即可。通常部分提示词模版会被用在全局设置上,如下示例,在正式format前设定foo值为foo,这样在生成最终prompt的时候只需要指定bar的值即可。有两种方法去指定部分提示词:
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(template="{foo}{bar}", input_variables=["foo", "bar"])
# 您可以使用 PromptTemplate.partial() 方法创建部分提示模板。
partial_prompt = prompt.partial(foo="foo")
print(partial_prompt.format(bar="baz"))
#您也可以只使用分部变量初始化提示。
prompt = PromptTemplate(template="{foo}{bar}", input_variables=["bar"], partial_variables={"foo": "foo"})
print(prompt.format(bar="baz"))
此外,我们也可以将函数的最终值作为prompt的一部分进行返回,如下例子,如果想在prompt中实时展示当下时间,我们可以直接声明一个函数用来返回当下时间,并最终将该函数拼接到prompt中去:
from datetime import datetime
def _get_datetime():
now = datetime.now()
return now.strftime("%m/%d/%Y, %H:%M:%S")
prompt = PromptTemplate(
template="Tell me a {adjective} joke about the day {date}",
input_variables=["adjective", "date"]
)
partial_prompt = prompt.partial(date=_get_datetime)
print(partial_prompt.format(adjective="funny"))
# 除上述方法,部分函数声明和普通的prompt一样,也可以直接用partial_variables去声明
prompt = PromptTemplate(
template="Tell me a {adjective} joke about the day {date}",
input_variables=["adjective"],
partial_variables={"date": _get_datetime})
3.组成提示词模版:可以通过PromptTemplate.compose()方法将多个提示词组合到一起。如下示例,生成了full_prompt和introduction_prompt进行进一步组合。
from langchain.prompts.pipeline import PipelinePromptTemplate
from langchain.prompts.prompt import PromptTemplate
full_template = """{introduction}
{example}
"""
full_prompt = PromptTemplate.from_template(full_template)
introduction_template = """You are impersonating Elon Musk."""
introduction_prompt = PromptTemplate.from_template(introduction_template)
example_template = """Here's an example of an interaction """
example_prompt = PromptTemplate.from_template(example_template)
input_prompts = [("introduction", introduction_prompt),
("example", example_prompt),]
pipeline_prompt = PipelinePromptTemplate(final_prompt=full_prompt, pipeline_prompts=input_prompts)
4.自定义提示模版:在创建prompt时,我们也可以按照自己的需求去创建自定义的提示模版。官方文档举了一个生成给定名称的函数的英语解释的例子,在这个例子中函数名称作为输入,并设置提示格式以提供函数的源代码:
import inspect
#该函数将返回给定其名称的函数的源代码。 inspect作用就是获取源代码
def get_source_code(function_name):
# Get the source code of the function
return inspect.getsource(function_name)
#测试函数
def test():
return 1 + 1
from langchain.prompts import StringPromptTemplate
from pydantic import BaseModel, validator
#初始化字符串prompt
PROMPT = """\
提供一个函数名和源代码并给出函数的相应解释
函数名: {function_name}
源代码:
{source_code}
解释:
"""
class FunctionExplainerPromptTemplate(StringPromptTemplate, BaseModel):
"""一个自定义提示模板,以函数名作为输入,并格式化提示模板以提供函数的源代码。 """
@validator("input_variables")
def validate_input_variables(cls, v):
"""验证输入变量是否正确。"""
if len(v) != 1 or "function_name" not in v:
raise ValueError("函数名必须是唯一的输入变量。")
return v
def format(self, **kwargs) -> str:
# 获取源代码
source_code = get_source_code(kwargs["function_name"])
# 源代码+名字提供给prompt
prompt = PROMPT.format(
function_name=kwargs["function_name"].__name__, source_code=source_code)
return prompt
def _prompt_type(self):
return "function-explainer"
FunctionExplainerPromptTemplate接收两个变量一个是prompt,另一个则是传入需要用到的model,该class下面的validate_input_variables用来验证输入量,format函数用来输出格式化后的prompt
#初始化prompt实例
fn_explainer = FunctionExplainerPromptTemplate(input_variables=["function_name"])
# Generate a prompt for the function "test_add"
prompt_1 = fn_explainer.format(function_name=test_add)
print(prompt_1)
输出结果:

5.少量提示模版:在构建prompt时,可以通过构建一个少量示例列表去进一步格式化prompt,每一个示例表都的结构都为字典,其中键是输入变量,值是输入变量的值。该过程通常先利用PromptTemplate将示例格式化成为字符串,然后创建一个FewShotPromptTemplate对象,用来接收few-shot的示例。官方文档中举例:
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
examples = [
{"question": "Who lived longer, Muhammad Ali or Alan Turing?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
"""},
{"question": "When was the founder of craigslist born?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the founder of craigslist?
Intermediate answer: Craigslist was founded by Craig Newmark.
Follow up: When was Craig Newmark born?
Intermediate answer: Craig Newmark was born on December 6, 1952.
So the final answer is: December 6, 1952
"""},
{"question": "Who was the maternal grandfather of George Washington?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who was the mother of George Washington?
Intermediate answer: The mother of George Washington was Mary Ball Washington.
Follow up: Who was the father of Mary Ball Washington?
Intermediate answer: The father of Mary Ball Washington was Joseph Ball.
So the final answer is: Joseph Ball
"""},
{"question": "Are both the directors of Jaws and Casino Royale from the same country?",
"answer":
"""
Are follow up questions needed here: Yes.
Follow up: Who is the director of Jaws?
Intermediate Answer: The director of Jaws is Steven Spielberg.
Follow up: Where is Steven Spielberg from?
Intermediate Answer: The United States.
Follow up: Who is the director of Casino Royale?
Intermediate Answer: The director of Casino Royale is Martin Campbell.
Follow up: Where is Martin Campbell from?
Intermediate Answer: New Zealand.
So the final answer is: No
"""}]
#配置一个格式化程序,该格式化程序将prompt格式化为字符串。此格式化程序应该是一个 PromptTemplate 对象。
example_prompt = PromptTemplate(input_variables=["question", "answer"], template="Question: {question}\n{answer}")
print(example_prompt.format(**examples[0]))
#最后用FewShotPromptTemplate 来创建一个提示词模板,该模板将输入变量作为输入,并将其格式化为包含示例的提示词。
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Question: {input}",
input_variables=["input"]
)
print(prompt)#此时会返回所有prompt
除了上述普通的字符串模版,聊天模版中也可以采用此类方式构建一个带例子的聊天提示词模版:
#这是一个聊天提示词模板,它将输入变量作为输入,并将其格式化为包含示例的提示词。
examples = [{"input": "2+2", "output": "4"},{"input": "2+3", "output": "5"},]
# 提示词模板,用于格式化每个单独的示例。
example_prompt = ChatPromptTemplate.from_messages(
[("human", "{input}"),
("ai", "{output}"),])
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples)
print(few_shot_prompt.format())

6.独立化prompt:为了便于共享、存储和加强对prompt的版本控制,可以将想要设定prompt所支持的格式保存为JSON或者YAML格式文件。也可以直接将待格式化的prompt单独存储于一个文件中,通过格式化文件指定相应路径,以更方便用户加载任何类型的提示信息。
创建json文件:
{
"_type": "prompt",
"input_variables": ["adjective", "content"],
"template": "Tell me a {adjective} joke about {content}."
}
主文件代码:
from langchain.prompts import load_prompt
prompt = load_prompt("./simple_prompt.json")
print(prompt.format(adjective="funny", content="chickens"))
输出结果:
Tell me a funny joke about chickens.
这里是直接在json文件中指定template语句,除此之外也可以将template单独抽离出来,然后在json文件中指定template语句所在的文件路径,以实现更好的区域化,方便管理prompt。
创建json文件:
{
"_type": "prompt",
"input_variables": ["adjective", "content"],
"template_path": "./simple_template.txt"
}
simple_template.txt:
Tell me a {adjective} joke about {content}.
其余部分代码同第一部分介绍,最后的输出结果也是一致的。
3.selector:
在few shot模块,当我们列举一系列示例值,但不进一步指定返回值,就会返回所有的prompt示例,在实际开发中我们可以使用自定义选择器来选择例子。例如,想要返回一个和新输入的内容最为近似的prompt, 这时候就可以选用去选择与输入最为相似的例子。这里的底层逻辑是利用了SemanticSimilarityExampleSelector这个例子选择器和向量相似度的计算(openAIEmbeddings)以及利用chroma进行数据存储,代码如下:
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
example_selector = SemanticSimilarityExampleSelector.from_examples(
#可选的示例列表。
examples,
#用于生成嵌入的嵌入类,这些嵌入用于测量语义相似性。
OpenAIEmbeddings(),
#用于存储嵌入并进行相似性搜索的 VectorStore 类。
Chroma,
#要生成的示例数。
k=1)
然后我们去输入一条想要构建的prompt,遍历整个示例列表,找到最为合适的example。
#选择与输入最相似的示例。
question = "Who was the father of Mary Ball Washington?"
selected_examples = example_selector.select_examples({"question": question})
print(f"Examples most similar to the input: {question}")
for example in selected_examples:
print("\n")
for k, v in example.items():
print(f"{k}: {v}")

此时就可以返回一个最相似的例子。接下来我们可以重新重复few shot的步骤 利用FewShotPromptTemplate去创建一个提示词模版。
对于聊天类型的few shot的prompt我们也可以采用例子选择器进行格式化:
examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
{"input": "2+4", "output": "6"},
{"input": "What did the cow say to the moon?", "output": "nothing at all"},
{
"input": "Write me a poem about the moon",
"output": "One for the moon, and one for me, who are we to talk about the moon?",
},
]
#由于我们使用向量存储来根据语义相似性选择示例,因此我们需要首先填充存储。
to_vectorize = [" ".join(example.values()) for example in examples]
这里就单纯理解为将value对应的值提取出来进行格式化即可。
#创建向量库后,可以创建 example_selector 以表示返回的相似向量的个数
example_selector = SemanticSimilarityExampleSelector(vectorstore=vectorstore,k=2)
# 提示词模板将通过将输入传递给 `select_examples` 方法来加载示例
example_selector.select_examples({"input": "horse"})
此时就可以返回两个个最相似的例子。接下来我们可以重复few shot的步骤 利用FewShotChatPromptTemplate去创建一个提示词模版。
上文中介绍了在利用Langchain进行应用开发时所常用的构建prompt方式,无论哪种方式其最终目的都是为了更方便的去构建prompt,并尽可能的增加其复用性。Langchain提供的prompt相关工具远不止上文这些,在了解了基础能力后可以进一步查阅官方文档找到最适合项目特点的工具,进行prompt格式化。
2.1.2LLM
上除了上文中的prompt,LLM作为langchain中的核心内容,也是我们需要花心思去了解学习的,不过还是那句话,应用层的开发实际上无需到模型底层原理了解的十分透彻,我们更应该关注的是llm的调用形式,Langchain作为一个“工具”它并没有提供自己的LLM,而是提供了一个接口,用于与许多不同类型的LLM进行交互,比如耳熟能详的openai、hugging face或者是cohere等,都可以通过langchain快速调用。
1.单个调用:直接调用Model对象,传入一串字符串然后直接返回输出值,以openAI为例:
from langchain.llms import OpenAI
llm = OpenAI()
print(llm('你是谁'))
2.批量调用:通过generate可以对字符串列表,进行批量应用Model,使输出更加丰富且完整。
llm_result = llm.generate(["给我背诵一首古诗", "给我讲个100字小故事"]*10)
这时的llm_result会生成一个键为generations的数组,这个数组长度为20项,第一项为古诗、第二项为故事、第三项又为古诗,以此规则排列…
3.异步接口:asyncio库为LLM提供异步支持,目前支持的LLM为OpenAI、PromptLayerOpenAI、ChatOpenAI 、Anthropic 和 Cohere 受支持。 可以使用agenerate 异步调用 OpenAI LLM。 在代码编写中,如果用了科学上网/魔法,以openAI为例,在异步调用之前,则需要预先将openai的proxy设置成为本地代理(这步很重要,若不设置后续会有报错)
import openai
openai.proxy = os.getenv('https_proxy')
# 异步举例
import asyncio # 用于处理异步编程
from langchain.llms import OpenAI # 从langchain.llms库导入OpenAI类
# 定义一个同步方式生成文本的函数
def generate_serially():
llm = OpenAI(temperature=0.9) # 创建OpenAI对象,并设置temperature参数为0.9
for _ in range(10): # 循环10次
resp = llm.generate(["Hello, how are you?"]) # 调用generate方法生成文本
print(resp.generations[0][0].text) # 打印生成的文本
