【Redis】Redis的内部设计与实现
Redis的设计、实现
数据结构和内部编码
type命令实际返回的就是当前键的数据结构类型,它们分别是:string(字符串)hash(哈希)、list(列表)、set(集合)、zset (有序集合),但这些只是Redis对外的数据结构。
实际上每种数据结构都有自己底层的内部编码实现,而且是多种实现,这样Redis会在合适的场景选择合适的内部编码。

每种数据结构都有两种以上的内部编码实现,例如list数据结构包含了linkedlist和ziplist两种内部编码。同时有些内部编码,例如ziplist,可以作为多种外部数据结构的内部实现,可以通过object encoding命令查询内部编码。
Redis这样设计有两个好处:
第一,可以改进内部编码,而对外的数据结构和命令没有影响,这样一旦开发出更优秀的内部编码,无需改动外部数据结构和命令,例如Redis3.2提供了quicklist,结合了ziplist和linkedlist两者的优势,为列表类型提供了一种更为优秀的内部编码实现,而对外部用户来说基本感知不到。
第二,多种内部编码实现可以在不同场景下发挥各自的优势,例如ziplist比较节省内存,但是在列表元素比较多的情况下,性能会有所下降,这时候Redis会根据配置选项将列表类型的内部实现转换为linkedlist。
redisobject对象
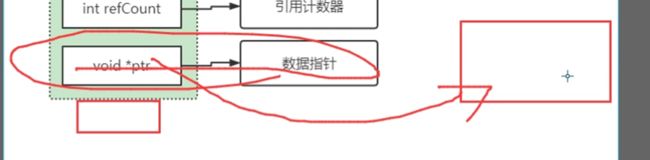
Redis存储的所有值对象在内部定义为redisobject结构体,内部结构如图所示。

Redis存储的数据都使用redis0bject来封装,包括string、hash、list、set,zset在内的所有数据类型。理解redis0bject对内存优化非常有帮助,下面针对每个字段做详细说明:
type字段
type字段:表示当前对象使用的数据类型,Redis主要支持5种数据类型:string, hash、 list,set,zset。可以使用type { key}命令查看对象所属类型,type命令返回的是值对象类型,键都是string类型。
encoding字段
encoding 字段 :表示Redis内部编码类型,encoding在 Redis内部使用,代表当前对象内部采用哪种数据结构实现。理解Redis内部编码方式对于优化内存非常重要,同一个对象采用不同的编码实现内存占用存在明显差异。
lru字段
lru字段:记录对象最后次被访问的时间,当配置了maxmemory和maxmemory-policy=volatile-lru或者allkeys-lru时,用于辅助LRU算法删除键数据。可以使用object idletime {key}命令在不更新lru字段情况下查看当前键的空闲时间。
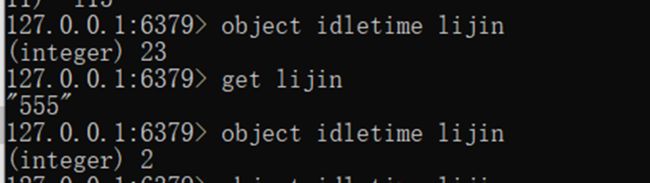
可以使用scan +object idletime 命令批量查询哪些键长时间未被访问,找出长时间不访问的键进行清理, 可降低内存占用。
refcount字段
refcount字段:记录当前对象被引用的次数,用于通过引用次数回收内存,当refcount=0时,可以安全回收当前对象空间。使用object refcount(key}获取当前对象引用。当对象为整数且范围在[0-9999]时,Redis可以使用共享对象的方式来节省内存。
PS面试题,Redis的对象垃圾回收算法-----引用计数法。
*ptr字段
*ptr字段:与对象的数据内容相关,如果是整数,直接存储数据;否则表示指向数据的指针。
Redis新版本字符串且长度<=44字节的数据,字符串sds和redisobject一起分配,从而只要一次内存操作即可。
PS :高并发写入场景中,在条件允许的情况下,建议字符串长度控制在44字节以内,减少创建redisobject内存分配次数,从而提高性能。