C语言小白速成笔记
一、初始C程序
1.一个c程序是由若干头文件和函数组成
2.c程序有且只有一个主函数,即main函数。主函数就是c语言中的唯一入口
3.规范:(1)一个说明或一个语句占一行。别学书上那样堆一起写,太难看了。
(2)函数体内语句要有明显缩进,按tab就行,或者两个空格(不推荐)
(3)括号要成对
(4)当一句可执行语句结束的时候末尾需要有分号
(5)代码中所有符号均为英文半角符号,可在输入法内调整切换输入法方式,将shift换成ctrl+space,可以有效防止中英文标点错误的问题
4.注释:
//为单行注释
/* */为多行注释
编程时可用ctrl+/将所选内容全部注释
二、基本元素
1.标识符:
(1)标识符可以是字母(A~Z,a~z)、数字(0~9)、下划线_组成的字符串,并且第一个字符必须是字母或下划线
(2)标识符的长度最好不要超过8位,因为在某些版本的C中规定标识符前8位有效,当两个标识符前8位相同时,则被认为是同一个标识符
(3)标识符是严格区分大小写的
(4)标识符最好选择有意义的英文单词组成做到"见名知意",不要使用中文。增强代码的可读性,做一名优雅的程序员
(5)标识符不能是C语言的关键字
2.关键字:
(1) char :声明字符型变量或函数
(2) double :声明双精度变量或函数
(3) enum :声明枚举类型
(4) float:声明浮点型变量或函数
(5) int: 声明整型变量或函数
(6) long :声明长整型变量或函数
(7) short :声明短整型变量或函数
(8) signed:声明有符号类型变量或函数
(9) struct:声明结构体变量或函数
(10) union:声明共用体(联合)数据类型
(11) unsigned:声明无符号类型变量或函数
(12) void :声明函数无返回值或无参数,声明无类型指针
(13) for:一种循环语句(可意会不可言传)
(14) do :循环语句的循环体
(15) while :循环语句的循环条件
(16) break:跳出当前循环
(17) continue:结束当前循环,开始下一轮循环
(18)if: 条件语句
(19)else :条件语句否定分支(与 if 连用)
(20)goto:无条件跳转语句
(21)switch :用于开关语句
(22)case:开关语句分支
(23)default:开关语句中的“其他”分支
(24)return :子程序返回语句
(25)auto :声明自动变量 一般不使用
(26)extern:声明变量是在其他文件正声明(也可以看做是引用变量)
(27)register:声明积存器变量
(28)static :声明静态变量
(29)const :声明只读变量
(30)sizeof:计算数据类型长度
(31)typedef:用以给数据类型取别名(当然还有其他作用
(32)volatile:说明变量在程序执行中可被隐含地改变
此外,dev c++里编程时,由于c++兼容大部分的c,所以在cpp下,class仍会被当做关键词
3.字符集:
(1)26个大写字母 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z (2)26个小写字母 a b c d e f g h i j k l m n o p q r s t u v w x y z (3)10个十进制数字字符 0 1 2 3 4 5 6 7 8 9 (4)29个图形字符 ! " # % & ’ ( ) * + , - . / : ; < = > ? [ \ ] ^ _ { 竖线 } ~ (5)空格字符 (6)3个控制字符(横向制表\t、纵向制表\v、换页\f)
三、基本数据类型
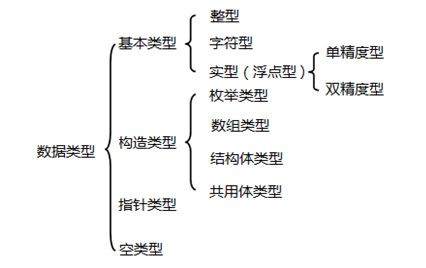
1.整型:
整型数据是指不带小数的数字,int,short,long,unsigned
2.字符型:
char
3.实型:
(1)单精度型:float,字节4,小数点后6位
(2)双精度:double,字节8,小数点后12位
(3)长双精度:long double,字节16,小数点后18位
四、运算符和表达式
1.运算符种类:
算术运算符、 赋值运算符、关系运算符、逻辑运算符、三目运算符
2.自增与自减运算符

3.赋值运算符:
+= -= *= /= %=
a=a+3 ----->a+=3
4.关系运算符:
>= < <= == !=
c语言中不能1
由于电脑是电子元件构成,状态只有通和断,所以正确时返回1,错误时返回0
5.逻辑运算符:
(1)与运算(&&)
参与运算的两个变量都为真时,结果才为真,否则为假。例如:5>=5 && 7>5 ,运算结果为真;
(2)或运算(||)
参与运算的两个变量只要有一个为真,结果就为真。 两个量都为假时,结果为假。例如:5>=5||5>8,运算结果为真;
(3)非运算(!)
参与运算的变量为真时,结果为假;参与运算量为假时,结果为真
6.三目运算符:表达式1?表达式2:表达式3;
先判断表达式1的值是否为真,如果是真的话执行表达式2;如果是假的话执行表达式3
7.算术运算符:
(1)如果是int/int,则结果为整数,且四舍五入只舍不入,应使一个为浮点型即可
(2)%只可用于两个整数
8.运算符优先级:
| 优先级 | 运算符 | 名称或含义 | 使用形式 | 结合方向 | 说明 |
|---|---|---|---|---|---|
| 1 | [] | 数组下标 | 数组名[常量表达式] | 左到右 | -- |
| () | 圆括号 | (表达式)/函数名(形参表) | -- | ||
| . | 成员选择(对象) | 对象.成员名 | -- | ||
| -> | 成员选择(指针) | 对象指针->成员名 | -- | ||
| 2 | - | 负号[运算符] | -表达式 | 右到左 | 单目运算符 |
| ~ | 按位取反运算符 | ~表达式 | |||
| ++ | 自增运算符 | ++变量名/变量名++ | |||
| -- | 自减运算符 | --变量名/变量名-- | |||
| * | 取值运算符 | *指针变量 | |||
| & | 取地址运算符 | &变量名 | |||
| ! | 逻辑非运算符 | !表达式 | |||
| (类型 *) | 强制类型转换 | (数据类型)表达式 | -- | ||
| sizeof | 长度运算符 | sizeof(表达式) | -- | ||
| 3 | / | 除 | 表达式/表达式 | 左到右 | 双目运算符 |
| * | 乘 | 表达式*表达式 | |||
| % | 余数(取模) | 整型表达式%整型表达式 | |||
| 4 | + | 加 | 表达式+表达式 | 左到右 | 双目运算符 |
| - | 减 | 表达式-表达式 | |||
| 5 | << | 左移 | 变量<<表达式 | 左到右 | 双目运算符 |
| >> | 右移 | 变量>>表达式 | |||
| 6 | > | 大于 | 表达式>表达式 | 左到右 | 双目运算符 |
| >= | 大于等于 | 表达式>=表达式 | |||
| < | 小于 | 表达式<表达式 | |||
| <= | 小于等于 | 表达式<=表达式 | |||
| 7 | == | 等于 | 表达式==表达式 | 左到右 | 双目运算符 |
| != | 不等于 | 表达式!= 表达式 | |||
| 8 | & | 按位与 | 表达式&表达式 | 左到右 | 双目运算符 |
| 9 | ^ | 按位异或 | 表达式^表达式 | 左到右 | 双目运算符 |
| 10 | | | 按位或 | 表达式|表达式 | 左到右 | 双目运算符 |
| 11 | && | 逻辑与 | 表达式&&表达式 | 左到右 | 双目运算符 |
| 12 | || | 逻辑或 | 表达式||表达式 | 左到右 | 双目运算符 |
| 13 | ?: | 条件运算符 | 表达式1?表达式2: 表达式3 | 右到左 | 三目运算符 |
| 14 | = | 赋值运算符 | 变量=表达式 | 右到左 | -- |
| /= | 除后赋值 | 变量/=表达式 | -- | ||
| *= | 乘后赋值 | 变量*=表达式 | -- | ||
| %= | 取模后赋值 | 变量%=表达式 | -- | ||
| += | 加后赋值 | 变量+=表达式 | -- | ||
| -= | 减后赋值 | 变量-=表达式 | -- | ||
| <<= | 左移后赋值 | 变量<<=表达式 | -- | ||
| >>= | 右移后赋值 | 变量>>=表达式 | -- | ||
| &= | 按位与后赋值 | 变量&=表达式 | -- | ||
| ^= | 按位异或后赋值 | 变量^=表达式 | -- | ||
| |= | 按位或后赋值 | 变量|=表达式 | -- | ||
| 15 | , | 逗号运算符 | 表达式,表达式,… | 左到右 | -- |
五、输入与输出
1.输入:
(1)scanf:录入输入的数据
scanf在录到空格时会停止录入,如果需要空格,应使用fgets和gets
或者运用正则表达式scanf("%[ ^\n ]",string);意为一直读取到回车键为止,记得用完要清理缓冲区
(2)fscanf:从fp指向的文件的当前位置,顺序读取ASCII码值,按照fomat规定的格式转化为各个变量对应的值,送入指定变量,操作文件时使用。
用法:fscanf(fp,format,&arg1,&arg2,…,&argn); format:格式说明字符串;&arg1…&argn:输入变量的地址列表
(3)gets与fgets
gets函数功能:从键盘上输入字符,直至接受到换行符或EOF时停止,并将读取的结果存放在buffer指针所指向的字符数组中。读取的换行符被转换为null值,做为字符数组的最后一个字符,来结束字符串
fgets函数功能:从文件指针stream中读取字符,存到以s为起始地址的空间里,知道读完N-1个字符,或者读完一行。注意:调用fgets函数时,最多只能读入n-1个字符。读入结束后,系统将自动在最后加’\0’,并以str作为函数值返回
fgets可以在Linux系统里使用,gets不行
(4)sscanf:从一个字符串中读进于指定格式相符的数据。利用它可以从字符串中取出整数、浮点数和字符串。
sscanf和scanf的区别:scanf是以键盘作为输入源,sscanf是以字符串作为输入源
2.输出:
(1)printf:printf() 是 C 语言标准库函数,用于将格式化后的字符串输出到标准输出。标准输出,即标准输出文件,对应终端的屏幕
格式控制字符串组成:
% [ 标志 ] [ 最小宽度 ] [.精度] [类型长度]类型
(2)fprintf:
用法:fprintf(fp,format,arg1,arg2,…,argn); format:格式说明字符串;arg1…argn:输出参数个数表 功能:按指定的格式(format)将输出列表arg1…argn的值转换成对应的ASCII码表示形式,写入fp文件的当前位置
例如:fprintf(fp,"%d,%x,%u",123,145,12);
(3)puts与fputs:
puts()函数只能输出字符串,其他类型的不能输出,puts()函数会在输出之后打印'n',并且是不管你有没有'\n'都要打印一个'\n'
puts和fputs比较,只不过fputs多了一个参数stdout,并且它不会默认在输出之后打印一个'\n'
六、选择结构:
1.多重if:
if else if else
记住不管下面是几行,一定要打 { }
2.嵌套if:
if之内再if
3.switch:

不要忘记加break,不然会一直往后推进,用于选择模式挺好用的,总不能一直套if吧
七、循环结构
1.while do while for三种循环语句的区别:
(1)在知道循环次数的情况下更适合使用for循环
(2)在不知道循环次数的情况下适合使用while或者do-while循环
(3)如果有可能一次都不循环应考虑使用while循环,如果至少循环一次应考虑使用do-while循环
2.continue:
跳出本次循环,进入下次循环
3.break:
跳出本级循环
break语句与continue语句的区别是:break是跳出当前整个循环,continue结束本次循环开始下一次循环
4.goto:
有的时候挺好的,直接返回,多省事,但是确实,如果用多了,它可能会乱传,所以能不用就不用
八、数组
1.基本概念:
它在程序中是一块连续的,大小固定并且里面的数据类型一致的内存空间,它还有个好听的名字叫数组
2.一维数组:
(1)声明:数据类型 数组名称[长度];
(2)初始化:
数据类型 数组名称[长度n] = {元素1,元素2…元素n};
数据类型 数组名称[] = {元素1,元素2…元素n};
数据类型 数组名称[长度n]; 数组名称[0] = 元素1; 数组名称[1] = 元素2; 数组名称[n-1] = 元素n;
(3)引用:数组名称[元素所对应下标];
注意:
(1)数组的下标均以0开始;
(2)数组在初始化的时候,数组内元素的个数不能大于声明的数组长度;
(3)如果采用第一种初始化方式,元素个数小于数组的长度时,多余的数组元素初 始化为0;
(4)在声明数组后没有进行初始化的时候,静态(static)和外部(extern)类型的 数组元素初始化元素为0,自动(auto)类型的数组的元素初始化值不确定
3.多维数组:
(1)定义:数据类型 数组名称[常量表达式1] [常量表达式2]...[常量表达式n];
(2)

(3)初始化:
数据类型 数组名称[常量表达式1] [常量表达式2]...[常量表达式n] = {{值1,..,值n},{值1,..,值n},...,{值1,..,值n}};
数据类型 数组名称[常量表达式1] [常量表达式2]...[常量表达式n]; 数组名称[下标1] [下标2]...[下标n] = 值;
注意:
(1)采用第一种始化时数组声明必须指定列的维数。因为系统会根据数组中元素的 总个数来分配空间,当知道元素总个数以及列的维数后,会直接计算出行的维数;
(2)采用第二种初始化时数组声明必须同时指定行和列的维数
(4)引用:相似一维数组,下标为前行后列
4.字符串数组:
在C语言中,是没有办法直接定义字符串数据类型的,但是我们可以使用数组来定义我们所要的字符串
(1)定义:
char 字符串名称[长度] = "字符串值";
char 字符串名称[长度] = {'字符1','字符2',...,'字符n','\0'};
注意:
[]中的长度是可以省略不写的,所以不确定的时候别写,防止溢出
采用第2种方式的时候最后一个元素必须是'\0','\0'表示字符串的结束标志
采用第2种方式的时候在数组中不能写中文
(2)字符串组成的数组:
必须使用二维数组,行代表一个字符串,列代表字符串里的单个子符
5.字符串函数:
(1)strlen:获取字符串的长度,在字符串长度中是不包括‘\0’而且汉字和字母的长度是不一样的

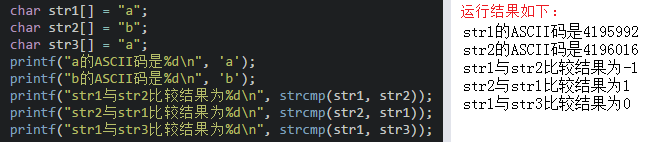
(2)strcmp:比较的时候会把字符串先转换成ASCII码再进行比较,返回的结果为0表示s1和s2的ASCII码相等,返回结果为1表示s1比s2的ASCII码大,返回结果为-1表示s1比s2的ASCII码小
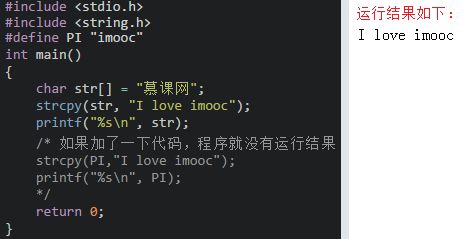
(3)strcpy:拷贝之后会覆盖原来字符串且不能对字符串常量进行拷贝
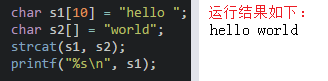
(4)strcat:在使用时s1与s2指的内存空间不能重叠,且s1要有足够的空间来容纳要复制的字符串。去插入一些元素的时候,创建一个新数组再strcat真的超级方便,血的教训
(5)strlwr:该函数的作用是将字符串中的大写字母转换成小写字母
(6)strupr:该函数的作用是将字符串中的小写字母转换成大写字母
(7)strstr:strstr(字符串1,字符串2))——查找字符串的函数
函数用于判断字符串str2是否是str1的子串。如果是,则该函数返回str2在str1中首次出现的地址;否则,返回NULL
???那作业不是秒杀吗???我是写到这才发现的。。。。。。
6.数组的应用:
(1)冒泡排序:相邻元素两两比较,将较大的数字放在后面,直到将所有数字全部排序
例:十个数比大小
for(i=8;i>=0;i--)
{
for(j=0;j<=i;j++)
{
if(arr[ j ] > arr[ j+1 ])
{ int temp;
temp = arr[ j ];
arr[ j ] = arr[ j+1 ];
arr[ j+1 ] = temp;
}
}
}
(2)查找元素:
for循环遍历数组,用分函数return下标到主函数,不能直接在主函数里面return,会直接退出,最后用索引值找到元素
现在知道了,还可以用strstr函数,绷不住
九、函数
1.自创函数:

(1)[ ]包含的内容可以省略,数据类型说明省略,默认是int类型函数;参数省略表示该函数是无参函数,参数不省略表示该函数是有参函数;
(2)函数名称遵循标识符命名规范;
(3)自定义函数尽量放在main函数之前,如果要放在main函数后面的话,需要在main函数之前先声明自定义函数,声明格式为:[数据类型说明] 函数名称([参数])
个人习惯放在后面,把主函数放在最上面,加上注释,让人一目了然
2.调用函数:
函数名([参数]);
(1)嵌套:自创函数的好处在于:非线性,可交叉,一个功能可到处使用,多次,多级使用,且使用完可以立即释放内存,所以学会自创函数是每个c语言学者要学会的事情
(2)递归:递归就是一个函数在它的函数体内调用它自身。自己用自己,达到实现动态改变,递归呈现的目的
3.参数:
(1)有参与无参:
有参函数和无参函数的唯一区别在于:函数()中多了一个参数列表。本质上无大区别,如果要调用函数外的数据,则需要传参
(2)实参与形参:
形参只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只有在函数内部有效。函数调用结束返回主调函数后则不能再使用该形参变量。
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须具有确定的值,以便把这些值传送给形参。因此应预先用赋值等办法使实参获得确定值。
在参数传递时,实参和形参在数量上,类型上,顺序上应严格一致,否则会发生类型不匹配”的错误。
(3)传参:用什么,传什么,传不了,用指针
4.内部与外部函数:
(1)在C语言中不能被其他源文件调用的函数称谓内部函数 ,内部函数由static关键字来定义,因此又被称谓静态函数,形式为:
static [数据类型] 函数名([参数])
(2)在C语言中能被其他源文件调用的函数称谓外部函数 ,外部函数由extern关键字来定义,形式为:
extern [数据类型] 函数名([参数])
C语言默认所有函数都是外部函数
十、变量
1.局部与全局变量:
局部变量也称为内部变量。局部变量是在函数内作定义说明的。其作用域仅限于函数内, 离开该函数后再使用这种变量是非法的。在复合语句中也可定义变量,其作用域只在复合语句范围内。
全局变量也称为外部变量,它是在函数外部定义的变量。它不属于哪一个函数,它属于一个源程序文件。其作用域是整个源程序。
2.变量的存储类型:
(1)静态存储方式:是指在程序运行期间分配固定的存储空间的方式。静态存储区中存放了在整个程序执行过程中都存在的变量,如全局变量。
(2)动态存储方式:是指在程序运行期间根据需要进行动态的分配存储空间的方式。动态存储区中存放的变量是根据程序运行的需要而建立和释放的,通常包括:函数形式参数;自动变量;函数调用时的现场保护和返回地址等
(3)自动:用关键字auto定义的变量为自动变量,auto可以省略,auto不写则隐含定为“自动存储类别”,属于动态存储方式
(4)静态:用static修饰的为静态变量,如果定义在函数内部的,称之为静态局部变量;如果定义在函数外部,称之为静态外部变量
注意:
在静态存储区内分配存储单元,在程序整个运行期间都不释放
(5)寄存器:为了提高效率,C语言允许将局部变量得值放在CPU中的寄存器中,这种变量叫“寄存器变量”,用关键字register作声明。别乱用!寄存器很重要,别随便什么东西都放进去
(6)外部:用extern声明的的变量是外部变量,外部变量的意义是某函数可以调用在该函数之后定义的变量
十一、结构体
1.结构体的定义:
只有结构体变量才分配地址,而结构体的定义是不分配空间的
结构体中各成员的定义和之前的变量定义一样,但在定义时也不分配空间
(1)常规定义 (2)声明的同时定义
struct time{ struct student{
int........... char........
int.......... char........
}; }Alan,Tom;
struct time t;
*这里的struct time相当于int,char等,是定义类型,而t是定义类型后面的变量
这里的Alan,Tom相当于变量
(3)使用结构体作为成员 (4)匿名结构体
struct DATE{ struct{
int.......... int............
int.......... char...........
} }Alan,Tom;
struct person{
char........
struct DATE birthday;
};
struct time t;
*struct DATE是定义结构体变量,可以嵌套进结构体
2.结构体的调用:
(1)student.name的.是成员运算符,用来获取结构体中的成员
(2)如果结构体的成员本身是一个结构体,则需要继续用.运算符,直到最低一级的成员
3.结构体的初始化:
(1)struct student Alan = {xxx,xxx,xxxxxx,xx};
(2)注意结构体数组要在定义时就直接初始化,如果先定义再赋初值是错误的
(3)进行数组初始化的时候如果定义的数组过长,而我们只初始化了一部分数据,对于未初始化的数据如果是数值型,则会自动赋值为0,对于字符型,会自动赋初值为NULL,即‘\0’ 即不足的元素补以默认值
struct student { char* Name; int number; char csex; }stu, * stu; stu = (struct student*)malloc(sizeof(struct student));. / * 结构体指针初始化*/ stu->name = (char * )malloc(sizeof(char)); / * 结构体指针的成员指针同样需要初始化*/
4.结构体数组:
struct student{
int.........
char.........
int.........
};
main()
{
struct student class_02[5] = {
{01,"Alan",18};
{02,"Tom",17};
};
}
导出各个学生资料时,用for循环,把结构体名换成class_02[i];
5.结构体指针:
使用分量运算符 -> 来获取成员 , 而不是 .
struct DATE{
int...........
char........
}date = {2012, 11, 27 }, *d ;
main()
{
d=&date;
printf("%d",d->year)
}
(++p) .xxxx指向结构体数组下一个元素的地址
swap函数里,如果不用指针,则只能改变局部变量而不能改变全局变量,因此需要运用指针。
6.清空结构体:
struct Student { char cName[20]; int number; char csex;
}stu1;
memset(&str,0,sizeof(struct Student)); 如果是数组: struct Student stu[10]; 就是 memset(stu,0,sizeof(struct Student)*10);
7.结构体与函数:
定义: struct time add(struct time now,struct time pass)
{
struct time rel;
rel.hour = .................
return rel;
}
int main()
{
struct time result;
result = add(now,pass);
}
十二、编译预处理
1.宏定义:
(1)宏定义是C语言提供的三种预处理功能的其中一种,这三种预处理包括:宏定义、文件包含、条件编译
(2)宏定义和操作符的区别:宏定义是替换,不做计算,也不做表达式求解。宏定义又称为宏代换、宏替换,简称“宏”。在 C 语言中,宏是产生内嵌代码的唯一方法。对于嵌入式系统而言,为了能达到性能要求,宏是一种很好的代替函数的方法
(3)格式:#define 标识符 字符串
(4)好处:防止重复定义
2.定义宏注意事项:
(1)宏名一般用大写;
(2)使用宏可提高程序的通用性和易读性,减少不一致性,减少输入错误和便于修改。例如:数组大小常用宏定义;
(3)预处理是在编译之前的处理,而编译工作的任务之一就是语法检查,预处理不做语法检查;
(4)宏定义末尾不加分号;
(5)宏定义写在函数的花括号外边,作用域为其后的程序,通常在文件的最开头;
(6)可以用#undef命令终止宏定义的作用域;
(7)宏定义允许嵌套;
(8)字符串( " " )中永远不包含宏;
(9)宏定义不分配内存,变量定义分配内存;
(10)宏定义不存在类型问题,它的参数也是无类型的。
3.库文件:
(1)C语言中提供了丰富的系统文件,也可称为库文件。
(2)C 语言的库文件分为两类:
第一类是扩展名为".h" 的头文件,包含常量定义、 类型定义、宏定义、函数原型以及各种编译选择设置等信息
第二类是函数库,包括了各种函数的目标代码,供用户在程序中调用。 通常在程序中调用一个库函数时,要在调用之前包含该函数原型所在的".h" 文件 (3)常用的库文件:
| alloc.h | 说明内存管理函数(分配、释放等)。 |
|---|---|
| assert.h | 定义 assert调试宏。 |
| bios.h | 说明调用IBM—PC ROM BIOS子程序的各个函数。 |
| conio.h | 说明调用DOS控制台I/O子程序的各个函数。 |
| ctype.h | 包含有关字符分类及转换的名类信息(如 isalpha和toascii等)。 |
| dir.h | 包含有关目录和路径的结构、宏定义和函数。 |
| dos.h | 定义和说明MSDOS和8086调用的一些常量和函数。 |
| error.h | 定义错误代码的助记符。 |
| fcntl.h | 定义在与open库子程序连接时的符号常量。 |
| float.h | 包含有关浮点运算的一些参数和函数。 |
| graphics.h | 说明有关图形功能的各个函数,图形错误代码的常量定义,正对不同驱动程序的各种颜色值,及函数用到的一些特殊结构。 |
| io.h | 包含低级I/O子程序的结构和说明。 |
| limit.h | 包含各环境参数、编译时间限制、数的范围等信息。 |
| math.h | 说明数学运算函数,还定了 HUGE VAL 宏, 说明了matherr和matherr子程序用到的特殊结构。 |
| mem.h | 说明一些内存操作函数(其中大多数也在STRING.H中说明)。 |
| process.h | 说明进程管理的各个函数,spawn…和EXEC …函数的结构说明。 |
| setjmp.h | 定义longjmp和setjmp函数用到的jmp buf类型,说明这两个函数。 |
| share.h | 定义文件共享函数的参数。 |
| signal.h | 定义SIG[ZZ(Z] [ZZ)]IGN和SIG[ZZ(Z] [ZZ)]DFL常量,说明rajse和signal两个函数。 |
| stddef.h | 定义读函数参数表的宏。(如vprintf,vscarf函数)。 |
| stddef.h | 定义一些公共数据类型和宏。 |
| stdio.h | 定义Kernighan和Ritchie在Unix System V 中定义的标准和扩展的类型和宏。还定义标准I/O 预定义流:stdin,stdout和stderr,说明 I/O流子程序。 |
| stdlib.h | 说明一些常用的子程序:转换子程序、搜索/ 排序子程序等。 |
| string.h | 说明一些串操作和内存操作函数。 |
| sys\stat.h | 定义在打开和创建文件时用到的一些符号常量。 |
| sys\types.h | 说明ftime函数和timeb结构。 |
| sys\time.h | 定义时间的类型time[ZZ(Z] [ZZ)]t。 |
| time.h | 定义时间转换子程序asctime、localtime和gmtime的结构,ctime、 difftime、 gmtime、 localtime和stime用到的类型,并提供这些函数的原型。 |
| value.h | 定义一些重要常量,包括依赖于机器硬件的和为与Unix System V相兼容而说明的一些常量,包括浮点和双精度值的范围。 |
十三、位运算
1.位:
bit,一般用b表示
2.字节:
Byte,一般用B表示,1B=8b
十四、文件
1.文件分类:
(1)文本文件:文件内容以ASCII码格式存放,一个字节存放一个ASCII码,代表一个字符 ,但占用存储空间较多.c 文件就是以文本文件形式存放的
(2)二进制文件:文件内容以补码格式存放,占用存储空间少。
数据按其内存中的存储形式原样存放.exe 文件就是以二进制文件形式存放
2.文件的操作:
(1)定义文件类型指针:
FILE *指针变量(fp)
凡是要对文件进行操作,就需要在程序中定义文件指针
(2)FILE类型:
包含在stdio.h 的头文件中,是结构体类型
(3)打开文件:
fopen( 文件路径, 模式 )
常用模式:
"r"(只读) 为了输入数据,打开一个已经存在的文本文件 出错
"w"(只写) 为了输出数据,打开一个文本文件 建立一个新的文件 "a"(追加) 向文本文件添加数据 建立一个新的文件 "r+"(读写) 为了读和写,打开一个文本文件 出错 "w+"(读写) 为了读和写,建立一个新的文本文件 建立一个新的文件 "a+"(读写) 打开一个文本文件,在文件尾进行读写 建立一个文件
(4)关闭文件:
fclose( fp );
(5)读写文件:
fgets( )
读取相应的文件,一次读一行。如果遇到换行符或EOF,输入即结束
例:
int main()
{
FILE *fp;
char buf[20];
fp = fopen("D:\1.txt","r"); //r意为只读模式,fopen传回的是指针,是地址
if(fp == NULL)
{ printf("打开文件失败");
}
fgets(buf,20,fp); //只能读一行,要读多行则
printf("%s",buf);
/*
fgets(buf,20,fp);
printf("%s",buf);
fgets(buf,20,fp);
printf("%s",buf);
*/
fclose(fp);
}
fgets循环读遍文件:
while( fgets ( buf ,20, fp)) //读到空就停止循环
{
printf("%s" , buf);
}
fputs( )
写入相应的文件,一次写一行
例:
FTLE *fp;
char buf[20] = "hello world";
fp = fopen("E:\1.txt", "w");
fputs( buf , fp)
fseek( ) 、 ftell( )
设置文件位置、获取当前位置
fseek(文件结构体,偏移量,偏移相对位置);
常见位置有:SEEK_SET文件开头,SEEK_CUR当前位置,SEEK_END文件结尾
ftell(文件结构体);
fputc( )
用法:fputc(ch,fp); ch:输出的字符 功能:写一个字符到fp对应文件的当前位置上。如果调用函数成功,则返回ch的值;如果失败,则返回值EOF(系统定义的宏,值为-1)
fgetc( )
用法:ch=fgetc(fp); 功能:从fp对应的当前位置读一个字符。如果调用成功,则返回读到的字符(赋值给ch);如果读到文件结束,则返回EOF(-1)
feof( )
用法:feof(fp); 功能:判断文件是否处于文件结束位置。如果文件结束,则返回1,否则返回0
fscanf( )
用法:fscanf(fp,format,&arg1,&arg2,…,&argn); format:格式说明字符串;&arg1…&argn:输入变量的地址列表。 功能:从fp指向的文件的当前位置,顺序读取ASCII码值,按照fomat规定的格式转化为各个变量对应的值,送入指定变量
fprintf( )
用法:fprintf(fp,format,arg1,arg2,…,argn); format:格式说明字符串;arg1…argn:输出参数个数表 功能:按指定的格式(format)将输出列表arg1…argn的值转换成对应的ASCII码表示形式,写入fp文件的当前位置
例如:fprintf(fp,"%d,%x,%u",123,145,12);
*fprintf和printf的区别
fprintf的函数原型为:int fprintf( FILE *stream, const char *format, [ argument ]...);
printf的函数原型为:int printf( const char *format [, argument]... );
所以fprintf是将字符输出到流(文件)的,printf是输出到标准输出设备(stdout)的,一般就是我们的屏幕
fread( )
用法:表示从文件中读入数据到内存缓冲区。
形式为:fread(buf,size,count,fp); buf:类型为void指针,表示内存中存放着数据到首地址,通常是数组名或数组指针。 size:无符号整型,表示一次读取的字节数。 count:无符号整型,表示读取的大小为size的块的次数。 功能:从fp指向的文件的当前位置读区size个字节,共count次,读取的总字节数为size*count,存放到首地址为buf的内存中。读取成功则返回读取的项数count
fwrite( )
用法:表示从内存输出数据块到文件中。
其一般形式为:fwrite(buf,size,count,fp); buf:类型为void指针,表示内存中存放着数据到首地址,通常是数组名或数组指针。 size:无符号整型,表示一次写入的字节数。 count:无符号整型,表示写入的大小为size的块的次数。 功能:从fp指向的地址开始,分count次,每次size个字节,向fp指向的文件的当前位置写数据,共写入count*size个字节。写入成功则返回读取的项数count
rewind( )
用来置文件读/写位置于开头处。一般形式为:rewind(fp); 功能:将文件的当前位置移动到文件的开始处