# 定义一个异步生成文本的函数
async def async_generate(llm):
resp = await llm.agenerate(["Hello, how are you?"]) # 异步调用agenerate方法生成文本
print(resp.generations[0][0].text) # 打印生成的文本
# 定义一个并发(异步)方式生成文本的函数
async def generate_concurrently():
llm = OpenAI(temperature=0.9) # 创建OpenAI对象,并设置temperature参数为0.9
tasks = [async_generate(llm) for _ in range(10)] # 创建10个异步任务
await asyncio.gather(*tasks) # 使用asyncio.gather等待所有异步任务完成
可以用time库去检查运行时间,利用同步调用耗时大概为12s,异步耗时仅有2s。通过这种方式可以大大提速任务执行。
4.自定义大语言模型:在开发过程中如果遇到需要调用不同的LLM时,可以通过自定义LLM实现效率的提高。自定义LLM时,必须要实现的是_call方法,通过这个方法接受一个字符串、一些可选的索引字,并最终返回一个字符串。除了该方法之外,还可以选择性生成一些方法用于以字典的模式返回该自定义LLM类的各属性
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain.llms.base import LLM
#有两个装饰方法, _llm_type 和 _identifying_params,这两个方法都返回一些固定的属性值。
#_call 方法主要是对输入的 prompt 字符串进行处理,返回前 n 个字符。如果提供了 stop 参数,它将引发一个异常。
class CustomLLM(LLM):#这个类 CustomLLM 继承了 LLM 类,并增加了一个新的类变量 n。
n: int # 类变量,表示一个整数
@property
def _llm_type(self) -> str:
return "custom"
def _call(
self,
prompt: str, # 输入的提示字符串
stop: Optional[List[str]] = None, # 可选的停止字符串列表,默认为 None
run_manager: Optional[CallbackManagerForLLMRun] = None, # 可选的回调管理器,默认为 None
**kwargs: Any,
) -> str:
# 如果 stop 参数不为 None,则抛出 ValueError 异常
if stop is not None:
raise ValueError("stop kwargs are not permitted.")
return prompt[: self.n]# 返回 prompt 字符串的前 n 个字符
@property # 一个属性装饰器,用于获取 _identifying_params 的值
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters.""" # 这个方法的文档字符串,说明这个方法的功能是获取标识参数
return {"n": self.n} # 返回一个字典,包含 n 的值
5.测试大语言模型:为了节省我们的成本,当写好一串代码进行测试的时候,通常情况下我们是不希望去真正调用LLM,因为这会消耗token(打工人表示伤不起),贴心的Langchain则提供给我们一个“假的”大语言模型,以方便我们进行测试。
# 从langchain.llms.fake模块导入FakeListLLM类,此类可能用于模拟或伪造某种行为
from langchain.llms.fake import FakeListLLM
from langchain.agents import load_tools#py运行器
from langchain.agents import initialize_agent#初始化代理
from langchain.agents import AgentType#
# 调用load_tools函数,加载"python_repl"的工具
tools = load_tools(["python_repl"])
# 定义一个响应列表,这些响应可能是模拟LLM的预期响应
responses = ["Action: Python REPL\nAction Input: print(2 + 2)", "Final Answer: 4"]
# 使用上面定义的responses初始化一个FakeListLLM对象
llm = FakeListLLM(responses=responses)
# 调用initialize_agent函数,使用上面的tools和llm,以及指定的代理类型和verbose参数来初始化一个代理
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
# 调用代理的run方法,传递字符串"whats 2 + 2"作为输入,询问代理2加2的结果
agent.run("whats 2 + 2")
与模拟llm同理,langchain也提供了一个伪类去模拟人类回复,该功能依赖于wikipedia,所以模拟前需要install一下这个库,并且需要设置proxy。这里同fakellm需要依赖agent的三个类,此外它还依赖下面的库:
# 从langchain.llms.human模块导入HumanInputLLM类,此类可能允许人类输入或交互来模拟LLM的行为
from langchain.llms.human import HumanInputLLM
# 调用load_tools函数,加载名为"wikipedia"的工具
tools = load_tools(["wikipedia"])
# 初始化一个HumanInputLLM对象,其中prompt_func是一个函数,用于打印提示信息
llm = HumanInputLLM(
prompt_func=lambda prompt: print(f"\n===PROMPT====\n{prompt}\n=====END OF PROMPT======"))
# 调用initialize_agent函数,使用上面的tools和llm,以及指定的代理类型和verbose参数来初始化一个代理
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
# 调用代理的run方法,传递字符串"What is 'Bocchi the Rock!'?"作为输入,询问代理关于'Bocchi the Rock!'的信息
agent.run("What is 'Bocchi the Rock!'?")
6.缓存大语言模型:和测试大语言模型一样目的的是缓存大语言模型,通过缓存层可以尽可能的减少API的调用次数,从而节省费用。在Langchain中设置缓存分为两种情况一是在内存中二是在数据中缓存。存储在内存中加载速度较快,但是占用资源并且在关机之后将不再被缓存,在内存中设置缓存示例如下:
#在内存缓存中
import langchain
from langchain.llms import OpenAI
import time
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2)
from langchain.cache import InMemoryCache
langchain.llm_cache = InMemoryCache() # 缓存放在内存里
start_time = time.time() # 记录开始时间
print(llm.predict("Tell me a joke"))
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start_time # 计算总时间
print(f"Predict method took {elapsed_time:.4f} seconds to execute.")
这里的时间大概花费1s+ ,因为被问题放在了内存里,所以在下次调用时几乎不会再耗费时间。
除了存储在内存中进行缓存也可以存储在数据库中进行缓存,当开发企业级应用的时候通常都会选择存储在数据库中,不过这种方式的加载速度相较于将缓存存储在内存中更慢一些,不过好处是不占电脑资源并且存储记录并不会随着关机消失。
# 使用SQLite数据库缓存
from langchain.cache import SQLiteCache
langchain.llm_cache = SQLiteCache(database_path=".langchain.db")
start_time = time.time() # 记录开始时间
print(llm.predict("用中文讲个笑话"))
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start_time # 计算总时间
print(f"Predict method took {elapsed_time:.4f} seconds to execute.")
7.跟踪token使用情况(仅限model为openAI):
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
llm = OpenAI(model_name="text-davinci-002", n=2, best_of=2,cache = None)
with get_openai_callback() as cb:
result = llm("讲个笑话")
print(cb)
上述代码直接利用get_openai_callback即可完成对于单条的提问时token的记录,此外对于有多个步骤的链或者agent,langchain也可以追踪到各步骤所耗费的token。
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
tools = load_tools(["llm-math"], llm=llm)
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
with get_openai_callback() as cb:
response = agent.run(
"王菲现在的年龄是多少?"
)
print(f"Total Tokens: {cb.total_tokens}")
print(f"Prompt Tokens: {cb.prompt_tokens}")
print(f"Completion Tokens: {cb.completion_tokens}")
print(f"Total Cost (USD): ${cb.total_cost}")
8.序列化配置大语言模型:Langchain也提供一种能力用来保存LLM在训练时使用的各类系数,比如template、 model_name等系数。这类系数通常会被保存在json或者yaml文件中,以json文件为例,配置如下系数,然后利用load_llm方法即可导入:
from langchain.llms.loading import load_llm
llm = load_llm("llm.json")
{"model_name": "text-davinci-003",
"temperature": 0.7,
"max_tokens": 256,
"top_p": 1.0,
"frequency_penalty": 0.0,
"presence_penalty": 0.0,
"n": 1,
"best_of": 1,
"request_timeout": null,
"_type": "openai"}
亦或者在配置好大模型参数之后,直接利用save方法即可直接保存配置到指定文件中。
llm.save("llmsave.json")
9.流式处理大语言模型的响应:流式处理意味着,在接收到第一个数据块后就立即开始处理,而不需要等待整个数据包传输完毕。这种概念应用在LLM中则可达到生成响应时就立刻向用户展示此下的响应,或者在生成响应时处理响应,也就是我们现在看到的和ai对话时逐字输出的效果:可以看到实现还是较为方便的只需要直接调用StreamingStdOutCallbackHandler作为callback即可。
from langchain.llms import OpenAI
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
llm = OpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], temperature=0)
resp = llm("Write me a song about sparkling water.")
可以看到实现还是较为方便的只需要直接调用StreamingStdOutCallbackHandler作为callback即可。
2.1.3 OutputParsers
model返回的内容通常都是字符串的模式,但是在实际开发过程中,我们往往希望model可以返回更直观的内容,这Langchain提供的输出解析器则将派上用场,在实现一个输出解析器的过程中,我们必须实现两种方法:
“获取格式指令”:返回一个字符串的方法,其中包含有关如何格式化语言模型输出的说明。
“Parse”:一种接收字符串(假设是来自语言模型的响应)并将其解析为某种结构的方法。
“Parse with prompt”:一种方法,它接受一个字符串(假设是来自语言模型的响应)和一个提示(假设是生成此类响应的提示)并将其解析为某种结构。提示主要在 OutputParser 想要以某种方式重试或修复输出时提供,并且需要来自提示的信息才能执行此操作。
1.列表解析器:利用此解析器可以输出一个用逗号分割的列表。
# 导入必要的模块和类
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
# 初始化一个解析由逗号分隔的列表的解析器
output_parser = CommaSeparatedListOutputParser()
# 获取解析器的格式指令
format_instructions = output_parser.get_format_instructions()
# 定义提示模板,用于生成关于特定主题的由逗号分隔的列表
prompt = PromptTemplate(
template="List five {subject}.\n{format_instructions}",
input_variables=["subject"],
partial_variables={"format_instructions": format_instructions})
# 初始化OpenAI模型
model = OpenAI(temperature=0)
# 格式化提示,这里的主题是“ice cream flavors”(冰淇淋口味)
_input = prompt.format(subject="冰淇淋口味")
# 使用模型生成输出
output = model(_input)
# 使用解析器解析输出
output_parser.parse(output)
2.日期解析器:利用此解析器可以直接将LLM输出解析为日期时间格式
# 导入必要的模块和类
from langchain.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
from langchain.chains import LLMChain
from langchain.llms import OpenAI
# 初始化一个日期时间输出解析器
output_parser = DatetimeOutputParser()
# 定义提示模板,用于引导模型回答用户的问题
template = """回答用户的问题:
{question}
{format_instructions}"""
# 使用模板创建一个提示实例
prompt = PromptTemplate.from_template(template,partial_variables={"format_instructions": output_parser.get_format_instructions()},)
# 初始化一个LLMChain,它结合了提示和OpenAI模型来生成输出
chain = LLMChain(prompt=prompt, llm=OpenAI())
# 运行链来获取关于特定问题的答案,这里的问题是“bitcoin是什么时候成立的?”
output = chain.run("bitcoin是什么时候成立的?用英文格式输出时间")
3.枚举解析器
from langchain.output_parsers.enum import EnumOutputParser
from enum import Enum
class Colors(Enum):
RED = "red"
GREEN = "green"
BLUE = "blue"
parser = EnumOutputParser(enum=Colors)
4.自动修复解析器:这类解析器是一种嵌套的形式,如果第一个输出解析器出现错误,就会直接调用另一个一修复错误
# 导入所需的库和模块
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field, validator
from typing import List
# 定义一个表示演员的数据结构,包括他们的名字和他们出演的电影列表
class Actor(BaseModel):
name: str = Field(description="name of an actor") # 演员的名字
film_names: List[str] = Field(description="list of names of films they starred in") # 他们出演的电影列表
# 定义一个查询,用于提示生成随机演员的电影作品列表
actor_query = "Generate the filmography for a random actor."
# 使用`Actor`模型初始化解析器
parser = PydanticOutputParser(pydantic_object=Actor)
# 定义一个格式错误的字符串数据
misformatted = "{'name': 'Tom Hanks', 'film_names': ['Forrest Gump']}"
# 使用解析器尝试解析上述数据
parser.parse(misformatted)
格式错误的原因是因为json文件需要双引号进行标记,但是这里用了单引号,此时利用该解析器进行解析就会出现报错,但是此时可以利用RetryWithErrorOutputParser进行修复错误,则会正常输出不报错。
from langchain.output_parsers import RetryWithErrorOutputParser
retry_parser = RetryWithErrorOutputParser.from_llm(
parser=parser, llm=OpenAI(temperature=0))
retry_parser.parse_with_prompt(bad_response, prompt_value)