2023.9.5 JVM类加载过程、Netty底层NIO模型的底层实现原理
上午全满课,还都是在大教室上,又热又困,勉勉强强写了两道力扣,接着继续看书。
两道题,都算比较简单的,简单说说吧
第一道,像这种一个数组累积什么什么的,一眼用动态规划,难得是要找到正确的规律。这题一眼看上去倒是简单,无脑叠乘积就行,但是这题有负数的存在,所以要同时维护一个dpMin来防止"闲鱼翻身",时间复杂度是O(n),dpMax[i]指的是以nums[i]为结尾的子数组的最大乘积和,看代码应该能直接看懂,就不细说了。

第二道,被分为"技巧"类型的题目,这个题目其实在之前碰到过类似的,只不过数据结构是链表,这个方法的原理是基于抽屉原理(鸽巢原理):如果有n+1个数放在n个抽屉里,那么至少有一个抽屉里会放两个数。直接讲解题法,第一步:设两个快慢指针,一个一次移动一步,一个一次移动两步,假如相遇了,那说明就肯定有重复数/链表肯定有环;第二步:把快指针设成和慢指针一样的速度,继续前进,再次相遇就是重复的数/链表环的开始。非常有意思的一道题。

写完题接着看《深入理解JAVA虚拟机》,昨天看到第四章,往后连续好几章就是JVM调优的东西了,我觉得这些可以往后再看,遂直接跳到第七章,看类加载相关的,简单说一下吧。
一个类型从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期将会经历加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)七个阶段,其中验证、准备、解析三个部分统称为连接(Linking)。一般我们讲的都是加载、连接、初始化这三个阶段,下面我会简单说一下这三个阶段的内容。
1、加载,虚拟机主要做这3件事:
(1)通过一个类的全限定名来获取定义此类的二进制字节流。
(2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
(3)在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
这三点其实要求的不是非常具体,所以就给了开发者们非常大的发挥空间。比如说获取全类名,可以从JAR包中获取,也可以从网络中获取,也可以在运行时计算生成(代理对象)。而数组类则不太一样,它不通过类加载器创建,而是JVM直接在内存中动态构造出来,但是数组的元素类型还是得靠类加载器来完成加载。加载与连接的部份动作是交叉进行的,可能加载尚未完成,连接就已经开始。
将类的数据安置在方法区之后,会在堆中实例话一个java.lang.Class类的对象,这个对象将作为程序访问方法区中的类型数据的外部接口。
2、验证,为了确保Class字节流中的包含信息符合规范,主要有下面四个检验动作:
(1)文件格式验证,主要验证字节流是否符合Class文件格式的规范,比如版本号是否在jvm接受范围内、常量池是否有不被支持的常量类型;
(2)元数据验证,主要对字节码描述的信息进行语义分析,以保证其满足规范,比如这个类是否有父类,是否继承了不允许被继承的类;
(3)字节码验证,主要通过数据流分析和控制流分析,确定程序语义是合法的,比如有没有吧把对象赋值给没有继承关系的数据类型;
(4)符号引用验证,这个行为将在解析阶段发生,这个阶段主要验证是否缺少或被禁止访问它依赖的某些外部类、方法、字段等资源。
3、准备,为类中静态变量分配内存并设置初始值的阶段,静态变量会随着Class对象一起被存放在堆中。
4、解析,将常量池内的符号引用替换为直接引用的过程。
(1)符号引用(Symbolic References):符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可;
(2)直接引用(Direct References):直接引用是可以直接指向目标的指针、相对偏移量或者是一个能间接定位到目标的句柄。
5、初始化,执行类构造器
上周开始做的黑马点评姑且算是做完了,开始准备投简历了,希望顺利吧。
打完上面这堆就去准备面试了,先从项目开始。
我有个手写RPC框架的项目,里面用到了两种网络通信框架,一个是阻塞的Tomcat,一个是非阻塞的Netty,但是我只是使用了而没有深入了解,所以花了点时间去学习了下Netty底层的实现,这里简单说下。
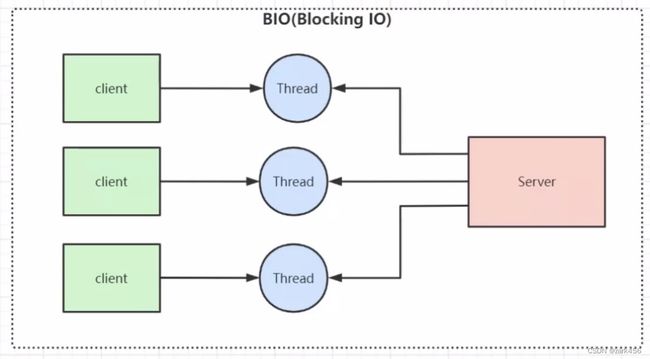
从BIO开始,顾名思义,阻塞的IO,BIO是最传统的I/O模型,它是同步阻塞的。在BIO中,当一个线程调用输入输出操作时,它会被阻塞直到操作完成。这意味着一个线程只能处理一个连接,如果有多个连接需要处理,就需要创建多个线程。这种模型在连接数较少时运行良好,但在高并发情况下,线程数量的增加会导致系统资源消耗过大。当然,我的程序中也进行了简单的优化,我会在接受到新的连接之后,单独创建一个线程去处理它,不过这不是一劳永逸的方法,随着连接数的增多,性能也会有下降;
然后就是NIO了,NIO是Java 1.4中引入的一种非阻塞I/O模型。它通过使用选择器(Selector)和通道(Channel)来实现非阻塞操作。在NIO中,一个线程可以管理多个连接,通过选择器监听多个通道的事件,当有事件发生时,线程可以处理这些事件。NIO适用于需要处理大量连接但每个连接处理时间较短的场景,如聊天服务器。
首先是大体实现流程,最简单的NIO实现是通过Channel实现的,建立连接之后,把连接放进一个专门存放Channel的集合中,接着去遍历Channel集合,假如该连接收到了消息,就会处理。这种做法只需要一个线程来处理连接的建立,把信息的处理交给了Channel集合,从而无需阻塞负责建立连接的线程。但是这种做法会有种浪费,Channel中的每一个连接不一定都有消息发送,而逐个遍历无疑是浪费资源的行为。
基于这个问题,引入了selector(多路复用器)。首先与上面说的一样,会建立Channel,然后存放到Channel集合中,但是同时会把这些Channel注册到多路复用器,来监听消息,从而做到只遍历处理有消息的Channel。
这个多路复用器涉及到一个叫epoll相关的函数底层实现,这些都是底层C语言的源码:
1、epoll_create:建立selector多路复用器,底层是一个结构题;
2、epoll_ctl:负责监听Channel集合,假如某个Channel有消息,就把这个Channel放到rdist中,这是一个专门存放有消息的Channel的集合;
3、epoll_wait:负责监听rdlist,也就是负责处理Channel中的消息。

那么还有一个问题,select、poll、epoll有什么区别?
select就是上面讲的NIO大体实现流程,它会遍历所有Channel,而且最大连接数有限制,是1024;而poll与select大体相似,只是更改了存储结构和使连接无上限。

奥还有一个AIO,这里也简单提一下吧。
AIO是Java 7中引入的一种异步非阻塞I/O模型。在AIO中,当一个线程发起输入输出操作时,它不会被阻塞,而是继续执行其他操作。当操作完成后,系统会通知线程进行处理。这种模型可以处理多个连接而不需要创建大量线程,因此在高并发情况下具有更好的性能。AIO是一种异步非阻塞I/O模型,通过异步回调机制来处理I/O操作,适用于需要处理大量并发操作的场景。
ok那么Netty的底层实现就讲完了。
收工。