图像卷积操作
图像卷积操作
-
- 什么是卷积操作
- 实现卷积(pytorch)
- 卷积的步长与填充
- 理解卷积的深度
- 卷积的作用
什么是卷积操作
卷积是通过一定大小的卷积核作用于图像的局部区域,将局部图像区域的像素值与卷积核中的数据做内积运算。

假设输入是一个3*3大小的单通道图像(可以将图像看作一个矩阵),卷积核为2*2的矩阵。
首先,从左上角开始在输入矩阵上选择一个与卷积核大小一致(2*2)的“窗口”,
然后,将该“窗口”中的数值与卷积核中的数值做内积运算(将对应位置的数据相乘,之后相加)
最后,依次向右、向下划动窗口,覆盖整个输入矩阵,获得输出矩阵。
实现卷积(pytorch)
Pytorch是一个开源机器学习框架,它能帮我更方便的进行模型搭建、训练,我们可以通过结合API文档以及项目进行学习。
(这里不再讲解pytorch安装,还未安装请提前安装)
在实现卷积之前,我们需要先了解一下“张量(tensor)”的概念,“张量”其实包含很多类型,如下图所示:

利用Pytorch进行操作时,需要将数据转换为“张量”。
import torch
# 生成2维张量
a = torch.tensor([[1,1,1],[0,0,1],[1,1,0]])
# 输出尺寸
print(a.shape) #torch.Size([3, 3]),表示一个二维张量,第一个维度有3个数据,第二个维度也有3个数据
在torch.nn.functional模块中conv2d()方法可以实现图像二维卷积操作,其主要参数包括:

其实现方法如下所示:
# 卷积运算
import torch.nn.functional as F
def _conv2d(data,kernel,stride = 1,padding = 0):
# 对数据进行尺寸变换
data = torch.reshape(data,[1,1,data.shape[0],data.shape[1]])
kernel = torch.reshape(kernel,[1,1,kernel.shape[0],kernel.shape[1]])
# 卷积操作
output = F.conv2d(data,kernel,stride = stride,padding = padding)
return output
- 首先需要对输入数据和卷积核尺寸变换,使用
torch.reshape()进行维度转换- 参数
input(输入)的维度需包括(样本个数,输入图像的通道数,图像的高,图像的宽),目前我们只考虑单通道图像,也没有涉及多样本的情况,所以前2个维度均设置为1,只考虑图像的高和宽 - 参数
weight(卷积核)的维度需包括(输出图像的通道数,输入图像的通道数/groups,卷积核的高,卷积核的宽),groups默认为1,在这里也只考虑卷积核的高和宽
- 参数
- 使用
conv2d()进行卷积操作。- 其他参数,如stride,padding,我们将在后面讨论,先将其设置为默认值。
调用函数实现卷积
# 构建输入矩阵(tensor类型)
data = torch.tensor([[1,1,1],
[0,0,1],
[1,1,0]])
# 构建卷积核(tensor类型)
kernel = torch.tensor([[1,1],
[0,0]])
output = _conv2d(data,kernel)
print(output)
输出:

卷积的步长与填充
步长(stride):是指图像窗口每次移动的“间距”。
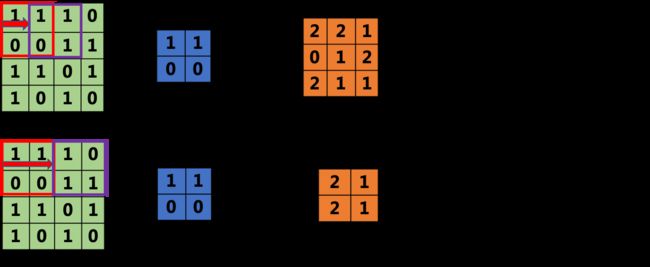
从图中可以发现,同样大小的图像与卷积核,当stride发生变化时,输出图像的大小也会发生变化。
data = torch.tensor([[1,1,1,0],
[0,0,1,1],
[1,1,0,1],
[1,0,1,0]])
kernel = torch.tensor([[1,1],
[0,0]])
# 不同步长的输出结果
output1 = _conv2d(data,kernel,stride = 1)
output2 = _conv2d(data,kernel,stride = 2)
print(output1.shape) # torch.Size([1, 1, 3, 3])
print(output2.shape) # torch.Size([1, 1, 2, 2])
填充(padding):延伸矩阵的“边界”
下图为stride = 1,padding = “valid”(no padding,无填充)的卷积效果;
4*4的图像与3*3的卷积核进行卷积操作时,图像边缘的点只会被卷积核操作一次,但是图像中间的点会被“照顾”到很多遍,那么就会在一定程度上降低边缘信息。

下图为stride = 1, padding=“same”,即对图像边缘填充像素点(一般使用0进行填充),填充之后可以保证在stride = 1的情况下,输出图像大小和输入图像大小是一致的。

实现过程如下所示:
data = torch.tensor([[1,1,1,0],
[0,0,1,1],
[1,1,0,1],
[1,0,1,0]])
kernel = torch.tensor([[1,1,0],
[0,0,1],
[1,1,0]])
output1 = _conv2d(data,kernel,stride = 1,padding = 0) # padding = 0,即padding = “valid”
output2 = _conv2d(data,kernel,stride = 1,padding = 1) # padding = 1,即padding = “same”
print(output1)
print(output2)
输出:

观察前面的输入与输出,发现当卷积核大小、步长、填充会影响输出矩阵的大小(shape),经过卷积后输出矩阵/图像的大小计算公式为:
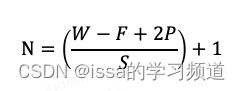
- W:输入矩阵的大小
- F:卷积核的大小
- P:填充的大小
- S:步长
- N:输出矩阵的大小
如输入图像的大小是4*4,卷积核大小为3*3,填充为1,步长为1,输出图像的大小为(4-3+2*1)/1+1 = 4。
这里需要注意的是,如果图像的宽和高不一样,就需要单独计算卷积后的宽和高,一般情况下在做图像卷积操作时,图像的宽和高是相等的。
理解卷积的深度
- 每个卷积核的深度==输入矩阵的深度。
- 输出矩阵的深度==卷积核的个数。

如图中输入矩阵数组的深度为3,每个矩阵都是4*4的大小,要进行卷积运算,卷积核的深度也需要是3(如图中的卷积核1和卷积核2),将输入矩阵数组与卷积核1做内积运算,获得一个输出矩阵;然后将输入矩阵继续与卷积核2做内积运算,获得另一个输出矩阵,因此输出矩阵数组的深度为2。
# 生成一个维度为[3, 4, 4]的张量
data = torch.tensor([[[1,1,1,0],
[0,0,1,1],
[1,1,0,1],
[1,0,1,0]],
[[0,0,1,0],
[0,1,1,0],
[1,0,0,1],
[0,0,1,1]],
[[1,0,0,0],
[1,1,0,0],
[0,1,0,1],
[1,0,1,1]]]
)
# 生成一个维度[2,3, 2, 2]的张量
kernel = torch.tensor([[[[1,1],
[0,0]],
[[1,0],
[1,0]],
[[1,0],
[0,1]]],
[[[0,1],
[0,0]],
[[1,0],
[1,1]],
[[0,1],
[1,1]]]])
print(data.shape)
print(kernel.shape)
data = torch.reshape(data,[1,3,data.shape[1],data.shape[2]])
# 卷积操作
output = F.conv2d(data,kernel,stride = 1,padding = 0)
print(output)
卷积的作用
卷积通过卷积核在图像矩阵上滑动窗口,可以实现局部区域的感知,提取图像的特征。
import cv2
import matplotlib.pyplot as plt
# 读取图像并将其转换为灰度图像
img = cv2.imread("img/1.png")
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
plt.imshow(img_gray, cmap='gray')
plt.show()

在下方案例中,可以使用不同的卷积核来提取图像的不同特征;
可以发现,(1)卷积核中参数是可变的;(2)卷积核的参数影响了特征提取;那么我们在训练一个卷积神经网络时,就是要去训练卷积核中参数。
# 将图像转换为tensor类型
inputimg = torch.FloatTensor(img_gray)
print(inputimg.shape)
# 指定卷积核,该卷积核可以获取垂直边界特征
kernel =torch.Tensor([[1,0,-1],
[1,0,-1],
[1,0,-1]])
#对数据进行尺寸变换
inputimg = torch.reshape(inputimg,[1,1,inputimg.shape[0],inputimg.shape[1]])
kernel = torch.reshape(kernel,[1,1,3,3])
# 卷积运算
output = F.conv2d(inputimg,kernel)
plt.imshow(output[0].permute(1, 2, 0), cmap='gray')
plt.show()
输出:
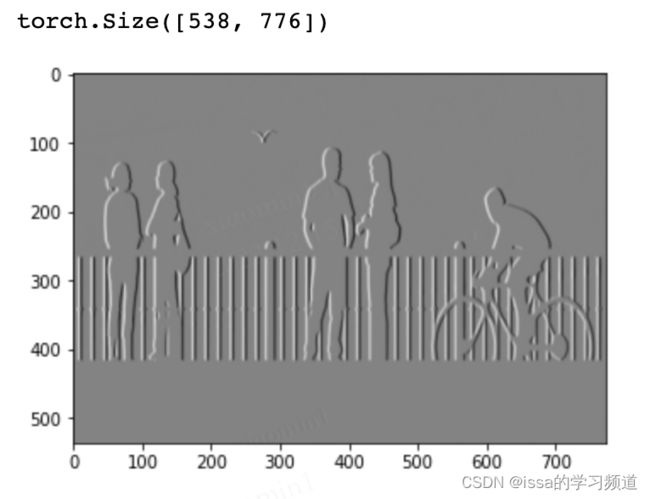
inputimg = torch.FloatTensor(img_gray)
# 指定卷积核,该卷积核可以获取水平边界特征
kernel =torch.Tensor([[1,1,1],
[0,0,0],
[-1,-1,-1]])
#对数据进行尺寸变换
inputimg = torch.reshape(inputimg,[1,1,img.shape[0],img.shape[1]])
kernel = torch.reshape(kernel,[1,1,3,3])
# 卷积运算
output = F.conv2d(inputimg,kernel)
plt.imshow(output[0].permute(1, 2, 0), cmap='gray')
plt.show()
输出:
