Linux 正则表达式
内容概述
1 文本编辑工具之神 VIM

1.1 vi 和 vim 简介
在 Linux 中我们经常编辑修改文本文件,即由 ASCII Unicode 或者其他编码的纯文字的文件。之前介绍过的 nano,实际工具中我们使用更为专业,功能强大的工具
文本编辑种类:
vi
Visual editor(可视化编辑器),文本编辑器,是 Linux 必备工具之一,功能强大,学习曲线陡峭,学习难度大。
vim
Visual editor iMproved,和 vi 使用方法一致,但是功能更为强大,不是必备软件。
官网:www.vim.org
其他相关编辑器:gvim 一个 Vim 编辑器的图形化版本。
参考链接
https://www.w3cschool.cn/vim/
1.2 使用 vim 初步
1.2.1 vim 命令格式
usage: vim [arguments] [file ..] edit specified file(s)
or: vim [arguments] - read text from stdin
or: vim [arguments] -t tag edit file where tag is defined
or: vim [arguments] -q [errorfile] edit file with first error
说明:
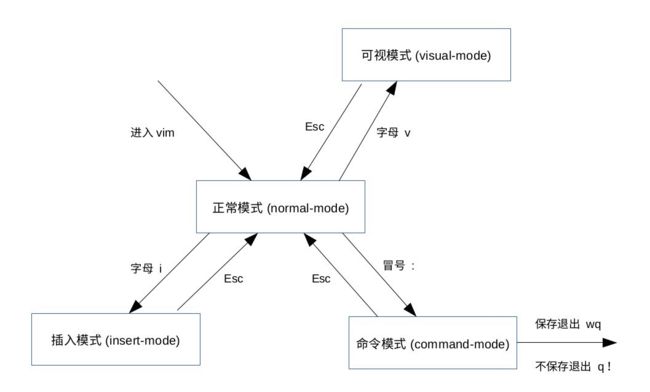
1.2.2 三种主要模式和转换
vim 是一个模式编辑器,击键行为是依赖于 vim 的“模式”
三种常见模式:
模式转换
范例:插入颜色字符
1 切换至插入模式
2 按住 Ctrl+v+[ 三个键,显示^[
3 后续输入颜色选项:如^[[32mhello^[[0m
4 切换到至扩展命令模式,保存退出
5 cat 文件可以看到下面显示信息
$ vim color.txt
^[[31mHello vim^[[0m
^[[32mGreen vim^[[0m
$ hexdump -C color.txt
00000000 1b 5b 33 31 6d 48 65 6c 6c 6f 20 76 69 6d 1b 5b |.[31mHello vim.[|
00000010 30 6d 0a 1b 5b 33 32 6d 47 72 65 65 6e 20 76 69 |0m..[32mGreen vi|
00000020 6d 1b 5b 30 6d 0a |m.[0m.|
00000026

1.3 扩展命令模式
按 “:” 进入 Ex 模式 ,创建一个命令提示符:处于底部的屏幕左侧
1.3.1 扩展命令模式基本使用
w :写(存)磁盘文件
wq :写入并退出
x :写入并退出
X :使用 cm 软加密算法进行文件加密
q :退出
q! :不存盘退出,即使更改都将丢失
r filename :读文件内容到当前文件中
w filename :将当前文件内容写入另一个文件
!command :执行命令
r!command :读入命令的输出
1.3.2 地址定界
格式:
:start_pos,end_pos CMD
1.3.2.1 地址定界格式
- \# :具体第 # 行,例如 2 表示第 2 行
- #,# :从左侧 # 表示的起始行,加上右侧 # 表示结尾行
- #,+# :从左侧 # 表示的起始行,加上右侧 # 表示的行数,范例:2,+3 表示 2到 5行
- . :当前行
- $ :最后一行
- .,$-1 :当前行到倒数第二行
- % :全文,相当于 1,$
- /pattern/ :从当前行向下查找,知道匹配到 pattern 的第一行,即正则表达式
- /pat1/,/pat2/ :从第一次被 pat1 模式匹配到的行开始,一直到第一次被 pat2 匹配到的行结束
- #./pat1/ :从指定行开始,一直找到第一个匹配pattern的行的结束
- /pat/,$ :向下找到第一个匹配pattern的行到整个文件的结尾的所有行
1.3.2.2 地址定界后跟一个编辑命令
- d :删除
- y :复制
- w file :将范围内的行另存为至指定文件中
- r file :在指定位置插入指定文件中的所有内容
1.3.3 查找并替换
格式:
s/要查找的内容/替换为的内容/修饰符
要查找的内容:可使用正则表达式
替换为的内容:不能使用模式,但是可以使用\1,\2,…等后向引用符号,还可以使用 “&” 引用前面查找时查找到的整个内容
修饰符:
说明:查找替换中的分隔符 / 可替换为其他字符,如:#,@,&
范例:
:s@/etc@/var@g
:s#/boot#/#i
1.3.4 定制vim的工作特性
扩展命令模式的配置只是对当前vim进程有效,可将配置存放在文件中持久保存
配置文件:永久有效
- 全局:/etc/vimrc
- 个人:~/.vimrc
- 扩展命令模式:当前 vim 进程有效
1.3.4.1 行号
- 显示:set number,简写:set nu
- 取消显示:set nonumber,简写:set nonu
1.3.4.2 忽略字符的大小写
- 显示:set ignorecase,简写:set ic
- 取消显示:set noignorecase,简写:set noic
1.3.4.3 自动缩进
- 启用:set autoindent,简写:set ai
- 不忽略:set noautoindent,简写:set noai
1.3.4.4 复制保留格式
- 启用:set paste
- 禁用:set nopaste
1.3.4.5 显示 Tab ^| 和换行符 和 $显示
- 启用:set list
- 禁用:set nolist
1.3.4.6 高亮搜索
- 启用:set hlsearch
- 禁用:set nohlsearch,简称:set nohl
1.3.4.7 语法高亮
- 启用:syntax on
- 禁用:syntax off
1.3.4.8 文件格式
- 启用 windows 格式(将 unix 格式转换为 dos 格式):set fileformat=dosx
- 启用 unix 格式(将 dos 格式转换为 unix 格式):set fileformat=unix
- 简写:set ff = dos | unix
1.3.4.9 Tab 用空格代替
- 启用:set expandtab 默认为8个空格代替Tab
- 禁用:set noexpandtab
- 简写:set et
1.3.4.10 Tab用指定空格的个数代替
- 启用:set tabstop=# 指定#个空格代替Tab(例如:4)
- 禁用:set notabstop
- 简写:set ts=4
1.3.4.11 设置文本宽度
- set textwidth = 65(vim only) # 从左向右计数
- set wrapmargin = 15 # 从右想左计数
1.3.4.12 设置光标所在行的标识线
- 启用:set cursorline,简写:set cul
- 禁用:set nocursorline,简写:set nocul
1.3.4.13 加密
- 启用:set key=password
- 禁用:set key=
1.3.4.14 了解更多
set 帮助
vi / vim 内置帮助
vimtutor 帮助手册
1.4 命令模式
命令模式,又称为 Normal 模式,命令模式功能强大,只是按键时,看不到输入(只是此模式输入指令并在屏幕上显示),所以需要大量的记忆才能更好的使用。
1.4.1 退出vim
ZZ:保存退出(编辑模式:wqall)
ZQ:不保存退出(编辑模式:qall)
1.4.2 光标跳转
字符间跳转:
^
k
< h l >
j
v
单词间跳转:
当前页跳转:
行首行尾跳转:
行间移动:
句间移动:
段落间移动:
命令模式翻屏操作:
1.4.3 字符编辑
- x :删除光标处的字符(剪切)
- #x :删除光标处起始的 # 个字符
- xp :交换光标所在处的字符及其后面的字符的位置
- ~ :转换大小写
- J :删除当前行后的换行符
1.4.4 替换命令(replace)
- r :替换光标所在处的字符
- R :切换成 REPLACE 模式 → ESC 回到命令模式
1.4.5 删除命令(delete)
- dd :删除命令,可结合光标跳转字符,实现范围删除
- d$ :删除到行尾
- d^ :删除到非空行首
- d0 :删除到行首
- dw :删除下一个单词的词首
- de :删除当前或者下一个单词的词尾
- db :删除当前或者前一个单词的词首
- #COMMAND:删除多个
- #dd :多行删除
- D :从当前光标位置一直删除到行尾,等同于 d$
1.4.6 复制命令(yank)
- y:复制,行为相似于 d 命令
- y$:复制到行尾
- y0:复制到行首
- y^:复制到非空行首
- ye:复制当前或者下一个单词的词尾
- yw:复制下一个单词的词首
- yb:复制当前或者前一个单词的词首
- #COMMAND:复制多个
- yy:行复制
- #yy:多行复制
- Y:复制整行
1.4.7 粘贴命令(paste)
- p:缓冲区存的如果为整行,则粘贴当前光标所在行的下方;否则,则粘贴至当前光标所在处的后面。
- P:缓冲区存的如果为整行,则粘贴当前光标所在行的上方;否则,则粘贴至当前光标所在处的前面。
1.4.8 改变命令(change)
- c:删除后,并切换成插入模式
- c$:删除到行尾后,并切换成插入模式
- c^:删除到非空行首,并切换成插入模式
- c0:删除到行首,并切换成插入模式
- cb:删除当前或者前一个单词的词首,并切换成插入模式
- ce:删除当前或者下一个单词的词尾,并切换成插入模式
- cw:删除下一个单词的词首,并切换成插入模式
- #COMMAND:删除多个,并切换成插入模式
- cc:删除当前行并输入新内容,相当于S
- #cc:多行删除并输入新内容
- C:删除当前光标到行尾,并切换成插入模式
命令模式操作文本总结
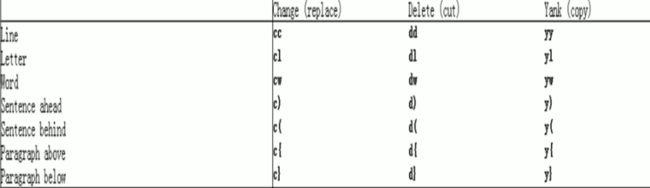
1.4.9 查找
1.4.10 撤销更改
1.4.11 高级用法
常见 Command:y 复制、d 删除、gU 变大写、gu 变小写;
范例:
0y$ :命令
0 :先到行头
y :从这里开始拷贝
$ :拷贝到本行最后一个字符
范例:粘贴 “wang” 100次
100iwang [ESC]
1.5 可视化模式
允许选择的文本块
可视化键可用于与移动键结合使用
w ) } 箭头等
突出显示的文字可被删除,复制,过滤,搜索,替换等。
范例:在文本行输入
1、输入 Ctrl + v 进入可视化模式
2、输入 G 跳到最后一行,选中第一行
3、输入 I 切换至插入模式
4、插入 #
