大数据技术1:大数据架构设计理论
1、传统数据处理系统存在的问题
随着信息时代互联网技术爆炸式的发展,人们对于网络的依赖程度日渐加深,在业务中需要处理的数据量快速增加,逐渐飙升到了一个惊人的数量级。并且数据产生的速度随着采集与 处理技术的更新仍在加快。
数据量从兆字节(MB)、 吉 字 节 (GB) 的级别到现在的太字节 (TB)、柏 字 节 (PB) 级别,数据量的变化促使数据管理系统 (DBMS) 和数据仓库 (Data Warehouse,DW) 系统也在 悄然地变化着。传统应用的数据系统架构设计时,应用直接访问数据库系统。当用户访问量增 加时,数据库无法支撑日益增长的用户请求的负载,从而导致数据库服务器无法及时响应用户于数据修改的请求时,就需要增加多个工作处理层并发执行,数据库又将再次成为响应请求的 瓶颈。 一个解决办法是对数据库进行分区 (Horizontal Partitioning)。分区的方式通常以 Hash 值 作为 key 。这样就需要应用程序端知道如何去寻找每个key 所在的分区。

但即便如此,问题仍然会随着用户请求的增加接踵而来。当之前的分区无法满足负载时, 就需要增加更多分区,这时就需要对数据库进行reshard 。resharding 的工作非常耗时而痛苦,因 为需要协调很多工作,例如数据的迁移、更新客户端访问的分区地址,更新应用程序代码。如 果系统本身还提供了在线访问服务,对运维的要求就更高。这种情况下,就可能导致数据写到 错误的分区,因此必须要编写脚本来自动完成,且需要充分的测试。
由此可见,在数据层和应用中增加了缓冲隔离,数据量的日渐增多仍然迫使传统数据仓库 的开发者一次又一次挖掘系统,试图在各个方面寻找一点可提升的性能。架构变得越来越复杂, 增加了队列、分区、复制、重分区脚本 (Resharding Scripts)。应用程序还需要了解数据库的 schema, 并能访问到正确的分区。问题在于:数据库对于分区是不了解的,无法帮助你应对分 区、复制与分布式查询。
最严重的问题是系统并没有对人为错误进行工程设计,仅靠备份是不能治本的。归根结底, 系统还需要限制因为人为错误导致的破坏。然而,数据永不止步,传统架构的性能被压榨至极 限,检索数据的延迟和频繁的硬件错误问题逐渐使用户不可接受,在传统架构上进行继续挖掘 被证明是“挤牙膏”。帮助处理海量数据的新技术和新架构开发被提上日程,以求得让企业在现代竞争中占得先机。越来越多的开发者参与到新技术与新架构的研究探讨
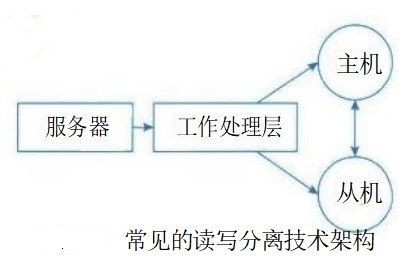
中,结论与成果逐渐丰硕。人们发现,当系统的用户访问量持续增加时,就需要考虑读写分离技术 (Master-Slave)和分库分表技术。常见读写分离技术架构如图19-2所示。
现在,数据处理系统的架构变得越来越复杂了,相比传统的数据库, 一次数据处理的过程增加了队列、分区、复制等处理逻辑。应用程序不仅仅需要了解数据的存储位置,还需要了解数据库的存储格式、数据组织结构 (schema) 等信息,才能访问到正确的数据。
随着技术的不断发展,商业现实也发生了变化。除了要求同一时间内可以处理的数据量提 升,现代商业要求更快做出的决定更有价值。现在,Kafka、Storm、Trident、Samza、Spark、 Flink 、Parquet 、Avro 、Cloud providers 等新技术成为了工程师和企业广泛采用的流行语。基 于新技术,不少企业开发了自己的数据处理方式,现代基于Hadoop 的 Map/Reduce 管 道 ( 使 用 Kafka,Avro 和数据仓库等现代二进制格式,即 Amazon Redshift,用于临时查询)采用了 如图所示。
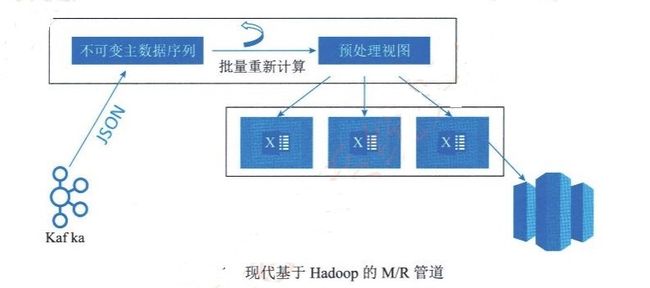
这个方式虽然看起来有其非常好的优势,但它仍然是一种传统的批处理方式,具有所有已 知的缺点,主要原因是客户端的数据在批处理花费大量时间完成之前的数据处理时,新的数据 已经进入而导致数据过时。
基于传统系统出现的上述问题和无数人对于新技术的渴求与探讨,“大数据”的概念被适时 的提出,研究与设计大数据系统成为了新的风潮。我们要学习的大数据系统架构设计理论,正 是为了解决在处理海量数据时出现的种种问题,并让系统在一定的度量属性下可以接受,成为 构造大数据系统的良好范式。
2、大数据处理系统架构分析
2.1 大数据处理系统面临挑战
当今,大数据的到来,已经成为现实生活中无法逃避的挑战。每当我们要做出决策的时候, 大数据就无处不在。大数据术语广泛地出现也使得人们渐渐明白了它的重要性。大数据渐渐向 人们展现了它为学术、工业和政府带来的巨大机遇。与此同时,大数据也向参与的各方提出了 巨大的挑战。那么主要挑战表现在以下三点。
(1)如何利用信息技术等手段处理非结构化和半结构化数据
大数据中,结构化数据只占15%左右,其余的85%都是非结构化的数据,它们大量存在 于社交网络、互联网和电子商务等领域。另一方面,也许有90%的数据来自开源数据,其余的 被存储在数据库中。大数据的不确定性表现在高维、多变和强随机性等方面。股票交易数据流 是不确定性大数据的一个典型例子。
大数据催生了大量研究问题。非结构化和半结构化数据的个体表现、 一般性特征和基本原 理尚不清晰,这些都需要通过包括数学、经济学、社会学、计算机科学和管理科学在内的多学 科交叉来研究和讨论。给定一种半结构化或非结构化数据,比如图像,如何把它转换成多维数 据表、面向对象的数据模型或者直接基于图像的数据模型?值得注意的是,大数据每一种表示 形式都仅为数据本身的一个侧面表现,并非全貌。
如果把通过数据挖掘提取“粗糙知识”的过程称为“一次挖掘”过程,那么将粗糙知识与被 量化后主观知识,包括具体的经验、常识、本能、情境知识和用户偏好,相结合而产生“智能 知识”过程就叫作“二次挖掘”。从“一次挖掘”到“二次挖掘”,就类似于事物由“量”到 “质”的飞跃。
由于大数据所具有的半结构化和非结构化特点,基于大数据的数据挖掘所产生的结构化的 “粗糙知识”(潜在模式)也伴有一些新的特征。这些结构化的粗糙知识可以被主观知识加工处 理并转化,生成半结构化和非结构化的智能知识。寻求“智能知识”反映了大数据研究的核心 价值。
(2)如何探索大数据复杂性、不确定性特征描述的刻画方法及大数据的系统建模
这一问题的突破是实现大数据知识发现的前提和关键。从长远角度来看,依照大数据的个 体复杂性和随机性所带来的挑战将促使大数据数学结构的形成,从而促使大数据统一理论日趋 完备。从短期而言,学术界鼓励发展一种一般性的结构化数据和半结构化、非结构化数据之间 的转换原则,以支持大数据的交叉工业应用。管理科学,尤其是基于最优化的理论将在大数据 知识发现的一般性方法和规律性的研究中发挥重要的作用。
大数据的复杂形式导致许多对“粗糙知识”的度量和评估相关的研究问题。已知的最优 化、数据包络分析、期望理论、管理科学中的效用理论可以被应用到研究如何将主观知识 融合到数据挖掘产生的粗糙知识的“二次挖掘”过程中。这里人机交互将起到至关重要的 作用。
(3)数据异构性与决策异构性的关系对大数据知识发现与管理决策的影响
由于大数据本身的复杂性,这一问题无疑是一个重要的科研课题,对传统的数据挖掘理论 和技术提出了新的挑战。在大数据环境下,管理决策面临着两个“异构性”问题:“数据异构性” 和“决策异构性”。传统的管理决策模式取决于对业务知识的学习和日益积累的实践经验,而管 理决策又是以数据分析为基础的。
大数据已经改变了传统的管理决策结构的模式。研究大数据对管理决策结构的影响会成为 一个公开的科研问题。除此之外,决策结构的变化要求人们去探讨如何为支持更高层次的决策 而去做“二次挖掘”。无论大数据带来了哪种数据异构性,大数据中的“粗糙知识”仍可被看作 “一次挖掘”的范畴。通过寻找“二次挖掘”产生的“智能知识”来作为数据异构性和决策异构性 之间的桥梁是十分必要的。探索大数据环境下决策结构是如何被改变的,相当于研究如何将决 策者的主观知识参与到决策的过程中。
大数据是一种具有隐藏法则的人造自然,寻找大数据的科学模式将带来对研究大数据之美 的一般性方法的探究,尽管这样的探索十分困难,但是如果我们找到了将非结构化、半结构化 数据转换成结构化数据的方法,已知的数据挖掘方法将成为大数据挖掘的工具。
2.2 大数据处理系统架构特征
Storm 之父Nathan Marz 在《大数据系统构建:可扩展实时数据系统构建原理与最佳实践》 一书中,提出了他认为大数据系统应该具有的属性。
(1)鲁棒性和容错性(Robust and Fault-tolerant )
对大规模分布式系统来说,机器是不可靠的,可能会宕机,但是系统需要是健壮、行为正 确的,即使是遇到机器错误。除了机器错误,人更可能会犯错误。在软件开发中难免会有一些 Bug, 系统必须对有Bug 的程序写入的错误数据有足够的适应能力,所以比机器容错性更加重 要的容错性是人为操作容错性。对于大规模的分布式系统来说,人和机器的错误每天都可能会 发生,如何应对人和机器的错误,让系统能够从错误中快速恢复尤其重要。
(2)低延迟读取和更新能力 (Low Latency Reads and Updates)
许多应用程序要求数据系统拥有几毫秒到几百毫秒的低延迟读取和更新能力。有的应用程 序允许几个小时的延迟更新,但是只要有低延迟读取与更新的需求,系统就应该在保证鲁棒性 的前提下实现。
(3)横向扩容 (Scalable)
当数据量/负载增大时,可扩展性的系统通过增加更多的机器资源来维持性能。也就是常 说的系统需要线性可扩展,通常采用scale out(通过增加机器的个数)而不是 scale up (通过增 强机器的性能)。
(4)通用性(General)
系统需要支持绝大多数应用程序,包括金融领域、社交网络、电子商务数据分析等。
(5)延展性(Extensible)
在新的功能需求出现时,系统需要能够将新功能添加到系统中。同时,系统的大规模迁移 能力是设计者需要考虑的因素之一,这也是可延展性的体现。
(6)即时查询能力 (Allows Ad Hoc Queries)
用户在使用系统时,应当可以按照自己的要求进行即席查询(Ad过系统多样化数据处理,产生更高的应用价值。
(7)最少维护能力(Minimal Maintenance)
系统需要在大多数时间下保持平稳运行。使用机制简单的组件和算法让系统底层拥有低复 杂度,是减少系统维护次数的重要途径。Marz 认为大数据系统设计不能再基于传统架构的增量 更新设计,要通过减少复杂性以减少发生错误的几率、避免繁重操作。
(8)可调试性 (Debuggable)
系统在运行中产生的每一个值,需要有可用途径进行追踪,并且要能够明确这些值是如何 产生的。