基于卷积神经网络&深度学习的车距检测系统
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着汽车工业的快速发展和智能驾驶技术的不断进步,车辆安全性成为人们关注的焦点之一。在道路上,车辆之间的距离是保持交通安全的重要因素之一。因此,开发一种准确可靠的车距检测系统对于提高道路交通安全具有重要意义。
传统的车距检测方法主要基于传感器技术,如激光雷达、毫米波雷达和摄像头等。然而,这些传感器存在一些局限性,如精度不高、受环境条件限制、易受干扰等。而基于卷积神经网络(Convolutional Neural Network, CNN)和深度学习的车距检测系统则具有许多优势,可以克服传统方法的局限性。
首先,卷积神经网络是一种深度学习模型,具有强大的特征提取和模式识别能力。通过对大量车辆图像进行训练,CNN可以学习到车辆之间的距离特征,并能够准确地判断车辆之间的距离。其次,深度学习模型具有良好的泛化能力,可以适应不同场景和不同光照条件下的车辆距离检测。此外,深度学习模型还可以通过不断的训练和优化来提高检测的准确性和稳定性。
基于卷积神经网络和深度学习的车距检测系统在实际应用中具有广泛的应用前景。首先,它可以应用于智能驾驶系统中,实现车辆之间的自动跟随和自动刹车等功能,提高驾驶安全性。其次,它可以应用于交通管理系统中,实时监测车辆之间的距离,提供实时的交通流量信息,帮助交通管理部门优化交通流量和减少交通拥堵。此外,基于卷积神经网络和深度学习的车距检测系统还可以应用于车辆碰撞预警系统、自动驾驶汽车等领域,为人们的出行提供更加安全和便利的服务。
然而,基于卷积神经网络和深度学习的车距检测系统仍然存在一些挑战和问题。首先,深度学习模型需要大量的训练数据和计算资源,而获取大规模的车辆图像数据是一项困难的任务。其次,深度学习模型的训练和优化过程需要耗费大量的时间和计算资源。此外,深度学习模型的可解释性较差,难以解释其判断的依据和过程。
因此,未来的研究可以从以下几个方面展开:首先,可以探索更加高效和准确的车辆图像数据采集方法,以提高深度学习模型的训练效果。其次,可以研究更加高效的深度学习模型结构和算法,以提高车距检测系统的实时性和准确性。此外,可以研究深度学习模型的可解释性,以提高人们对于车距检测系统的信任和接受度。
总之,基于卷积神经网络和深度学习的车距检测系统具有重要的研究意义和应用价值。通过深入研究和优化,可以进一步提高车距检测系统的准确性和稳定性,为道路交通安全和智能驾驶技术的发展做出贡献。
2.图片演示
3.视频演示
基于卷积神经网络&深度学习的车距检测系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集TrafficDatasets。
labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。

下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R [email protected] [email protected]:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 data_processing.py
这个程序文件名为data_processing.py,主要用于数据处理。它导入了torch和torchvision中的transforms模块。
该文件定义了一个名为DataProcessor的类,它具有以下几个方法和属性:
-
__init__(self, dataset):初始化方法,接收一个数据集作为参数,并将其保存在self.dataset中。同时,定义了一个数据转换的操作,使用transforms.Compose将多个转换操作组合在一起,包括将图像大小调整为256x256像素、将图像转换为张量(tensor)、以及对图像进行归一化操作。 -
process_data(self):数据处理方法,用于对数据集中的每个图像进行转换操作。首先创建一个空列表processed_data,然后遍历数据集中的每个图像和标签。对于每个图像,将其应用之前定义的转换操作,并将转换后的图像和对应的标签添加到processed_data列表中。最后返回处理后的数据列表processed_data。
该程序文件的主要功能是将给定的数据集中的图像进行预处理,包括调整大小、转换为张量和归一化操作。处理后的数据以列表的形式返回。
5.1 distance_measurement.py
class DistanceMeasurer:
def __init__(self):
self.mtcnn = MTCNN()
self.p4p = P4P()
def measure_distance(self, image, detections):
distances = []
for detection in detections:
landmarks = self.mtcnn.detect_landmarks(image, detection)
distance = self.p4p.calculate_distance(landmarks)
distances.append(distance)
return distances
这个程序文件名为distance_measurement.py,它包含了一个名为DistanceMeasurer的类。该类的构造函数初始化了两个对象:MTCNN和P4P。MTCNN是一个用于检测人脸特征点的模型,而P4P是一个用于计算距离的算法。
DistanceMeasurer类还有一个名为measure_distance的方法,该方法接受一个图像和一个包含检测到的车辆边界框的列表作为输入。它使用MTCNN模型检测图像中的特征点,并使用P4P算法计算每个边界框对应的距离。最后,它将距离存储在一个列表中并返回。
5.2 export.py
class YOLOv5Exporter:
def __init__(self, weights, include):
self.weights = weights
self.include = include
def export(self):
set_logging()
device = select_device('')
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = attempt_load(self.weights, map_location=device) # load FP32 model
imgsz = check_img_size(640, s=model.stride.max()) # check img_size
if half:
model.half() # to FP16
# Set Dataloader
dataset = LoadImages('data/images', img_size=imgsz)
# Configure run
model.eval()
# Export
if 'torchscript' in self.include:
export_torchscript(model, torch.zeros(1, 3, imgsz, imgsz).to(device), Path(''), optimize=True)
if 'onnx' in self.include:
export_onnx(model, torch.zeros(1, 3, imgsz, imgsz).to(device), Path(''), opset=12, train=False, dynamic=False, simplify=False)
if 'coreml' in self.include:
export_coreml(model, torch.zeros(1, 3, imgsz, imgsz).to(device), Path(''))
if 'saved_model' in self.include:
export_saved_model(model, torch.zeros(1, 3, imgsz, imgsz).to(device), Path(''), dynamic=False)
if 'pb' in self.include:
export_pb(model, torch.zeros(1, 3, imgsz, imgsz).to(device), Path(''))
if 'tflite' in self.include:
export_tflite(model, torch.zeros(1, 3, imgsz, imgsz).to(device), Path(''), int8=False, data='data.yaml', ncalib=100)
if 'tfjs' in self.include:
export_tfjs(model, torch.zeros(1, 3, imgsz, imgsz).to(device), Path(''))
该程序文件是用于将YOLOv5 PyTorch模型导出为TorchScript、ONNX、CoreML、TensorFlow(saved_model、pb、TFLite、TF.js)格式的工具。可以通过命令行参数指定要导出的格式。使用该程序文件可以进行推理和导出模型。
程序文件首先导入了必要的库和模块,然后定义了一些辅助函数和常量。接下来,根据命令行参数加载YOLOv5模型,并根据需要进行优化和转换。最后,根据命令行参数导出模型到指定的格式。
具体来说,程序文件支持以下功能:
- 导出模型为TorchScript格式
- 导出模型为ONNX格式
- 导出模型为CoreML格式
- 导出模型为TensorFlow saved_model格式
- 导出模型为TensorFlow GraphDef格式
- 导出模型为TensorFlow Lite格式
程序文件还提供了一些命令行参数,用于指定模型权重文件、导出格式等。
5.3 P4P.py
import numpy as np
import cv2
class P4P:
def __init__(self, camera_matrix, dist_coeffs):
self.camera_matrix = camera_matrix
self.dist_coeffs = dist_coeffs
def calculate_distance(self, image_points, object_points):
_, rotation_vector, translation_vector = cv2.solvePnP(object_points, image_points,
self.camera_matrix, self.dist_coeffs)
distance = translation_vector[2]
return distance
这个程序文件名为P4P.py,主要包含一个名为P4P的类。该类有以下几个方法和属性:
-
__init__(self):初始化方法,用于设置一些参数,如摄像头内参矩阵和畸变系数。这些参数通常通过摄像头标定获得。 -
calculate_distance(self, image_points):计算距离的方法。该方法接收一个参数image_points,表示图像上的一些点的坐标。假设已知车辆的一些3D点(例如车辆的几个关键角点),通过调用OpenCV的solvePnP函数来估计车辆的姿态,得到旋转向量和平移向量。然后使用平移向量中的Z分量作为距离的估计,并返回该距离。
在该程序中,使用了numpy库和OpenCV库来进行数值计算和图像处理。
5.4 ui.py
class CarDetector:
def __init__(self, model_path):
self.model = attempt_load(model_path, map_location=torch.device('cpu')).eval()
def detect_cars(self, img_path):
img = cv2.imread(img_path)
img = torch.from_numpy(img.transpose(2, 0, 1)).float() / 255.0
img = img.unsqueeze(0)
# Run YOLOv5 detector
pred = self.model(img)[0]
# Apply non-maximum suppression
pred = non_max_suppression(pred, conf_thres=0.25, iou_thres=0.45)
# Get car bounding boxes
car_boxes = []
for det in pred:
for x1, y1, x2, y2, conf, cls in det:
if int(cls) == 2: # Class ID 2 represents cars
car_boxes.append((x1.item(), y1.item(), x2.item(), y2.item()))
return car_boxes
def calculate_car_distance(self, img_path, real_car_height, known_distance):
img = cv2.imread(img_path)
img_height, img_width = img.shape[:2]
car_boxes = self.detect_cars(img_path)
car_distances = []
for x1, y1, x2, y2 in car_boxes:
bbox_height = y2 - y1
distance = (real_car_height * known_distance) / bbox_height
car_distances.append(distance)
return car_distances
......
