Flume采集数据到Hive&HBase
文章目录
Flume汇入数据到Hive
方法一:汇入到Hive指定的HDFS路径中:
方法二:利用HiveSink汇入数据
Flume 汇入数据到HBase
一、Flume 的HBaseSinks 详细介绍
1.1、HBaseSink
1.2、AsyncHBaseSink
Flume汇入数据到Hive
方法一:汇入到Hive指定的HDFS路径中:
- 在hive中创建数据库和外部表
create database flume;

create external table flume_into_hive(name string,age int) partitioned by (dt string) row format delimited fields terminated by ',' location '/user/hive/warehouse/flume.db/flume_into_hive';
![]()

2. 在/root中创建hive.log文件
mkdir flume-hive
cd flume-hive/
vi hive.log


3. 在flume的conf路径中编写配置文件
cd /opt/software/flume/conf/
vi flume-into-hive-1.conf
agent.sources=r1
agent.channels=c1
agent.sinks=s1
agent.sources.r1.type=exec
agent.sources.r1.command=tail -F /root/flume-hive/hive.log
agent.channels.c1.type=memory
agent.channels.capacity=1000
agent.channels.c1.transactionCapacity=100
agent.sinks.s1.type=hdfs
agent.sinks.s1.hdfs.path = hdfs://node01:9000/user/hive/warehouse/flume.db/flume_into_hive/dt=%Y%m%d
agent.sinks.s1.hdfs.filePrefix = upload-
agent.sinks.s1.hdfs.fileSuffix=.txt
#是否按照时间滚动文件夹
agent.sinks.s1.hdfs.round = true
#多少时间单位创建一个新的文件夹
agent.sinks.s1.hdfs.roundValue = 1
#重新定义时间单位
agent.sinks.s1.hdfs.roundUnit = hour
#是否使用本地时间戳
agent.sinks.s1.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
agent.sinks.s1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
agent.sinks.s1.hdfs.fileType = DataStream
agent.sinks.s1.hdfs.writeFormat=Text
#多久生成一个新的文件
agent.sinks.s1.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是 128M
agent.sinks.s1.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
agent.sinks.s1.hdfs.rollCount = 0
agent.sources.r1.channels=c1
agent.sinks.s1.channel=c1


4.运行flume
bin/flume-ng agent -c conf -f conf/flume-into-hive-1.conf -n agent
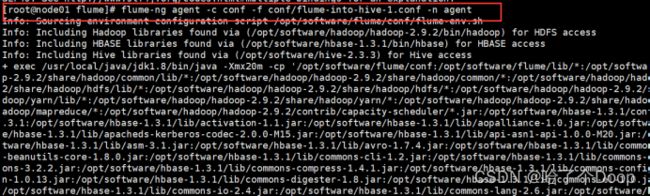
运行成功

5.查询hdfs中的数据

6.在hive表中加载数据
load data inpath '/user/hive/warehouse/flume.db/flume_into_hive/dt=20221110' into table flume_into_hive partition(dt=20221110);
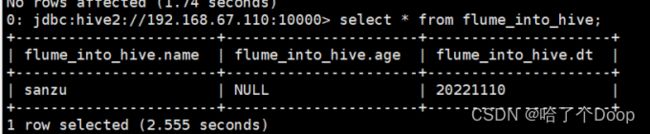
7.查询hive表中的数据
select * from flume_into_hive;
方法二:利用HiveSink汇入数据
- 从hive/lib和和hive/hcatalog/share/hcatalog/中找寻下列JAR包,放入到flume/lib中。
如果flume中有重名的则先删除flume中的再进行复制。

![]()
 2.编写flume的配置文件
2.编写flume的配置文件
vi flume-into-hive-2.conf
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type=exec
a1.sources.s1.command=tail -F /root/flume-hive/hive.log
a1.sinks.k1.type = hive
a1.sinks.k1.channel=c1
a1.sinks.k1.hive.metastore = thrift://node01:9083
a1.sinks.k1.hive.database = flume_hive
a1.sinks.k1.hive.table = flume_into_hive_1
a1.sinks.k1.useLocalTimeStamp = true
a1.sinks.k1.round = false
a1.sinks.k1.roundValue = 10
a1.sinks.k1.roundUnit = minute
a1.sinks.k1.serializer = DELIMITED
a1.sinks.k1.serializer.fieldnames =name,age
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.channel = c1
a1.sources.s1.channels = c1
![]()
3.在hive中创建表
create table flume_into_hive_1(name string,age int) clustered by (age) into 2 buckets stored as orc tblproperties("transactional"='true');
![]()
4.在hive中设置权限
set hive.support.concurrency=true;
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;

5.启动metastore服务
hive --service metastore -p 9083

6.运行flume
bin/flume-ng agent -c conf -f conf/hive/flume-into-hive-2.conf -n a1

7.查询数据

Flume 汇入数据到HBase
一、Flume 的HBaseSinks 详细介绍
Flume 有两大类 HBasesinks: HBaseSink (org.apache.flume.sink.hbase.HBaseSink) 和 AsyncHBaseSink (org.apache.flume.sink.hbase.AsyncHBaseSink) 。
1.1、HBaseSink
HBaseSink提供两种序列化模式:SimpleHbaseEventSerializer和RegexHbaseEventSerializer。
1.1.1、SimpleHbaseEventSerializer
将整个事件event的body部分当做完整的一列写入hbase,因此在插入HBase的时候,一个event的body只能被插入一个column;
1.1.2、RegexHbaseEventSerializer
根据正则表达式将event 的body拆分到不同的列当中,因此在插入HBase的时候,支持用户自定义插入同一个rowkey对应的同一个columnFamily 的多个column。
【优点】
(a) 安全性较高:支持secure HBase clusters (FLUME-1626) ,支持往secure hbase写数据(hbase可以开启kerberos校验);
(b) 支持0.96及以上版本的HBase 的IPC通信
【缺点】
性能没有AsyncHBaseSink高。因为HBaseSink采用阻塞调用(blocking calls),而AsyncHBaseSink采用非阻塞调用(non-blocking calls)。
1.2、AsyncHBaseSink
目前只提供一种序列化模式:SimpleAsyncHbaseEventSerializer:
将整个事件event的body部分当做完整的一列写入hbase,因此在插入HBase的时候,一个event的body只能被插入一个column。
【优点】
AsyncHBaseSink采用非阻塞调用(non-blocking calls),因此,性能比HBaseSink高;
【缺点】
(a) 不支持secure HBase clusters (FLUME-1626),不支持往secure hbase写数据;
(b) 不支持0.96及以上版本的HBase 的IPC通信
- HBaseSinks的三种序列化模式使用
SimpleHbaseEventSerializer
打开hbase客户端
首先在HBase里面建立一个表flume-hbase-table,拥有colfamily1和colfamily2两个列族
create 'flume-hbase-table','colfamily1','colfamily2'

然后写一个flume的配置文件flume-into-hbase.conf:

agent.sources = r1
agent.channels = c1
agent.sinks = s1
agent.sources.r1.type = exec
agent.sources.r1.command = tail -F /root/flume-hbase/test.log
agent.sources.r1.checkperiodic = 50
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100
agent.sinks.s1.type = org.apache.flume.sink.hbase.HBaseSink
agent.sinks.s1.zookeeperQuorum=node01:2181
agent.sinks.s1.table=flume-hbase-table
#HBase表的列族名称
agent.sinks.s1.columnFamily=colfamily1
agent.sinks.s1.serializer = org.apache.flume.sink.hbase.SimpleHbaseEventSerializer
#HBase表的列族下的某个列名称
agent.sinks.s1.serializer.payloadColumn=column-1
agent.sources.r1.channels = c1
agent.sinks.s1.channel=c1
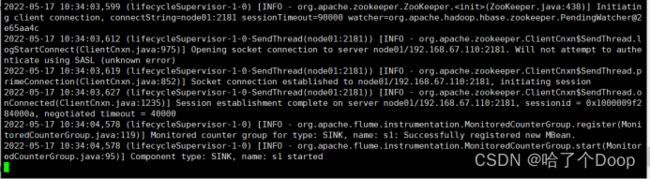
运行Flume:
flume-ng agent -c conf -f conf/flume-into-hbase.conf -n agent -Dflume.root.logger=INFO,console
mkdir flume-hbase
cd flume-hbase
vi test.log

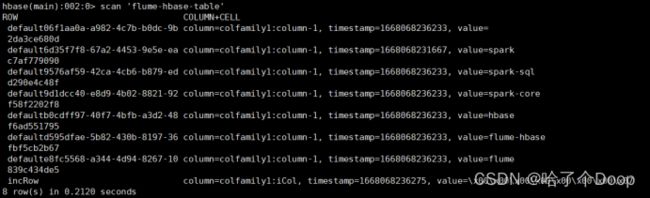
scan 'flume-hbase-table'
SimpleAsyncHbaseEventSerializer
编写flume-into-hbase-1.conf配置文件:
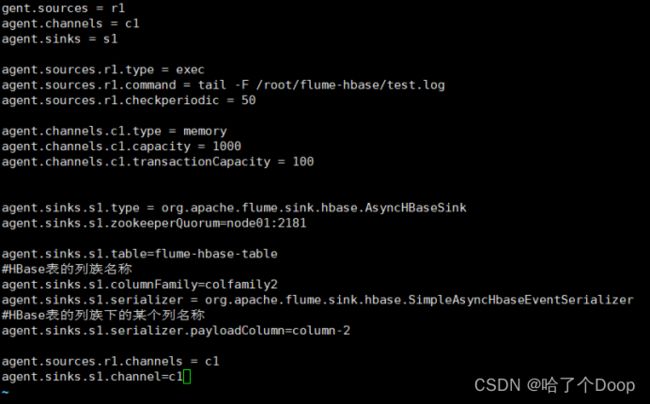
agent.sources = r1
agent.channels = c1
agent.sinks = s1
agent.sources.r1.type = exec
agent.sources.r1.command = tail -F /root/flume-hbase/test.log
agent.sources.r1.checkperiodic = 50
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100
agent.sinks.s1.type = org.apache.flume.sink.hbase.AsyncHBaseSink
agent.sinks.s1.zookeeperQuorum=node01:2181
agent.sinks.s1.table=flume-hbase-table
#HBase表的列族名称
agent.sinks.s1.columnFamily=colfamily2
agent.sinks.s1.serializer = org.apache.flume.sink.hbase.SimpleAsyncHbaseEventSerializer
#HBase表的列族下的某个列名称
agent.sinks.s1.serializer.payloadColumn=column-2
agent.sources.r1.channels = c1
agent.sinks.s1.channel=c1
运行flume:
flume-ng agent -c conf -f conf/flume-into-hbase-1.conf -n agent -Dflume.root.logger=INFO,console

在hbase中查看:
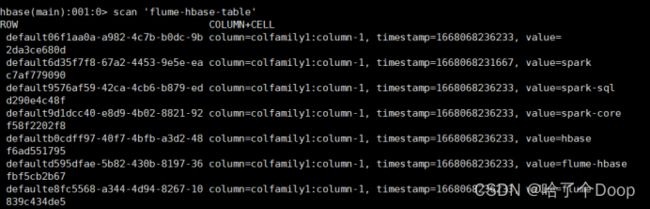
RegexHbaseEventSerializer
编写flume-into-hbase-2.conf配置文件:
agent.sources = r1
agent.channels = c1
agent.sinks = s1
agent.sources.r1.type = exec
agent.sources.r1.command = tail -F /root/flume-hbase/test.log
agent.sources.r1.checkperiodic = 50
agent.channels.c1.type = memory
agent.channels.c1.capacity = 1000
agent.channels.c1.transactionCapacity = 100
agent.sinks.s1.type = org.apache.flume.sink.hbase.HBaseSink
agent.sinks.s1.zookeeperQuorum=node01:2181
agent.sinks.s1.table=flume-hbase-table
#HBase表的列族名称
agent.sinks.s1.columnFamily=colfamily1
agent.sinks.s1.serializer = org.apache.flume.sink.hbase.RegexHbaseEventSerializer
agent.sinks.s1.serializer.regex=\\[(.*?)\\]\\ \\[(.*?)\\]\\ \\[(.*?)\\]
agent.sinks.s1.serializer.colNames=time,url,number
agent.sources.r1.channels = c1
agent.sinks.s1.channel=c1
运行Flume:
flume-ng agent -c conf -f conf/flume-into-hbase-2.conf -n agent -Dflume.root.logger=INFO,console

在/root/flume-hbase/test.log中添加如下数据:

[2022-05-17] [http://www.baidu.com] [20]
[2022-05-17] [http://www.bilibili.com] [25]
[2022-05-17] [http://www.qq.com] [26]
查看hbase的flume-hbase-table:
