为什么 SQL 不适合图数据库
背景
“为什么你们的图形产品不支持 SQL 或类似 SQL 的查询语言?”
过去,我们的一些客户经常问这个问题,但随着时间的推移,这个问题变得越来越少。
尽管一度被忽视,但图数据库拥有无缝设计并适应其底层数据结构的查询语言的必要性已被创新产品所明确证明并受到市场的欢迎。图数据库在数据模型、数据存储、性能等方面与关系数据库存在显著差异,适合不同的应用场景和业务目标。这些区别表明SQL不适合用作本机图计算引擎的查询语言。
为了进行更全面的比较,我们将演示针对存储在 SQL Server 中的表格数据集的 SQL 查询,以及在 UQL 中编写的等效查询,以针对加载到 Ultipa 中的相同内容的图形数据集运行。这两个数据集在另一篇文章《分步指南:如何将表格转换为图形》中进行了分析。
数据集
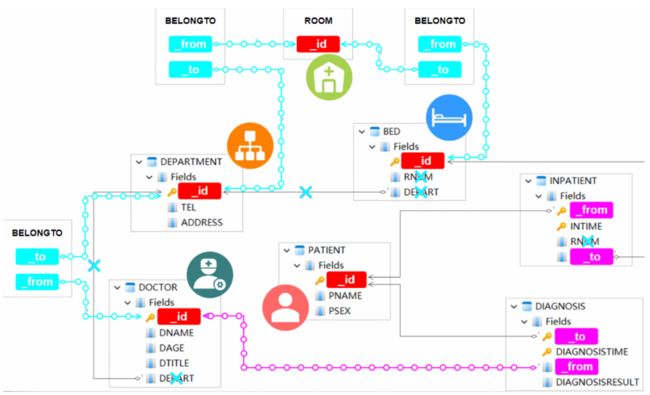
如果您还没有机会查看它,我们将使用的表格数据集包含来自医院信息管理系统内的六个表的数据:医生、患者、科室、病床、诊断和住院患者。该数据集相对较小,由大约 60 行记录组成。每个表的数据字段概述如下,重点关注它们的互连(从外键指向主键的箭头):
表结构的简洁可视化,强调从外键到主键的 连接。
SQL Server 连接中的分层数据管理结构表示为“数据库表字段”,在 Ultipa 图形系统中可以将其转换为“图形架构属性”。换句话说,Ultipa图系统中的模式对应于关系数据库中的表,模式属性类似于表字段。
图数据集是从上述表格数据集通过将表结构转换为节点模式(具有 _id 等属性)和边模式(具有 _from、_to 等属性)而派生出来的。此过程涉及相当于对原始表进行修改的任务,如下所述:
通过对原始表结构的修改来说明图模型的全面描述
生成的图形数据集包含五个节点模式:DOCTOR、PATIENT、DEPARTMENT、BED 和 ROOM,以及三个边缘模式:DIAGNOSIS、INPATIENT 和 BELONGTO。节点 ID 是从表的主键中提取的,而边的 FROM 和 TO 是从表的外键中导出的,并在必要时进行补充。
表查询与架构查询
鉴于 SQL Server 中表的概念与 Ultipa 中架构的概念相对应,我们首先比较一下 DOCTOR 表和 DOCTOR 节点架构的查询过程。
-
查询目标:检索每位医生的所有信息。
SQL:
SELECT * FROM guest.DOCTOResult of single-table query using SQLUQL:
n({@DOCTOR} as N) RETURN N{*}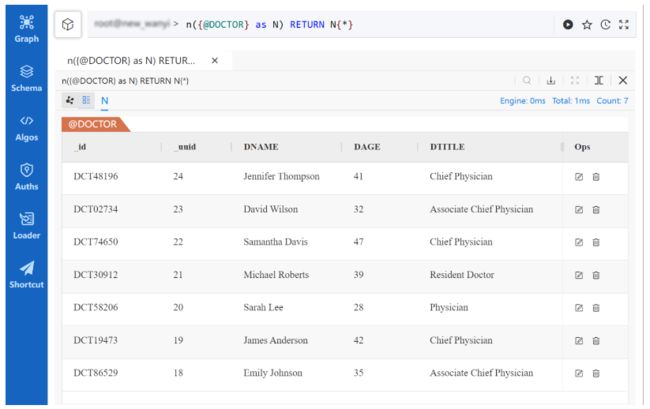
使用 UQL 的单模式查询结果
尽管两个查询同样清晰并产生相同的结果,但 SQL 类似于请求“从 DOCTOR 表中选择所有数据字段”的英语句子,而 UQL 故意偏离这种基于自然语言的语法,利用符号来传达其执行逻辑,即“n()”,表示图中的节点。
这种方法符合图的本质,其中节点和边是基本组件,这与表作为核心数据模型存在的关系数据库不同。在下一轮中,我们将遇到 UQL 中表示边缘的“e()”。
连接查询与路径查询
图数据通过忠实地复制现实世界的复杂性而赢得赞誉。例如,可以轻松地查询图形数据之间的链式关系(称为路径查询) ,特别是与关系表的JOIN 查询相比。
-
查询目标:检索Michael Roberts医生治疗过的所有患者的详细信息,包括诊断结果和医生姓名。
SQL:
SELECTPATIENT.PNO,PATIENT.PNAME,PATIENT.PSEX,DIAGNOSIS.DIAGNOSISRESULT,DIAGNOSIS.DNAMEFROMguest.DIAGNOSISJOIN guest.PATIENT ON guest.DIAGNOSIS.PNO = guest.PATIENT.PNOWHEREDNAME = 'James Anderson'

使用SQL进行表JOIN查询的结果
UQL:
n({@DOCTOR.DNAME == "James Anderson"} AS D).e({@DIAGNOSIS} AS A).n({@PATIENT } AS P)RETURN table(P._id,P.PNAME,P.PSEX,A.DIAGNOSISRESULT,D.DNAME)
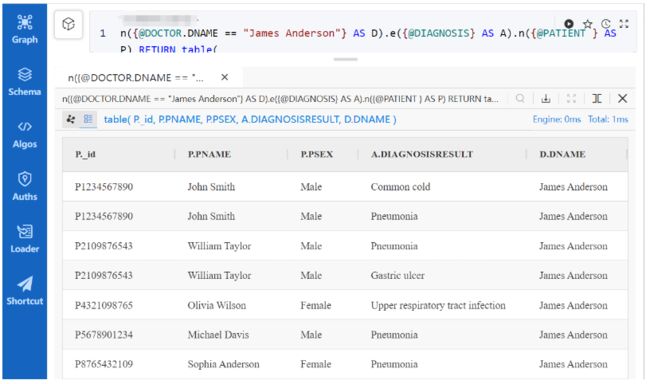
使用UQL的路径查询结果
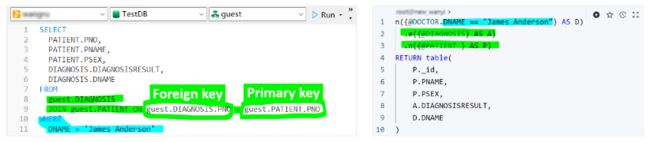
虽然在前面用于查询单个表或模式的代码中可能没有突出强调这一点,但在这些更广泛的代码摘录中出现了一个有趣的观察结果:这两种查询语言的语法表达式是相反的。SQL 首先定义要检索的数据,然后概述数据必须满足的过滤条件。另一方面,UQL 首先描述数据应满足的标准,然后指定要检索的数据。这种语法顺序的颠倒会影响开发人员的思维过程,从而带来不同的编程体验。

语法顺序比较,SQL(左)与 UQL(右)
让我们将焦点转移回数据关系的表示。SQL 使用 JOIN 来链接表,并应用 ON 来锚定关键字段(主键、外键)。相比之下,UQL 采用路径模板 n().e().n() 来系统地定义互连的节点和边,基本上消除了额外锚定步骤的需要。
关系表达式的比较,SQL(左)与 UQL(右)
为什么图查询语言(这里是UQL)能够实现如此精简的表达?这是因为表之间固有的锚定关系,即从外键到主键的链接,无缝嵌入到边缘数据(_from 和 _to)中。这种基本的集成正是图数据库在有效管理关联关系方面优于关系数据库的原因。
此外,UQL 直接将过滤条件合并到每个节点和边声明 n() 和 e() 中,这与 SQL 的 WHERE 子句不同,后者在连接所有表并锚定后添加过滤条件。这种方法使 UQL 语法更加简洁、有凝聚力,并增强了代码的可读性。
UQL巧妙地将每个节点和边缘及其过滤条件整合成一个自然的链状路径模型。
值得强调的是,虽然上面的 SQL 和 UQL 片段长度相似并且产生相同的结果,但它们的实际查询功能从底层来看是不同的。在上面的示例中,SQL 仅完成 PATIENT 和 DIAGNOSIS 两个表之间的连接,从 DIAGNOSIS 表中检索医生的姓名 (DNAME)。相比之下,UQL 在 PATIENT、DIAGNOSIS 和 DOCTOR 之间建立关系,本质上是跨三个表(模式)执行 JOIN。它返回 D.DNAME,这是节点模式 DOCTOR 的属性。了解这些潜在的区别给性能比较增添了讽刺:SQL 查询花费了 3 毫秒,而处理更多数据关联的 UQL 查询只花费了 0.5 毫秒。
从 3 毫秒到 0.5 毫秒的转变可能看起来无关紧要,但随着查询的链式关系数量的增加,它变得非常明显。SQL 中针对 10,000 行的小表的递归 5 表 JOIN 查询将需要 38 秒,而 UQL 中的 5 步路径模板实现的等效查询仅需要 0.001 秒。在更一般的情况下,SQL 在针对大型数据集执行冗长的链表 JOIN 时往往会遇到困难。虽然并发性的低效利用确实造成了这种显著差异,但与 UQL 相比,所有 JOIN 过程中表记录的笛卡尔积是 SQL 查询性能指数级下降的根本原因。
使用图查询的技巧
到目前为止,我们一直以传统的表格格式呈现UQL的查询结果,以便与SQL进行比较。然而,我们强烈建议使用 2D/3D 可视化在小规模图上表示路径查询的结果。这种方法有助于更直观地理解和分析数据。
本文中实现的查询目标表示图中的一步路径。将提供的 UQL 的返回值重新配置到这些路径并执行查询后,Ultipa Manager 中获得的 2D 结果如下所示:
n({@DOCTOR.DNAME == "James Anderson"}).e({@DIAGNOSIS}).n({@PATIENT}) AS pRETURN p{*}
结论
在本文中,我们的目标不是全面展示图查询语言与结构化数据查询语言的不同之处。相反,我们的目标是传达图数据库应该如何从根本上设计其查询语言以及为什么 SQL 可能不适合查询图数据。
代码组合的简单性和针对本机图的查询效率提供了宝贵的见解——也许在处理数据时,我们应该采用更直观、更自然的方法,类似于通过图来理解世界,而不是陷入抽象的数据网络中关系数据库。
作者:Ricky Sun
更多技术干货请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。
irds.cn,多数据库管理平台(私有云)。