5、按 ESC 键
# ---
1、先将光标移动到指定的第一行的行首
2、输入Ctrl+v,进入可视化模式
3、向下移动光标,选中希望操作的每一行的第一个字符
4、输入大写字母 I 切换至插入模式
5、输入 #
6、按 ESC 键
范例:在指定的块位置插入相同的内容
1、光标定位到要操作的地方
2、按Ctrl + V 进入可视化块模式,选取这一列操作多少行
3、SHIFT + i(I)
4、输入要插入的内容
5、按 ESC 键
1.6 多文件模式
vim FILE1 FILE2 FILE3 …
1.7 多窗口模式
1.7.1 多文件分割
vim -o | -O FILE1 FILE2 FILE3 …
1.7.2 单文件窗口分割
1.8 vim 的寄存器
有 26 个命令寄存器和 1个无命名寄存器,常存放不同的剪贴板内容,可以不同会话间共享
寄存器名称:a,b,……,z,格式:"寄存器,放在数字和命令之间
范例:
未指定,将使用无命名寄存器
有 10 个数字寄存器,用 0,1,……,9表示,0 存放最近复制内容,1 存放最近删除的内容。当新的文本变更和删除时,1 转存到 2,2 转存到 3,以此类推。数字寄存器不能再不同的会话间共享。
1.9 标记和宏(macro)
1.10 编辑二进制文件
# 以二进制方式打开文件
vim -b binaryfile
# 扩展命令模式下,利用 xxd 命令转换为可读的十六进制
:%!xxd
# 插入模式下,编辑二进制文件
# 扩展命令模式下,利用 xxd 命令转换回二进制
:%!xxd -r
# 保存退出
:wq
1.10.1 练习:
# 1、在vim中设置tab缩进为4个字符
# 2、复制/etc/rc.d/init.d/functions文件至/tmp目录,替换/tmp/functions文件中的/etc/sysconfig/init为/var/log
# 3、删除/tmp/functions文件中所有以#开头,且#后面至少有一个空白字符的行的行首的#号
# 1、在vim中设置tab缩进为4个字符
~ vim .vimrc
set expandtab
set tabstop=4
# 2、复制/etc/rc.d/init.d/functions文件至/tmp目录,替换/tmp/functions文件中的/etc/sysconfig/init为/var/log
~ cp -av /etc/rc.d/init.d/functions /tmp
~ vim /tmp/functions
:%s@\/etc\/sysconfig\/init@\/var\/log@ig
# 3、删除/tmp/functions文件中所有以#开头,且#后面至少有一个空白字符的行的行首的#号
~ vim /tmp/functions
:%s@^#\([[:space:]]\+\)@\1@ig
1.11 帮助
1.12 vim 总结图

vim 文本编辑工具
文本的各种工具主要用来查看,统计,不是修改文件
2 文本常见处理工具
2.1 文件内容查看命令
2.1.1 查看文本文件内容
2.1.1.1 cat
cat 可以查看文本内容,cat 不能查看二进制文件,查看的结果就是乱码
格式:
cat [OPTION] ... [FILE] ...
常见选项:
范例:
$ cat -A /data/fa.txt
a^Ib$
c $
d^Ib^Ic$
$ cat /data/fa.txt
a b
c
d b c
$ cat /data/fb.txt
a
b
c
$ hexdump -C fb.txt
00000000 61 0d 0a 62 0d 0a 63 0d 0a |a..b..c..|
00000009
$ cat -A fb.txt
a^M$
b^M$
c^M$
# -n 显示行号 -A 显示所有控制符
$ cat -An /data/fb.txt
1 a^M$
2 b^M$
3 c^M$
$ file /data/fb.txt
/data/fb.txt: ASCII text, with CRLF line terminators
2.1.1.2 nl
nl :显示行号(非空行编号),相当于 cat -b
nl命令是一个很好用的编号过滤工具。该命令可以读取 File 参数(缺省情况下标准输入),计算输入中的行号,将计算过的行号写入标准输出。
语法格式:nl [参数] [文件]
常用参数:
| -b | 指定行号指定的方式 |
|---|---|
| -n | 列出行号表示的方式 |
| -w | 行号栏位的占用的位数 |
| -p | 在逻辑定界符处不重新开始计算。 |
$ cat -b a.txt
1 a
2 b
3 c
$ nl a.txt
1 a
2 b
3 c
$ cat -b a.log
1 a
2 b
3 c
$ nl a.log
1 a
2 b
3 c
2.1.1.3 tac
tac :逆向显示文本内容
tac命令就是将文件反向输出,刚好和cat输出相反。
语法格式:tac [参数] [文件]
常用参数:
| -b | 在行前而非行尾添加分隔标志 |
|---|---|
| -r | 将分隔标志视作正则表达式来解析 |
| -s | 使用指定字符串代替换行作为分隔标志 |
| –version | 显示版本信息并退出 |
| –help | 显示此帮助信息并退出 |
$ cat a.txt
a
b
c
$ tac a.txt
c
b
a
$ tac
a
bb
ccc (按Ctrl + D)
ccc
bb
a
$ seq 10 | tac
2.1.1.4 rev
rev :将同一行的内容逆向显示
使用rev命令可以把每一行字符的顺序颠倒过来显示文件内容
语法格式:rev [文件]
$ cat a.txt
a b c d
1 2 3 4 5
$ rev a.txt
d c b a
5 4 3 2 1
$ rev
abcdef
fedcba
$ echo {1..10} | rev
01 9 8 7 6 5 4 3 2 1
2.1.2 查看非文本文件内容
2.1.2.1 hexdump
一般用来查看"二进制"文件的十六进制编码
语法:
hexdump [-bcCdovx] [-e format_string] [-f format_file] [-n length] [-s skip] file
参数:
- -s offset 从偏移量开始输出
- -n length 只格式化输入文件的前length个字节
- -v 显示所有的重复数据
- -C 输出十六进制和对应字符
- -e 指定格式字符串,格式字符串包含在一对单引号中
范例:以十六进制的方式显示文件内容
$ hexdump -C -n 512 /dev/sda
00000000 eb 63 90 10 8e d0 bc 00 b0 b8 00 00 8e d8 8e c0 |.c..............|
$ echo {a..z} | tr -d " " | hexdump -C
00000000 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 |abcdefghijklmnop|
00000010 71 72 73 74 75 76 77 78 79 7a 0a |qrstuvwxyz.|
0000001b
2.1.2.2 od
Linux od命令用于输出文件内容。
od指令会读取所给予的文件的内容,并将其内容以八进制字码呈现出来。
od:即 dump files in octal and other formats,输出文件的八进制、 十六进制等格式编码的字节
语法:
Usage: od [OPTION]… [FILE]…
or: od [-abcdfilosx]… [FILE] [[+]OFFSET[.][b]]
or: od --traditional [OPTION]… [FILE] [[+]OFFSET[.][b] [+][LABEL][.][b]]
参数:
- -a 此参数的效果和同时指定"-ta"参数相同。
- -A<字码基数> 选择要以何种基数计算字码。
- -b 此参数的效果和同时指定"-toC"参数相同。
- -c 此参数的效果和同时指定"-tC"参数相同。
- -d 此参数的效果和同时指定"-tu2"参数相同。
- -f 此参数的效果和同时指定"-tfF"参数相同。
- -h 此参数的效果和同时指定"-tx2"参数相同。
- -i 此参数的效果和同时指定"-td2"参数相同。
- -j<字符数目>或–skip-bytes=<字符数目> 略过设置的字符数目。
- -l 此参数的效果和同时指定"-td4"参数相同。
- -N<字符数目>或–read-bytes=<字符数目> 到设置的字符数目为止。
- -o 此参数的效果和同时指定"-to2"参数相同。
- -s<字符串字符数>或–strings=<字符串字符数> 只显示符合指定的字符数目的字符串。
- -t<输出格式>或–format=<输出格式> 设置输出格式。
- -v或–output-duplicates 输出时不省略重复的数据。
- -w<每列字符数>或–width=<每列字符数> 设置每列的最大字符数。
- -x 此参数的效果和同时指定"-h"参数相同。
- –help 在线帮助。
- –version 显示版本信息。
范例:
$ echo {a..z} | tr -d " " | od -t x
0000000 64636261 68676665 6c6b6a69 706f6e6d
0000020 74737271 78777675 000a7a79
0000033
$ echo {a..z} | tr -d " " | od -t x1
0000000 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70
0000020 71 72 73 74 75 76 77 78 79 7a 0a
0000033
$ echo {a..z} | tr -d " " | od -t x1z
0000000 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 >abcdefghijklmnop<
0000020 71 72 73 74 75 76 77 78 79 7a 0a >qrstuvwxyz.<
0000033
2.1.2.3 xxd
二进制查看命令,默认将二进制文件显示为十六进制字符串表示形式。
echo {a..z} | tr -d " " | xxd
00000000: 6162 6364 6566 6768 696a 6b6c 6d6e 6f70 abcdefghijklmnop
00000010: 7172 7374 7576 7778 797a 0a qrstuvwxyz.
2.2 分页查看文件内容
2.2.1 more
more 可以实现分页查看文件,可以配合管道实现输出信息的分页
格式:
more [options] ...
常用选项:
范例:
$ more -d /etc/passwd
$ more -d /etc/init.d/functions
2.2.2 less
less 也可以实现分页查看文件或者 STDIN 输出,less 命令是 man 命令使用的分页器
查看时有用的命令包括:
? | /文本 搜索 文本
n / N:跳到下一个 或者 上一个匹配
less 命令是 man 命令使用的分页器
范例:
$ less /etc/init.d/functions
$ cat /etc/init.d/functions | less
$ ls -lR /etc/ | less
2.3 显示文本前行或者后行的内容
2.3.1 head
head 可以显示文件或者标准输入的前面行
格式:
head [OPTION]... [FILE]...
常用选项:
范例:head的基本使用
# 查看 /etc/passwd 配置文件的前 3 行
$ head -n 3 /etc/passwd
$ head -n3 /etc/passwd
$ head -3 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
# "我" 占3个字节
$ echo a我b | head -c 5
a我b
# 查看倒数第3行之前的内容
$ head -n -3 seq.log
范例:生成随机口令
# 生成随机口令:取大小字母和数字(12位)
$ cat /dev/urandom | tr -dc "[[:alnum:]]" | head -c 12
$ cat /dev/urandom | tr -dc "[[:alnum:]]" | head -c 12
$ cat /dev/urandom | tr -dc [:alnum:] | head -c 12 | tee passwd.txt | passwd --stdin alice
Changing password for user alice.
passwd: all authentication tokens updated successfully.
$ cat passwd.txt
cIOxVg6816of
$ su alice
Password:
2.3.2 tail
tail 和 head 相反,查看文件和标准输入的倒数行
格式:
tail [OPTION]... [FILE]...
常用选项:
范例:
$ tail -n 3 /data/seq.log
$ tail -n -3 /data/seq.log
范例:
# /var/log/messages 记录系统的事件
# -F :跟踪文件名,相当于 --follow=name --retry,当文件删除再新建同名文件,将可以继续跟踪文件
$ tail -f /var/log/messages
May 9 08:36:50 centos-8-server systemd[2088]: Reached target Sockets.
May 9 08:36:50 centos-8-server systemd[2088]: Reached target Basic System.
May 9 08:36:50 centos-8-server systemd[2088]: Reached target Default.
# tailf 类似于 tail -f ,当文件不增长时并不访问文件(yum install -y util-linux)
$ echo "happy new year" >> hello.txt
$ tail -f hello.txt
hello
happy new year
$ ps -aux | grep "tail -f"
root 7160 0.0 0.0 7320 864 pts/0 S+ 15:06 0:00 tail -f hello.txt
$ ll /proc/7160/fd/
total 0
# (0,1,2,3,4)代表的是文件描述符
lrwx------ 1 root root 64 Jun 23 15:07 0 -> /dev/pts/0
lrwx------ 1 root root 64 Jun 23 15:07 1 -> /dev/pts/0
lrwx------ 1 root root 64 Jun 23 15:07 2 -> /dev/pts/0
lr-x------ 1 root root 64 Jun 23 15:07 3 -> /data/hello.txt
lr-x------ 1 root root 64 Jun 23 15:07 4 -> anon_inode:inotify
# 只查看最新发生的日志
$ tail -f -n0 /var/log/messages
$ tail -0f /var/log/messages
# 获取IP地址所在行
[09:03:26 root@centos-8-server data]#ifconfig | head -2 | tail -1
inet 10.0.0.250 netmask 255.255.255.0 broadcast 10.0.0.255
2.3.3 head 和 tail 的总结

范例:显示第 6 行
$ cat seq.log | head -n6 | tail -n1 == (cat seq.log | head -n-4 | tail -n1)
6
$ cat seq.log | tail -n+6 | head -n1 == (cat seq.log | tail -n5 | head -n1)
6
2.4 按列抽取文本cut
cut 命令可以提取文本文件或者 STDIN 数据的指定列
格式:
cut OPTION... [FILE]...
常用选项:
范例:
# 取当前文件列表的所有者和文件名
$ ls -l | tail -n +2 | tr -s " " : | cut -d ":" -f 3,10
# 取分区利用率
$ df | tail -n +2 | tr -s " " : | cut -d ":" -f 5 | tr -d %
$ df | tail -n +2 | tr -s " " % | cut -d "%" -f 5
$ df | tail -n +2 | cut -c44-46 (不推荐)
# 取网卡的IP地址
$ ifconfig eth0 | head -n2 | tail -n1 | tr -s " " : | cut -d":" -f 3
$ ifconfig eth0 | head -n2 | tail -n1 | cut -d" " -f10
$ cat /etc/passwd | cut -d":" -f1,3,7 --output-delimiter="---"
root---0---/bin/bash
bin---1---/sbin/nologin
$ echo {1..10} | cut -d" " --output-delimiter="+" -f1-10 | bc
2.5 合并多个文件 paste
paste 合并多个文件同行号的列到一行
格式:
paste [OPTION]... [FILE]...
常用选项:
范例:
$ seq 5 > a.txt
$ echo {a..e} | xargs -n1 > b.txt
# 横向的合并
$ paste a.txt b.txt
1 a
2 b
3 c
4 d
5 e
# 所有行合成一行显示
$ paste -s a.txt b.txt
1 2 3 4 5
a b c d e
$ paste -d "-" a.txt b.txt
1-a
2-b
3-c
4-d
5-e
$ paste -d "-" -s a.txt b.txt
1-2-3-4-5
a-b-c-d-e
范例:批量修改密码
$ cat > user.txt <<EOF
> admins
> gentoo
> EOF
$ cat > password.txt <<EOF
> Admin@h3c
> SZzhongaislf@123
> EOF
$ paste -d":" user.txt password.txt | chpasswd
2.6 分析文本的工具
2.6.1 收集文本统计数据 wc
wc 命令可用于统计文件的行总数,单词总数,字节总数和字符总数
可以对文件或者 STDIN 中的数据统计
常用选项:
范例:
$ cat user.txt
root
zzw
zhong zhi wei
$ wc user.txt
3 5 23 user.txt
# 行数 单词数(空格隔开就算一个单词) 字节数 文件名
# 统计文件的行数
$ wc -l user.txt
3 user.txt
$ cat user.txt | wc -l
3
$ cat -n user.txt
1 root
2 zzw
3 zhong zhi wei
$ df | tail -n$(echo `df | wc -l`-1 | bc)
范例:单词文件
$ yum provides /usr/share/dict/linux.words
$ yum install -y words
$ cat /usr/share/dict/linux.words | wc -l (wc -l /usr/share/dict/linux.words)
479828
范例:查看并打开文件类型为 data
# 查看文件类型
$ file btmp-34
btmp-34: data
# 打开文件类型 data 的内容
$ lastb -f btmp-34
2.6.2 文本排序 sort
把整理过的文本显示在 STDOUT,不改变原始文件
格式:
sort [OPTION]... [FILE]...
常用选项:
范例:
$ sort /etc/passwd
# 默认正序排列
$ sort -t: -k3 -n /etc/passwd
# -r:倒序排列
$ sort -t: -k3 -nr /etc/passwd
# 分区利用率
$ df | tail -n +2 |tr -s " " % | cut -d "%" -f 5 | sort -nr
$ df | tail -n +2 |tr -s " " % | cut -d "%" -f 5 | sort -nr | head -n1
# 统计日志访问量
$ cat /etc/passwd | cut -d":" -f1,3 | sort -t":" -k2 -nr
$ cut -d" " -f1 /var/log/nginx/access_log | sort -u | wc -l
范例:统计分区利用率
$ df
# 查看分区利用率最高的值
$ df | tail -n+2 | tr -s " " % | cut -d"%" -f 5 | sort -nr | head -n1
$ df | tr -s " " % | cut -d"%" -f 5 | tr -d "[:alpha:]" | sort -nr | head -n1
面试题:有两个文件,a.txt 与 b.txt ,合并两个文件,并输出时确保每个数字也唯一
# a.txt 中的每一个数字在本文件中唯一
$ seq 5 > a.txt
# b.txt 中的每一个数字在本文件中唯一
$ seq 8 > b.txt
# 就是将两个文件合并后重复的行去除,不保留
$ cat a.txt b.txt | sort -nr | uniq
2.6.3 去重 uniq
uniq 命令从输入中删除前后相接的重复的行
格式:
uniq [OPTION]... [FILE]...
常用选项:
uniq 常和 sort 命令一起配合使用
范例:
sort userlist.txt | uniq -c
范例:统计日志访问量最多的请求
# 取日志 IP 地址进行排序,并取其前三名
$ cut -d " " -f 1 access.log | sort | uniq -c | sort -nr | head -3
$ lastb -f btmp-34 | tr -s " " | cut -d " " -f 3 | sort |uniq -c | sort -nr | head -3
面试题:
# 找出两个文件相同的行,-d :仅显示重复过的行(--repeated)
cat a.txt b.txt | sort | uniq -d
# 找出两个不同的行,-u :仅显示不曾重复的行(--unique)
cat a.txt b.txt | sort | uniq -u
2.6.4 比较文件
2.6.4.1 diff
diff:比较给定的两个文件的不同
-u 选项来输出"统一的(unified)"diff 格式文件,最适用于补丁文件
范例:
$ diff a.txt b.txt
$ diff -u a.txt b.txt
--- a.txt 2022-05-13 11:34:41.586338504 +0800
+++ b.txt 2022-05-13 11:34:57.946451203 +0800
@@ -1,5 +1,5 @@
1
a
-2
+4
c
-3
+8
### diff 可以做校验备份
$ diff -u a.txt b.txt > diff.log
$ mv b.txt /data/
# 需要借助patch
$ patch -b a.txt diff.log
$ cat a.txt (b.txt变成了a.txt,后续需要改文件名)
$ cat a.txt.orig (a.txt.orig是之前a.txt的备份,后续需要改为原名)
2.6.4.2 patch
diff 命令的输出被保存在一种叫做 “补丁” 的文件中
使用 -u 选项 来输出 “统一的(unified)” diff 格式文件,最适合于补丁文件
patch :复制在其他文件中进行的改变(要谨慎使用)
使用 -b 选项来自动备份改变了的文件
范例:
diff -u foo.conf foo2.conf > foo.patch
patch -b foo.conf foo.patch
范例:使用 patch 命令备份还原文件
$ diff -u a.txt b.txt > diff.log
$ mv b.txt /data/
# 需要借助patch
# 使用 -b 选项来自动备份改变了的文件
$ patch -b a.txt diff.log
$ cat a.txt (b.txt变成了a.txt,后续需要改文件名)
$ cat a.txt.orig (a.txt.orig是之前a.txt的备份,后续需要改为原名)
2.6.4.3 vimdiff
相当于 vim -d
$ yum install -y vim-enhanced
$ vim -d a.txt b.txt
$ vimdiff a.txt b.txt

2.6.4.4 cmp
cmp命令 用来比较两个文件是否有差异。 当相互比较的两个文件完全一样时, 则该指令不会显示任何信息。 若发现有差异, 预设会标示出第一个不通之处的字符和列数编号。 若不指定任何文件名称或是所给予的文件名为“-”, 则cmp指令会从标准输入设备读取数据。
范例:查看二进制文件的不同
$ ls -li /bin/dir /bin/ls
8690804 -rwxr-xr-x. 1 root root 117608 Aug 20 2019 /bin/dir
8690825 -rwxr-xr-x. 1 root root 117608 Aug 20 2019 /bin/ls
$ diff /bin/dir /bin/ls
Binary files /bin/dir and /bin/ls differ
$ cmp /bin/dir /bin/ls
/bin/dir /bin/ls differ: byte 645, line 1
$ hexdump -s 645 -n 20 -C /bin/dir
00000285 a6 1a 14 51 10 be 66 62 a0 1c 2d 16 82 3d 92 6a |...Q..fb..-..=.j|
00000295 fe 5a 88 03 |.Z..|
00000299
$ hexdump -s 645 -n 20 -C /bin/ls
00000285 f0 56 15 b6 c9 1d 3c bb 07 6a f8 1a ef f5 31 c5 |.V....<..j....1.|
00000295 d7 df d9 03 |....|
00000299
2.6.5 练习
# 1、找出ifconfig “网卡名” 命令结果中本机的IPv4地址
# 2、查出分区空间使用率的最大百分比值
# 3、查出用户UID最大值的用户名、UID及shell类型
# 4、查出/tmp的权限,以数字方式显示
# 5、统计当前连接本机的每个远程主机IP的连接数,并按从大到小排序
# 1、找出ifconfig “网卡名” 命令结果中本机的IPv4地址
~ ifconfig eth0 | grep -i "mask" | tr -s " " | cut -d " " -f 3
~ ifconfig eth0 | head -n2 | tail -n1 | tr -s " " | cut -d " " -f 3
# 2、查出分区空间使用率的最大百分比值
~ df|grep -Eo "[0-9]+%"|sort -nr|head -n1
~ df|tail -n $(echo `df|wc -l`-1|bc)|tr -s " " :|cut -d ":" -f 5|sort -nr|head -n1
# 3、查出用户UID最大值的用户名、UID及shell类型
~ getent passwd|cut -d":" -f 1,3,7|sort -t : -k 2 -nr|head -n1
nobody:65534:/sbin/nologin
# 4、查出/tmp的权限,以数字方式显示
~ stat /tmp|grep "Access"|head -n1|cut -d"/" -f1|cut -d"(" -f2
~ stat /tmp|grep "Access"|head -n1|grep -Eo "[0-9]+"|head -n1
# 5、统计当前连接本机的每个远程主机IP的连接数,并按从大到小排序
~ netstat -antl|grep "ESTABLISHED"|tr -s " "|cut -d " " -f 5|cut -d":" -f 1|sort -nr|uniq -c
3 正则表达式
REGEXP: Regular Expressions, 由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意义,而表示控制或者通配的功能,类似于增强版的通配符功能。
正则表达式被很多程序和开发语言所广泛支持:vi,vim,less,grep,sed,awk,nginx,mysql等等。
正则表达式分为两类:
正则表达式引擎:
采用不同算法,检查处理正则表达式的软件模块,如:PCRE(Perl(Perl计算机开发语言) Compatible Regular Exporessions)
正则表达式的元字符分类:字符匹配,匹配次数,位置锚定,分组
帮助:man 7 regex
注意:文件通配符是用来匹配现有文件,并不是生成文件
正则表达式是用来匹配字符串
3.1 基本正则表达式元字符
3.1.1 字符匹配
### [] 中括号内的字符是原始属性,例如[.] 中的.就是. 没有任意的意思
# . :匹配任意单个字符
# []:匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z]
# [^]:匹配指定范围外的任意单个字符,示例:[^wang]
# [:alnum:]:字母和数字,示例:[[:alnum:]]
# [:digit:]:十进制数字,示例:[[:digit:]]
# [:punct:]:标点符号,示例:[[:punct:]]
# [:alpha:]:代表任何英文大小写字符,亦即 A-Z,a-z,示例:[[:alpha:]]
# [:graph:]:可打印的非空白字符,示例:[[:graph:]]
# [:space:]:水平和垂直的空白字符(比[:blank:]包含的范围广),示例:[[:space:]]
# [:blank:]:空白字符(空格和制表符),示例:[[:blank:]]
# [:lower:]:小写字母,示例:[[:lower:]] 相当于 [a-z]
# [:upper:]:大写字符,示例:[[:upper:]] 相当于 [A-Z]
# [:cntrl:]:不可打印的控制字符(退格,删除,警铃......)示例:[[:cntrl:]]
# [:print:]:可打印字符,示例:[[:print:]]
# [:xdigit:]:十六进制数字,示例:[[:xdigit:]]
范例:
# [] 中括号内的字符是原始属性
$ ls /etc | grep "rc[.0-6]"
# rc[.(原始属性)0-6].(任意字符)
$ ls /etc | grep "rc[.0-6]."
# rc[.(原始属性)0-6]\.(原始属性)
$ ls /etc | grep "rc[.0-6]\."
3.1.2 匹配次数
用在要指定次数的字符后面,用于指定前面的字符要出现的次数
# * :匹配前面的字符任意次,包括 0 次,贪婪模式:尽可能长的匹配
# .* :任意长度的任意字符
# \? :匹配其前面的字符的 0 或者 1 次,即:可有可无,懒惰模式
# \+ :匹配其前面的字符至少 1 次,即:肯定有
# \{n\} :匹配前面的字符 n 次
# \{m,n\} :匹配前面的字符至少 m 次,至多 n 次
# \{,n\} :匹配前面的字符至多 n 次
# \{n,\} :匹配前面的字符至少 n 次
范例:
$ echo /etc/ | grep "/etc/\?"
/etc/
$ echo /etc | grep "/etc/\?"
/etc
范例:
$ cat test.txt
google
goooooooooogle
ggle
gogle
gooo000ooogle
gooogle
$ grep "go\{2,\}gle" test.txt
google
goooooooooogle
$ grep "goo\+gle" test.txt
google
goooooooooogle
gooogle
$ grep "goo*gle" test.txt
google
goooooooooogle
gogle
$ grep "gooo*gle" test.txt
google
goooooooooogle
gooogle
范例:匹配正负数
$ echo -1 -2 123 -123 234 | grep "\-\?[0-9]\+"
-1 -2 123 -123 234
$ echo -1 -2 123 -123 234 | grep -E "\-?[0-9]+"
-1 -2 123 -123 234
$ echo -1 -2 123 -123 234 | grep -E -- "-?[0-9]+"
-1 -2 123 -123 234
$ echo -1 -2 123 -123 234 | grep -E "(-)?[0-9]+"
-1 -2 123 -123 234

范例:获取IP地址
$ ifconfig eth0|grep netmask|tr -s " " :|cut -d: -f 3
$ ifconfig eth0| grep netmask | grep -Eo "([0-9]{1,3}.){3}[0-9]{1,3}" | head -n1
$ ifconfig eth0| grep netmask | grep -o "\([0-9]\{1,3\}\.\)\{3\}[0-9]\{1,3\}" | head -n1
$ ifconfig eth0|grep "\" |grep -o "[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\[0-9]\{1,3\}"|head -n1
3.1.3 位置锚定
位置锚定可以用于定位出现的位置
# ^ :行首锚定,用于模式的最左侧
# $ :行尾锚定,用于模式的最右侧
# ^PATTERN$ :用于模式匹配整行
# ^$ :空行
# ^[[:space:]]*$ :空白行
# \< 或者 \b :词首锚定,用于单词模式的左侧
# \> 或者 \b :词首锚定,用于单词模式的右侧
# \ :匹配整个单词
# \w :匹配单词构成部分,等价于[_[:alnum:]]
# \W :匹配非单词构成部分,等价于[^_[:alnum:]]
### 注意:单词是由字母,数字,下划线组成(并且连续,例如:hello_123_world)
范例:
# 行首为root的行
$ grep "^root" /etc/passwd
# [^root]代表排除root字符
$ grep "[^root]" /etc/passwd
$ grep -v "^#" /etc/fstab
### [^#] 代表一个字符(可以是任意字符)
$ grep "^[^#]" /etc/fstab
UUID=9cff3d69-3769-4ad9-8460-9c54050583f9 / xfs defaults 0 0
LABEL=YUNIFYSWAP swap swap defaults 0 0
$ grep "bash$" /etc/passwd
## 测试:搜索只包含google字符串的行
$ cat test.txt
google
abc google xyz
gooogle
# 需要位置锚定
$ grep "^google$" test.txt
google
$ grep -n "^[[:space:]]*$" test.txt
$ echo hello-123 | grep "\<123\>"
$ echo hello:123:world | grep "\"
范例:排除掉空行和 # 开头的行
$ grep -v "^#" /etc/profile | grep -v "^$"
$ grep "^[^$#]" /etc/profile
3.1.4 分组其他
3.1.4.1 分组
分组:() 将一个或者多个字符捆绑在一起,当作一个整体处理,如:(root)+;支持嵌套的操作
分组括号中的模式匹配的内容会被正则表达式引擎记录与内部的变量中,这些变量的命名方式为:\1,\2,\3,……
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
示例:
\(string1\(string2\)\)
\1 : string1\(string2\)
\2 : string2
& : 可以表示 \(string1\(string2\)\) 的所有内容
后向引用:引用前面的分组括号中的模式所匹配字符,而非模式本身
范例:
$ echo abcabcabc abccc | grep "abc\{3\}"
abcabcabc abccc
$ echo abcabcabc abccc | grep "\(abc\)\{3\}"
abcabcabc abccc
范例:排除掉空行和 # 开头的行
$ cat /etc/fstab | grep -v "^\(#\|$\)"
$ cat /etc/fstab | grep -Ev "^(#|$)"
3.1.4.2 或者
或者:|
示例:
a \| b # a 或者 b
C \| cat # C 或者 cat
\(C\|c\)at # Cat 或者 cat
范例:
$ echo 1 2 3 | grep "1\|2"
1 2 3
$ echo 1abc 2abc | grep "\(1\|2\)abc"
1abc 2abc
# 取网卡IP地址
$ ifconfig eth0|grep "\" |grep -o "\([0-9]\{1,3\}\.\)\{3\}[0-9]\{1,3\}"|head -n1
3.1.5 正则表达式练习:
# 1、显示/proc/meminfo文件中以大小s开头的行(要求:使用两种方法)
# 2、显示/etc/passwd文件中不以/bin/bash结尾的行
# 显示了/etc/passwd文件中以/bin/bash结尾的行
# 显示了/etc/passwd文件中不以/bin/bash结尾的行
# 3、显示用户rpc默认的shell程序
# 4、找出/etc/passwd中的两位或三位数
# 5、显示CentOS7的/etc/grub2.cfg文件中,至少以一个空白字符开头的且后面有非空白字符的行
# 6、找出“netstat -tan”命令结果中以LISTEN后跟任意多个空白字符结尾的行
# 7、显示CentOS7上所有UID小于1000以内的用户名和UID
# 8、添加用户bash、testbash、basher、sh、nologin(其shell为/sbin/nologin),找出/etc/passwd用户名和shell同名的行(未完成)
# 9、利用df和grep,取出磁盘各分区利用率,并从大到小排序
# 1、显示/proc/meminfo文件中以大小s开头的行(要求:使用两种方法)
~ cat /proc/meminfo | grep -i "^s"
~ grep -i "^s" /proc/meminfo
# 2、显示/etc/passwd文件中不以/bin/bash结尾的行
# 显示了/etc/passwd文件中以/bin/bash结尾的行
# (1)
~ cat /etc/passwd |grep -v "/bin/bash$"
# (2)
~ cat /etc/passwd |grep "/bin/bash$"
# 3、显示用户rpc默认的shell程序
~ cat /etc/passwd | grep "\" |cut -d ":" -f 7
# 4、找出/etc/passwd中的两位或三位数
~ cat /etc/passwd | grep -o "\<[0-9]\{2,3\}\>"
~ cat /etc/passwd | grep "\<[0-9]\{2,3\}\>"
# 5、显示CentOS7的/etc/grub2.cfg文件中,至少以一个空白字符开头的且后面有非空白字符的行
~ cat /etc/grub2.cfg | grep -E "^[[:space:]]+[^[:space:]].*"
# 6、找出“netstat -tan”命令结果中以LISTEN后跟任意多个空白字符结尾的行
~ netstat -tan|grep "LISTEN[[:space:]]*$"
# 7、显示CentOS7上所有UID小于1000以内的用户名和UID
~ cat /etc/passwd |cut -d ":" -f 1,3|grep "\<[0-9]\{1,3\}\>"
# 8、添加用户bash、testbash、basher、sh、nologin(其shell为/sbin/nologin),找出/etc/passwd用户名和shell同名的行
~ for NAME in {bash,testbash,bsaher,sh}; do useradd $NAME; done
~ useradd -s /sbin/nologin nolgin
~ grep "^\([^:]\+\):.*/\1$" /etc/passwd
~ cat /etc/passwd |grep "^\([^:]\+\):.*\1$"
# 9、利用df和grep,取出磁盘各分区利用率,并从大到小排序
~ df |grep -o "[0-9]\+%" |grep -o "[0-9]\+"|sort -nr
3.2 扩展正则表达式
3.2.1 字符匹配
# . :匹配任意单个字符
# []:匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z]
# [^]:匹配指定范围外的任意单个字符,示例:[^wang]
# [:alnum:]:字母和数字,示例:[[:alnum:]]
# [:digit:]:十进制数字,示例:[[:digit:]]
# [:punct:]:标点符号,示例:[[:punct:]]
# [:alpha:]:代表任何英文大小写字符,亦即 A-Z,a-z,示例:[[:alpha:]]
# [:graph:]:可打印的非空白字符,示例:[[:graph:]]
# [:space:]:水平和垂直的空白字符(比[:blank:]包含的范围广),示例:[[:space:]]
# [:blank:]:空白字符(空格和制表符),示例:[[:blank:]]
# [:lower:]:小写字母,示例:[[:lower:]] 相当于 [a-z]
# [:upper:]:大写字符,示例:[[:upper:]] 相当于 [A-Z]
# [:cntrl:]:不可打印的控制字符(退格,删除,警铃......)示例:[[:cntrl:]]
# [:print:]:可打印字符,示例:[[:print:]]
# [:xdigit:]:十六进制数字,示例:[[:xdigit:]]
3.2.2 次数匹配
# * :匹配前面的字符任意次,包括 0 次,贪婪模式:尽可能长的匹配
# .* :任意长度的任意字符
# ? :匹配其前面的字符的 0 或者 1 次,即:可有可无
# + :匹配其前面的字符至少 1 次,即:肯定有
# {n} :匹配前面的字符 n 次
# {m,n} :匹配前面的字符至少 m 次,至多 n 次
# {,n} :匹配前面的字符至多 n 次
# {n,} :匹配前面的字符至少 n 次
3.2.3 位置锚定
# ^ :行首锚定,用于模式的最左侧
# $ :行尾锚定,用于模式的最右侧
# ^PATTERN$ :用于模式匹配整行
# ^$ :空行
# ^[[:space:]]*$ :空白行
# \< 或者 \b :词首锚定,用于单词模式的左侧
# \> 或者 \b :词首锚定,用于单词模式的右侧
# \ :匹配整个单词
3.2.4 分组其他
() 分组
后向引用:\1 , \2 ,……
| 或者
a | b # a 或者 b
C | cat # C 或者 cat
(C|a)at # Cat 或者 cat
\(string1\(string2\)\)
\1 : string1\(string2\)
\2 : string2
& : 可以表示 \(string1\(string2\)\) 的所有内容
范例:
$ ifconfig eth0|grep "\" |grep -Eo "([0-9]{1,3}\.){3}[0-9]{1,3}"|head -n1
# 取QQ邮箱
$ cat mail.com | grep "[[:alnum:]]\+\@qq.com"
$ cat mail.com | grep "[[:alnum:]]\+\@[[:alnum:]]\+\.com"
$ cat mail.com | grep "[[:alnum:]_]\+\@[[:alnum:]]\+\.com"
$ cat mail.com | grep "\<[[:alnum:]_]\+\@[[:alnum:]]\+\.com\>"
[email protected]
935523993@qq.com
15118013447@163.com
[email protected]
3.2.5 扩展正则表达式练习
# 1、显示三个用户root、mage、wang的UID和默认shell
# 2、找出/etc/rc.d/init.d/functions文件中行首为某单词(包括下划线)后面跟一个小括号的行
# 3、使用egrep取出/etc/rc.d/init.d/functions中其基名
# 4、使用egrep取出上面路径的目录名
# 5、统计last命令中以root登录的每个主机IP地址登录次数
# 6、利用扩展正则表达式分别表示0-9、10-99、100-199、200-249、250-255
# 7、显示ifconfig命令结果中所有IPv4地址
# 8、将此字符串:welcome to magedu linux 中的每个字符去重并排序,重复次数多的排到前面
# 1、显示三个用户root、mage、wang的UID和默认shell
~ cat /etc/passwd| grep -E "^root|^mage|^wang" |cut -d":" -f3,7
# 2、找出/etc/rc.d/init.d/functions文件中行首为某单词(包括下划线)后面跟一个小括号的行
~ cat /etc/rc.d/init.d/functions |grep -E "^[[:alpha:]]+\_?[[:alpha:]]+\(\)"
# 3、使用egrep取出/etc/rc.d/init.d/functions中其基名
~ basename /etc/rc.d/init.d/functions
~ echo "/etc/rc.d/init.d/functions"|egrep -o "[a-zA-Z0-9]+\$"
# 4、使用egrep取出上面路径的目录名
~ echo "/etc/rc.d/init.d/functions"|egrep -o "^/[a-zA-Z].*\/+"
# 5、统计last命令中以root登录的每个主机IP地址登录次数
~ last |grep "root"|grep -Eo "([0-9]{1,3}\.){3}[0-9]{1,3}"|sort -nr|uniq -c
~ last |grep -Eo "([0-9]{1,3}\.){3}[0-9]{1,3}"|sort -nr|uniq -c
# 6、利用扩展正则表达式分别表示0-9、10-99、100-199、200-249、250-255
~ echo {0..255}|xargs -n1 > test.txt
~ cat test.txt |grep -E "\<[0-9]\>" (cat test.txt | grep -E ^[0-9]\{1\}$)
~ cat test.txt |grep -E "\<[1-9][0-9]\>" (cat test.txt | grep -E ^[1-9]\{1\}[0-9]$)
~ cat test.txt |grep -E "\<1[0-9][0-9]\>" (cat test.txt | grep -E ^1[0-9]\{2\}$)
~ cat test.txt |grep -E "\<2[0-4][0-9]\>" (cat test.txt | grep -E ^2[0-4][0-9]$)
~ cat test.txt |grep -E "\<25[0-5]\>" (cat test.txt | grep -E ^25[0-5]$)
# 7、显示ifconfig命令结果中所有IPv4地址
~ ifconfig |grep -Eo "([0-9]{1,3}\.){3}[0-9]{1,3}"
# 8、将此字符串:welcome to magedu linux 中的每个字符去重并排序,重复次数多的排到前面
~ echo "welcome to magedu linux"|grep -Eo "."|sort -r|uniq -c|sort -nr
~ echo "welcome to magedu linux"|grep -Eo "[a-z]"|sort -r|uniq -c|sort -nr
4 文本处理三剑客
4.1 文本处理三剑客之 grep
grep:Global search REgular expression and Print out the line
作用:文本搜索工具,根据用户指定的“模式对目标文本逐行进行匹配检查”,打印匹配到的行
模式:由正则表达式字符及文本字符所编写的过滤条件
格式:
grep [OPTION]... PATTERN(模式:支持正则表达式) [FILE]...
常用选项:
范例:基本用法
grep root /etc/passwd
grep "USER" /etc/passwd
grep 'USER' /etc/passwd
grep whoami /etc/passwd
范例:相关操作
# 取分区利用率最大值
~ df | grep /dev/sd | tr -s " " % | cut -d % -f 5 | sort -nr | head -n 1
~ df | grep /dev/sd | tr -s " " % | cut -d % -f 5 | sort -n | tail -n 1
# 取 ss -nt 远程连接主机数和连接数
~ ss -nt | grep ^ESTAB | tr -s " " : | cut -d : -f 6 | sort -nr | uniq -c
1 10.0.0.40
1 10.0.0.20
4 10.0.0.1
# 过滤 /etc/profile 文件信息
# 方法一:
~ cat /etc/profile | grep -v "^#" | grep -v "^$"
# 方法二:
~ cat /etc/profile | grep -v "^#\|^$"
# 方法三:
~ cat /etc/profile | grep -v "^\(#\|$\)"
# 使用扩展正则表达式
~ cat /etc/profile | grep -Ev "^(#|$)"
~ cat /etc/profile | egrep -v "^(#|$)"
# 使用 grep 搜索 s 或者 t 开头的行
~ grep "^\(s\|t\)" /etc/passwd
~ grep "^[st]" /etc/passwd
# 使用 grep -v 选项(显示不被 pattern 匹配到的行)
~ grep -v "^\(s\|t\)" /etc/passwd
~ grep -v "^#" /etc/fstab
~ grep -v "^\(#\|$\)" /etc/fstab
# 使用 grep -in(显示忽略大小写以及匹配的行号)
# -i :忽略字符大小写
# -n :显示匹配的行号
~ cat /etc/passwd | grep -i ROOT
~ cat /etc/passwd | grep -in ROOT
~ grep -vn "^\(#\|$\)" /etc/profile
# 使用 grep -o(仅仅显示匹配到的字符串)
~ cat passwd | grep -no "r..t" passwd
~ ifconfig | grep netmask | grep -o "\([0-2]\?[0-9]\+\.\)\{3\}[0-2]\?[0-9]\+"
~ ifconfig | grep -o '[0-9]\{1,3\}\.[0-9]\{1,3\}.[0-9]\{1,3\}.[0-9]\{1,3\}'
# 范例:取 ifconfig 中的 IP 地址
~ ifconfig | grep -o "\([0-9]\{1,3\}.\)\{3\}[0-9]\{1,3\}" | head -1
~ ifconfig | grep netmask | grep -o "\([0-2]\?[0-9]\+\.\)\{3\}[0-2]\?[0-9]\+"
~ ifconfig | grep netmask | grep -o "\([0-2]\?[0-9]\{1,2\}\.\)\{3\}[0-2]\?[0-9]\{1,2\}"
~ ifconfig | grep -Eo "([0-9]{1,3}.){3}[0-9]{1,3}" | head -n 1
grep -e "r..t" /etc/passwd
grep -E "root|bash" /etc/passwd
grep -e "root" -e "bash" /etc/passwd
# 哪个IP和当前主机地址链接数最多的主机和次数
~ ss -nt | grep -v "^State" | tr -s " " : | cut -d":" -f6 |sort -nr | uniq -c
范例:连接状态的统计
~ ss -ant | grep -v '^State' | cut -d " " -f1 | sort -nr | uniq -c
~ ss -ant | tail -n +2 | cut -d " " -f1 | sort -nr | uniq -c
范例:/etc/passwd中用户名和 shell 名相同的行
~ grep "^\(.*\)\>.*\<\1$" /etc/passwd
~ grep -E "^(.*)\>.*\<\1$" /etc/passwd
~ egrep "^(.*)\>.*\<\1$" /etc/passwd
~ grep -E "^(.*):x:.*\<(\1)$" /etc/passwd
面试题:算出所有人的年龄总和
➜ ~ tee > age.txt <<-'EOF'
xiaoming=20
xiaohong=18
xiaoqiang=22
EOF
➜ ~ cat age.txt | cut -d "=" -f 2 | tr "\n" + | cut -d "+" -f -3 | bc
➜ ~ cut -d "=" -f2 age.txt | tr "\n" + | grep -Eo ".*[0-9]" |bc
➜ ~ grep -Eo "[0-9]+" age.txt | tr "\n" + | grep -Eo ".*[0-9]" | bc
➜ ~ grep -Eo "[0-9]+" age.txt | paste -s -d "+" | bc
4.2 文本处理三剑客之 sed
官网:http://sed.sourceforge.net/
4.2.1 sed 工作原理
帮助参考官网:http://www.gnu.org/software/sed/manual/sed.html
sed 即 Stream EDitor(流编辑器),和 vi 不同,sed 是行编辑器
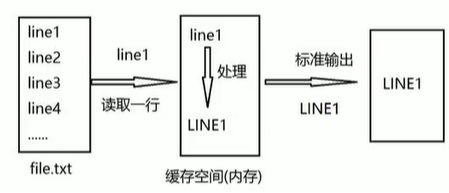
Sed 是从文件或者管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。
每当处理一行时,把当前处理的行存储再临时缓存区中,称为模式空间(Pattern Space),接着用 sed 命令来处理。
缓存区中的内容,处理完成后,把缓存区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。一次处理一行的设计模式使得 sed 性能很高,sed 在读取大文件时不会出现卡顿的现象。如果使用 vi 命令打开几十M上百M的文件,明显会出现卡顿的现象,这是因为 vi 命令打开文件是一次性将文件加载到内存,然后再打开。 Sed 就避免了这种情况,一行一行的处理,打开速度非常快,执行速度也很快。
sed 命令完全可以替代 grep 命令的使用
4.2.2 sed 基本用法
格式:
Usage: sed [OPTION]... {script-only-if-no-other-script} [input-file]...
