6-PACK论文学习及复现记录
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、基本思想
-
- 1.1 创新点
- 1.2 两个变换
- 二、实现结构
-
- 1.基于注意力机制生成锚点特征
- 2.生成关键点(分对称类、非对称)
-
- 2.1 损失函数(非对称)
- 2.2 损失函数(对称)
- 3.预测帧间变化
- 4.测试
-
- 指标
- 三、项目复现
-
- 3.1 数据文件含义
- 3.2 代码逻辑
- 四、复现记录
-
- 4.1 环境配置&复现流程
-
- 4.1.1 本地
- 4.1.2 服务器配置
- 4.2 遇到的问题
-
- 4.2.1 本地
- 4.2.2 服务器
- 4.3 复现结果
前言
6D位姿估计相关知识学习:
6D位姿估计学习
一、基本思想
6-PACK是一种类别级的基于投票的方法,实际上是一种位姿追踪器。基本思想是通过距离加权投票出一个目标锚点(距离物体质心最近的锚点),再由目标锚点生成1组有顺序的关键点,通过连续帧之间关键点的坐标变化估计帧间的相对位姿Δp,则在已知初始位姿p0的情况下,t时刻的位姿可以表示为:pt=Δp(t)Δp(t-1)…Δp(1)p0(下一帧的预测姿势是由最后一次估计的帧间姿态变化推断出来的)
初始姿势是相对于标准帧的相机帧的平移R(33)和旋转T(31),同种类别的初始姿势一致。
其中,训练的模型只是得到每一帧的关键点、目标锚点的坐标和锚点置信分数,实际的位姿预测在eval.py中进行。
1.1 创新点
- 利用anchor机制产生稳健而小规模的keypoints,能够有效减少噪声和遮挡干扰,且作用于同一类别的不同实例
- 利用帧间关键点追踪来估计姿态
1.2 两个变换
-
世界坐标系与相机坐标系:
Tc=Tm*RcmT+tcm,其中Tm为物体在世界坐标系的坐标,Tc为物体在相机坐标系的坐标。Rcm为由世界系到相机系的旋转,tcm为由世界系到相机系的平移。 -
相机坐标系与图片2D坐标系:
如下图所示,相机3D坐标为[x,y,z],像素平面坐标为[u,v,1]两者通过相机内参矩阵K变换

详见一文带你搞懂相机内参外参
二、实现结构

1.基于注意力机制生成锚点特征
使用在围绕物体的预测姿态生成的锚点网格(第IV-A节)上的注意机制。每个锚点用其周围RGB-D点的个体特征的距离加权和,表示其周围的体积。在预测当前物体位置周围设置三维锚点网格。每个锚都包含一个周围的体积特征表示。基于这个特征,模型学习关注最接近物体质心的锚点。
实现步骤:
-
首先根据物体bbox(bounding box)生成5 *5 *5 个锚点ai的anchor网络,再利用DenseFusion将颜色特征和几何特征结合,生成融合特征,即彩色点的1维embedding ϕ \phi ϕj:将DenseFusion[45]特征嵌入到锚点网格内的RGB-D图像的所有彩色3D点,并使用距离加权平均将它们汇聚到每个锚点中,从而生成锚点嵌入(embedding:低维特征表示).
-
假设网格有N个锚点ai,M个RGB-D图中的彩色点云的点xj。则对每个锚点,各个点云的点到他的距离为di=[di1,…,diM];设权值w=softemax(d),采用距离加权的平均池化得到嵌入锚点 ψ \psi ψi=Σjwj ϕ \phi ϕj
(其中 ϕ \phi ϕj为DenseFusion编码器生成的xj的一维嵌入) -
以上过程已经得到锚点特征,再从 ψ \psi ψi中找最接近物体真实质心的点作为目标锚点。采用2层MLP作为注意力网络,网络输入为 ψ \psi ψi,输出为置信分数ci,损失函数为:


其中ogt为ground-truth的质心。取置信度最高的点作为锚点,关键点由锚点的偏移点生成(见step2)
2.生成关键点(分对称类、非对称)
设关键点有K个,[k1,…kK]
提出一种神经网络(卷积网络构成),输入为锚点的特征 ψ \psi ψi,输出一个K*3维有序的关键点列表,因为有序,所以相邻帧的关键点可以直接按照索引匹配。
2.1 损失函数(非对称)
由于多视图一致性损失只保证可见部分特征位置在帧间一致,不能保证对最终的目标–预测帧间位姿变化有效(有可能这些点位置一致)。故不适用。(多视图一致性:假设keypoints在每两个连续的帧中生成;训练目标是将当前视图中的关键点放置在与前一帧关键点对应的位置,并通过地面真值帧间运动进行变换)
实际使用的Loss是6种损失函数的加权和,权重由它们的相对大小和重要性决定。
-
多视图一致性损失Lmvc

其中,kit为视频t时刻帧种关键点的坐标,减号后的部分代表将t-1时刻关键点坐标通过真实的相对位姿变化推测出一个t时的坐标,多视图一致性损失即为推测出的关键点与实际关键点的平均距离。 -
平移损失Ltra

其中,kt-kt-1为两组关键点中心坐标的差,即根据关键点预测出来的两帧间的相对平移向量t,而为实际的相对平移,平移损失即为两帧间预测相对平移向量与实际平移向量的距离。 -
旋转损失Lrot

-
分离损失Lsep
迫使关键点之间保持一定的距离,以避免构型退化和改善姿态估计 -
轮廓损失Lsil
轮廓损失定义为8个Keypoints与他们最接近的bbox网格点的距离的平均值,该部分计算轮廓一致性的损失,迫使关键点更接近物体表面,以提高可解释性。
2.2 损失函数(对称)
由于沿对称轴确定旋转角是个不可解问题,对于有旋转对称性的物体,找关键点时,定义一种旋转不变性的坐标变换将(x,y,z)坐标变换为(d,h, θ \theta θ),其中
- d:点到对称轴的距离
- h:点相对于笛卡尔原点的高度
- θ \theta θ:将点连接到对称轴上的径向矢量与顺时针推进时所遇到的下一个关键点的径向矢量之间的分离角(同一层相邻关键点之间的夹角)
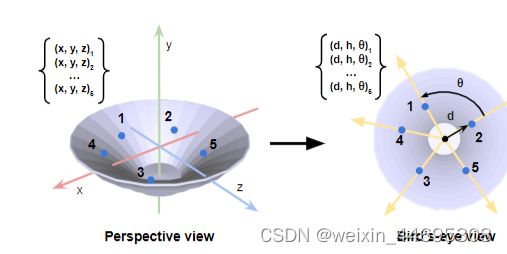
变换后,损失函数中的旋转损失和多视图一致性损失改变:
- 多视图一致性损失Lmvc

- 旋转损失Lrot
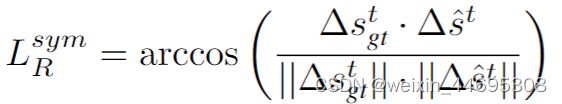
3.预测帧间变化
该部分在eval.py中完成,需要说明eval.py并非对相邻帧求位姿变化,而是将每一帧与初始帧比对。当前帧和初始帧的关键点被传递给最小二乘优化[2],计算帧间的位姿变化
4.测试
- 验证
1)我们的方法是否确实生成了健壮的适合6D姿态跟踪的三维关键点?
2)我们的锚定注意力机制是否提高了整体跟踪性能?
3)我们的方法对位姿初始化中不同程度的噪声的鲁棒性如何?
在NOCS-REAL275[46]数据集上运行,与多个baseline比较
指标
- 5°5 cm,方向误差<5°,平移误差<5 cm的跟踪结果百分比
- IoU25,交并比,预测与地面真实三维边界框之间的体积重叠百分比大于25%
- Rerr方向误差的平均值(以度为单位)
- Terr,平移误差的平均值(以厘米为单位)
论文中给出的指标值:


- 为验证实时性
部署到机器人上,并测试10个未见过的物体
三、项目复现
3.1 数据文件含义
部分文件意义如下:
-
data_pose:对应图片中目标实例的初始位姿

-
model_pts:
其中".txt"文件为实例8个边框顶点的坐标(数据集自带,与data_preprocess生成的bbox文件有差异,需要变换)
 ".xyz"文件为实例点云坐标(世界坐标系下)
".xyz"文件为实例点云坐标(世界坐标系下) -
model_scales:
训练集中:最小拟合3D bbox的2个对角顶点坐标(归一化,使得他们相距1)
验证集:边框的8个顶点(不需要再生成bbox文件)

3.2 代码逻辑
训练生成的models实际输出的并不是位姿RT,而是关键点坐标、锚点网络和置信分数。预测位姿RT的生成过程在eval.py中,通过初始帧&当前帧的关键点坐标和初始位姿来预测当前帧与初始帧之间的位姿变化,再得到当前帧的实际物体位姿。
【6PACK代码注解】train.py
【6PACK代码注解】数据集载入与预处理
【6PACK代码注解】网络结构
【6PACK代码注解】损失函数
【6PACK代码注解】测试过程数据处理
【6PACK代码注解】测试过程eval.py
【6PACK代码注解】评估指标benchmark.py
四、复现记录
4.1 环境配置&复现流程
4.1.1 本地
参照文章:手把手教你跑通6-PACK: Category-level 6D Pose Tracker with Anchor-Based Keypoints
可顺利调通(将train.py中参数改小处理)
4.1.2 服务器配置
1.在当前账户安装anaconda3
2.当前账户安装cuda9.0
由于服务器gcc编译版本太高,直接安装cuda不成功,故先将当前账户的gcc版本降低为6以下,这里用5.5.0,参照文章:非root权限修改当前用户linux gcc版本
(文章中contrib/download_prequisites有误,改为contrib/download_prerequisites)
成功降低gcc后,参照文章Linux服务器下给当前用户安装自己的CUDA、CUDA 还是自己的好用安装cuda9.0
- 对于只在当前账户修改的环境配置,均在该账号路径下载安装文件,并通过 vim ~/.bashrc修改环境
3.将数据集上传至服务器大空间硬盘,并软链接至项目地址
4.为了能实时修改服务器内代码文件,将VScode链接到服务器,参考文章:
使用VScode连接远程服务器的配置方法
5.调整文件地址后,试跑成功
6.执行python train.py --category x --dataset_root '/home/robot413/My_NOCS' --workers 5多次,将6个类别的模型训练出来,各类别最优模型如下:

7.执行原eval.py文件(不输出图片版,速度较快),先得到验证集的预测位姿文件。
8.执行修改后的benchmark.py文件,得到所有指标。
9.执行修改后的eval.py文件(TEST_2),输出标记边框和关键点的图片。
4.2 遇到的问题
4.2.1 本地
1.transfomations.py 中由于环境版本不同,自定义的import_module()函数报错,追踪发现其中调用的import_module 找不到对应文件,且是由于没有按要求忽略 " _ "造成(原因未知)
解决方法:调用时不加 " _ ",并引入sys,将文件路径添加至搜索路径:

2.关于upsample和size_average的warning
纯属因为版本不同造成的函数弃用和改动,但能向下兼容,不影响运行
3.train.py中在for i, data in enumerate(dataloader)处经常卡住不动,或者有时成功运行但耗时很长


且后面遇到这样的警告:
![]()
起初怀疑前面卡住也是因为出现了除0的情况,由于只是warning不是error,先不管他,后面如果对效果影响比较大,考虑将该段代码中加入判别,当分母为0时跳过

解决除0问题后还是不行,有时候能成功运行几次,然后又卡住:

根据github中issue的相关回答,暂时去掉dataset_nocs中_item_函数的try-except后,显示出报错信息,发现问题在于简单粗暴的截取了一部分数据集做测试,但对应的数据没有做相应更改

该项目读取数据的过程要通过datalist中的list.txt获取,每个txt文件中的文件是随机分配的,很难解耦,要么直接用软链接接入所有train文件进行测试,要么更改datalist文件夹,重写list.txt,但这个重写的过程会很繁琐。
目前选择连接所有train文件,先生成真值数据再说(耗时会很长)
成功
4.重新保留dataset_nocs中_item_函数的try-except,修改train.py参数中的地址(outf),且在6test文件夹中新建一个models文件夹,可以成功运行,以此运行各类别得到models
4.eval.py—注意修改其中的model参数
4.2.2 服务器
- 奇怪的报错
该报错只在训练’bottle’, 'bowl‘两类时出现过,前期运行很正常,突然卡住:

torch.svd()调用出错,似乎是矩阵不可分解,目前没有找到对策
尝试1:有说法svd的输入最好是double类型,尝试修改loss.py如下:

不行,会直接无法训练
尝试2:试图使用try except跳过异常并输出“something wrong”来保证训练正常执行,结果发现,第130+个epoch异常后,此后所有epoch都有问题

但从训练结果来看,似乎已经得到了想要的模型
论文中模型:

我们的bowl和bottle:

- 运行benchmark.py时出现如下错误:

该问题在github中也有人提问:issue21问题产生的原因是NOCS数据集中*_meta.txt文件与实际图片中出现的实例不匹配,有的*_meta.txt文件可能多了不存在的实例,导致源代码中通过直接计数num_idx来对应真实位姿gt_RTs的方式出错。github中给出的解决方案是在数据集预处理时摘除多余的实例信息。但由于运行benchmark.py时,模型都训练好了,当然不考虑修改预处理过程再重新训练。故再benchmark.py中将代码做如下修改:
#为读取gts文件中实例真实位姿做准备
obj_path = img_path + "_meta.txt"#图片中出现的实例列表
mask_path=img_path+"_mask.png"
mask_im=cv2.imread(mask_path)[:,:,2]#读取mask.png的各掩码id
mask_im=np.array(mask_im)
inst_ids=np.unique(mask_im)
ins_id = -1#实例在图片中的掩码id
num_idx = 0#目标实例在图片中的idx
with open(obj_path, "r") as obj_f:
for line in obj_f:
if int(line.split(" ")[1]) == cls_idx and line.split(" ")[-1].replace("\n","") == model_name:
ins_id = int(line.split(" ")[0])#实例在图片中的掩码idx
break
if int(line.split(" ")[0]) in inst_ids:
num_idx=num_idx+1
#num_idx = num_idx + 1
if ins_id == -1:
continue
使得在计数过程中判断*_meta.txt各行是否真的有效,修改代码后,如下图所示,问题解决。该部分代码注解详见【6PACK代码注解】评估指标benchmark.py

4.3 复现结果
各类别指标如下:

可视化结果:
关键点&边框图:


位姿图:

