中文手写数字数据识别
实验环境
python=3.7
torch==1.13.1+cu117
torchaudio==0.13.1+cu117
torchvision==0.14.1
数据下载地址:Mnist中文手写数字数据集Python资源-CSDN文库
这些汉字包括:
零、一、二、三、四、五、六、七、八、九、十、百、千、万、亿
总共15个汉字,分别用0、1、2、3、4、5、6、7、8、9、10、100、1000、10000、100000000标记
使用方法
import pickle, numpy
with open("./chn_mnist", "rb") as f:
data = pickle.load(f)
images = data["images"]
targets = data["targets"]
数据预处理
数据加载
将数据存入俩个变量,格式为numpy.ndarray
#修改自己的数据集路径
with open(r"D:\zr\data\chn_mnist\chn_mnist", "rb") as f:
dataset = pickle.load(f)
images = dataset["images"]
targets = dataset["targets"]
统一标签值
100、1000、10000、100000000这四个标签分别用11、12、13、14表示
index = np.where(targets == 100)
targets[index] = 11
index = np.where(targets == 1000)
targets[index] = 12
index = np.where(targets == 10000)
targets[index] = 13
index = np.where(targets == 100000000)
targets[index] = 14
构建数据集
构建Dataset
使用torch.utils.data.DataLoader根据数据集生成一个可迭代的对象,用于模型训练前,需要构建自己的Dataset类
在定义自己的数据集时,需要继承Dataset类,并实现三个函数:init、len__和__getitem
init:实例化Dataset对象时运行,完成初始化工作
len:返回数据集的大小
getitem:根据索引返回一个样本(数据和标签)
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
class MyDataset(Dataset):
def __init__(self, data, targets, transform=None, target_transform=None):
'''
data 数据形状为(x,64,64) x张64*64图像数组
targets 数据形状为(x) x个图像类别取值
'''
self.transform = transform
self.target_transform = target_transform
self.data = []
self.targets = []
#转换数据格式
targets = targets.astype(np.uint8)
#标签集不做任何处理的情况下
if target_transform is None:
self.targets = targets
#我这里transform处理numpy数组图像会报错,需要将图像转为Image格式
#遍历依次对每个图像转换
for index in range(0, data.shape[0]):
if self.transform:
image = Image.fromarray(data[index])
self.data.append(self.transform(image))
if self.target_transform:
self.targets.append(self.target_transform(targets))
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index], self.targets[index]
定义转换方法,对于图像数组,将每个像素点取值规范至0-1之间,均值为0.5
transform_data = transforms.Compose([
#确保所有图像都为(64,64),此处图像为标准数据,可以不用
torchvision.transforms.Resize((64, 64)),
#将PIL Image格式的数据转换为tensor格式,像素值大小缩放至区间[0., 1.]
transforms.ToTensor(),
#对输入进行标准化,传入均值(mean[1],…,mean[n])和标准差(std[1],…,std[n]),n与输入的维度相同
#对于三通道图像(mean=[0.5,0.5,0.5], std=[0.5,0.5,0.5])
transforms.Normalize(mean=[0.5], std=[0.5])])
transform_target = None
实例化Dataset类,此处将前14000张作为训练集,后1000张作为测试集
train_dataset = dataloader.MyDataset(images[:14000, :, :], targets[:14000], transform_data, transform_target)
test_dataset = dataloader.MyDataset(images[-1000:, :, :], targets[-1000:], transform_data, transform_target)
DataLoader加载数据集
DataLoader参数解释,通常填前三个参数即可
常用参数:
- dataset (Dataset) :定义好的数据集
- batch_size (int, optional):每次放入网络训练的批次大小,默认为1.
- shuffle (bool, optional) :是否打乱数据的顺序,默认为False。一般训练集设置为True,测试集设置为False
- num_workers (int, optional) :线程数,默认为0。在Windows下设置大于0的数可能会报错
- drop_last (bool, optional) :是否丢弃最后一个批次的数据,默认为False
两个工具包,可配合DataLoader使用:
- enumerate(iterable, start=0):输入是一个可迭代的对象和下标索引开始值;返回可迭代对象的下标索引和数据本身
- tqdm(iterable):进度条可视化工具包
定义超参数
# 定义超参数
#每次进入模型的图像数量
batch_size = 32
#学习率
learning_rate = 0.001
#总的迭代次数
num_epochs = 50
加载
#shuffle=True表示打乱数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
模型构建
CNN
自定义卷积模块,对于不同数据集,修改输入图像通道数和输出的分类数量即可
import torch
import torch.nn as nn
class SelfCnn(nn.Module):
def __init__(self):
super(SelfCnn, self).__init__()
self.features = nn.Sequential(
# Block 1
nn.Conv2d(1, 32, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # (32,32,64)
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # (16,16,64)
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # (8,8,64)
)
self.classifier = nn.Sequential(
nn.Linear(8 * 8 * 64, 256),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(256, 256),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(256, 15) # 输出层,二分类任务
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1) # 展开特征图
x = self.classifier(x)
return x
加载模型
model=SelfCnn()
VGG16
VGG16由于模型参数量太大,自己从0训练不大能行,需要加载pytorch的预训练模型
#pretrained = True代表加载预训练数据
vgg16_ture = torchvision.models.vgg16(pretrained = True)
VGG16默认的输入图像数据为(224,224,3),输出为(1,1,1000) 我们的数据输入为(64,64,1),目标输出为(1,1,15),因此需要对模型进行修改结构
#增加一层线性变化,将1000类变为15类
vgg16_ture.classifier.append(nn.Linear(1000,15))
#全连接层修改,原来为(7*7*512),将(224/32=)7换为(64/32=)2即可
vgg16_ture.classifier[0]=nn.Linear(2*2*512,4096)
#输入的三通道改为单通道1
vgg16_ture.features[0]=nn.Conv2d(1, 64, kernel_size=3, padding=1)
vgg16_ture.avgpool=nn.AdaptiveAvgPool2d((2,2))
model=vgg16_ture
ResNet50
ResNet50同样需要加载预训练模型
#pretrained = True代表加载预训练数据
resnet50 = torchvision.models.resnet50(pretrained=True)
ResNet50默认输入为三通道图像,将其修改为单通道,以及全连接层输出分类修改
#输入的三通道改为单通道1
resnet50.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3)
#将输出分类改为15
resnet50.fc = (nn.Linear(2048, 15))
model=resnet50
模型训练
选择模型以及训练环境
#有gpu则使用gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#选择使用的模型,model=vgg16_ture,model=SelfCnn()
#加载已经训练过的模型: model=torch.load(r'D:\zr\projects\utils\chn_mnist_resnet50.pth')
model=resnet50
#将模型置于device
model.to(device)
定义损失函数和优化器
#多分类任务使用这个损失
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), momentum=0.9, lr=learning_rate)
定义绘图方法,本例绘制俩附图像
def plt_img(plt_data):
# 创建数据点
plt.clf()
x = plt_data.get('Epoch')
train_acc = plt_data.get('train_acc')
train_loss = plt_data.get('train_loss')
test_acc = plt_data.get('test_acc')
test_loss = plt_data.get('test_loss')
# 绘制曲线
plt.plot(x, train_acc, label='train_acc')
plt.plot(x, test_acc, label='test_acc')
plt.plot(x, train_loss, label='train_loss')
plt.plot(x, test_loss, label='test_loss')
plt.legend(title='Accuracy And Loss') # 添加图例标题
plt.xlabel('epoch')
# plt.ylabel('rate')
plt.savefig(f'resnet50_{num_epochs}_{batch_size}_{learning_rate}_1.png')
# 显示图形
def plt_acc_loss(plt_data):
plt.clf()
_, axes = plt.subplots(2, 1)
x = plt_data.get('Epoch')
train_acc = plt_data.get('train_acc')
train_loss = plt_data.get('train_loss')
test_acc = plt_data.get('test_acc')
test_loss = plt_data.get('test_loss')
axes[0].plot(x, train_acc, label='train_acc')
axes[0].plot(x, test_acc, label='test_acc')
axes[0].legend(title='Accuracy') # 添加图例标题
axes[0].set_xlabel('epoch')
# axes[0].set_ylabel('rate')
axes[1].plot(x, train_loss, label='train_loss')
axes[1].plot(x, test_loss, label='test_loss')
axes[1].legend(title='Loss')
axes[1].set_xlabel('epoch')
# axes[1].set_ylabel('rate')
# 防止标签被遮挡
plt.tight_layout()
plt.savefig(f'resnet50_{num_epochs}_{batch_size}_{learning_rate}_2.png')
开始训练,每次epoch结束都会对模型进行评估,保存准确率最高的模型,同时记录每次的准确率以及loss
max_acc = 0.0
plt_data = {
'Epoch': [],
'train_acc': [],
'train_loss': [],
'test_acc': [],
'test_loss': [],
}
for epoch in range(num_epochs):
plt_data.get('Epoch').append(epoch + 1)
model.eval()
torch.no_grad()
correct = 0.0
total = 0.0
loss_ = 0.0
#测试模型
loop = tqdm(enumerate(test_loader), total=len(test_loader))
for i, (images, labels) in loop:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
loss_ += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = correct / total
loop.set_description(f'Epoch Test [{epoch + 1}/{num_epochs}]')
loop.set_postfix(loss=loss_/(i+1), acc=acc)
if epoch == 0:
print('原有模型在测试集表现如下:')
acc = correct / total
loss_ = loss_ / len(test_loader)
plt_data.get('test_acc').append(acc)
plt_data.get('test_loss').append(loss_)
print(f"Accuracy on test images: {acc * 100}% , Loss {loss_}")
if acc > max_acc:
max_acc = acc
torch.save(model, 'chn_mnist_resnet50.pth')
print('The model has been saved as chn_mnist_resnet50.pth')
correct = 0.0
total = 0.0
loss_ = 0.0
time.sleep(0.1)
#训练
loop = tqdm(enumerate(train_loader), total=len(train_loader))
for i, (images, labels) in loop:
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
loss_ += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = correct / total
# 反向传播和优化,测试集时不要要
optimizer.zero_grad()
loss.backward()
optimizer.step()
loop.set_description(f'Epoch Train [{epoch + 1}/{num_epochs}]')
loop.set_postfix(loss=loss_/(i+1), acc=acc)
acc = correct / total
loss_ = loss_ / len(train_loader)
plt_data.get('train_acc').append(acc)
plt_data.get('train_loss').append(loss_)
print(f"Accuracy on train images: {acc * 100}% , Loss {loss_}")
time.sleep(0.1)
#绘图
plt_img(plt_data)
plt_acc_loss(plt_data)
结果分析
以下结果均在总训练次数(Epoch)=100,学习率(learn_rate_=0.001,批样本数量(Batch Size)=32的情况下
CNN
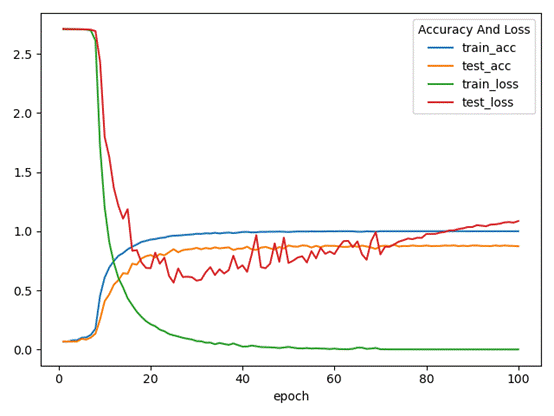
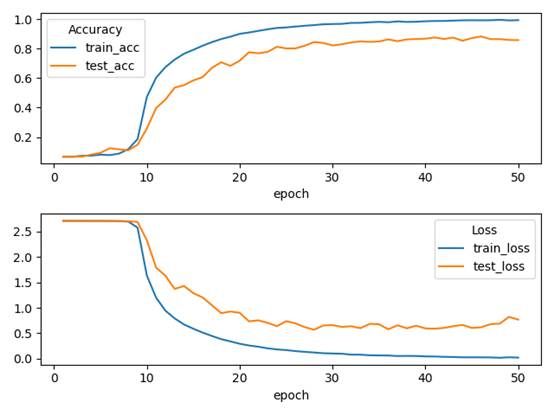
测试表现

训练集准确率为:99.99%,测试集准确率为 88.5%,模型存在过拟合
VGG16
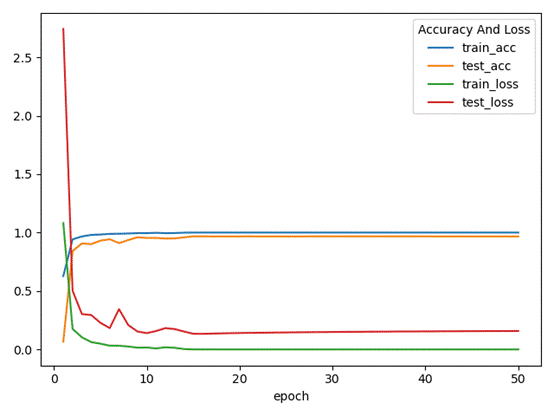
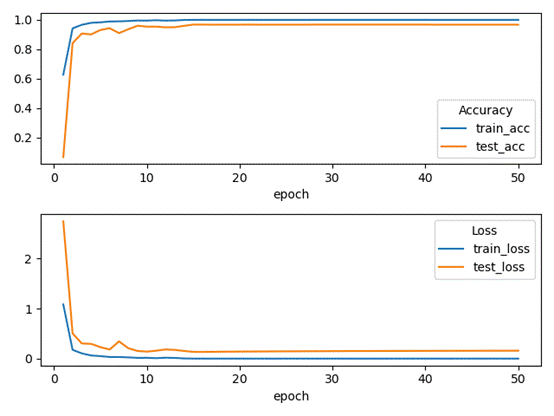
可见模型正在Epoch =10左右的时候就基本收敛完成
测试表现

训练集准确率为:99.92%,测试集准确率为 99.5%,模型良好且泛化能力强
ResNet50
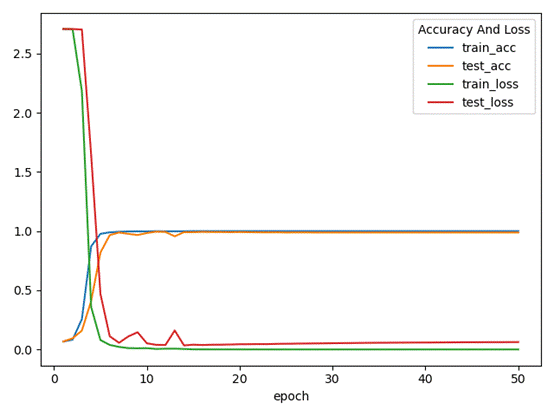
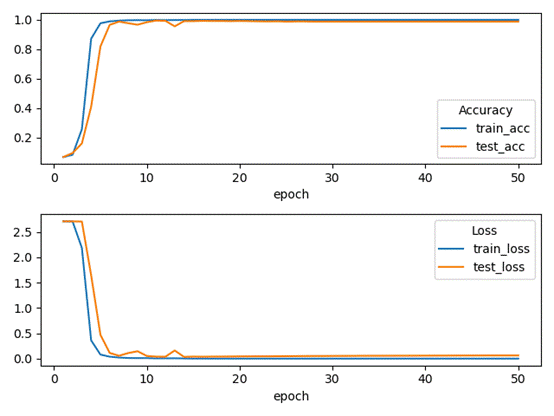
可见模型正在Epoch =10之前的时候就基本收敛完成,相较于VGG,resnet50的收敛速度更快
测试表现

训练集准确率为:100%,测试集准确率为 96.8%,模型良好但存在过拟合
源代码
dataloader.py
import numpy as np
from torch.utils.data import Dataset
from PIL import Image
class MyDataset(Dataset):
def __init__(self, data, targets, transform=None, target_transform=None):
self.transform = transform
self.target_transform = target_transform
self.data = []
self.targets = []
targets = targets.astype(np.uint8)
if target_transform is None:
self.targets = targets
for index in range(0, data.shape[0]):
if self.transform:
image = Image.fromarray(data[index])
self.data.append(self.transform(image))
if self.target_transform:
self.targets.append(self.target_transform(targets))
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index], self.targets[index]
selfnet_cnn.py
import torch
import torch.nn as nn
class SelfCnn(nn.Module):
def __init__(self):
super(SelfCnn, self).__init__()
self.features = nn.Sequential(
# Block 1
nn.Conv2d(1, 32, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # (32,32,64)
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # (16,16,64)
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # (8,8,64)
)
self.classifier = nn.Sequential(
nn.Linear(8 * 8 * 64, 256),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(256, 256),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(256, 15) # 输出层,二分类任务
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1) # 展开特征图
x = self.classifier(x)
return x
train_self_cnn.py
import pickle
import time
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from torch import nn
from torch.utils.data import DataLoader
import dataloader
import torch
import torchvision
import torchvision.transforms as transforms
from tqdm import tqdm
import os
from selfnet_cnn import SelfCnn
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 定义数据转换
transform_data = transforms.Compose([
torchvision.transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
transform_target = None
with open(r"D:\zr\data\chn_mnist\chn_mnist", "rb") as f:
dataset = pickle.load(f)
images = dataset["images"]
targets = dataset["targets"]
index = np.where(targets == 100)
targets[index] = 11
index = np.where(targets == 1000)
targets[index] = 12
index = np.where(targets == 10000)
targets[index] = 13
index = np.where(targets == 100000000)
targets[index] = 14
train_dataset = dataloader.MyDataset(images[:14000, :, :], targets[:14000], transform_data, transform_target)
test_dataset = dataloader.MyDataset(images[-1000:, :, :], targets[-1000:], transform_data, transform_target)
# 定义超参数
batch_size = 32
learning_rate = 0.001
num_epochs = 100
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model=SelfCnn()
# model = torch.load(r'D:\zr\projects\utils\chn_mnist_resnet50.pth', map_location=device)
model.to(device)
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), momentum=0.9, lr=learning_rate)
def plt_img(plt_data):
# 创建数据点
plt.clf()
x = plt_data.get('Epoch')
train_acc = plt_data.get('train_acc')
train_loss = plt_data.get('train_loss')
test_acc = plt_data.get('test_acc')
test_loss = plt_data.get('test_loss')
# 绘制曲线
plt.plot(x, train_acc, label='train_acc')
plt.plot(x, test_acc, label='test_acc')
plt.plot(x, train_loss, label='train_loss')
plt.plot(x, test_loss, label='test_loss')
plt.legend(title='Accuracy And Loss') # 添加图例标题
plt.xlabel('epoch')
# plt.ylabel('rate')
plt.savefig(f'selfCnn_{num_epochs}_{batch_size}_{learning_rate}_1.png')
# 显示图形
def plt_acc_loss(plt_data):
plt.clf()
_, axes = plt.subplots(2, 1)
x = plt_data.get('Epoch')
train_acc = plt_data.get('train_acc')
train_loss = plt_data.get('train_loss')
test_acc = plt_data.get('test_acc')
test_loss = plt_data.get('test_loss')
axes[0].plot(x, train_acc, label='train_acc')
axes[0].plot(x, test_acc, label='test_acc')
axes[0].legend(title='Accuracy') # 添加图例标题
axes[0].set_xlabel('epoch')
# axes[0].set_ylabel('rate')
axes[1].plot(x, train_loss, label='train_loss')
axes[1].plot(x, test_loss, label='test_loss')
axes[1].legend(title='Loss')
axes[1].set_xlabel('epoch')
# axes[1].set_ylabel('rate')
# 防止标签被遮挡
plt.tight_layout()
plt.savefig(f'selfCnn_{num_epochs}_{batch_size}_{learning_rate}_2.png')
# 训练模型
max_acc = 0.0
plt_data = {
'Epoch': [],
'train_acc': [],
'train_loss': [],
'test_acc': [],
'test_loss': [],
}
for epoch in range(num_epochs):
plt_data.get('Epoch').append(epoch + 1)
model.eval()
torch.no_grad()
correct = 0.0
total = 0.0
loss_ = 0.0
loop = tqdm(enumerate(test_loader), total=len(test_loader))
for i, (images, labels) in loop:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
loss_ += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = correct / total
loop.set_description(f'Epoch Test [{epoch + 1}/{num_epochs}]')
loop.set_postfix(loss=loss_/(i+1), acc=acc)
if epoch == 0:
print('原有模型在测试集表现如下:')
acc = correct / total
loss_ = loss_ / len(test_loader)
plt_data.get('test_acc').append(acc)
plt_data.get('test_loss').append(loss_)
print(f"Accuracy on test images: {acc * 100}% , Loss: {loss_}")
if acc > max_acc:
max_acc = acc
torch.save(model, 'chn_mnist_selfCnn.pth')
print('The model has been saved as chn_mnist_selfCnn.pth')
correct = 0.0
total = 0.0
loss_ = 0.0
time.sleep(0.1)
loop = tqdm(enumerate(train_loader), total=len(train_loader))
for i, (images, labels) in loop:
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
loss_ += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = correct / total
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
loop.set_description(f'Epoch Train [{epoch + 1}/{num_epochs}]')
loop.set_postfix(loss=loss_/(i+1), acc=acc)
acc = correct / total
loss_ = loss_ / len(train_loader)
plt_data.get('train_acc').append(acc)
plt_data.get('train_loss').append(loss_)
print(f"Accuracy on train images: {acc * 100}% , Loss: {loss_}")
time.sleep(0.1)
plt_img(plt_data)
plt_acc_loss(plt_data)
train_vgg16.py
import pickle
import time
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from torch import nn
from torch.utils.data import DataLoader
import dataloader
import torch
import torchvision
import torchvision.transforms as transforms
from tqdm import tqdm
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 定义数据转换
transform_data = transforms.Compose([
torchvision.transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
transform_target = None
with open(r"D:\zr\data\chn_mnist\chn_mnist", "rb") as f:
dataset = pickle.load(f)
images = dataset["images"]
targets = dataset["targets"]
index = np.where(targets == 100)
targets[index] = 11
index = np.where(targets == 1000)
targets[index] = 12
index = np.where(targets == 10000)
targets[index] = 13
index = np.where(targets == 100000000)
targets[index] = 14
train_dataset = dataloader.MyDataset(images[:14000, :, :], targets[:14000], transform_data, transform_target)
test_dataset = dataloader.MyDataset(images[-1000:, :, :], targets[-1000:], transform_data, transform_target)
# 定义超参数
batch_size = 32
learning_rate = 0.001
num_epochs = 50
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
vgg16_ture = torchvision.models.vgg16(pretrained = True)
vgg16_ture.classifier.append(nn.Linear(1000,15))
vgg16_ture.classifier[0]=nn.Linear(2*2*512,4096)
vgg16_ture.features[0]=nn.Conv2d(1, 64, kernel_size=3, padding=1)
vgg16_ture.avgpool=nn.AdaptiveAvgPool2d((2,2))
model=vgg16_ture
# model = torch.load(r'D:\zr\projects\utils\chn_mnist_resnet50.pth', map_location=device)
model.to(device)
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), momentum=0.9, lr=learning_rate)
def plt_img(plt_data):
# 创建数据点
plt.clf()
x = plt_data.get('Epoch')
train_acc = plt_data.get('train_acc')
train_loss = plt_data.get('train_loss')
test_acc = plt_data.get('test_acc')
test_loss = plt_data.get('test_loss')
# 绘制曲线
plt.plot(x, train_acc, label='train_acc')
plt.plot(x, test_acc, label='test_acc')
plt.plot(x, train_loss, label='train_loss')
plt.plot(x, test_loss, label='test_loss')
plt.legend(title='Accuracy And Loss') # 添加图例标题
plt.xlabel('epoch')
# plt.ylabel('rate')
plt.savefig(f'vgg16_{num_epochs}_{batch_size}_{learning_rate}_1.png')
# 显示图形
def plt_acc_loss(plt_data):
plt.clf()
_, axes = plt.subplots(2, 1)
x = plt_data.get('Epoch')
train_acc = plt_data.get('train_acc')
train_loss = plt_data.get('train_loss')
test_acc = plt_data.get('test_acc')
test_loss = plt_data.get('test_loss')
axes[0].plot(x, train_acc, label='train_acc')
axes[0].plot(x, test_acc, label='test_acc')
axes[0].legend(title='Accuracy') # 添加图例标题
axes[0].set_xlabel('epoch')
# axes[0].set_ylabel('rate')
axes[1].plot(x, train_loss, label='train_loss')
axes[1].plot(x, test_loss, label='test_loss')
axes[1].legend(title='Loss')
axes[1].set_xlabel('epoch')
# axes[1].set_ylabel('rate')
# 防止标签被遮挡
plt.tight_layout()
plt.savefig(f'vgg16_{num_epochs}_{batch_size}_{learning_rate}_2.png')
# 训练模型
max_acc = 0.0
plt_data = {
'Epoch': [],
'train_acc': [],
'train_loss': [],
'test_acc': [],
'test_loss': [],
}
for epoch in range(num_epochs):
plt_data.get('Epoch').append(epoch + 1)
model.eval()
torch.no_grad()
correct = 0.0
total = 0.0
loss_ = 0.0
loop = tqdm(enumerate(test_loader), total=len(test_loader))
for i, (images, labels) in loop:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
loss_ += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = correct / total
loop.set_description(f'Epoch Test [{epoch + 1}/{num_epochs}]')
loop.set_postfix(loss=loss_/(i+1), acc=acc)
if epoch == 0:
print('原有模型在测试集表现如下:')
acc = correct / total
loss_ = loss_ / len(test_loader)
plt_data.get('test_acc').append(acc)
plt_data.get('test_loss').append(loss_)
print(f"Accuracy on test images: {acc * 100}% , Loss: {loss_}")
if acc > max_acc:
max_acc = acc
torch.save(model, 'chn_mnist_vgg16.pth')
print('The model has been saved as chn_mnist_vgg16.pth')
correct = 0.0
total = 0.0
loss_ = 0.0
time.sleep(0.1)
loop = tqdm(enumerate(train_loader), total=len(train_loader))
for i, (images, labels) in loop:
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
loss_ += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = correct / total
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
loop.set_description(f'Epoch Train [{epoch + 1}/{num_epochs}]')
loop.set_postfix(loss=loss_/(i+1), acc=acc)
acc = correct / total
loss_ = loss_ / len(train_loader)
plt_data.get('train_acc').append(acc)
plt_data.get('train_loss').append(loss_)
print(f"Accuracy on train images: {acc * 100}% , Loss: {loss_}")
time.sleep(0.1)
plt_img(plt_data)
plt_acc_loss(plt_data)
train_resnet50.py
import pickle
import time
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from torch import nn
from torch.utils.data import DataLoader
import dataloader
import torch
import torchvision
import torchvision.transforms as transforms
from tqdm import tqdm
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 定义数据转换
transform_data = transforms.Compose([
torchvision.transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
transform_target = None
with open(r"D:\zr\data\chn_mnist\chn_mnist", "rb") as f:
dataset = pickle.load(f)
images = dataset["images"]
targets = dataset["targets"]
index = np.where(targets == 100)
targets[index] = 11
index = np.where(targets == 1000)
targets[index] = 12
index = np.where(targets == 10000)
targets[index] = 13
index = np.where(targets == 100000000)
targets[index] = 14
train_dataset = dataloader.MyDataset(images[:14000, :, :], targets[:14000], transform_data, transform_target)
test_dataset = dataloader.MyDataset(images[-1000:, :, :], targets[-1000:], transform_data, transform_target)
# 定义超参数
batch_size = 32
learning_rate = 0.001
num_epochs = 50
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
resnet50 = torchvision.models.resnet50(pretrained=True)
# print(resnet50)
resnet50.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3)
resnet50.fc = (nn.Linear(2048, 15))
# resnet50.add_module('add',nn.Linear(1000,15))
model=resnet50
# model = torch.load(r'D:\zr\projects\utils\chn_mnist_resnet50.pth', map_location=device)
model.to(device)
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), momentum=0.9, lr=learning_rate)
def plt_img(plt_data):
# 创建数据点
plt.clf()
x = plt_data.get('Epoch')
train_acc = plt_data.get('train_acc')
train_loss = plt_data.get('train_loss')
test_acc = plt_data.get('test_acc')
test_loss = plt_data.get('test_loss')
# 绘制曲线
plt.plot(x, train_acc, label='train_acc')
plt.plot(x, test_acc, label='test_acc')
plt.plot(x, train_loss, label='train_loss')
plt.plot(x, test_loss, label='test_loss')
plt.legend(title='Accuracy And Loss') # 添加图例标题
plt.xlabel('epoch')
# plt.ylabel('rate')
plt.savefig(f'resnet50_{num_epochs}_{batch_size}_{learning_rate}_1.png')
# 显示图形
def plt_acc_loss(plt_data):
plt.clf()
_, axes = plt.subplots(2, 1)
x = plt_data.get('Epoch')
train_acc = plt_data.get('train_acc')
train_loss = plt_data.get('train_loss')
test_acc = plt_data.get('test_acc')
test_loss = plt_data.get('test_loss')
axes[0].plot(x, train_acc, label='train_acc')
axes[0].plot(x, test_acc, label='test_acc')
axes[0].legend(title='Accuracy') # 添加图例标题
axes[0].set_xlabel('epoch')
# axes[0].set_ylabel('rate')
axes[1].plot(x, train_loss, label='train_loss')
axes[1].plot(x, test_loss, label='test_loss')
axes[1].legend(title='Loss')
axes[1].set_xlabel('epoch')
# axes[1].set_ylabel('rate')
# 防止标签被遮挡
plt.tight_layout()
plt.savefig(f'resnet50_{num_epochs}_{batch_size}_{learning_rate}_2.png')
# 训练模型
max_acc = 0.0
plt_data = {
'Epoch': [],
'train_acc': [],
'train_loss': [],
'test_acc': [],
'test_loss': [],
}
for epoch in range(num_epochs):
plt_data.get('Epoch').append(epoch + 1)
model.eval()
torch.no_grad()
correct = 0.0
total = 0.0
loss_ = 0.0
loop = tqdm(enumerate(test_loader), total=len(test_loader))
for i, (images, labels) in loop:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
loss_ += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = correct / total
loop.set_description(f'Epoch Test [{epoch + 1}/{num_epochs}]')
loop.set_postfix(loss=loss_/(i+1), acc=acc)
if epoch == 0:
print('原有模型在测试集表现如下:')
acc = correct / total
loss_ = loss_ / len(test_loader)
plt_data.get('test_acc').append(acc)
plt_data.get('test_loss').append(loss_)
print(f"Accuracy on test images: {acc * 100}% , Loss: {loss_}")
if acc > max_acc:
max_acc = acc
torch.save(model, 'chn_mnist_resnet50.pth')
print('The model has been saved as chn_mnist_resnet50.pth')
correct = 0.0
total = 0.0
loss_ = 0.0
time.sleep(0.1)
loop = tqdm(enumerate(train_loader), total=len(train_loader))
for i, (images, labels) in loop:
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
loss_ += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
acc = correct / total
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
loop.set_description(f'Epoch Train [{epoch + 1}/{num_epochs}]')
loop.set_postfix(loss=loss_/(i+1), acc=acc)
acc = correct / total
loss_ = loss_ / len(train_loader)
plt_data.get('train_acc').append(acc)
plt_data.get('train_loss').append(loss_)
print(f"Accuracy on train images: {acc * 100}% , Loss: {loss_}")
time.sleep(0.1)
plt_img(plt_data)
plt_acc_loss(plt_data)