常见的分布式事务解决方案,你会几种?
今天我们来聊一聊分布式事务,在传统的单体应用中,事务的控制非常简单,Spring框架都为我们做了封装,我们只需简单地使用@Transactional注解就能进行事务的控制,然而在分布式应用中,传统的事务方案就出现了极大的问题:

当用户进行下单操作时,我们需要查询出当前下单的用户、购物车中的商品、扣减商品库存,这些内容都被划分到不同的模块中,所以一个下单的操作往往需要远程调用多个模块。假设在执行下单流程中,扣减库存成功,但是在扣减用户余额的时候出现了异常,此时用户模块中会回滚扣减的金额,但由于用户模块和库存模块是相互独立的,库存模块无法感知到用户模块出现了异常并执行回滚操作,由此导致用户没有花费一分钱就白嫖到了商品,这显然是不允许存在的。
分布式事务解决方案
下面列举一些分布式事务的解决方案:
-
2PC模式
-
TCC事务补偿
-
最大努力通知
-
可靠消息
2PC模式
2PC意为二阶段提交,又叫XA Transactions,其中,XA是一个两阶段提交协议,该协议将事务分为两个阶段:
-
第一阶段:事务协调器要求每个涉及到事务的数据库预提交此操作,并响应是否可以提交
-
第二阶段:事务协调器要求每个数据库提交数据,其中,如果有任何一个数据库否决此次提交,那么所有的数据库都会被要求回滚它们在此事务中修改的内容
2PC非常好理解,就是在所有涉及事务操作的数据库之上建立了一个事务协调器,该协调器能够管理这些数据库的事务,如下图所示,第一阶段:

第二阶段:

2PC的优势是简单,实现成本低,但缺点也非常明显,性能低下,在MySQL和一些NoSQL数据库中的支持也不够。
TCC事务补偿
2PC模式遵循的是ACID原则,即:原子性、一致性、隔离性、持久性,它是一种强一致性的设计,而事实上,很多情况下我们都无法做到强一致性,或者想要实现强一致性成本比较高。eBay 的架构师 Dan Pritchett在ACM上发表文章提出了BASE理论,该理论指出即使无法做到强一致性,但应用可以采用合适的方式达到最终一致性,最终一致性对于数据的要求并不是非常严格,它不需要系统做到数据实时保持最新状态,而是数据在经过一段时间后,最终能够达到一致即可,TCC事务补偿方案就是一种柔性事务的设计,它能够保证数据的最终一致性,一般是在业务层进行实现的。
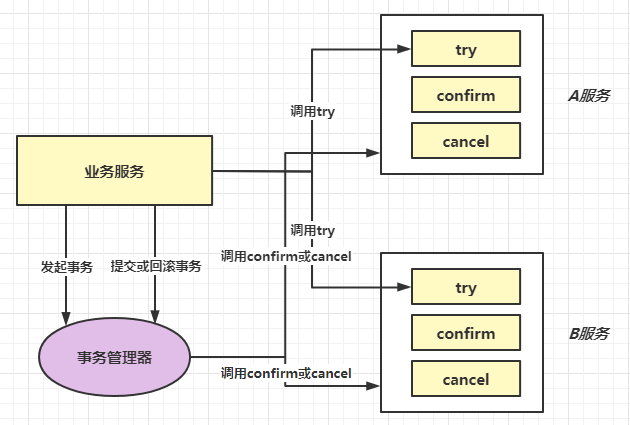
如图所示,我们必须在需要被事务控制的服务中编写Try、Confirm、Cancel三个方法,此时,业务服务会尝试调用每个服务的Try方法,若是没有出现问题,则由事务管理器调用Confirm方法进行提交,若是出现问题,则调用Cancel方法进行回滚。TCC事务补偿方案也比较好理解,但它对业务的侵入较大,且与业务耦合在了一起。
最大努力通知
最大努力通知方案也是柔性事务的设计,它按规律进行消息通知,不保证数据一定能通知成功,但会提供可查询接口进行核对。如果你在项目中对接过支付宝支付服务,就应该清楚,支付宝在付款后采用的就是最大努力通知方案,支付宝会每隔一段时间发送一个通知来告诉开发者订单的支付情况,只有返回了 success 数据后支付宝才会停止通知。
可靠消息
可靠消息仍然只保证数据的最终一致性,且它需要借助消息中间件来完成,当某个服务在事务提交之前,会向消息中间件发送一条消息,再根据本地事务的执行状态发送Commit或者RollBack给消息中间件,消费方根据对应的状态对事务进行对应的处理。
RabbitMQ实现数据的最终一致性
想象一个场景,用户在进行下单操作之后,会有30分钟的时间让用户进行付款,在用户付款之前,商品的库存并没有真正的扣除,而是进行锁定。若是用户在规定时间内付款成功,则需要真正扣减库存;若是用户在规定时间内没有付款,则需要将锁定的商品库存重新解锁,这里涉及到两个模块之间的事务操作:

当用户下单后,订单模块需要保存本次订单的库存工作单,记录的是哪些商品需要被锁定的库存数,并远程调用库存模块锁定库存,此时需要等待用户进行付款,若是用户未付款,则解锁库存。那么如何知道哪些订单是用户超时未付款需要解锁的呢?我们可以编写一个定时任务,让其每隔一定的时间就去扫描订单,并判断是否超时,若是超时则解锁库存。不过这种方式并不理想,不仅效率低,而且扫描时间也不好确定。我们可以使用消息中间件来解决这一问题:

订单模块在生成订单后向RabbitMQ发送一条消息,并由RabbitMQ暂时保存,当30分钟过后,订单过期,RabbitMQ再将消息提供给库存模块进行消费, 当库存模块得到消息后就明白有订单过期了,再去解锁对应的库存即可,所以接下来我们面临的问题就是:如何将消息在RabbitMQ中保存30分钟,当消息过期后再交给库存模块消费。
延时队列
在RabbitMQ中,我们可以实现一个延时队列,消息进入延时队列后不会立马被消费,而是需要等待设定的时间,在实现之前,需要清楚两个概念:
-
死信
-
死信路由
死信
在RabbitMQ中,我们可以为消息设置一个存活时间TTL(time to live),当消息超过了存活时间,就可以认为这个消息已经死了,称为 死信 。一个消息在满足如下条件时会进入死信路由:
-
消息被Consumer拒收,并且reject方法的参数中requeue值为false,即:该消息被拒收后,不会再进入消息队列
-
消息超过了TTL时间,导致消息过期
-
消息队列满了,排在前面的消息会被丢弃或者扔到死信路由上
死信路由
在死信概念中,我们一直强调一个词, 死信路由 ,其实,它就是一个普通的路由,只是当某个队列绑定了死信路由后,该消息队列中的消息过期了,就会自动触发消息的转发,消息会被扔到死信路由上。通过死信和死信路由,我们就能够实现一个延时队列,如图所示:

当生产者生产了一个消息后,会通过交换器放入一个队列,该队列比较特殊,在该队列中的消息存活时间均为30分钟,并且当这些消息过期成为死信后,会被交给死信路由,死信路由再将消息放入另一个消息队列,这样,该消息队列便保证了每次放入的消息都经过了30分钟,因为只有死信才能进入该队列,要想实现这一过程,我们需要为那个特殊的消息队列设置一些属性值:
-
x-dead-letter-exchange:xxx 设置死信路由
-
x-dead-letter-routing-key:xxx 设置死信路由键
-
x-message-ttl:1800 000 设置消息的存活时间为30分钟
将其类比到具体的业务场景中,就比如订单超时自动解锁库存的需求,其设计如下图所示:

执行流程如下:
-
Publisher发送消息给路由order.delay.exchange,路由键为order.delay
-
路由order.delay.exchange将消息放入绑定关系为order.delay的消息队列order.delay.queue
-
消息队列order.delay.queue中消息的存活时间为30分钟,当消息过期后,消息会交给路由order.exchange,路由键为order
-
路由order.exchange将消息放入绑定关系为order的消息队列order.queue
-
Consumer监听消息队列order.queue,保证了消费的消息均是过期的
不过这一过程还可以再简化一下:

它与刚才唯一的区别在于少了一个路由,Publisher在将消息发送给路由order.delay.exchange之后,会将消息放入队列order.delay.queue,我们让该队列在消息过期后仍然将消息交给路由order.delay.exchange,这样就节省了一个路由的资源。
代码实现
概念吹得天花乱坠,不动手实现一下始终是无法深刻理解的,所以,我们就通过一个案例来感受一下延迟队列的效果。
创建一个SpringBoot应用,并使用代码创建出路由、消息队列及其它们之间的关系:
@Configuration
public class MyRabbitMQConfig {
@Bean
public Queue orderDelayQueue() {
Map arguments = new HashMap<>();
arguments.put("x-dead-letter-exchange", "order.delay.exchange");
arguments.put("x-dead-letter-routing-key", "order.release.order");
arguments.put("x-message-ttl", 1000 * 10);
return new Queue("order.delay.queue", true, false, false, arguments);
}
@Bean
public Queue orderReleaseOrderQueue() {
return new Queue("order.release.order.queue", true, false, false);
}
@Bean
public Exchange orderDelayExchange() {
return new TopicExchange("order.delay.exchange", true, false);
}
@Bean
public Binding orderCreateOrderBinding() {
return new Binding("order.delay.queue",
Binding.DestinationType.QUEUE,
"order.delay.exchange",
"order.create.order", null);
}
@Bean
public Binding orderReleaseOrderBinding() {
return new Binding("order.release.order.queue",
Binding.DestinationType.QUEUE,
"order.delay.exchange",
"order.release.order", null);
}
}
需要注意的是使用这种方式创建需要发送一下消息:
@RestController
public class TestController {
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping("/test")
public String test(){
rabbitTemplate.convertAndSend("order.delay.queue","message");
return "test";
}
}
当发送消息到队列 order.delay.queue 时,RabbitMQ便会创建出队列和路由:
![]()

接下来我们编写一个监听方法,它用来监听队列 order.release.order.queue :
@RabbitListener(queues = "order.release.order.queue")
public void listener(Message message) {
System.out.println("收到消息:" + message);
}
此时我们访问 http://localhost:8080/test ,就会发送一条消息到队列,再经过10秒钟的时间,消息会过期,消息便会进入队列 order.release.order.queue ,而我们监听的又是这个队列,所以总能收到10秒后过期的消息:
收到消息:(Body:'message' ......)
收到消息:(Body:'message' ......)
收到消息:(Body:'message' ......)
通过这样的方式,我们便能够实现数据的最终一致性。