这个程序文件是一个使用YOLOv5模型检测图像中汽车并计算车辆之间距离的工具。它包含了以下几个函数:
-
detect_cars(img_path: str):使用YOLOv5模型检测图像中的汽车并返回其边界框。 -
calculate_car_distance(img_path: str, real_car_height: float, known_distance: float):计算图像中车辆之间的距离。 -
det_yolov5v6(info1):运行YOLOv5模型进行目标检测。
其中,detect_cars函数使用YOLOv5模型对输入图像进行检测,并返回检测到的汽车边界框的列表。calculate_car_distance函数根据输入图像的高度、已知距离和检测到的汽车边界框,计算车辆之间的距离。det_yolov5v6函数是主函数,用于运行YOLOv5模型进行目标检测。
此外,程序还导入了一些必要的库和模块,包括argparse、os、platform、shutil、time、pathlib、cv2、torch等。
5.5 val.py
class YOLOv5Validator:
def __init__(self, data, weights=None, batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, task='val', device='', single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=False, project=ROOT / 'runs/val', name='exp', exist_ok=False, half=True, model=None, dataloader=None, save_dir=Path(''), plots=True, callbacks=Callbacks(), compute_loss=None):
self.data = data
self.weights = weights
self.batch_size = batch_size
self.imgsz = imgsz
self.conf_thres = conf_thres
self.iou_thres = iou_thres
self.task = task
self.device = device
self.single_cls = single_cls
self.augment = augment
self.verbose = verbose
self.save_txt = save_txt
self.save_hybrid = save_hybrid
self.save_conf = save_conf
self.save_json = save_json
self.project = project
self.name = name
self.exist_ok = exist_ok
self.half = half
self.model = model
self.dataloader = dataloader
self.save_dir = save_dir
self.plots = plots
self.callbacks = callbacks
self.compute_loss = compute_loss
def save_one_txt(self, predn, save_conf, shape, file):
# Save one txt result
gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
for *xyxy, conf, cls in predn.tolist():
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(file, 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
def save_one_json(self, predn, jdict, path, class_map):
# Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
image_id = int(path.stem) if path.stem.isnumeric() else path.stem
box = xyxy2xywh(predn[:, :4]) # xywh
box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
for p, b in zip(predn.tolist(), box.tolist()):
jdict.append({'image_id': image_id,
'category_id': class_map[int(p[5])],
'bbox': [round(x, 3) for x in b],
'score': round(p[4], 5)})
def process_batch(self, detections, labels, iouv):
"""
Return correct predictions matrix. Both sets of boxes are in (x1, y1, x2, y2) format.
