【完整记录】使用kubeadm部署kubernetes集群踩坑记录及解决方案
文章目录
- 搭建集群过程中遇到的问题及解决方案
-
- 1. 现有网上的kubernetes集群搭建教程中的kubeadm配置文件版本过老导致出现以下报错:
- 2. kubeadm init过程中pull镜像超时
- 3. kubeadm init过程中报错超时,具体错误如下:
- 4. 使用kube-weave部署cni的时候一直卡住超时
- 5. coredns的状态一直为ContainerCreating
- 6. worker节点在join的时候一直卡在```[preflight] Running pre-flight checks```
- 踩坑流程
-
- 1. 使用kubeadm部署
-
- 1.1 通过kubeadm执行部署master节点流程
-
- 1.1.1 [【问题1】](#1)执行过程中报错如下:
- 1.1.2 [【问题2】](#2)上述配置修改完成后,终于能够执行init了,但是发现在拉取镜像的时候非常的慢,可能是没有设置国内镜像源导致的。
- 1.1.3 [【问题3】](#3) 镜像拉取成功后,再次执行init,报错超时如下:
- 1.1.4 [【问题4】](#4) 部署成功,查看pod的时候发现为NotReady - 缺少CNI
- 1.1.5 [【问题5】](#5) 部署成功,查看pod的时候发现coredns的状态一直为ContainerCreating
- 1.1.6 部署Dashboard
- 1.2 通过kubeadm执行部署worker节点流程
-
- 1.2.1 [【问题6】](#6) worker节点 join的时候一直卡在```[preflight] Running pre-flight checks```
搭建集群过程中遇到的问题及解决方案
1. 现有网上的kubernetes集群搭建教程中的kubeadm配置文件版本过老导致出现以下报错:
your configuration file uses an old API spec: “kubeadm.k8s.io/v1alpha1”. Please use kubeadm v1.11 instead and run ‘kubeadm config migrate --old-config old.yaml --new-config new.yaml’, which will write the new, similar spec using a newer API version.
- 错误原因:配置文件中的kubernetesVersion和安装的kubeadm版本不一致,并且配置中的apiVersion也需要和此版本匹配。
- 解决方法:找到所下载版本的官方文档,寻找支持的apiVersion,以及对应的配置文件kind。并且在v1.25.0版本中,controllerManagerExtraArgs需要拆分。修改后的配置文件如下:
apiVersion: kubeadm.k8s.io/v1beta3 kind: ClusterConfiguration controllerManager: extraArgs: node-monitor-grace-period: "10s" apiServer: extraArgs: runtime-config: "api/all=true" kubernetesVersion: "v1.25.0"
2. kubeadm init过程中pull镜像超时
- 问题原因:国内无法访问初始的镜像源,并且现有网上的解决方案在v1.25.0版本不适用。
- 解决方案:安装官方配置文档,在配置文件中添加如下镜像源的配置。
imageRepository: "registry.aliyuncs.com/google_containers"
3. kubeadm init过程中报错超时,具体错误如下:
[kubelet-check] Initial timeout of 40s passed.
# systemctl status kubelet 查看日志
"Error getting node" err="node xxx not found"
# journalctl -xeu kubelet 错误同上
"Error getting node" err="node xxx not found"
- 错误原因:未找到。在1.24和1.25版本出现上述问题,改为1.23之后执行成功。
- 解决方法:换成旧版本的kubeadm(1.23以上都存在这个错误,1.23及以下就可以直接执行成功),重复执行上述命令直接成功。
# 删除现有的v1.25.0 apt remove kubeadm kubelet kubectl kubernetes-cni # 重新安装一个旧版本的 如v1.23.0 (1.25和1.24都不行) apt install -y kubelet=1.23.0-00 kubeadm=1.23.0-00 kubectl=1.23.0-00 (后面的-00必须要) # 修改修改配置文件中k8s的版本 kubernetesVersion: "v1.23.10" # 安装完成后直接执行kubeadm init kubeadm init --config kubeadm.yaml # 成功执行 Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: ....
4. 使用kube-weave部署cni的时候一直卡住超时
- 解决方法:换成kube-flannel,执行以下命令:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
5. coredns的状态一直为ContainerCreating
- 错误原因:查看该节点状态,发现缺少/run/flannel/subnet.env文件
kubectl describe pod coredns-6d8c4cb4d-drcgw -n kube-system
#logs
kubernetes installation and kube-dns: open /run/flannel/subnet.env: no such file or directory
- 解决方案:手动写入/run/flannel/subnet.env文件,再次查看为running
cat < /run/flannel/subnet.env
FLANNEL_NETWORK=172.100.0.0/16
FLANNEL_SUBNET=172.100.1.0/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
EOF
6. worker节点在join的时候一直卡在[preflight] Running pre-flight checks
- 错误原因:在kubeadm join 命令后面加上–v=2 查看日志
Failed to request cluster-info, will try again: Get “https://xxxx:6443/api/v1/namespaces/kube-public/configmaps/cluster-info?timeout=10s”: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
可以发现是master节点的ip连不上,ping试一下发现ping不通。产生的原因是在master节点中使用的是云服务器的内网ip,在配置中改为公网ip就成功了。
- 解决方法:在配置文件中加上下面这一句:
并且kubeadm init成功后的ip也为公网ip意味着修改完成。controlPlaneEndpoint: "xxx.xxx.xxx.xxx(对应的公网IP):6443"
踩坑流程
1. 使用kubeadm部署
配置文件kubeadm.yaml如下:
apiVersion: kubeadm.k8s.io/v1alpha1
kind: MasterConfiguration
controllerManagerExtraArgs:
node-monitor-grace-period: "10s"
apiServerExtraArgs:
runtime-config: "api/all=true"
kubernetesVersion: "stable-1.11"
其中,“stable-1.11”就是kubeadm帮我们部署的Kubernetes版本号,即:Kubernetes release 1.11最新的稳定版,在我的环境下,它是v1.11.1。你也可以直接指定这个版本,比如:kubernetesVersion: “v1.11.1”。
1.1 通过kubeadm执行部署master节点流程
kubeadm init --config kubeadm.yaml
1.1.1 【问题1】执行过程中报错如下:
your configuration file uses an old API spec: “kubeadm.k8s.io/v1alpha1”. Please use kubeadm v1.11 instead and run ‘kubeadm config migrate --old-config old.yaml --new-config new.yaml’, which will write the new, similar spec using a newer API version.
- 尝试使用提示的命令解决:
kubeadm config migrate --old-config old.yaml --new-config new.yaml- 但只得到一个空文件,说明没有迁移过去。
其实上述报错是因为配置文件中的kubernetesVersion和安装的kubeadm版本不一致,并且配置中的apiVersion也需要和此版本匹配。解决方法如下:
- 查看本地安装的kubeadm版本:kubeadm版本为v1.25.0
kubeadm version # kubeadm version: &version.Info{Major:"1", Minor:"25", GitVersion:"v1.25.0" ...} - 修改配置文件中的kubernetesVersion为kubeadm版本
kubernetesVersion: "v1.25.0" - 修改apiVersion,需要与安装的kubeadm匹配:
apiVersion版本从最早的v1alpha1、v1alpha2…到现在的v1beta1、v1beta2等,随着kubeadm和kubernetesVersion版本的不同选择对应版本的apiVersion
- 在这个网站中可以找到kubeadm对应的apiVersion:
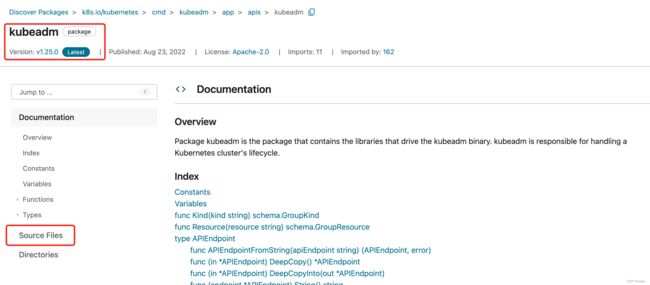
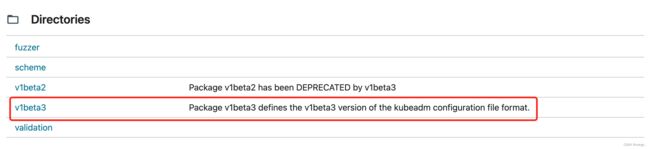
- 可以发现在kubeadm v1.25.0版本中1v1beta2已经被弃用。
- 点击v1beta3,进去后可以发现

Migration from old kubeadm config versions:
kubeadm v1.15.x and newer can be used to migrate from v1beta1 to v1beta2.
kubeadm v1.22.x and newer no longer support v1beta1 and older APIs, but can be used to migrate v1beta2 to v1beta3.
- 因此本地安装kubeadm v1.25.0可以选择该版本的api
apiVersion: kubeadm.k8s.io/v1beta3
- 修改上述配置文件后,还会产生以下这个错误:
Ignored YAML document with GroupVersionKind kubeadm.k8s.io/v1beta3, Kind=MasterConfiguration
no InitConfiguration or ClusterConfiguration kind was found in the YAML file
To see the stack trace of this error execute with --v=5 or higher
- 查看文档后发现配置文件中的kind设置有误,应该如下所示,从中选一个即可。由于是配置一个k8s集群,所以选了ClusterConfiguration。
apiVersion: kubeadm.k8s.io/v1beta3 kind: InitConfiguration apiVersion: kubeadm.k8s.io/v1beta3 kind: ClusterConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration apiVersion: kubeadm.k8s.io/v1beta3 kind: JoinConfiguration
- 修改完成后又出现了一个新的报错:
error unmarshaling configuration schema.GroupVersionKind{Group:“kubeadm.k8s.io”, Version:“v1beta3”, Kind:“ClusterConfiguration”}: strict decoding error: unknown field “apiServerExtraArgs”, unknown field “controllerManagerExtraArgs”
- 查看上述的官方文档,发现新版本的配置文件中不再支持controllerManagerExtraArgs,需要拆开。最终修改的配置文件如下:
apiVersion: kubeadm.k8s.io/v1beta3 kind: ClusterConfiguration controllerManager: extraArgs: node-monitor-grace-period: "10s" apiServer: extraArgs: runtime-config: "api/all=true" kubernetesVersion: "v1.25.0"
1.1.2 【问题2】上述配置修改完成后,终于能够执行init了,但是发现在拉取镜像的时候非常的慢,可能是没有设置国内镜像源导致的。
[init] Using Kubernetes version: v1.25.0
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using ‘kubeadm config images pull’
- 尝试了网上现有的解决方法,均在v1.25.0版本无效。包括以下:
- 使用docker pull镜像,然后使用docker tag修改名称
- 添加docker镜像加速等
- 最后在官方文档中发现可以在配置文件中添加以下配置进行自定义镜像源:
imageRepository: "registry.aliyuncs.com/google_containers" - 【当网上现有的方法无效时,可以尝试阅读官方文档寻找解决方案】
1.1.3 【问题3】 镜像拉取成功后,再次执行init,报错超时如下:
[kubelet-check] Initial timeout of 40s passed.
# systemctl status kubelet 查看日志
"Error getting node" err="node xxx not found"
# journalctl -xeu kubelet 错误同上
"Error getting node" err="node xxx not found"
尝试了现有的解决方案在v1.25.0均无效,包括:
- 修改/etc/hosts
- 指定kubeadm init的各种参数,包括apiserver-advertise-address等
- …
如果有大佬找到该问题在v1.25.0版本的解决方案,麻烦在评论区解答一下,万分感谢!
个人解决方法:换成旧版本的kubeadm(1.23以上都存在这个错误,1.23及以下就可以直接执行成功),重复执行上述命令直接成功。
# 删除现有的v1.25.0
apt remove kubeadm kubelet kubectl kubernetes-cni
# 重新安装一个旧版本的 如v1.23.0 (1.25和1.24都不行)
apt install -y kubelet=1.23.0-00 kubeadm=1.23.0-00 kubectl=1.23.0-00 (后面的-00必须要)
# 修改修改配置文件中k8s的版本
kubernetesVersion: "v1.23.10"
# 安装完成后直接执行kubeadm init
kubeadm init --config kubeadm.yaml
# 成功执行
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
....
至此集群中的master节点成功部署。并保存授权信息。
# kubeadm还会提示我们第一次使用Kubernetes集群所需要的配置命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
需要这些配置命令的原因是:Kubernetes集群默认需要加密方式访问。所以,这几条命令,就是将刚刚部署生成的Kubernetes集群的安全配置文件,保存到当前用户的.kube目录下,kubectl默认会使用这个目录下的授权信息访问Kubernetes集群。
1.1.4 【问题4】 部署成功,查看pod的时候发现为NotReady - 缺少CNI
# 查看nodes
root@master:/home/ubuntu# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady control-plane,master 5m28s v1.23.0
# 查看日志
kubectl describe node master
NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
- 可以发现cni config uninitialized导致的节点为NotReady,因此需要再部署一个网络插件cni
但是使用常用的kube-weave部署cni时一直卡住超时:
kubectl apply -f https://git.io/weave-kube-1.6
- 解决方法:
- 换成kube-flannel,执行以下命令:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
- 换成kube-flannel,执行以下命令:
kubectl apply -f https://git.io/weave-kube-1.6
# 上述命令超时
kubectl apply -n kube-system -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
# 上述命令失败
# 使用kube-flannel
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
1.1.5 【问题5】 部署成功,查看pod的时候发现coredns的状态一直为ContainerCreating
- 错误原因:查看该节点状态,发现缺少/run/flannel/subnet.env文件
kubectl describe pod coredns-6d8c4cb4d-drcgw -n kube-system
#logs
kubernetes installation and kube-dns: open /run/flannel/subnet.env: no such file or directory
- 解决方案:手动写入/run/flannel/subnet.env文件,再次查看为running
cat < /run/flannel/subnet.env
FLANNEL_NETWORK=172.100.0.0/16
FLANNEL_SUBNET=172.100.1.0/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
EOF
1.1.6 部署Dashboard
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml
kubectl get pods --namespace=kubernetes-dashboard -o wide
1.2 通过kubeadm执行部署worker节点流程
Kubernetes的Worker节点跟Master节点几乎是相同的,它们运行着的都是一个kubelet组件。唯一的区别在于,在kubeadm init的过程中,kubelet启动后,Master节点上还会自动运行kube-apiserver、kube-scheduler、kube-controller-manger这三个系统Pod。
所以,相比之下,部署Worker节点反而是最简单的,只需要两步即可完成。
- 在所有Worker节点上安装kubeadm和Docker。
- 执行部署Master节点时生成的kubeadm join指令:
kubeadm join xxxx:6443 --token xxxx --discovery-token-ca-cert-hash sha256:xxxxxx
1.2.1 【问题6】 worker节点 join的时候一直卡在[preflight] Running pre-flight checks
- 错误原因:在kubeadm join 命令后面加上–v=2 查看日志
Failed to request cluster-info, will try again: Get “https://xxxx:6443/api/v1/namespaces/kube-public/configmaps/cluster-info?timeout=10s”: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
可以发现是master节点的ip连不上,ping试一下发现ping不通。产生的原因是在master节点中使用的是云服务器的内网ip,在配置中改为公网ip就成功了。
- 解决方法:在master配置文件中加上下面这一句,然后重新执行init:
controlPlaneEndpoint: "公网ip:6443"
并且kubeadm init成功后的ip也为公网ip意味着修改完成。
至此kubernetes集群搭建完毕!