数据分析师的学习之路-pandas篇(7)
继续接上篇,这次学习下透视表、线性回归还有根据条件上颜色。
3.9 透视表
在excel里也经常用到透视表来构建想要的列的组合来形成一个新的表,在pandas里也能做。
举例数据是这样的:

是各种类产品的订单数据,现在想做一个透视表,看看各种类(Category)在每年的销售额数据。
先导入库和读入文件:
import pandas as pd
#因为一会儿销售额会求和,所以要导入这个库
import numpy as np
#读进来
orders = pd.read_excel("C:/tmp/1.xlsx")
要按年来看,而此时Date的格式是个datetime格式,我们只要获取年:
orders['Year'] = pd.DatetimeIndex(orders['Date']).year
然后就可以生成透视表了,也有专门的函数调用,最后的参数可以传入一个方法来计算values
pt1 = orders.pivot_table(index='Catgory', columns='Year', values='Total', aggfunc=np.sum)
这样结果就是:

得到了一个表,每行是一个种类的销售额,每列就是不同年份。
3.10 线性回归
线性回归原理会有单独的学习,这里是用pandas直接跑出来线性回归方程并画图。
假设有这样的数据,是每月的营业额:

先导入库和文件
import pandas as pd
import matplotlib.pyplot as plt
#也导入计算线性回归的库
from scipy.stas import linregress
#读文件,由于month列格式有点像float会被判断错格式,所以要设置下该列是string类型
sales = pd.read_excel("C:/tmp/1.xlsx", dtype={'Month':str})
求线性回归方程,得到的结果slope是斜率,intercept是截距,std_err是标准差,r和p先不用,也就是通过这个函数直接得到:
slope, intercept, r, p, std_err = linregress(sales.index, sales.Revenue)
得到了参数,那么线性回归方程就出来了,正常就是 y=kx+c, 这里k就是slope, c就是intercept,x就是index,y就是销售额
#得到所有的exp的结果
exp=sale.index * slope + intercept
然后画个图,一般用散点图看起来明显,然后把线性回归的那条线画出来,一目了然。
#散点图
plt.scatter(sales.index, sales.Revenue)
#画个线,用橙色明显一点
plt.plot(sales.index, exp, color='orange')
#加个标题, 标题就用这个线性回归方程当标题吧
plt.title(f"y={slope}*x + {intercept}")
#x轴显示标签名并转90度
plt.xticks(sales.index, sales.Month, rotation=90)
#画出来
plt.tight_layout()
plt.show()
最后画出来就长这样:
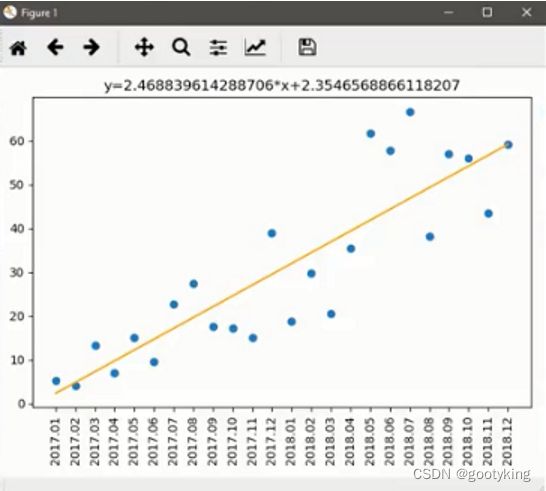
有了这个方程,就可以预测未来的销售额了。
3.11 上点颜色
有时候表数据一堆很难一目了然知道数据的情况,当给一些不同条件弄上不同颜色,就清楚多了,例如这样一组数据,是学生3次考试的成绩:
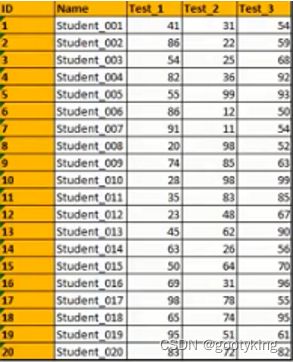
我们想一目了然的了解成绩情况,可以把不及格的标成红色,每次成绩最高的标成绿色。
先导入库和读入文件:
import pandas as pd
students = pd.read_excel("C:/tmp/1.xlsx")
为了实现标红色和绿色,分别定义一个函数:
#把不及格的标红色
def low_score_red(s):
color = "red" if s<60 else "black"
return f"color:{color}"
#把每列最高分标绿色
def highest_score_green(col):
return ['background-color:lime' if s==col.max() else 'background-color.white' for s in col]
然后呢用dataframe的applymap方法传入筛选函数
#不及格标红
students.style.applymap(low_score_red, subset=['Test_1', 'Test_2', 'Test_3'])
然后也要把每列最高分标绿,其实可以和上面这句合并,加到后面,所以上面这句就改成:
students.style.applymap(low_score_red, subset=['Test_1', 'Test_2', 'Test_3'])\
.apply(highest_score_green, subset=['Test_1', 'Test_2', 'Test_3'])
这里第一个用的applymap,是因为要对所有单元格操作,而后面用apply是只针对某一列来操作。
然后打印student一看,结果就对了:

现在想用一种颜色的深浅来表达数值的高低,分数越高就越深,怎么弄呢:
import pandas as pd
#要在前面多导入一个库来画颜色
import seaborn as sns
#然后相当于生成一个调色板
color_map = sns.light_palette('green', as_cmap = True)
#读入文件
students = pd_read_excel("C:/tmp/1.xlsx", index_col='ID')
#画
students.style.background_gradient(color_map, subset=['Test_1', 'Test_2', 'Test_3'])
最终students的结果就是这样:
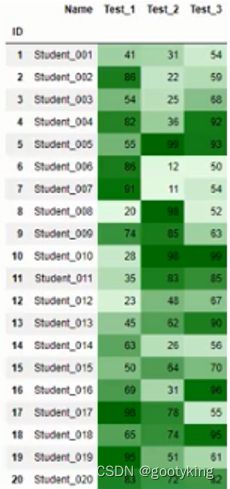
如果想用一个柱状颜色条来表示成绩的高低,越长成绩越高,怎么弄呢:
import pandas as pd
#这个情况,就不用seaborn库了
#读入文件
students = pd_read_excel("C:/tmp/1.xlsx", index_col='ID')
#直接画
students.style.bar(color='orange', subset=['Test_1', 'Test_2', 'Test_3'])
最总students的效果是这样:
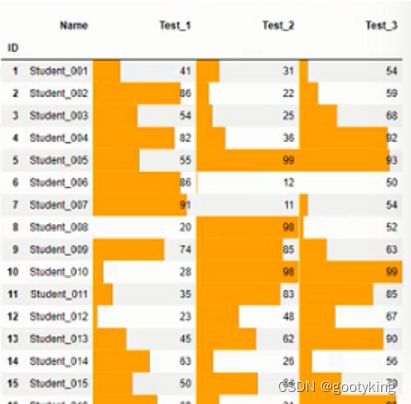
今天先学到这,下一篇总结一下,把所有的行和列的常用操作都整理一下。