C语言指针进阶版
前言
指针是C语言的灵魂,有了它的存在,C语言就变得无比灵活,但是也让许多学习C语言的小伙伴的头脑爆炸,本文章是我通过学习总结下来的笔记。
- 指针是就是个变量,用来存放地址,地址唯一标识一块内存空间
- 指针的大小是固定的4/8个字节(32位平台/64位平台)
- 指针是由类型,指针的类型决定了指针的+-整数的步长,指针解引用操作的时候的权限
- 指针的预算(指针+-整数、指针-指针)
本文章重点
- 字符指针
- 数组指针
- 指针数组
- 数组传参和指针传参
- 函数指针
- 函数指针数组
- 指向函数指针数组的指针
- 回调函数
一、字符指针
在指针的类型中,我们知道有一种指针类型为字符指针char*;
一般使用:
(1)指向一个字符变量地址
int main()
{
char ch = 'w';
char *pc = &ch;
*pc = 'a';
return 0;
}
(2)指向一串字符串的首个字符的地址
int main()
{
const char* pstr = "hello bit.";//这里是把一个字符串放到pstr指针变量里了吗?
printf("%s\n", pstr);
return 0;
}
代码const char* pstr = "hello bit.";特别容易让同学以为把字符串hello bit放到字符指针pstr里,但是本质上是把字符串hello bit.首字符的地址放到pstr中。
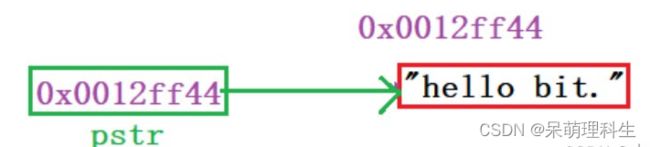 上面代码的意思是把一个常量字符串的首字符'h'的地址存放到指针变量pstr中。
上面代码的意思是把一个常量字符串的首字符'h'的地址存放到指针变量pstr中。
那就有这样一个面试题:
int main()
{
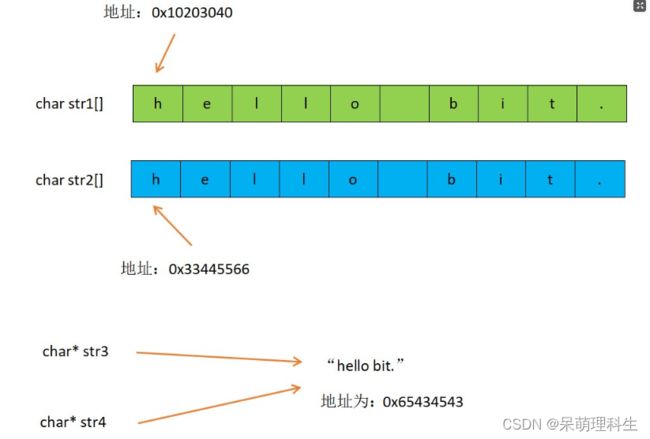
char str1[] = "hello bit.";
char str2[] = "hello bit.";
const char *str3 = "hello bit.";
const char *str4 = "hello bit.";
if(str1 == str2)
printf("str1 and str2 are same\n");
else
printf("str1 and str2 are not same\n");
if(str3 == str4)
printf("str3 and str4 are same\n");
else
printf("str3 and str4 are not same\n");
return 0;
}
最终输出结果:

这里str3和str4指向的是一个同一个常量字符串。C/C++会把常量字符串存储到单独的一个内存区,传递给字符型指针的字符串是存储在全局区或者数据区里面,全局区里面的数据不可以修改。(这里在str3和str4前面加上const是为了保证在编译时编译器能给我们检查一下是否有代码对数据进行修改)当几个字符指针指向同一个字符串的时候,他们实际会指向同一块内存。但是用相同的常量字符串去初始化不同的数组的时候就会开辟出不同的内存快。所以str1和str2不同,str3和str4相同。
图示如下:
二、指针数组
在我的文章C语言的指针(初阶)中有讲过指针数组,指针数组就是一个存放指针的数组。
例1:
int main()
{
/*指针数组
数组 - 数组中存放的是指针(地址)*/
//int* arr[3];//存放整形指针的数组
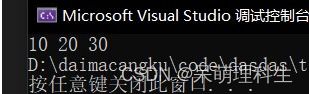
int a = 10;
int b = 20;
int c = 30;
int* arr[3] = {&a, &b, &c};
int i = 0;
for (i = 0; i < 3; i++)
{
printf("%d ", *(arr[i]));
}
return 0;
}
(1)&a,&b,&c;是这各自变量的地址存放到int* arr[3]指针数组中
(2)第一次循环,arr[0]表示是&a的值(也就是a变量的地址),*(arr[0])对地址进行解引用(也就是对&a进行解引用)对变量a进行输出(这里的arr[0]的外面也可以不用加小括号,因为[]的优先级高于*)
(3)结果如下:
例2:
int main()
{
/*指针数组
数组 - 数组中存放的是指针(地址)*/
int a[5] = { 1,2,3,4,5 };
int b[] = { 2,3,4,5,6 };
int c[] = { 3,4,5,6,7 };
int* arr[3] = {a,b,c};
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 5; j++)
{
//printf("%d ", *(arr[i] + j));
printf("%d ", arr[i][j]);
}
printf("\n");
}
return 0;
}
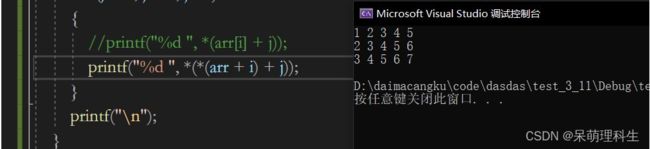
(1)int* arr[3] = {a,b,c};的作用是将每一个维数组的首元素地址赋值给int* arr[3]中的元素。
(2)接着用3个循环进行输出,第一层循环是取出一维数组的首元素的地址,第二层循环接着使得每个首元素进行地址移动取出里面的值(例如:取出arr[0] + 1表示第一个一维数组的第2个元素的地址,*(arr[0] + 1)输出该地址的值)。
(3)其中的*(arr[i] + j)也可以写成arr[i][j],为什么呢?假如有一个维数组为arr,arr数组名代表了首元素的地址,一个元素arr[i]在编译时会被解析成*(arr+i)。同理可得:arr[i]在本代码中代表每一组数组的首元素的地址,那么arr[i][j]([]的结合性是从左往右),就可以解析为①*(*(arr + i)[j]),②*(*(arr + i) + j)
(4)结果如下:
 三、数组指针
三、数组指针
1.数组指针的定义
数组指针是指针?还是数组呢?
答案:是指针。
我们可以把指针数组理解指针的数组(许多指针组成的数组);数组指针理解为数组的指针(指向数组的指针)。
数组指针,是先有指针再指向数组类型,最后确定类型的是什么;指针数组是先确定为数组,再确定整个数组是否为指针,类型是什么。
我们知道int* pint;是能够指向整型数据的指针,float* pf;是能够指向浮点型数据的指针。那么我们就可以类比出数组指针的意思:就是能够指向数组的指针。
int main()
{
int a = 10;//①
int*pa = &a;//②
char ch = 'w';//③
char*pc = &ch;//④
double c[5]
double* d[5];//⑤
double (*pd)[5] = &c;//⑥ pd就是一个数组指针
double* (*pd)[5] = &d;//⑦ pd就是一个数组指针
return 0;
}
(1)我在我的文章中的《C语言的指针(初级)》中介绍过什么是整型指针、浮点型指针和字符型指针。②④分别是整型指针和字符型指针。
(2)⑤是浮点型指针的数组——我们可以从操作符的优先级和结合性去拆分double* d[5],第一:[ ]的优先级比*高,所以先执行d[5],结合性是从左往右,我们可以知道d[5]这是一个含有5个元素的数组,但是还不知道元素是什么类型的。第二:*d[5]表示d[5]的元素都是指针,那么是指向什么类型的指针呢。第三:double* d[5]我们就可以完整地知道d是一个指针数组,指向的数据类型是double。
(3)我们按照(2)的分析思路来分析⑥。第一:(*pd)得知这是一个指针。第二:因为[ ]的优先级高于*,所以执行(*pd)[5],我们就可得知了首先它是一个指针,[5]又是数组,那么合起来就是一个指针指向一个含有5个元素的数组。第三:double (*pd)[5]表示指向一个含有5个元素的数组,此数组是double类型。
(4)来个大招,分析⑦。第一:double* (*pd)[5]中的double (*pd)[5]的分析步骤同(3)。第二:&d是把double* d[5]的地址赋值给pd,double* d[5]是一个指针数组,含有5个元素指向double的指针,也就可以理解为每个元素都是一级指针,整个d也就是一个“大”的一级指针,那么什么能存储一级指针的地址呢?只能是二级指针了。所以double* (*pd)[5]的意思是pd是一个指向含有5个元素的double类型指针数组的二级指针(double*代表了指向的类型)。
int arr[10] = {1,2,3,4,5};
int (*parr)[10] = &arr;//取出的是数组的地址
注:
(1)arr - 数组名是首元素的地址 - arr[0]的地址
(2)parr 就是一个数组指针 - 其中存放的是数组的地址
(3)&arr;是取出的是数组的地址 ,所以arr != &arr,赋值给数组指针的数组地址要用&(取地址符)取出。
2.&数组名VS数组名
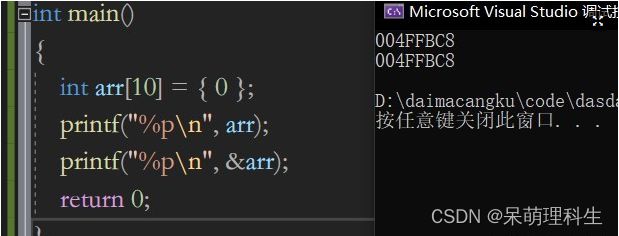
我们可以看到arr,&arr输出的地址都是一样,那么他们的代表意思就一样吗?再来看段代码。
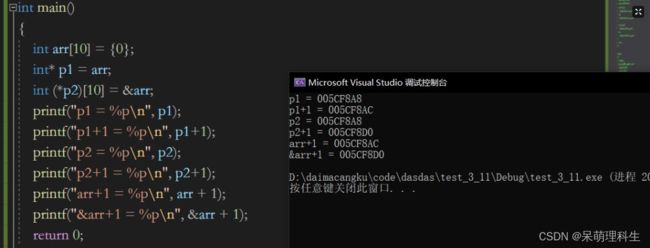
根据上面的代码我们发现,其实& arr和arr,虽然值是一样的,但是意义应该不一样的。
实际上:& arr 表示的是数组的地址,而不是数组首元素的地址。(细细体会一下)本例中& arr 的类型是: int(*)[10](数组也是自定义类型) ,是一种数组指针类型。数组的地址 + 1,跳过整个数组的大小,所以 & arr + 1 相对于 & arr 的差值是40,而arr+1在加时,只是跨过了一个int的大小(4个字节)。
注:数组名是数组首元素的地址
但是有2个例外:
(1)sizeof(数组名) - 数组名表示整个数组,计算的是整个数组大小,单位是字节
(2)&数组名 - 数组名表示整个数组,取出的是整个数组的地址
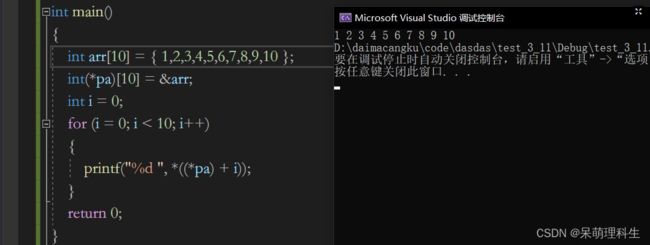
对pa进行解引用也就是*pa,可以理解为把&arr的&个去掉了,得到了arr也就是首元素的地址,那么地址去跨步,输出值也是需要解引用,就有了*((*pa) + i)。
void print1(int arr[3][5], int r, int c)
{
int i = 0;
int j = 0;
for (i = 0; i < r; i++)
{
for (j = 0; j < c; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
}
//p是一个数组指针
void print2(int(*p)[5], int r, int c)
{
int i = 0;
int j = 0;
for (i = 0; i < r; i++)
{
for (j = 0; j < c; j++)
{
printf("%d ", *(*(p + i) + j));
}
printf("\n");
}
}
int main()
{
//int a[5]; &a
int arr[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7 } };
//print1(arr, 3, 5);
print2(arr, 3, 5);//arr数组名,表示数组首元素的地址
return 0;
}
(1)int arr[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7 } };是一个含有3行5列int型元素的二维数组。
(2)print2(arr,3,5);传过去的是arr二维数组的第一行的地址,也就是arr[0]的地址。arr[0]同时也是里面的第一个一维数组的数组地址(arr[0]表示二维数组中第一行的数组地址【整个】,(*arr[0])才是表示第一行第一列元素的地址。要注意一步一步慢慢进去,先从行再到行列,)承接上文,一维数组的整个数组地址就应该由一个数组指针来接收,也就是int(*p)[5]。
(3)printf1(int arr[3][5],……)中的int arr[3][5]实际上也是接收的二维数组的第一行一维数组的地址,也就是int(*p)[5]。
回顾下面代码是什么意思:(比较难,细细体会~)
int arr [ 5 ]; 一个含有5个整型元素的整型数组。
int * parr1 [ 10 ]; 一个含有5个指向整型的指针元素的整型指针数组。
int ( * parr2 )[ 10 ]; 一个指向含有10个整型元素的数组的整型数组指针。
int ( * parr3 [ 10 ])[ 5 ]; 一个含有5个指向含有10个整型元素的数组的整型数组指针的指针数组。
四、数组参数、指针参数
在写代码的时候难免要把【数组】或者【指针】传给函数,那函数的参数该如何设计呢?
