R文件详细介绍、瘦身
R 文件可能是很多 Android 开发者既熟悉又陌生的存在。它无处不在,所有使用到资源的地方都离不开它。它又有些陌生,google 已经把它封装的很完美了,以至于很多开发者并不知道它是怎么工作的。那么我们今天就来揭开它神秘的面纱。
R.id
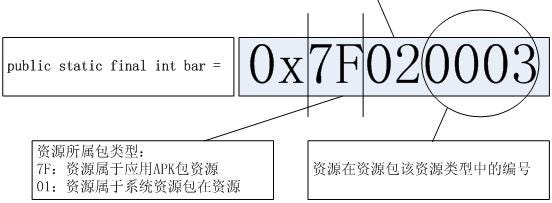
这是一个资源的 id,用 32 位的 int 表示。格式为 PPTTNNNN。
前 8 位 PP(Package) 表示资源所属包类型,0x7f 表示应用 Apk 包资源,0x01 表示系统包资源。
中间 8 位 TT(Type) 代表资源 id 的类型
0x02:drawable
0x03:layout
0x04:values
0x05:xml
0x06:raw
0x07:color
0x08:menu
最后 16 位表示资源在此类型里面的编号。
有了 id 之后,就可以去 resource.arsc 里面去查找到真正的资源,将 id 作为 key,就可以查到此 id 对应的资源。
R 文件的存在形式
在平常的开发流程中,我们大概可以将「project」分为三种。
- AAR
- Module (com.android.library)
- Application (com.android.application)
其中 module 和 aar 对于 App 来说是一样的。
为了方便演示,我们构造了以下的工程
- app
- lib1
- lib2
- androidx.recyclerview:recyclerview:1.1.0
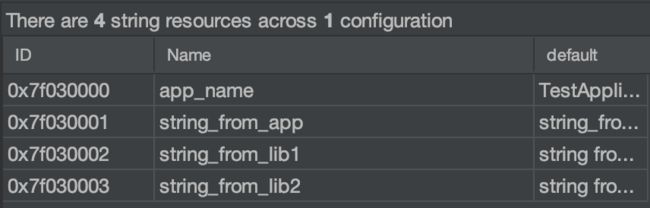
app 是 application 工程,依赖 lib1,lib1 依赖 lib2,lib2 依赖了 recyclerview。其中我们在 app、lib1、lib2 分别放置了 string 资源
- appstring_from_app - lib1string from lib1 - lib2string from lib2
APK
首先我们来看一下最终生成的 apk 里面的 R
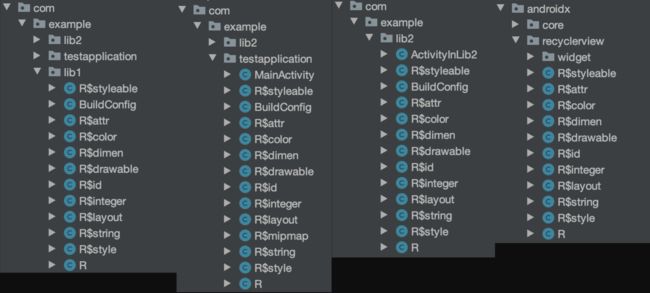
我们发现会生成所有「library」和 「appliaction」 的 R 文件,并且放在不同的包名下。我们再来看一下每个包的 AndroidManifest.xml




有没有发现什么呢?
每个模块最后都是按照 AndroidManifest.xml 里面定义的 package 来决定要生成的 R 文件的包名。
AAR
我们拆开 recyclerview-1.0.0.aar
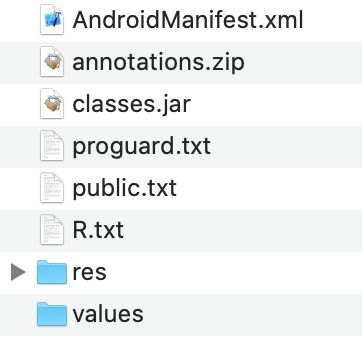
找了一圈,除了一个 R.txt,并没有在其它地方找到 R 相关的踪迹,classes.jar 里面也没有生成的 R.class。
有同学就可能有疑问了,既然 classes.jar 里面没有 R.class,那么在开发的时候,我们是怎么引用到 aar 里面的资源的呢?
首先我们明确一点,所有的 R 都是在生成 apk 的时候由 aapt 完成。为什么要这样做呢?试想如果 R 文件在 aar 打包阶段就已经生成了的话,那么很大概率会导致 id 之间的冲突。比如 recyclerview.aar 用了 0x7f020001,appcompat.aar 也有可能用了 0x7f020001 这个 id,在合并的时候,resource.arsc 只能将这个 id 映射到一个资源,这样就会出现错乱。
所以 AGP 做了一件事,所有 R 文件的生成都在 apk 生成的时候交与 aapt 完成。在开发期间对于 R 文件的引用都给一个临时的 classpath: R.java,这里面包含了编译时期所需要的 R 文件,这样编译就不会出错。并且在运行时会扔掉这些临时的 R.java,真正的 R.java 是 aapt 去生成的。
所以我们总结一下:
- module/aar 里面临时生成的 R.java 只是为了「make compiler happy」,在编译流程中扮演着「compileOnly」的角色。
- 在生成 apk 的时候,aapt 会根据 app 里面的资源,生成真正的 R.java 到 apk 中,运行的时候代码就会获取到 aapt 生成的 id。
这里有一个问题,我们仔细观察一下 app 和 module 里面对 R.id 引用出的地方。
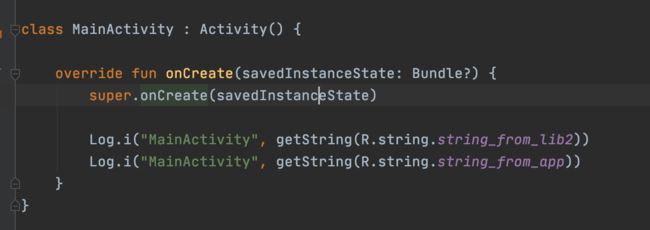
App 的代码
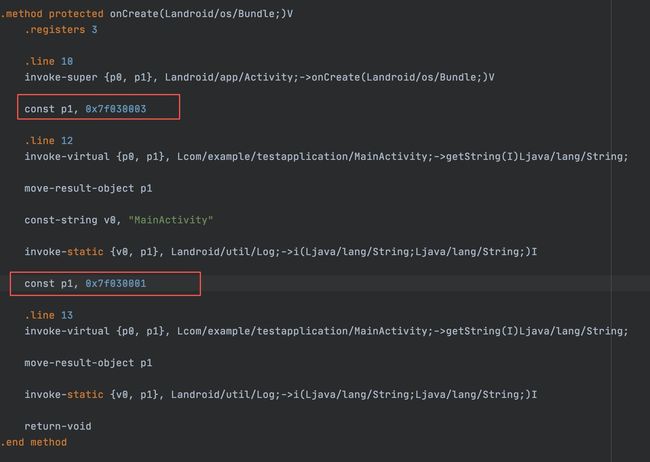
App 生成的字节码
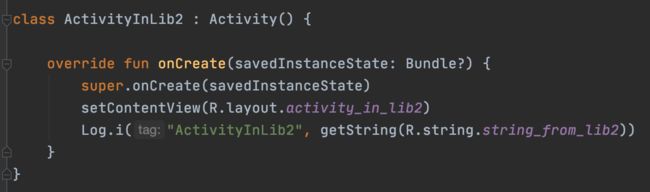
Module 的代码
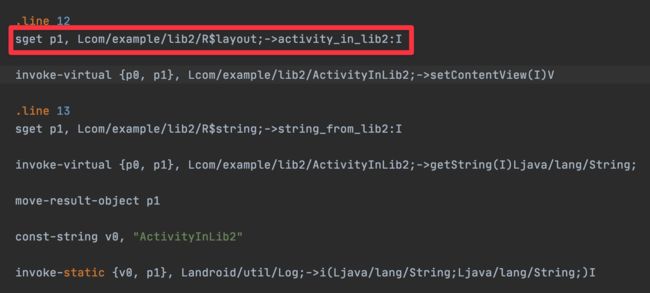
Module 生成的字节码。
我们发现,在 App 里面的代码发生了「内联」,但是在 module 里面的代码并没有被内联,而是通过运行时查找变量的方式去获取。
结合上面的「R生成过程」,来想一下为什么 module 里面的 id 不被内联而 app 里面的 id 会被内联呢?
答案已经很清楚了。module/aar 在编译的时候,AGP 会为它们提供一个临时的 R.java 来帮助他们编译通过,我们知道,如果一个常量被标记成 static final,那么 java 编译器会在编译的时候将他们内联到代码里,来减少一次变量的内存寻址。AGP 为 module/aar 提供的 R.java 里面的 R.id 不是 final 的,因为如果设计成了 final,R.id 就会被内联到代码中去,那在运行的时候,module 里面的代码就不会去寻找 aapt 生成的 R.id,而是使用在编译时期 AGP 为它提供的假的 R.id,这个 id 肯定是不能用的,不然就会导致 resource not found。
R 文件的生成
在编译的中间产物中,R 大概有这么几种存在形式
「此 project」代表当前在编译的 module
「本地资源」代表当前在编译的 module 里面声明的资源
- R.java(java 文件,给此 projet 做 compileOnly 用)
- R.txt(记录了此 project 的所有资源列表,并生成了 id,最后会根据这个值生成对应的 R.java)
- R-def.txt(记录了此 project 的本地资源,不包括依赖)
- package-aware-r.txt(记录了此 project 的所有资源,没有生成 id)
大概的生成逻辑是
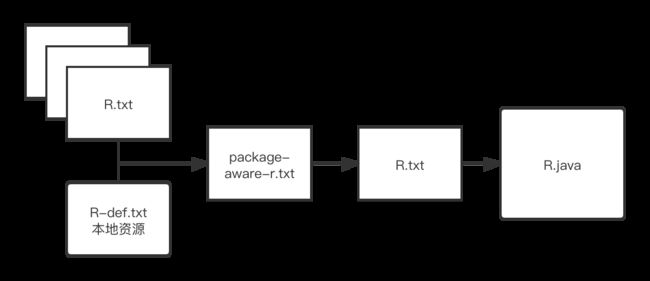
这是一个 module 生成 R.java 的过程。
首先,当前 module 会搜集所有它的依赖,并且拿到它的 R.txt。比如 lib1 依赖 lib2,lib2 依赖 recyclerview-1.0.0.aar,那么 lib1 会拿到这俩个 R.txt。其中
- lib2 的 R.txt 是经历了上图的过程已经生成好的了
- AAR 的 R.txt 是 AGP 在 transform 的时候从 aar 里面解压出来的
这样这个 module 就拿到了所有的依赖的资源。然后 AGP 会独处当前 module 的「本地资源」,结合刚刚拿到的所有依赖的 R.txt,生成 package-aware-r.txt.
它的格式是这样的
com.example.lib1 layout activity_in_lib2 string string_from_lib1 string string_from_lib2
第一行表示了它的 package name,是从 AndroidManifest.xml 里面取的,下面的几行表示这个 module 中所有的资源,包括自己的和依赖的别人的。
然后 AGP 就会根据 package-aware-r.txt 生成 R.txt,那 R.txt 里面的内容和 package-aware-r.txt 有什么不同呢?
int layout activity_in_lib2 0x7f0e0001 int string string_from_lib1 0x7f140001 int string string_from_lib2 0x7f140002
我们可以看到 R.txt 已经很接近我们的 R.java 的内容了。在从 package-aware-r.txt 拿到所有的资源后,AGP 为资源分配了「临时的 id」。
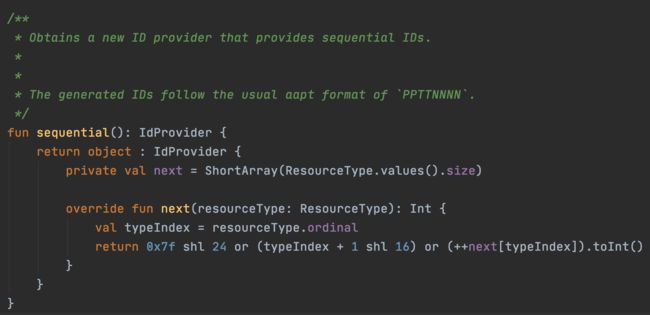
具体的分配逻辑如上,可以看到它维护了一个 “map”,每个资源的 id 都是从 0x7fxx0000 开始递增的。当然这里的分配逻辑没什么用,完全可以乱分配,反正最后也用不着。
最后一步就是通过 R.txt 生成 R.java 啦,AGP 会根据 R.txt 里面的资源及其 id 生成最后的 R.java,作为 classpath 供编译时使用。
这样一通操作下来,「此 project」也生成了 R.txt,当它的上层依赖在编译的时候,就可以拿到它的 R.txt 作为依赖,生成自己的 R.txt,重复上面的步骤。
另:
其实在 AGP 最新版本已经没有 R.java 了,取而代之的是 R.jar,R.jar 会把所有生成的 R.java 打成一个 jar 包,作为 classpath 来编译。可是这样做有什么好处呢?
看看 Jake 大神的说法:
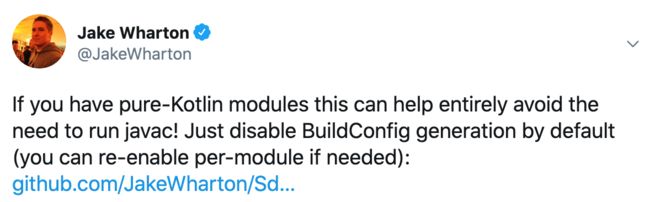
如果你的工程是纯 kotlin 工程,那 AGP 就不用启动一个 javac 去编译 R.java,这样会大幅提升编译的速度。(可见 Google 也在很努力的优化 AGP 了,高版本的 AGP 往往能带来很多性能上的优化。
AAPT 生成 R
终于来到了激动人心的时刻了,前面 AGP 生成了这么多 R.java 最后都要被丢掉,统统交给 aapt 去生成我们运行时需要的 R.java 了。
AGP 的高版本已经默认开启 aapt2 了,这里我们就直接看 aapt2 相关的代码。
首先 aapt2 其实是 Android SDK 里面的一个命令,用 c++ 编写。你可以运行一下 aapt2,看它的 readme。你也可以在 aapt2中找到它的说明。
$ANDROID_HOME/build-tools/29.0.2/aapt2
AGP
AGP 是通过 AaptV2CommandBuilder 来生成 aapt 的具体命令。
在 aapt2 中,为了实现增量编译,aapt2 将原来的编译拆成了 compile 和 link。aapt2 先将资源文件编译成 .flat 的中间产物,然后通过 link 将 .flat 中间产物编译成最终的产物。
AGP 对于 Module 模块调用的 link 命令如下:
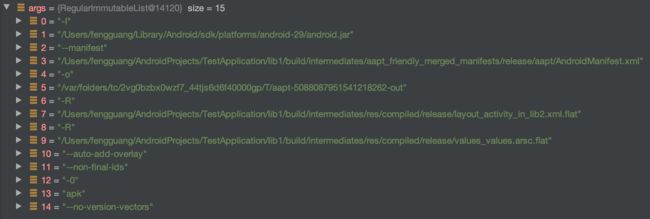
传入了 android.jar、AndroidManifest.xml、merge & compile 后的资源产物等等。
android.jar 是提供给代码去链接 Android 自身的资源,比如你使用了 @android:color/red 这个资源,就会从 android.jar 中去取。--non-final-ids 表示不要为 module 生成的 R.java 使用 final 字段,这个我们上面讨论过了。
对应的,application 生成的 aapt link 命令是这样的
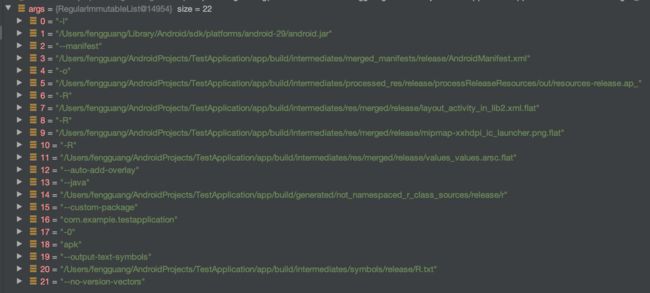
为 Application 生成的命令中就没有 --non-final-ids。还传入了一个 --java的参数,表示生成的 R.java 的存放路径,这里就是我们的 R 的最终存放路径了。
aapt 生成 R
调用 aapt2 命令之后就要开始执行 link 了,这里的代码比较多,就不一一啰嗦了。
我们抽一个 id 生成的逻辑来讲。
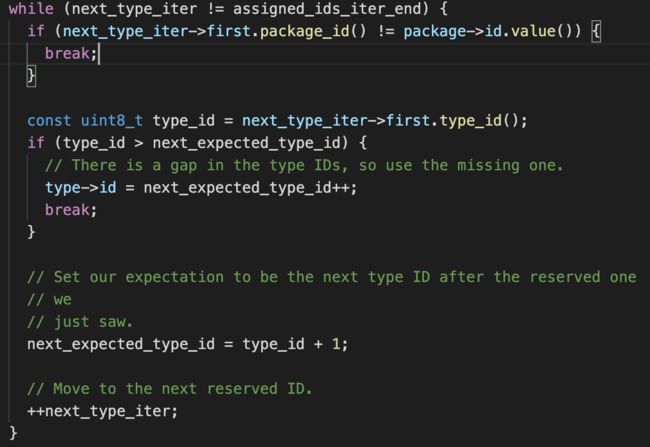
通过注释我们可以大概了解到:正常的话,id 是从 0 开始生成,每用一个会往后 +1。比如 string 是从 0x7f030000 开始,下一个 string 就是 0x7f030001。
如果你看过 aapt2 的命令,还会发现 aapt2 有个有意思的功能:「固定 id」
![]()
— emit-ids 会输出一个 resource name -> id 的映射表。
— stable-ids 可以输入一个 resource name -> 映射表,来决定这次生成的映射关系。

当有 — stable-ids 的输入时,aapt link 会解析这个文件,将映射表提前存入 stable_id_map 中。
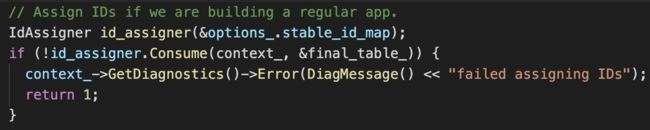
在构造 IdAssigner 的时候,将这个 map 传进去,IdAssigner 在遇到在 map 中存在的 resource 时,就会直接分配 map 表里面存的 id。其它的 resource 在分配的时候将会 “Fill the Gap”,找到空缺的 id 分配给它。
— stable-ids 在「热修复」、「插件化」中有很大的用处,我们知道,如果新增了一个资源,按照原来的分配逻辑,是会在原来的 id 里面插入一个新的 id 的。比如原来是
int string string_from_lib1 0x7f140001 int string string_from_lib2 0x7f140002 int string string_from_lib3 0x7f140003
这个时候,如果不固定 id,在 lib1 和 lib2 中间插入一个 lib4,它将会变成如下的样子
int string string_from_lib1 0x7f140001 int string string_from_lib4 0x7f140002 int string string_from_lib2 0x7f140003 int string string_from_lib3 0x7f140004
这就导致原来的 lib2 和 lib3 都发生了变动。
但是如果我们固定了 id,那生成的 id 可能就是以下这样
int string string_from_lib1 0x7f140001 int string string_from_lib4 0x7f140004 int string string_from_lib2 0x7f140002 int string string_from_lib3 0x7f140003
R 文件相关的优化
其实在细品了 R 文件生成的流程之后,我们发现其实在很多方向上 R 文件有优化的空间。
比如,我们可以在编译完成之后将 module 里面对于 R 的引用换成「内联」的,这样就可以少了一次内存寻址,也可以删掉被内联后的 R.class,减少了包体积又做了性能优化。
比如,我们可以在编译的时候通过固定 id 来减少增删改资源带来的大量 id 变动,导致 R.java 被“连根拔起”,带来下游依赖它的 java/kotlin 文件重新编译。
agp 4.1.0升级如下:
App size significantly reduced for apps using code shrinking
Starting with this release, fields from R classes are no longer kept by default, which may result in significant APK size savings for apps that enable code shrinking. This should not result in a behavior change unless you are accessing R classes by reflection, in which case it is necessary to add keep rules for those R classes.
从标题看 apk 包体积有显著减少(这个太有吸引力了),通过下面的描述,大致意思是不再保留 R 的 keep 规则,也就是 app 中不再包括 R 文件?(要不怎么减少包体积的)
在分析这个结果之前先介绍下 apk 中,R 文件冗余的问题;
R 文件冗余问题
android 从 ADT 14 开始为了解决多个 library 中 R 文件中 id 冲突,所以将 Library 中的 R 的改成 static 的非常量属性。
在 apk 打包的过程中,module 中的 R 文件采用对依赖库的R进行累计叠加的方式生成。如果我们的 app 架构如下:
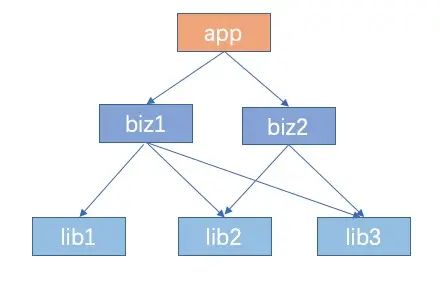
编译打包时每个模块生成的 R 文件如下:
- R_lib1 = R_lib1;
- R_lib2 = R_lib2;
- R_lib3 = R_lib3;
- R_biz1 = R_lib1 + R_lib2 + R_lib3 + R_biz1(biz1本身的R)
- R_biz2 = R_lib2 + R_lib3 + R_biz2(biz2本身的R)
- R_app = R_lib1 + R_lib2 + R_lib3 + R_biz1 + R_biz2 + R_app(app本身R)
在最终打成 apk 时,除了 R_app(因为 app 中的 R 是常量,在 javac 阶段 R 引用就会被替换成常量,所以打 release 混淆时,app 中的 R 文件会被 shrink 掉),其余的 R 文件全部都会打进 apk 包中。这就是 apk 中 R 文件冗余的由来。而且如果项目依赖层次越多,上层的业务组件越多,将会导致 apk 中的 R 文件将急剧的膨胀。
R 文件内联(解决冗余问题)
系统导致的冗余问题,总不会难住聪明的程序员。在业内目前已经有一些R文件内联的解决方案。大致思路如下:
由于 R_app 是包括了所有依赖的的 R,所以可以自定义一个 transform 将所有 library module 中 R 引用都改成对 R_app 中的属性引用,然后删除所有依赖库中的 R 文件。这样在 app 中就只有一个顶层 R 文件。(这种做法不是非常彻底,在 apk 中仍然保留了一个顶层的 R,更彻底的可以将所有代码中对 R 的引用都替换成常量,并在 apk 中删除顶层的 R )
agp 4.1.0 R 文件内联
首先我们分别用 agp 4.1.0 和 agp 3.6.0 构建 apk 进行一个对比,从最终的产物来确认下是否做了 R 文件内联这件事。
测试工程做了一些便于分析的配置,配置如下:
- 开启 proguard
buildTypes {
release {
minifyEnabled true // 打开
proguardFiles getDefaultProguardFile('proguard-android-optimize.txt'), 'proguard-rules.pro'
}
}
- 关闭混淆,仅保留压缩和优化(避免混淆打开,带来的识别问题)
// proguard-rules.pro中配置
-dontobfuscate
构建 release 包。
先看下 agp 3.6.0 生成的 apk:
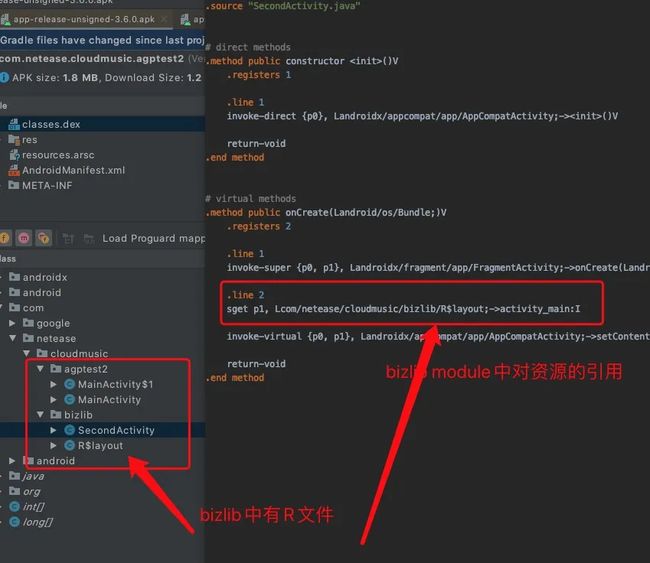
从图中可以看到 bizlib module 中会有 R 文件,查看 SecondActivity 的 byte code ,会发现内部有对 R 文件的引用。
接着再来看 agp 4.1.0 生成的 apk:
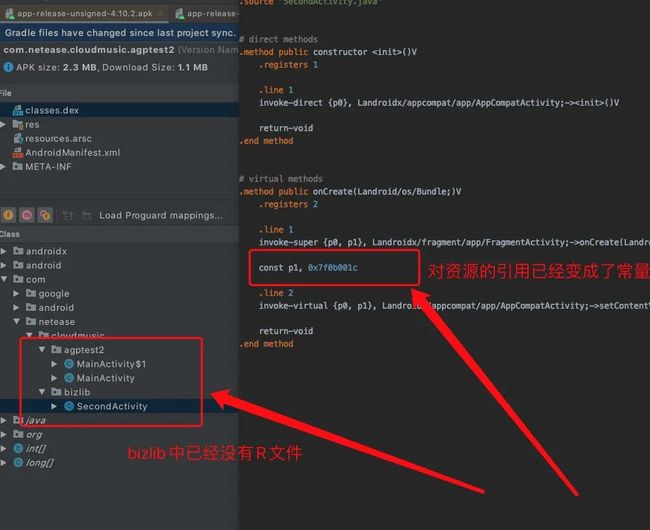
可以看到,bizlib module 中已经没有 R 文件,并且查看 SecondActivity 的 byte code ,会发现内部的引用已经变成了一个常量。
由此可以确定,agp 4.1.0 是做了对 R 文件的内联,并且做的很彻底,不仅删除了冗余的 R 文件,并且还把所有对 R 文件的引用都改成了常量。
具体分析
现在我们来具体分析下 agp 4.1.0 是如何做到 R 内联的,首先我们大致分析下,要对 R 做内联,基本可以猜想到是在 class 到 dex 这个过程中做的。确定了大致阶段,那接下看能不能从构建产物来缩小相应的范围,最好能精确到具体的 task。(题外话:分析编译相关问题一般四板斧:1. 先从 app 的构建产物里面分析相应的结果;2.涉及到有依赖关系分析的可以将所有 task 的输入输出全部打印出来;3. 1、2满足不了时,会考虑去看相应的源码;4. 最后的大招就是调试编译过程;)
首先我们看下构建产物里面的 dex,如下图:
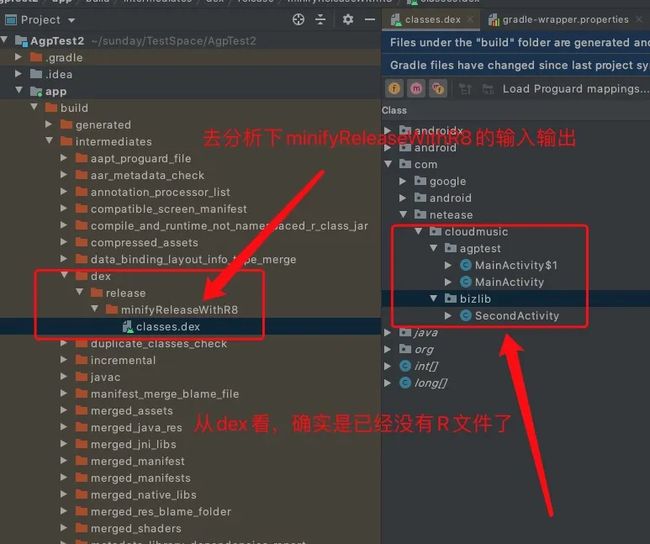
接下来在 app module 中增加所有 task 输入输出打印的 gradle 脚本来辅助分析,相关脚本如下:
gradle.taskGraph.afterTask { task ->
try {
println("---- task name:" + task.name)
println("-------- inputs:")
task.inputs.files.each { it ->
println(it.absolutePath)
}
println("-------- outputs:")
task.outputs.files.each { it ->
println(it.absolutePath)
}
} catch (Exception e) {
}
}
minifyReleaseWithR8 相应的输入输出如下:
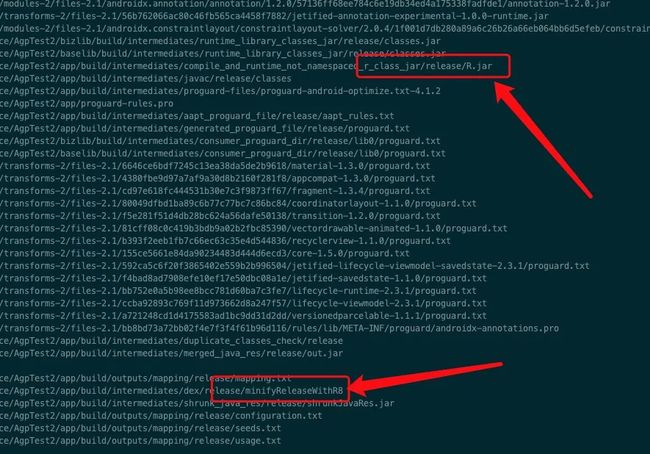
从图中可以看出,输入有整个 app 的 R 文件的集合(R.jar),所以基本明确 R 的内联就是在 minifyReleaseWithR8 task 中处理的。
接下来我们就具体分析下这个 task。
具体的逻辑在 R8Task.kt 里面.
创建 minifyReleaseWithR8 task 代码如下:
class CreationAction(
creationConfig: BaseCreationConfig,
isTestApplication: Boolean = false
) : ProguardConfigurableTask.CreationAction(creationConfig, isTestApplication) {
override val type = R8Task::class.java
// 创建 minifyReleaseWithR8 task
override val name = computeTaskName("minify", "WithR8")
.....
}
task 执行过程如下(由于代码过多,下面仅贴出部分关键节点):
// 1. 第一步,task 具体执行
override fun doTaskAction() {
......
// 执行 shrink 操作
shrink(
bootClasspath = bootClasspath.toList(),
minSdkVersion = minSdkVersion.get(),
......
)
}
// 2. 第二步,调用 shrink 方法,主要做一些输入参数和配置项目的准备
companion object {
fun shrink(
bootClasspath: List,
......
) {
......
// 调用 r8Tool.kt 中的顶层方法,runR8
runR8(
filterMissingFiles(classes, logger),
output.toPath(),
......
)
}
// 3. 第三步,调用 R8 工具类,执行混淆、优化、脱糖、class to dex 等一系列操作
fun runR8(
inputClasses: Collection,
......
) {
......
ClassFileProviderFactory(libraries).use { libraryClasses ->
ClassFileProviderFactory(classpath).use { classpathClasses ->
r8CommandBuilder.addLibraryResourceProvider(libraryClasses.orderedProvider)
r8CommandBuilder.addClasspathResourceProvider(classpathClasses.orderedProvider)
// 调用 R8 工具类中的run方法
R8.run(r8CommandBuilder.build())
}
}
}
至此可以知道实际上 agp 4.1.0 中是通过 R8 来做到 R 文件的内联的。那 R8 是如果做到的呢?这里简要描述下,不再做具体代码的分析:
R8 从能力上是包括了 Proguard 和 D8(java脱糖、dx、multidex),也就是从 class 到 dex 的过程,并在这个过程中做了脱糖、Proguard 及 multidex 等事情。在 R8 对代码做 shrink 和 optimize 时会将代码中对常量的引用替换成常量值。这样代码中将不会有对 R 文件的引用,这样在 shrink 时就会将 R 文件删除。
当然要达到这个效果 agp 在 4.1.0 版本里面对默认的 keep 规则也要做一些调整,4.1.0 里面删除了 默认对 R 的 keep 规则,相应的规则如下:
-keepclassmembers class **.R$* {
public static;
}
总结
- 从 agp 对 R 文件的处理历史来看,android 编译团队一直在对R文件的生成过程不断做优化,并在 agp 4.1.0 版本中彻底解决了 R 文件冗余的问题。
- 编译相关问题分析思路:
- 先从 app 的构建产物里面分析相应的结果;
- 涉及到有依赖关系分析的可以将所有 task 的输入输出全部打印出来;
- 1、2满足不了时,会考虑去看相应的源码;
- 最后的大招就是调试编译过程;
- 从云音乐 app 这次 agp 升级的效果来看,app 的体积降低了接近 7M,编译速度也有很大的提升,特别是 release 速度快了 10 分钟+(task 合并),整体收益还是比较可观的。
文章中使用的测试工程;
参考资料
- Shrink, obfuscate, and optimize your app
- r8
- Android Gradle plugin release notes