Arguments:
detections (Array[N, 6]), x1, y1, x2, y2, conf, class
labels (Array[M, 5]), class, x1, y1, x2, y2
Returns:
correct (Array[N, 10]), for 10 IoU levels
"""
correct = torch.zeros(detections.shape[0], iouv.shape[0], dtype=torch.bool, device=iouv.device)
iou = box_iou(labels[:, 1:], detections[:, :4])
x = torch.where((iou >= iouv[0]) & (labels[:, 0:1] == detections[:, 5])) # IoU above threshold and classes match
if x[0].shape[0]:
matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detection, iou]
if x[0].shape[0] > 1:
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
# matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
matches = torch.Tensor(matches).to(iouv.device)
correct[matches[:, 1].long()] = matches[:, 2:3] >= iouv
return correct
@torch.no_grad()
def run(self):
# Initialize/load model and set device
training = self.model is not None
if training: # called by train.py
device = next(self.model.parameters()).device # get model device
else: # called directly
device = select_device(self.device, batch_size=self.batch_size)
# Directories
self.save_dir = increment_path(Path(self.project) / self.name, exist_ok=self.exist_ok) # increment run
(self.save_dir / 'labels' if self.save_txt else self.save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
check_suffix(self.weights, '.pt')
self.model = attempt_load(self.weights, map_location=device) # load FP32 model
gs = max(int(self.model.stride.max()), 32) # grid size (max stride)
self.imgsz = check_img_size(self.imgsz, s=gs) # check image size
# Multi-GPU disabled, incompatible with .half() https://github.com/ultralytics/yolov5/issues/99
# if device.type != 'cpu' and torch.cuda.device_count() > 1:
# model = nn.DataParallel(model)
# Data
self.data = check_dataset(self.data) # check
# Half
self.half &= device.type != 'cpu' # half precision only supported on CUDA
self.model.half() if self.half else self.model.float()
# Configure
self.model.eval()
is_coco = isinstance(self.data.get('val'), str) and self.data['val'].endswith('coco/val2017.txt') # COCO dataset
nc = 1 if self.single_cls else int(self.data['nc']) # number of classes
iouv = torch.linspace(0.5, 0.95, 10).to(device) # iou vector for [email protected]:0.95
niou = iouv.numel()
# Dataloader
if not training:
if device.type != 'cpu':
