Python中用于机器学习的Lazy Predict库
Python是一种多功能语言,你可以用它来做任何事情。Python的一个伟大之处在于,有这么多的库使它变得更加强大。Lazy Predict就是其中一个库。它是机器学习和数据科学的一个很好的工具。在本文中,我们将了解它是什么,它做什么,以及如何使用它来使您的生活更轻松。
Lazy Predict是预测建模项目所需的一个工具。它是一个简单而高效的工具,使您的预测建模项目更容易,更快。Lazy Predict是一个Python库,提供了一种简单有效的预测方法。它易于使用,易于安装。Lazy Predict是开源的,并在MIT许可证下发布。
Lazy Predict如何帮助您使用机器学习模型实现更好的结果?
Lazy predict是一个功能强大的Python库,可以帮助您使用机器学习模型实现更好的结果。它为您提供了一种方便的方法来预处理数据、调整模型和评估结果。此外,它还提供了许多有用的功能,例如模型选择和超参数优化,可以帮助您充分利用机器学习模型。
在预测建模项目中使用Lazy Predict的好处:
如果您正在寻找一种工具来帮助您进行预测建模项目,请考虑使用Lazy Predict。它可以通过自动为您的模型生成代码来保存您的时间和精力。
Lazy Predict可以帮助您:
- 自动为模型生成代码,从而保存时间。
- 通过提供一致的代码生成方式来减少错误。
- 通过让你专注于其他任务来提高你的生产力。
如何开始使用Lazy Predict?
如果你是Python库世界的新手,那么你可能想知道如何开始使用Lazy Predict。这里有一个快速指南来帮助你开始。首先,你需要确保你的系统上安装了最新版本的Python。您可以通过访问Python网站并下载最新版本来实现这一点。
安装Python后,需要安装Lazy Predict库。您可以使用pip命令来完成此操作。打开一个终端窗口,输入以下内容:
pip install lazypredict
有效使用Lazy Predict的提示和技巧:
Lazy Predict是快速为数据生成预测的一个很好的工具。但是,在使用它以获得最准确的结果时,需要记住一些事情。
- 首先,确保您的数据是干净的,并为分析做好准备。这意味着删除任何无效或缺失的值,并确保所有数值都正确缩放。
- 接下来,注意将数据正确地划分为训练集和测试集。这将有助于避免过度拟合,并确保您的预测尽可能准确。
- 最后,注意你的预测的准确性。Lazy Predict并不完美,有时其结果可能不准确。如果你注意到你的预测是关闭的,尝试调整你的参数或使用不同的算法。
使用LazyRegressor进行回归任务示例
- Python库使我们能够非常容易地处理数据,并通过一行代码执行典型和复杂的任务。
- Pandas -此库有助于以2D数组格式加载数据框,并具有多个功能,可以一次性执行分析任务。
- Numpy - Numpy数组非常快,可以在很短的时间内执行大型计算。
- Matplotlib/Seaborn -此库用于绘制可视化。
- Sklearn -该模块包含多个库,这些库具有预实现的功能,可以执行从数据预处理到模型开发和评估的任务。
from sklearn import datasets
from sklearn.utils import shuffle
import numpy as np
# Importing LazyRegressor
from lazypredict.Supervised import LazyRegressor
在下面的步骤中,我们将从因变量或目标变量中分离独立特征。
# storing the Boston dataset in variable
boston = datasets.load_boston()
# loading and shuffling the dataset
X, y = shuffle(boston.data,
boston.target,
random_state=13)
offset = int(X.shape[0] * 0.9)
为了测试模型在看不见的数据上的性能,我们需要一些剩余的数据集,我们将数据以90:10的比例分成两部分,用于训练和测试目的。
# splitting dataset into training and testing part
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
现在让我们初始化LazyRegressor类的一个实例,然后我们将使用训练和测试数据调用这个实例的fit函数。
# fitting data in LazyRegressor because
# here we are solving Regression use case.
reg = LazyRegressor(verbose=0,
ignore_warnings=False,
custom_metric=None)
# fitting data in LazyClassifier
models, predictions = reg.fit(X_train, X_test,
y_train, y_test)
# lets check which model did better
# on Breast Cancer Dataset
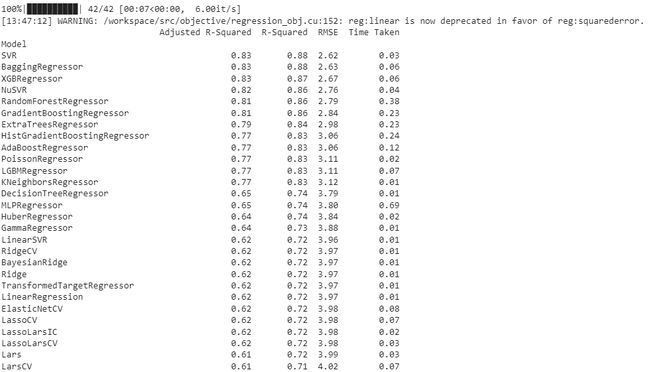
print(models)
使用LazyClassifier进行分类任务示例
现在,让我们尝试使用lazy predict库进行分类任务,以发现将拟合数据并测量性能的模型。为此,我们可以使用Sklearn库中的乳腺癌数据集。
# storing the Boston dataset in variable
canc = datasets.load_breast_cancer()
# loading and shuffling the dataset
X, y = shuffle(canc.data,
canc.target,
random_state=13)
offset = int(X.shape[0] * 0.9)
为了测试模型在看不见的数据上的性能,我们需要一些剩余的数据集,我们将数据以90:10的比例分成两部分,用于训练和测试目的。
# splitting dataset into training and testing part
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
现在让我们初始化LazyClassifier类的一个实例,然后我们将使用训练和测试数据调用这个实例的fit函数。
from lazypredict.Supervised import LazyClassifier
# fitting data in LazyRegressor because
# here we are solving Regression use case.
clf = LazyClassifier(verbose=0,
ignore_warnings=False,
custom_metric=None)
# fitting data in LazyClassifier
models, predictions = clf.fit(X_train, X_test,
y_train, y_test)
# lets check which model did better
# on Breast Cancer Dataset
print(models)
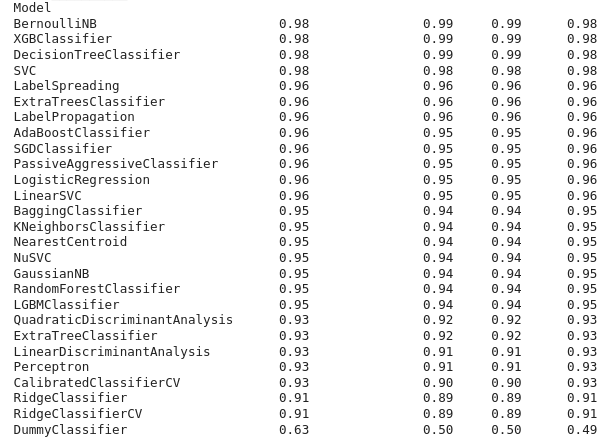
在上述输出中,数值列为准确度、平衡准确度、ROC - AUC和F1评分。这就是我们如何使用Lazy Predict库为特定任务构建回归器或分类器。
Lazy Predict是你写研究论文所需要的一个工具。它可以帮助你生成你的论文的部分内容,在一小部分的时间。它还可以帮助你格式化你的论文,使它看起来专业,易于阅读。