1.一维数组传参
void test(int arr[])//ok?①
{}
void test(int arr[10])//ok?②
{}
void test(int* arr)//ok?③
{}
void test2(int* arr[20])//ok?④
{}
void test2(int** arr)//ok?⑤
{}
int main()
{
int arr[10] = { 0 };
int* arr2[20] = { 0 };
test(arr);
test2(arr2);
}
(1)对①②而言,这种传参方式肯定是可以的。重点介绍③,arr是一个数组名,传过去的是int首元素的地址(也是一级指针的意思),int* arr也是int的一级指针,所以也是ok。
(2)int* arr[20]是一个指针数组,里面存放了20个元素的一级指针,arr2传过去的是首元素的地址,也就是一级指针的地址,一级指针的地址就可以由二级指针来接收。所以⑤就正确,④就不多说了。
2.二维数组传参
void test(int arr[3][5])//ok?①
{}
void test(int arr[][])//ok?②
{}
void test(int arr[][5])//ok?③
{}
//总结:二维数组传参,函数形参的设计只能省略第一个[]的数字。
//因为对一个二维数组,可以不知道有多少行,但是必须知道一行多少元素。
//这样才方便运算。
void test(int* arr)//ok?④
{}
void test(int* arr[5])//ok?⑤
{}
void test(int(*arr)[5])//ok?⑥
{}
void test(int** arr)//ok?⑦
{}
int main()
{
int arr[3][5] = { 0 };
test(arr);
}
(1)①②都可以,③不可以,就不多赘述了。
(2)对于④而言,arr是一个二维数组,传过去的值是第一行的地址,也就是一个数组的地址,所以不可以用一个整型指针来接收。
(3)对于⑤而言,int* arr[5]表示一维指针数组,一维指针数组怎么可能接收整个一维数组呢?
(4)对于⑥而言,int(*arr)[5]是一个数组指针,arr传过来的值刚好是一维数组的整个数组地址,刚好能接收。
(5)对于⑦而言,int**是指向int*的指针,而现在传过来的值是int(*)[ ]类型,也就是数组指针,所以接收不了。
3.一级指针传参
void print(int* p, int sz) {
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d\n", *(p + i));
}
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9 };
int* p = arr;
int sz = sizeof(arr) / sizeof(arr[0]);
//一级指针p,传给函数
print(p, sz);
return 0;
}
代码十分简单,就不多赘述了。
4.二级指针传参
void test(int** ptr)
{
printf("num = %d\n", **ptr);
}
int main()
{
int n = 10;
int* p = &n;
int** pp = &p;
test(pp);
test(&p);
return 0;
}
二级指针存放的是一级指针的地址,int** pp = &(int* p)(这是伪代码)
void test(char** p)
{}
int main()
{
char c = 'b';
char* pc = &c;
char** ppc = &pc;
char* arr[10];
test(&pc);
test(ppc);
test(arr);//Ok?①
return 0;
}
(1)对于①而言,char* arr[10]里面存放了10个字符型指针变量,那么arr数组名传参传过去的值为首元素的地址,也就是第一个字符型指针变量的地址,就为二级指针,所以拿char** p(二级指针)来接收就没有问题。
五、函数指针
首先看段代码:
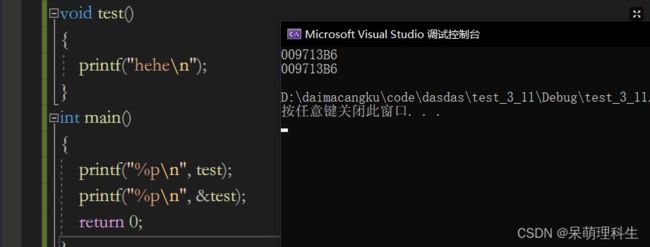
输出的是两个地址,这两个地址是test函数的地址。那我们的函数地址要想保存起来,怎么保存呢?
void test()
{
printf("hehe\n");
}
//下面pfun1和pfun2哪个有能力存放test函数的地址?
void (*pfun1)();
void* pfun2();
pfun1可以存放。因为()函数调用操作符的优先级高于*解引用操作符,所以需要加小括号提高优先级。pfun1先和*结合,说明pfun1是指针,指针指向的是一个函数,指向的函数无参数,返回值类型为void。推荐书籍《C陷阱和缺陷》
int main()
{
int a = 10;
int* pa = &a;
char ch = 'w';
char* pc = &ch;
int arr[10] = {0};
int (*parr)[10] = &arr;//取出数组的地址
//parr 是指向数组的指针 - 存放的是数组的地址
//函数指针 - 存放函数地址的指针
//&函数名 - 取到的就是函数的地址
//
//pf就是一个函数指针变量
int (*pf)(int, int) = &Add;//①
int (*pd)(int, int) = Add;//②
//printf("%p\n", &Add);
//printf("%p\n", Add);
return 0;
}
(1)①②的意义都一样,都是把Add函数的地址赋值给pd或者pf。
(2)函数指针的定义的格式:函数返回值类型 (*变量名)(参数类型1,参数类型2,……)。
练习1:对函数test定义一个函数指针
void test(char* str)
{}
int main()
{
//函数的参数是char*(一级指针)
void (*pt)(char*) = &test;//答案
return 0;
}
- 一级指针对应了变量的地址
- 二级指针对应了一级指针的地址
加深理解
int Add(int x, int y)
{
return x + y;
}
int main()
{
//pf就是一个函数指针变量
//int (*pf)(int, int) = &Add;
int (*pf)(int, int) = Add;//Add === pf
//int ret = (*pf)(3, 5);//①通过函数指针调用函数
//int ret = pf(3, 5);//②通过函数指针调用函数
//int ret = Add(3, 5);//③通过函数名调用函数
//
//int ret = * pf(3, 5);//err
//printf("%d\n", ret);
return 0;
}
(1)首先我们知道了数组名 != &数组名、函数名 == &函数名,函数指针是指向函数的指针,里面存放了函数的地址。
(2)int (*pf)(int, int) = Add;那么变量pf和Add是不是就相等了(细细体会下~),那么我在调用的时候无论是pf(3, 5)、Add(3, 5)和(*pf)(3, 5)调用都是正确的。这里的*号可以不看。因为在编译的时候都会变成:pf(3, 5)->(*pf)(3, 5)、Add(3, 5)->(*Add)(3, 5)、(*pf)(3, 5)->(*pf)(3, 5)。因为pf和函数名都是代表了地址,地址都必须解引用才能使用里面的东西,所以这种思路也是合情合理的。
(3)总结:调用函数时,只需要给出函数地址即可,解引用操作可由编译器来操作。
(4)论证代码如下:

阅读两端有趣的代码:
//代码1 (*(void (*)())0)(); //代码2 void (*signal(int , void(*)(int)))(int);
代码1:
注:我们分析代码都应该从数据入手,0就是一个数据,一个被系统默认的int数据。
(1) void(*)() - 函数指针类型
(2)(void(*)())0 - 对0进行强制类型转换,被解释为一个函数地址
(3) *(void(*)())0 - 对0地址进行了解引用操作
(4)(*(void(*)())0)() - 调用0地址处的函数
代码2:
注:数据可以是值,也可以是地址。数组名、函数名、变量都可以是一个数据的代表。例如:我们在定义一个函数指针(int (*变量名)(参数1,参数2,……)),那么我们知道了C语言在定义变量和定义函数是有些相同数,例如:int 变量名;int 函数名(参数列表),定义函数就多了个参数列表,int可以理解为最终代表的数据类型,变量名和函数名都只是个承载体,参数列表也就只是个过程而已,这样理解的话,C语言的数据定义就变得通透起来了。
(1)signal 和()先结合,说明signal是函数名。
(2)signal函数的第一个参数的类型是int,第二个参数的类型是函数指针。该函数指针,指向一个参数为int,返回类型是void的函数。
(3)signal函数的返回类型也是一个函数指针。该函数指针,指向一个参数为int,返回类型是void的函数。
(4) signal是一个函数的声明。
为什么可以这样写呢?类比(int (*变量名)(参数1,参数2,……))就表示了该变量名是一个函数指针,int为返回类型,为什么必须这样写呢?是由于操作符的结合性和优先级决定的。
所以,把signal(int , void(*)(int))拿掉就剩下:void(*)(int)这不就是一个函数指针类型的意思吗,函数指针指向的函数返回值是void,参数列表是(int)。而signal(int , void(*)(int))的返回值类型就是void(*)(int)。计算机通过操作符的优先级和结合性去解释这段代码。
void (*signal(int , void(*)(int)))(int);可以进一步改写为:
typedef void(*pfun_t)(int);
pfun_t signal(int, pfun_t);
写多了起别名方式后,我们就可以发现,别名的定义位置是不是和变量名的位置一致呢?答案是肯定的。例如:void(*p)(int);p是一个函数指针;而typedef void(*pfun_t)(int);pfun_t是一个函数指针类型的别名,只是在最前面多加了个typedef,把变量名改为别名就ok了。
六、函数指针数组
数组是一个存放相同类型数据的存储空间(在内存中也是开辟了一连串的空间),那我们已经学习了指针数组,比如:
int *arr[10]; //数组的每个元素是int*
那么要把函数的地址存放到一个数组中,那这个数组就叫函数指针数组,那函数指针的数组如何定义?
//函数指针数组 - 存放函数指针的数组
//
//整型指针 int*
//整型指针数组 int* arr[5];
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int main()
{
int (*pf1)(int, int) = Add;
int (*pf2)(int, int) = Sub;
int (*pfArr[2])(int, int) = {Add, Sub};//pfArr就是函数指针数组
return 0;
}
(1)(* pfArr[2])中的pfArr和[2]先结合,确定了pfArr是一个数组,本身为数组名。把pfArr[2]取出不看,就剩下int (*)(int, int)类型,也就是数组里面元素的类型。
(2)反正pfArr[2]的优先级高于*,那么是否能将代码写成int *pfArr[2](int,int)呢?
显然是不行的因为聚组()的优先级高于()函数调用,而函数调用的优先级又高于*。如果写成了int *pfArr[2](int,int),那么pfArr还是与[2]相结合表示数组,接下来就和函数调用操作符()结合变成了调用函数,这就很奇怪了。只有先是*确定了数组为指针数组,接下来才有说法嘛。
注:无论是变量类型还是函数返回值,都可以理解为类型(int)确定是最后操作。
(3)要知道数组的元素类型是什么可以把数组名[ ]去掉,剩下的就是数组元素的类型。
好了,不想想了,头脑快炸了!!!
例子:(计算器)
(1)不用函数指针数组
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("**************************\n");
printf("**** 1. add 2. sub ****\n");
printf("**** 3. mul 4. div ****\n");
printf("**** 0. exit ****\n");
printf("**************************\n");
}
int main()
{
int input = 0;
//计算器-计算整型变量的加、减、乘、除
//a&b a^b a|b a>>b a<b
do {
menu();
int x = 0;
int y = 0;
int ret = 0;
printf("请选择:>");
scanf("%d", &input);
switch (input)
{
case 1:
printf("请输入2个操作数>:");
scanf("%d %d", &x, &y);
ret = Add(x, y);
printf("ret = %d\n", ret);
break;
case 2:
printf("请输入2个操作数>:");
scanf("%d %d", &x, &y);
ret = Sub(x, y);
printf("ret = %d\n", ret);
break;
case 3:
printf("请输入2个操作数>:");
scanf("%d %d", &x, &y);
ret = Mul(x, y);
printf("ret = %d\n", ret);
break;
case 4:
printf("请输入2个操作数>:");
scanf("%d %d", &x, &y);
ret = Div(x, y);
printf("ret = %d\n", ret);
break;
case 0:
printf("退出程序\n");
break;
default:
printf("选择错误,重新选择!\n");
break;
}
} while (input);
return 0;
}
(2)使用函数指针数组的实现
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("**************************\n");
printf("**** 1. add 2. sub ****\n");
printf("**** 3. mul 4. div ****\n");
printf("**** 0. exit ****\n");
printf("**************************\n");
}
int main()
{
int input = 0;
//计算器-计算整型变量的加、减、乘、除
//a&b a^b a|b a>>b a<b
do {
menu();
//pfArr就是函数指针数组
//转移表 - 《C和指针》
int (*pfArr[5])(int, int) = { NULL, Add, Sub, Mul, Div };
int x = 0;
int y = 0;
int ret = 0;
printf("请选择:>");
scanf("%d", &input);//2
if (input >= 1 && input <= 4)
{
printf("请输入2个操作数>:");
scanf("%d %d", &x, &y);
ret = (pfArr[input])(x, y);
printf("ret = %d\n", ret);
}
else if(input == 0)
{
printf("退出程序\n");
break;
}
else
{
printf("选择错误\n");
}
} while (input);
return 0;
}
七、指向函数指针数组的指针
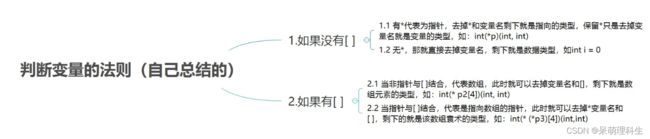
(1)指针类型 != 指向的类型。如int(*p)(int, int)的变量p的类型是int(*)(int, int);p指针指向的类型是int (int, int)。
(2)声明函数和定义函数指针都不需要写出具体的形参字符,只有在定义函数时才需写出。
(3)数组类型与数组元素类型比较:int arr[10];元素的数据类型是int,数组的类型是int[10]。
(4)通过对上面的思维导图分析可得:一个变量与[ ]结合后,就可以不看变量名[]或(*变量名)[],此时剩下的东西就是来说明数组元素的类型。如果一个变量的定义没有[ ],说明就只有指针(*表示变量为指针,剩下东西说明指向数据的类型)或普通变量(剩下东西直接说明该变量的数据类型)。

指向函数指针数组的指针是一个指针
指针指向一个数组,数组的元素都是函数指针
例子如下:
void test(const char* str)
{
printf("%s\n", str);
}
int main()
{
//函数指针pfun
void (*pfun)(const char*) = test;
//函数指针的数组pfunArr
void (*pfunArr[5])(const char* str);
pfunArr[0] = test;
//指向函数指针数组pfunArr的指针ppfunArr
void (*(*ppfunArr)[5])(const char*) = &pfunArr;
return 0;
}
八、回调函数
回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
我们可以用回调函数的思想对前面的计算器代码进行修改:
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("**************************\n");
printf("**** 1. add 2. sub ****\n");
printf("**** 3. mul 4. div ****\n");
printf("**** 0. exit ****\n");
printf("**************************\n");
}
int Calc(int (*pf)(int, int))
{
int x = 0;
int y = 0;
printf("请输入2个操作数>:");
scanf("%d %d", &x, &y);
return pf(x, y);
}
int main()
{
int input = 0;
//计算器-计算整型变量的加、减、乘、除
//a&b a^b a|b a>>b a<b
do {
menu();
int ret = 0;
printf("请选择:>");
scanf("%d", &input);
switch (input)
{
case 1:
ret = Calc(Add);
printf("ret = %d\n", ret);
break;
case 2:
ret = Calc(Sub);
printf("ret = %d\n", ret);
break;
case 3:
ret = Calc(Mul);
printf("ret = %d\n", ret);
break;
case 4:
ret = Calc(Div);
printf("ret = %d\n", ret);
break;
case 0:
printf("退出程序\n");
break;
default:
printf("选择错误,重新选择!\n");
break;
}
} while (input);
return 0;
}
int Calc(int (*pf)(int, int))
{
int x = 0;
int y = 0;
printf("请输入2个操作数>:");
scanf("%d %d", &x, &y);
return pf(x, y);
}
定义了这样一个函数,里面的形参类型是int (*)(int, int),也就是个函数指针类型。该类型可以对应上:Add、Sub、Mul、Div。通过传入的地址是什么,再去调用相应的函数,完成对事件或条件的响应。
复习冒泡排序
void bubble_sort(int arr[], int sz)
{
int i = 0;
//冒泡排序的趟数
for (i = 0; i < sz - 1; i++)
{
//一趟冒泡排序
int j = 0;
for (j = 0; j < sz-1-i; j++)
{
if (arr[j] > arr[j + 1])
{
//交换
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
void print_arr(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
//升序
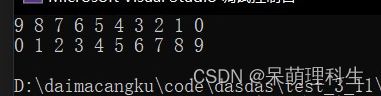
int arr[10] = { 9,8,7,6,5,4,3,2,1,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
print_arr(arr, sz);
bubble_sort(arr, sz);
print_arr(arr, sz);
return 0;
}
接下来解析一下qsort函数的使用(里面含有回调函数)
(1)首先我们得知道qsort函数的特点
void qsort(void* base, //base中存放的是待排序数据中第一个对象的地址
size_t num, //排序数据元素的个数
size_t size,//排序数据中一个元素的大小,单位是字节
int (*cmp)(const void* e1, const void* e2)//是用来比较待排序数据中的2个元素的函数
);
(2)接着得明白e1-e2是代表要得到升序的结果,e2-e1是代表要得到降序的结果。e1是相比于e2的前一个地址里的数值。
(3) int (*cmp)(const void* e1, const void* e2)中传入的函数是由用户自行定义,要按照一样的样式的函数(返回值一致,参数列表一致)
(4)qsort函数是在stdlib.h头文件中
1.以排序int数组为例:
#include#include void print(int arr[], int sz) { int i = 0; for (i = 0;i < sz;i++) { printf("%d ", *(arr + i)); } printf("\n"); } // int (*cmp)(const void* e1, const void* e2) //该函数由qsort函数通过函数指针来调用 int cmp_int(const void* e1, const void* e2) { return *((int*)e1) - *((int*)e2); } void test() { int arr[] = { 9,8,7,6,5,4,3,2,1,0 }; int sz = sizeof(arr) / sizeof(arr[0]);//得到数组的元素个数 print(arr, sz); qsort(arr, sz, sizeof(arr[0]), cmp_int);//arr[0]得到一个元素的字节大小 print(arr, sz); } int main() { test(); return 0; }
运行结果如下:

2.以排序结构体数组为例
(1)以int age来排序
#include#include struct Stu { char name[20]; int age; }; // int (*cmp)(const void* e1, const void* e2) int cmp_struct_by_age(const void* e1, const void* e2) { return ((struct Stu*)e1)->age - ((struct Stu*)e2)->age; } void test2() { struct Stu students[] = { {"lishi",30},{"zhanshan",20},{"aa",10} }; int sz = sizeof(students) / sizeof(students[0]); qsort(students, sz, sizeof(students[0]), cmp_struct_by_age); printf("students[0].age==%d", students[0].age); } int main() { test2(); return 0; }
运行结果如下:

(2)以char name[20]来排序
#include#include #include struct Stu { char name[20]; int age; }; // int (*cmp)(const void* e1, const void* e2) int cmp_struct_by_name(const void* e1, const void* e2) { return strcmp(((struct Stu*)e1)->name, ((struct Stu*)e2)->name); } void test2() { struct Stu students[] = { {"lishi",30},{"zhanshan",20},{"aa",10} }; int sz = sizeof(students) / sizeof(students[0]); qsort(students, sz, sizeof(students[0]), cmp_struct_by_name); printf("students[0].name==%s", students[0].name); } int main() { test2(); return 0; }
运行结果如下:
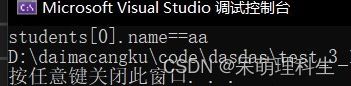
3.模仿qsort实现一个冒泡排序的通用算法
#include#include #include //void qsort(void* base, //base中存放的是待排序数据中第一个对象的地址 // size_t num, //排序数据元素的个数 // size_t size,//排序数据中一个元素的大小,单位是字节 // int (*cmp)(const void* e1, const void* e2)//是用来比较待排序数据中的2个元素的函数 //); void Swap(char* num1, char* num2, int width) { //按字节来交换 int i = 0; for (i = 0;i < width;i++) { char tmp = *num1; *num1 = *num2; *num2 = tmp; num1++; num2++; } } void bubble_sort(void* base, int num, int width, int(*cmp)(const void* e1, const void* e2)) { int i = 0, j = 0; //第一层for循环决定了冒泡排序的趟数 for (i = 0;i < num - 1;i++) { //一趟冒泡排序 for (j = 0;j < num - 1 - i;j++) { //10个元素就要比9次,9个就比8次,刚好和i关系上了 //下面使用了回调函数 if (cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0){ //交换 Swap((char*)base + j * width, (char*)base + (j + 1) * width,width); } } } } int cmp_int(const void* e1, const void* e2) { return *((int*)e1) - *((int*)e2); } void print(int arr[], int sz) { int i = 0; for (i = 0;i < sz;i++) { printf("%d ", *(arr + i)); } printf("\n"); } void test() { int arr[] = { 9,8,7,6,5,4,3,2,1,0 }; int sz = sizeof(arr) / sizeof(arr[0]); print(arr, sz); bubble_sort(arr, sz, sizeof(arr[0]), cmp_int); print(arr, sz); } int main() { test(); return 0; }
运行结果如下: