深度学习框架:Pytorch与Keras的区别与使用方法

☁️主页 Nowl
专栏《机器学习实战》 《机器学习》
君子坐而论道,少年起而行之

文章目录
Pytorch与Keras介绍
Pytorch
模型定义
模型编译
模型训练
输入格式
完整代码
Keras
模型定义
模型编译
模型训练
输入格式
完整代码
区别与使用场景
结语
Pytorch与Keras介绍

pytorch和keras都是一种深度学习框架,使我们能很便捷地搭建各种神经网络,但它们在使用上有一些区别,也各自有其特性,我们一起来看看吧
Pytorch

模型定义
我们以最简单的网络定义来学习pytorch的基本使用方法,我们接下来要定义一个神经网络,包括一个输入层,一个隐藏层,一个输出层,这些层都是线性的,给隐藏层添加一个激活函数Relu,给输出层添加一个Sigmoid函数
import torch
import torch.nn as nn
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(1, 32)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(32, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.Sigmoid(x)
return x模型编译
我们在之前的机器学习文章中反复提到过,模型的训练是怎么进行的呢,要有一个损失函数与优化方法,我们接下来看看在pytorch中怎么定义这些
import torch.optim as optim
# 实例化模型对象
model = SimpleNet()
# 定义损失函数
criterion = nn.MSELoss()
# 定义优化器
learning_rate = 0.01
optimizer = optim.SGD(model.parameters(), lr=learning_rate)我们上面创建的神经网络是一个类,所以我们实例化一个对象model,然后定义损失函数为mse,优化器为随机梯度下降并设置学习率
模型训练
# 创建随机输入数据和目标数据
input_data = torch.randn((100, 1)) # 100个样本,每个样本有1个特征
target_data = torch.randn((100, 1)) # 100个样本,每个样本有1个目标值
# 训练模型
epochs = 100
for epoch in range(epochs):
# 前向传播
output = model(input_data)
# 计算损失
loss = criterion(output, target_data)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()以上步骤是先创建了一些随机样本,作为模型的训练集,然后定义训练轮次为100次,然后前向传播数据集,计算损失,再优化,如此反复
输入格式
关于输入格式是很多人在实战中容易出现问题的,对于pytorch创建的神经网络,我们的输入内容是一个torch张量,怎么创建呢
data = torch.Tensor([[1], [2], [3]])很简单对吧,上面这个例子创建了一个torch张量,有三组数据,每组数据有1个特征
我们可以把这个数据输入到训练好的模型中,得到输出结果,如果输出不是torch张量,代码就会报错
完整代码
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的神经网络模型
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(1, 32)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(32, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.sigmoid(x)
return x
model = SimpleNet()
criterion = nn.MSELoss()
# 定义优化器
learning_rate = 0.01
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# 创建随机输入数据和目标数据
input_data = torch.randn((100, 1)) # 100个样本,每个样本有1个特征
target_data = torch.randn((100, 1)) # 100个样本,每个样本有1个目标值
# 训练模型
epochs = 100
for epoch in range(epochs):
# 前向传播
output = model(input_data)
# 计算损失
loss = criterion(output, target_data)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
data = torch.Tensor([[1], [2], [3]])
prediction = model(data)
print(prediction)
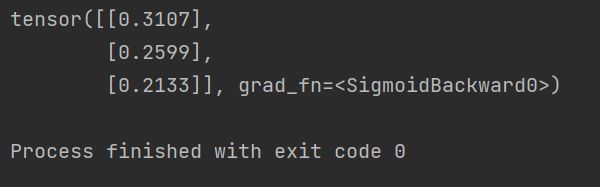
可以看到模型输出了三个预测值
注意,这个任务本身没有意义,因为我们的训练集是随机生成的,这里主要学习框架的使用方法
Keras

我们在这里把和上面相同的神经网络结构使用keras框架实现一遍
模型定义
from keras.models import Sequential
from keras.layers import Dense
model = Sequential([
Dense(32, input_dim=1, activation='relu'),
Dense(1, activation='sigmoid')
])注意这里也是一层输入层,一层隐藏层,一层输出层,和pytorch一样,输入层是隐式的,我们的输入数据就是输入层,上述代码定义了一个隐藏层,输入维度是1,输出维度是32,还定义了一个输出层,输入维度是32,输出维度是1,和pytorch环节的模型结构是一样的
模型编译
那么在Keras中模型又是怎么编译的呢
model.compile(loss='mse', optimizer='sgd')非常简单,只需要这一行代码 ,设置损失函数为mse,优化器为随机梯度下降
模型训练
模型的训练也非常简单
# 训练模型
model.fit(input_data, target_data, epochs=100)因为我们已经编译好了损失函数和优化器,在fit里只需要输入数据,输出数据和训练轮次这些参数就可以训练了
输入格式
对于Keras模型的输入,我们要把它转化为numpy数组,不然会报错
data = np.array([[1], [2], [3]])完整代码
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# 定义模型
model = Sequential([
Dense(32, input_dim=1, activation='relu'),
Dense(1, activation='sigmoid')
])
# 创建随机输入数据和目标数据
input_data = np.random.randn(100, 1) # 100个样本,每个样本有10个特征
target_data = np.random.randn(100, 1) # 100个样本,每个样本有5个目标值
# 编译模型
model.compile(loss='mse', optimizer='sgd')
# 训练模型
model.fit(input_data, target_data, epochs=10)
data = np.array([[1], [2], [3]])
prediction = model(data)
print(prediction)可以看到,同样的任务,Keras的代码量小很多
区别与使用场景
Keras代码量少,使用便捷,适用于快速实验和快速神经网络设计
而pytorch由于结构是由类定义的,可以更加灵活地组建神经网络层,这对于要求细节的任务更有利,同时,pytorch还采用动态计算图,使得模型的结构可以在运行时根据输入数据动态调整,但这个特点我还没有接触到,之后可能会详细讲解
结语
Keras和Pytorch都各有各的优点,请读者根据需求选择,同时有些深度学习教程偏向于使用某一种框架,最好都学习一点,以适应不同的场景
感谢阅读,觉得有用的话就订阅下本专栏吧