常用选项:
说明:
-ir 不支持
-ri & -r -i 支持
script 格式:
‘地址命令’
地址命令"
地址命令:
1.不给地址:全全文进行处理
2.单地址:
#:指定的行,$:最后一行
/pattern/:被此处模式所能够匹配到的每一行
3.地址范围:
#,# # 从#行到第#行,3,6 表示从第3行到第6行
#,+# # 从#行到+#行,3,+4行,表示从第3行到第7行
/pat1/,/pat2/
#,/pat/
/pat/,#
4.步进:~
1~2 奇数行(1:从第一行开始)
2~2 偶数行(2:从第二行开始)
命令:
#基本用法
p :打印当前模式空间内容,追加到默认输出之后
Ip:忽略大小写输出
d :删除模式空间匹配的行,并立即启用下一轮循环
a []text :在指定行后面追加文本,支持使用\n实现多行追加
i []text :在行前面插入文本
c []text :替换行为单行或多行文本
w /path/file :保存模式匹配的行至指定文件
r /path/file :读取指定文件的文本至模式空间中匹配到的行后
= :为模式空间中的行打印行号
! :模式空间中匹配行取反处理
q:结束或者退出sed
#查看替换
s/pattern/string/修饰符 :查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s###
替换修饰符:
g :行内全局替换
p :显示替换成功的行
w :/PATH/FILE 将替换成功的行保存至文件中
I,i :忽略大小写
范例:
➜ ~ sed ''
welcome to kubesphere
welcome to kubesphere
➜ ~ sed '' /etc/issue
\S
Kernel \r on an \m
➜ ~ sed 'p' /etc/issue
\S
\S
Kernel \r on an \m
Kernel \r on an \m
➜ ~ sed -n '' /etc/issue
➜ ~ sed -n 'p' /etc/issue
\S
Kernel \r on an \m
➜ ~ sed -n '1p' /etc/passwd
root:x:0:0:root:/root:/bin/zsh
➜ ~ ifconfig eth0 | sed -n '2p'
inet 10.150.22.47 netmask 255.255.255.0 broadcast 10.150.22.255
➜ ~ sed -n '$p' /etc/passwd
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
# 倒数第二行
➜ ~ sed -n "$(echo $[ $(cat /etc/passwd | wc -l)-1 ])p" /etc/passwd
mage:x:1011:1011::/home/mage:/bin/bash
➜ ~ ifconfig eth0 | sed -n '/netmask/p'
inet 10.150.22.47 netmask 255.255.255.0 broadcast 10.150.22.255
➜ ~ ifconfig eth0 | sed -nr '2s@.* inet ([0-9].+).*netmask.*@\1@p'
➜ ~ sed -ri.bak -e 's@Listen 80@Listen 8080@ig' -e 's@^#(ServerName.*)@\1@ig' /etc/httpd/conf/httpd.conf
# 删除所有以 # 开头的行
➜ ~ sed -ri.bak '/^#/d' fstab
# 只显示非 # 开头的行
➜ ~ sed -nr '/^#/!p' /etc/fstab
# 修改网卡的配置
➜ ~ sed -Ei.bak '/GRUB_CMDLINE_LINUX/s/(.*)(")$/\1 net .ifnames=0\2/' /etc/default/grub
范例:将非 # 开头的行加#
➜ ~ sed -nr 's@^[^#]@#&@p' fstab
➜ ~ sed -nr '/^#/!s@(.*)@#\1@p' fstab
范例:将# 开头的行删除#
➜ ~ sed -nr 's@(# )(.*)@\2@p' fstab
➜ ~ sed -nr '/^#/s@^#@@p' fstab
# 可以排除行首后加多个空白符之后有 # 这种行
sed -n '/^$/d;/^[[:space:]]^#/!p' /etc/httpd/conf/httpd.conf
sed -n -e '/^$/d' -e '/^[[:space:]]*#/!p' /etc/httpd/conf/httpd.conf
# 注意:以下能前后顺序不同,执行的效果不同
sed -n '/^[[:space:]]*#/!p;/^$/d' /etc/httpd/conf/httpd.conf
sed -n '/^[[:space:]]*#/!p' -e '/^$/d' /etc/httpd/conf/httpd.conf
范例:取分区利用率
➜ ~ df | sed -nr '/\/dev\//s@.* ([0-9]+)%.*@\1@p'
范例:修改内核参数
➜ ~ sed -Ei.bak '/GRUB_CMDLINE_LINUX/s/(.*)(")$/\1 net .ifnames=0\2/' /etc/default/grub
➜ ~ sed -rn '/^GRUB_CMDLINE_LINUX=/s@(.*)"$@\1 net.ifnames=0"@p' /etc/default/grub
➜ ~ sed -rn '/^GRUB_CMDLINE_LINUX=/s@"$@ net.ifnames=0"@p' /etc/default/grub
范例:修改网卡名称
# CentOS7,8
sed -i '/GRUB_CMDLINE_LINUX=/s#quiet#& net.ifnames=0#' /etc/default/grub
sed -ri '/^GRUB_CMDLINE_LINUX=/s@"$@ net.ifnames=0"@' /etc/default/grub
grub2-mkconfig -o /boot/grub2/grub.cfg
# Ubuntu
grub-mkconfig -o /boot/grub/grub.cfg
范例:查看配置文件
# 过滤掉空行和#开头的行
sed -r '/^(#|$)/d' /etc/httpd/conf/httpd.conf
范例:将/etc/passwd中 r…t 改为 r…ter
# sed 中 & 是占位符
~ cat /etc/passwd | sed -nr '[email protected]@&er@igp'
# sed 中分组
~ cat /etc/passwd | sed -nr 's@(r..t)@\1er@igp'
范例:修改CentOS操作系统网卡名为 eth0
~ sed -i.bak -r '/^GRUB_CMDLINE_LINUX=/s@(.*)"$@\1 net.ifnames=0"@ig' grub
~ sed -i.bak -r '/^GRUB_CMDLINE_LINUX=/s@"$@ net.ifnames=0"@ig' grub
# CentOS系统启动grub配置
~ grub2-mkconfig -o /boot/grub2/grub.cfg ; reboot
# Ubuntu系统启动grub配置
~ grub-mkconfig -o /boot/grub/grub.cfg ; reboot
# CentOS网卡eth0配置
~ vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
NAME="eth0"
BOOTPROTO="static"
ONBOOT="yes"
IPADDR="10.0.0.200"
PREFIX="24"
GATEWAY="10.0.0.2"
DNS1="114.114.114.114"
DNS2="8.8.8.8"
范例:引用变量
~ echo | sed "s@^@$RANDOM.rmvb@"
~ echo | sed 's@^@'$RANDOM'.rmvb@'
~ echo | sed 's@^@'''$RANDOM'''.rmvb@'
范例:sed 使用变量修改文件
~ port=8080
~ sed -i.bak -r -e '/^Listen/s@(.*) (.*)@\1 '$port'@ig' -e '/#ServerName /s@#(.*) (.*)@\1 '$HOSTNAME':'$port'@ig' /etc/httpd/conf/httpd.conf
范例:显示前 5 行
seq 10 | sed '5q'
4.2.3 sed 高级用法
sed 中除了模式空间(Pattern Space),还有另外还支持保持空间(Hold Space),利用此空间,可以将模式空间中的数据,临时保存至保持空间,从而后续接着处理,实现更为强大的功能。
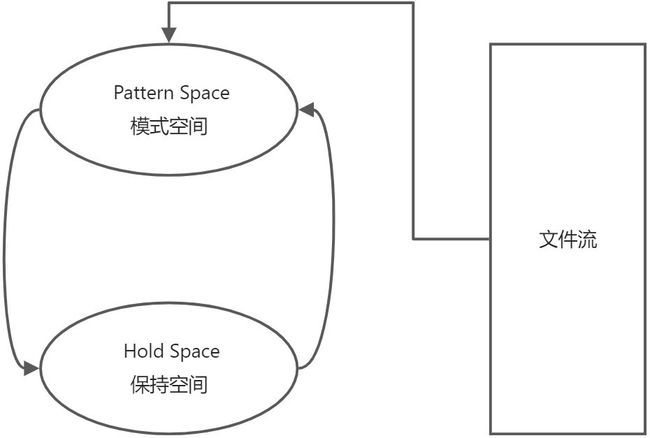
常见的高级命令:
sed -n ‘n;p’ FILE
seq 10 | sed ‘N;s/\n//’
seq 10 | sed ‘N;s/\n/’ & seq 10 | sed ‘N;s/\n/\t/’
sed ‘1!G;h;KaTeX parse error: Expected 'EOF', got '#' at position 43: …3/{g;1!p;};h' #̲ 前一行 seq 10 | s…!N; ! D ′ F I L E s e d ′ !D' FILE sed ' !D′FILEsed′!d’ FILE
sed ‘G’ FILE
sed ‘g’ FILE
sed ‘/^ / d ; G ′ F I L E s e d ′ n ; d ′ F I L E s e d − n ′ 1 ! G ; h ; /d;G' FILE sed 'n;d' FILE sed -n '1!G;h; /d;G′FILEsed′n;d′FILEsed−n′1!G;h;p’ FILE
范例:
# sed -n 'n;p' FILE
## 只打印偶数行
seq 10 | sed -n 'n;p' &
seq 10 | sed -n '2~2p' &
seq 10 | sed '1~2d' &
seq 10 | sed -n '1~2!p'
4.2.4 练习
# 1、删除centos7系统/etc/grub2.cfg文件中所有以空白开头的行行首的空白字符
# 2、删除/etc/fstab文件中所有以#开头,后面至少跟一个空白字符的行的行首的#和空白字符
# 3、在centos6系统/root/install.log每一行行首增加#号
# 4、在/etc/fstab文件中不以#开头的行的行首增加#号
# 5、处理/etc/fstab路径,使用sed命令取出其目录名和基名
# 6、利用sed 取出ifconfig命令中本机的IPv4地址
# 7、统计centos安装光盘中Package目录下的所有rpm文件的以.分隔倒数第二个字段的重复次数
# 8、统计/etc/init.d/functions文件中每个单词的出现次数,并排序(用grep和sed两种方法分别实现)
# 9、将文本文件的n和n+1行合并为一行,n为奇数行
# 1、删除centos7系统/etc/grub2.cfg文件中所有以空白开头的行行首的空白字符
➜ ~ cat /etc/grub2.cfg | sed -nr 's@[[:space:]]+(.*)$@\1@p'
➜ ~ cat /etc/grub2.cfg | sed -i.bak -r 's@[[:space:]]+(.*)$@\1@ig'
# 2、删除/etc/fstab文件中所有以#开头,后面至少跟一个空白字符的行的行首的#和空白字符
➜ ~ sed -nr 's@^#[[:space:]]+(.*$)@\1@p' /etc/fstab
➜ ~ sed -i.bak -r 's@^#[[:space:]]+(.*$)@\1@ig' /etc/fstab
# 3、在centos6系统/root/install.log每一行行首增加#号
➜ ~ cat /root/install.log | sed -nr 's@.*@#&@p'
➜ ~ cat age.txt|sed -nr 's@(.*)@#\1@p'
➜ ~ cat /root/install.log | sed -i.bak -r 's@.*@#&@ig'
# 4、在/etc/fstab文件中不以#开头的行的行首增加#号
➜ ~ sed -i.bak -r '/^[^#]/s@(.*)@#\1@ig' fstab
➜ ~ sed -i.bak -r '/^[^#]/s@.*@#&@ig' fstab
# 5、处理/etc/fstab路径,使用sed命令取出其目录名和基名
# 取路径的目录名
echo "/etc/fstab" | sed -nr 's@(.*)/([^/]+)@\1@p'
# 取路径的基名
echo "/etc/fstab" | sed -nr 's@(.*)/([^/]+)@\2@p'
# 6、利用sed 取出ifconfig命令中本机的IPv4地址
➜ ~ ifconfig eth0 | sed -nr '2s@.*inet ([0-9].*).*netmask.*@\1@p'
# 7、统计centos安装光盘中Package目录下的所有rpm文件的以.分隔倒数第二个字段的重复次数
➜ ~ ls /misc/cd/Packages | grep rpm | rev | cut -d "." -f2 | rev | sort -nr | uniq -c
➜ ~ ls /misc/cd/Packages | grep rpm | sed -nr 's@(.*)\.(.*).rpm$@\2@p' | sort -nr | uniq -c
# 8、统计/etc/init.d/functions文件中每个单词的出现次数,并排序(用grep和sed两种方法分别实现)
➜ ~ cat /etc/init.d/functions | grep -Eo "[a-Z]+" | sort -nr | uniq -c | sort -nr
➜ ~ cat /etc/init.d/functions | grep -Eo "[a-z]+" | sort | uniq -c | sort -nr
➜ ~ sed -nr 's@[^[:alpha:]]+@\n@gp' /etc/init.d/functions | sed '/^$/d' | sort | uniq -c | sort -nr
# 9、将文本文件的n和n+1行合并为一行,n为奇数行
➜ ~ cat /etc/passwd | sed -r 'N;s@\n@ @'
4.3 文本处理三剑客之 awk
4.3.1 awk 工作原理和基本用法说明
awk:Aho,Weinberger,Kernighan,报告生成器,格式化文本输出,GNU/Linux发布的AWK目前由自由软件基金会(FSF)进行开发和维护,通常也称为 GNU AWK
有多种版本:
gawk:模式扫描和处理语言,可以实现下面功能
格式:
awk [options] ‘program’ var=value file…
awk [options] -f programfile var=value file…
awk [options] ‘BEGIN{ action ;… } pattern{ action ;… } END{ action;… }’ file…
说明:
program 通常是被放在单引号中,并可以由三种部分组成
常见选项:
- -F fs or --field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。 - -v var=value or --asign var=value
赋值一个用户定义变量。 - -f scripfile or --file scriptfile
从脚本文件中读取awk命令。 - -mf nnn and -mr nnn
对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。 - -W compact or --compat, -W traditional or --traditional
在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。 - -W copyleft or --copyleft, -W copyright or --copyright
打印简短的版权信息。 - -W help or --help, -W usage or --usage
打印全部awk选项和每个选项的简短说明。 - -W lint or --lint
打印不能向传统unix平台移植的结构的警告。 - -W lint-old or --lint-old
打印关于不能向传统unix平台移植的结构的警告。 - -W posix
打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符和=不能代替和=;fflush无效。 - -W re-interval or --re-inerval
允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。 - -W source program-text or --source program-text
使用program-text作为源代码,可与-f命令混用。 - -W version or --version
打印bug报告信息的版本。
Program 格式:
porgram:pattern {action statements ;...}
awk 'pattern{action}' file
pattern 和 action:
awk 工作过程
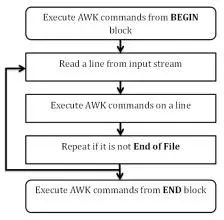
第一步:执行 BEGIN{ action ;… } 语句块中的语句
第二步:从文件或者标准输入(stdin)读取一行,然后执行 pattern{ action ;… }语句块,它逐行扫描文件,从第一行到最后一行重复这个流程,知道文件全部被读取完毕
第三步:当读至输入流末尾时,执行 END{ action ;… } 语句块
BEGIN 语句块在 awk 开始从输入流中读取行之前被执行,这个一个可选择的语句块,比如变量初始化,打印输出表格的表头等语句通常可以写在 BEGIN 语句块中
END 语句块在 awk 从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在 END 语句块中完成,它也是一个可选择语句块
pattern 语句块中的通用命令时最重要的部分,也是可选择的,如果没有提供 pattern 语句块,则默认执行 { print },即打印每一个读取到的行,awk 读取的每一行都是会执行该语句块
分割符、域和记录
常用的 action 分类
awk 控制语句
4.3.2 动作 print
格式:
print item1, item2, ...
说明:
4.3.3 awk 变量
awk 中的变量分为:内置和自定义变量
4.3.3.1 常见的内置变量
| 变量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由FS分隔 |
| $0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| ARGIND | 命令行中当前文件的位置(从0开始算) |
| ARGV | 包含命令行参数的数组 |
| CONVFMT | 数字转换格式(默认值为%.6g)ENVIRON环境变量关联数组 |
| ERRNO | 最后一个系统错误的描述 |
| FIELDWIDTHS | 字段宽度列表(用空格键分隔) |
| FILENAME | 当前文件名 |
| FNR | 各文件分别计数的行号 |
| FS | 字段分隔符(默认是任何空格) |
| IGNORECASE | 如果为真,则进行忽略大小写的匹配 |
| NF | 一条记录的字段的数目 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| OFMT | 数字的输出格式(默认值是%.6g) |
| OFS | 输出字段分隔符,默认值与输入字段分隔符一致。 |
| ORS | 输出记录分隔符(默认值是一个换行符) |
| RLENGTH | 由match函数所匹配的字符串的长度 |
| RS | 记录分隔符(默认是一个换行符) |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| SUBSEP | 数组下标分隔符(默认值是/034) |
- FS(Field Separator):输入字段分隔符, 默认为空白字符
- OFS(Out of Field Separator):输出字段分隔符, 默认为空白字符
- RS(Record Separator):输入记录分隔符(输入换行符), 指定输入时的换行符
- ORS(Output Record Separate):输出记录分隔符(输出换行符),输出时用指定符号代替换行符
- NF(Number for Field):当前行的字段的个数(即当前行被分割成了几列)
- NR(Number of Record):行号,当前处理的文本行的行号。
- FNR:各文件分别计数的行号
- ARGC:命令行参数的个数
- ARGV:数组,保存的是命令行所给定的各参数
FS:输入字段分隔符,默认为空白字符,功能相当于 -F
范例:
OFS:输出字段分隔符,默认是空白字符
范例:
RS:输入记录分隔符,指定输入时的换行符
范例:
ORS:输出记录分隔符,输出时用指定符号代替换行符
范例:
NF:字段数量
范例:
NR:记录编号
范例:
FNR:各文件分别计数,记录号
范例:
FILENAME:当前文件名
范例:
ARGC:命令行参数的个数
范例:
ARGV:数组,保存的是命令行所给定的各参数
范例:
4.3.3.2 自定义变量
范例:
4.3.4 动作 printf
printf 可以实现格式化输出
格式:
4.3.5 操作符
4.3.6 模式 PATTERN
4.3.7 条件判断 if-else
4.3.8 条件判断 switch
4.3.9 循环 while
语法:while(condition){statement ; …}
条件为“真”,进入循环;条件“假”,退出循环
使用场景:
4.3.10 循环 do-while
4.3.11 循环 for
4.3.12 continue 和 break
4.3.13 next
4.3.14 数组
AWK 数组
4.3.15 awk 函数
AWK 内置函数