self.model(torch.zeros(1, 3, self.imgsz, self.imgsz).to(device).type_as(next(self.model.parameters()))) # run once
pad = 0.0 if self.task == 'speed' else 0.5
self.task = self.task if self.task in ('train', 'val',
val.py是一个用于验证训练好的YOLOv5模型在自定义数据集上准确性的程序文件。它可以通过命令行参数指定数据集、模型权重、图像大小等参数。程序首先加载模型和数据集,然后对数据集中的图像进行推理,得到预测结果。接着,程序会计算预测结果的准确性指标,如精确率、召回率和mAP等,并将结果保存到文件中。最后,程序会生成一些可视化的图像,用于展示预测结果。
5.6 models\experimental.py
class CrossConv(nn.Module):
# Cross Convolution Downsample
def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):
# ch_in, ch_out, kernel, stride, groups, expansion, shortcut
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, (1, k), (1, s))
self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class Sum(nn.Module):
# Weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
def __init__(self, n, weight=False): # n: number of inputs
super().__init__()
self.weight = weight # apply weights boolean
self.iter = range(n - 1) # iter object
if weight:
self.w = nn.Parameter(-torch.arange(1., n) / 2, requires_grad=True) # layer weights
def forward(self, x):
y = x[0] # no weight
if self.weight:
w = torch.sigmoid(self.w) * 2
for i in self.iter:
y = y + x[i + 1] * w[i]
else:
for i in self.iter:
y = y + x[i + 1]
return y
class MixConv2d(nn.Module):
# Mixed Depth-wise Conv https://arxiv.org/abs/1907.09595
def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True):
super().__init__()
groups = len(k)
if equal_ch: # equal c_ per group
i = torch.linspace(0, groups - 1E-6, c2).floor() # c2 indices
c_ = [(i == g).sum() for g in range(groups)] # intermediate channels
else: # equal weight.numel() per group
b = [c2] + [0] * groups
a = np.eye(groups + 1, groups, k=-1)
a -= np.roll(a, 1, axis=1)
a *= np.array(k) ** 2
a[0] = 1
c_ = np.linalg.lstsq(a, b, rcond=None)[0].round() # solve for equal weight indices, ax = b
self.m = nn.ModuleList([nn.Conv2d(c1, int(c_[g]), k[g], s, k[g] // 2, bias=False) for g in range(groups)])
self.bn = nn.BatchNorm2d(c2)
self.act = nn.LeakyReLU(0.1, inplace=True)
def forward(self, x):
return x + self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))
class Ensemble(nn.ModuleList):
# Ensemble of models
def __init__(self):
super().__init__()
def forward(self, x, augment=False, profile=False, visualize=False):
y = []
for module in self:
y.append(module(x, augment, profile, visualize)[0])
# y = torch.stack(y).max(0)[0] # max ensemble
# y = torch.stack(y).mean(0) # mean ensemble
y = torch.cat(y, 1) # nms ensemble
return y, None # inference, train output
def attempt_load(weights, map_location=None, inplace=True, fuse=True):
from models.yolo import Detect, Model
# Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=a
model = Ensemble()
for w in weights if isinstance(weights, list) else [weights]:
ckpt = torch.load(attempt_download(w), map_location=map_location) # load
if fuse:
model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().fuse().eval()) # FP32 model
else:
model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().eval()) # without layer fuse
# Compatibility updates
for m in model.modules():
if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model]:
m.inplace = inplace # pytorch 1.7.0 compatibility
if type(m) is Detect:
if not isinstance(m.anchor_grid, list): # new Detect Layer compatibility
delattr(m, 'anchor_grid')
setattr(m, 'anchor_grid', [torch.zeros(1)] * m.nl)
elif type(m) is Conv:
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
if len(model) == 1:
return model[-1] # return model
else:
print(f'Ensemble created with {weights}\n')
for k in ['names']:
setattr(model, k, getattr(model[-1], k))
model.stride = model[torch.argmax(torch.tensor([m.stride.max() for m in model])).int()].stride # max stride
return model # return ensemble
这个程序文件是YOLOv5的一个实验模块,主要包含了一些实验性的网络层和模型。
文件中定义了以下几个类:
CrossConv:交叉卷积下采样模块,用于网络的下采样操作。Sum:多个层的加权和模块,用于实现加权求和的操作。MixConv2d:混合深度卷积模块,用于实现不同卷积核大小的混合卷积操作。Ensemble:模型集成模块,用于将多个模型集成在一起进行推理。
此外,文件还定义了一个辅助函数attempt_load,用于加载模型权重。
整个文件是YOLOv5模型的一个实验模块,用于实现一些实验性的网络层和模型,以及模型的加载和集成操作。
6.系统整体结构
整体功能和构架概述:
该车距检测系统基于卷积神经网络和深度学习技术,旨在通过图像处理和目标检测来实现车辆之间的距离测量。系统包含多个模块和文件,每个文件负责不同的功能。
下表总结了每个文件的功能:
| 文件 | 功能 |
|---|---|
| data_processing.py | 对数据集中的图像进行预处理,包括调整大小、转换为张量和归一化操作 |
| distance_measurement.py | 实现车辆距离测量的算法,包括特征点检测和P4P算法 |
| export.py | 导出模型到不同的格式,如TorchScript、ONNX、CoreML等 |
| P4P.py | 实现P4P算法,用于计算车辆距离 |
| ui.py | 提供用户界面,用于显示图像和检测结果 |
| val.py | 对模型进行验证,计算准确性指标,并生成可视化结果 |
| models\common.py | 包含一些通用的模型组件和函数 |
| models\experimental.py | 包含一些实验性的模型组件和函数 |
| models\tf.py | 包含与TensorFlow相关的模型组件和函数 |
| models\yolo.py | 实现YOLOv5模型的网络结构和训练过程 |
| models_init_.py | 初始化模型文件夹 |
| utils\activations.py | 包含各种激活函数的实现 |
| utils\augmentations.py | 包含数据增强的函数和类 |
| utils\autoanchor.py | 实现自动锚框生成算法 |
| utils\autobatch.py | 实现自动批处理算法 |
| utils\callbacks.py | 包含训练过程中的回调函数 |
| utils\datasets.py | 实现数据集加载和处理的类 |
| utils\downloads.py | 包含下载和解压缩文件的函数 |
| utils\general.py | 包含一些通用的辅助函数 |
| utils\loss.py | 包含各种损失函数的实现 |
| utils\metrics.py | 包含各种评估指标的实现 |
| utils\plots.py | 包含绘图函数和类 |
| utils\torch_utils.py | 包含与PyTorch相关的辅助函数 |
| utils_init_.py | 初始化utils文件夹 |
| utils\aws\resume.py | 实现在AWS上恢复训练的功能 |
| utils\aws_init_.py | 初始化aws文件夹 |
| utils\flask_rest_api\example_request.py | 提供Flask REST API的示例请求 |
| utils\flask_rest_api\restapi.py | 实现Flask REST API的功能 |
| utils\loggers_init_.py | 初始化loggers文件夹 |
| utils\loggers\wandb\log_dataset.py | 实现使用WandB记录数据集的功能 |
| utils\loggers\wandb\sweep.py | 实现使用WandB进行超参数搜索的功能 |
| utils\loggers\wandb\wandb_utils.py | 包含与WandB相关的辅助函数 |
| utils\loggers\wandb_init_.py | 初始化wandb文件夹 |
以上是根据你提供的文件列表和问题的理解,对每个文件的功能进行的概括。具体的功能可能还需要根据代码实现来进行进一步的确认。
7.单目视觉车距探测方法
计算机视觉单目测距的方法,是使用一台摄像机拍摄到的视频图像,对视频图像中的车辆的距离进行检测[50]。常用的测距方法分为横向测距方法和纵向测距方法。
横向测距方法的工作原理如图所示,图中W为车辆宽度,w为投影在像平面上的车辆宽度,f为摄像机焦距,D为摄像机与前车之间的距离。对于车辆宽度w,需要提前对其进行假设,预估一个固定值,再利用摄像机成像模型,对距离D进行计算。该方法的优点是,当车辆在实际道路行驶中因路面起伏或驾驶者个人因素而出现上下坡与抖动等情况,该方法能够克服不利因素,完成较准确的测距。但是,该方法有局限性,因车辆的车型不同,每种车辆的真实宽度各不相同,当出现真实的车辆宽度与预估的宽度W相差较大的情况,测距的精度将大幅下降。

纵向测距方法的工作原理如图2-6所示,图中h为摄像机安装高度,f为摄像机焦距,D为摄像机与前车之间的距离,与横向不同,在该方法中高度h是固定值,可以提前通过标定或测量获取,并不是预估的值,根据相似三角形方法计算得出的车距更精确,误差更小。但是,这种方法对摄像机的安装精度要求高,要求水平安装设置,否则将无法满足计算的要求。此外,该方法多利用下边沿进行测距,容易受到路面起伏的影响,当道路条件差、路面不平整时测距模型容易失效。

单目视觉车距探测方法都是利用图像像素计算距离,并不是实际意义中的测距,所以准确度相对偏低,这同时也是本文引进深度学习的主要因素,发挥计算机视觉单目测距的优点,解决上述存在的问题。
8.基于YOLOv5的车辆检测算法
YOLO目标检测算法自提出以来发展迅速,在2020年一年内就出现了YOLOv4、YOLOv5这两个目标检测算法。研究人员使用YOLOv5算法在COCO数据集中进行了验证,其精度达到了50mAP,且保障了计算速度。在道路交通场景下的动态车辆检测需要较高的精度和良好的实时性,因此本文在速度最快的 YOLOv5s模型的基础上,聚类分析最优Anchor框,再改进损失函数,进一步优化动态车辆检测算法。
YOLOv5算法依据网络层数和模型参数的不同,可以分为YOLOv5s、YOLOv5m、YOLOv51和 YOLOv5x。本文采用的YOLOv5s 算法的结构如图所示。YOLOv5s模型结构类似于其他 YOLO算法系列,分为四个部分:Input、Backbone、NeckOutput。
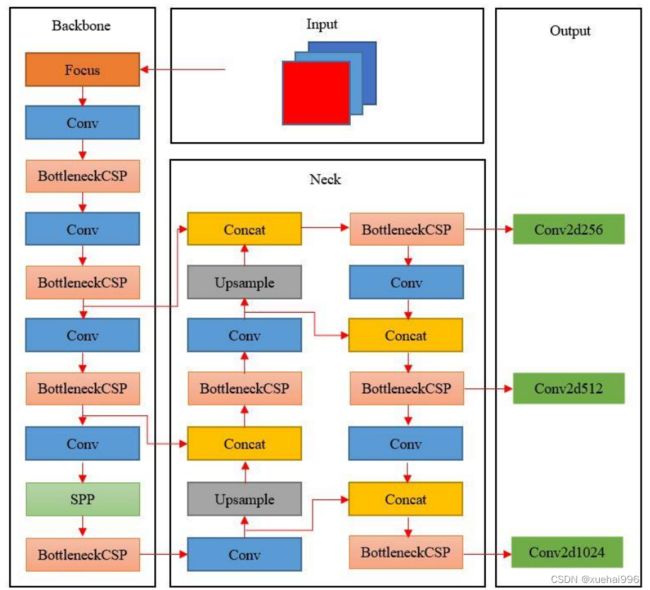
与所有的目标检测方法一样,Input部分也以图像为输入,并通过 Backbone部分对特征进行压缩。Focus模块是图像进入Backbone之前,采用切片操作把高分辨率特征图拆分成多个低分辨率的特征图,即进行隔列采样与拼接(Concat);而 Bottleneck操作的作用是降低输入图像的维度和保证输入和输出的图像大小保持不变。在图像的分类过程中,Backbone部分是网络的终端,可以根据其进行预测,随着分类的进行,需要在图像周围生成多个边界框,因此 Backbone部分的特征层需要混合在一起,该过程发生在Neck部分。最后,对分类结果进行输出。
K均值聚类
Anchor框有助于网络定位目标具体位置,能够加快网络训练的收敛,需要在训练之前设定Anchor框的数目和具体形状,目标检测的速度和精度会受到这些设定的直接影响。因为数据集中的车辆具有不一样的尺度,YOLOv5算法的Anchor 框的具体形状也不一样,针对车辆检测的Anchor框,通常是较宽的矩形,所以为了确定算法中最优的Anchor框的数量,要利用K均值聚类算法再次分析训练数据。
K均值聚类算法,随机选择k个目标作为最初的聚类中心,之后对所有目标和聚类中心的距离进行计算,并且调配给最近的聚类中心,调节聚类中心的具体位置后重复进行以上过程。在K均值聚类算法中,聚类的准确度主要与距离的计算方法有关,传统类型的K均值算法采用的距离为欧式距离,而若是在车辆检测网络中应用欧式距离,较大的框会比较小的框出现更多错误的情况,所以应用了重合度(loU)作为衡定2个框的位置是否相似的度量,2个框的距离计算如下式所示:
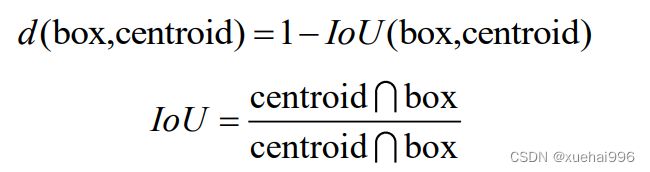
式中box——车辆检测候选框;
centroid——聚类中心所对应的候选框。
经过对车辆检测的数据信息聚类,所示loU候选框之间的交叉比例。loU的示意图如所示。

9.前方车辆车距探测方法
摄像机投影原理
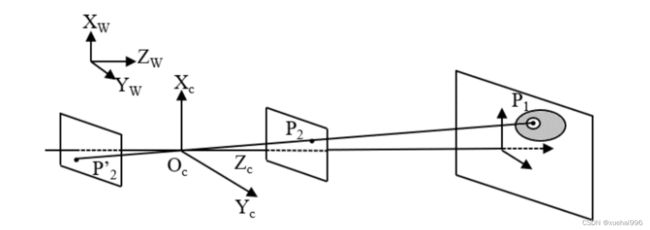
采用摄像机获取视频图像信息时,将三维空间物体投影到摄像机的二维平面上,三维空间点与二维空间点之间可用摄像机模型进行关联,即空间的点P在二维平面的投影点Р都是光心Oc 与Pi点的连线与像平面的交点,如图所示,经过构建数学分布坐标系,描绘一个三维立体分布空间点到二维像平面点相互之间的分布坐标投影交换关系。
常用坐标系与转换关系
坐标系之间的相互转换是单目测距的基础,用来实现三维信息与图像的二维信息之间转换。在摄像机的成像过程中,经过了多个坐标系之间转化:从真实景物所在的三维立体世界坐标系,转换至摄像机坐标系,再投影到图像坐标系,最终转换至像素坐标系。在计算机视觉中,常用坐标系及定义与互相转换关系具体如下[8];
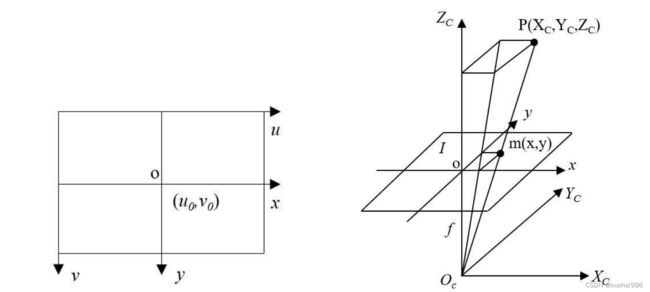
(1)像素坐标系(uv):摄像机收集的图像,被保存为二维数组,该二维数组是由视频图像里的每一个图像像素点为元素组成的。经过像素坐标系,能够了解一个图片有效像素点处于该数组里的详细位置,所以,图片像素是该坐标系的单位。u轴正方向为水平朝右侧分布方向,v轴正方向为竖直朝下分布方向,横纵坐标(u,v)表示图像矩阵中的行列数。
(2)图像坐标系( o-xy ):如图所示,坐标(u,v)中并没有具体的距离单位,无法找到像素在图像中的具体位置,因此用实际的物理单位来建立图像坐标系。图像坐标系可以描绘图片有效像素点在视频图像里的物理位置。x坐标轴正向和y 坐标轴正向和图像像素坐标系中u,v两轴正方向一致。
(3)摄像机坐标系(O-XcYcZ):图展示了摄像机成像几何关系,其中坐标系原点称为摄像机光心Oc,该坐标系以摄像机光轴所在分布方向为Z。轴分布方向,X,Yc轴分布方向和x,y坐标轴分布方向一致。
(4)世界坐标系(Xw,Yw,Zw):摄像机的安装位置不固定,可以通过世界坐标系来更好的表达摄像机与物体在空间中的位置。世界坐标系虽然可以随意定义选用,但在实际应用中,为方便视频图像采集与计算,在选取坐标系时参考物必须确定。
基于P4P的车距计算
PnP问题是指在透视投影环境里具有很多三维和二维匹配点,当预知摄像机内部系数的基础上,计算求解上述三维匹配点在摄像机坐标系的具体位置。许多专家学者对PnP问题的计算求解展开了研究,研究的主流方法包括P3P、直接数学线性转换(DLT)、EPnP、UP、SoftPOSIT等。PnP技术使用图像上特征作用点的二维平面图像坐标,以及特征作用点在靶标坐标系里的三维立体坐标,来获取摄像机坐标系和靶标坐标系彼此的位姿关系[6]。在 PnP算法中,当n<3的时候,PnP问题具有无穷多解[62-63],因此PnP问题的研究内容主要是针对3个特征作用点以上的实际状况。在P3P标定法中,其解并不唯一,一般要应用其他算法判定多解的科学性,以获得正确的解。n取5以上的时候,存在异面点,可以计算得出唯一解,但并不是解析解,并且异面特征作用点靶标制作过程复杂,特征作用点三维立体坐标测量困难。n取4的时候,如果4个特征点共面,可使用坐标系交换矩阵的单位正交性来进行计算,依然能够得到唯一的解析解。
在对检测目标的距离进行运算时,使用摄像机对检测目标进行视频图像采集,由视频图像检测算法获取目标上参考点的坐标数据信息。在摄像机内参标定的过程当中,通过PnP算法可以获取图像坐标与真实距离的相互作用关系,经过此关系由视频图像检测的坐标数据信息计算检测目标的距离。在进行目标参考点的选用时,考虑到车牌是管理部门统一安装的附属件,其尺寸有一致的大小,可以用来作为动态车距探测方法中的参照点。
车辆号牌在摄像机中的投影原理如图所示。图中包含上节中提到的四个坐标系:世界坐标系(Ow-XwYwZw>、摄像机坐标系(Oc-XcY.Ze)、图像坐标系(o-xy〉以及像素坐标系(uv);A、B、C、D分别表示车辆号牌的四个角点,a、b、c、d是车辆号牌四个角点在摄像机成像作用平面上的投影点。

10.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《基于卷积神经网络&深度学习的车距检测系统》
11.参考文献
[1]曾志强,冯鹏鹏,李忠华.影像测量中大视场相机畸变精确校正研究[J].机床与液压.2022,50(2).DOI:10.3969/j.issn.1001-3881.2022.02.005 .
[2]杨清峻,侯忠伟.基于车道线消失点检测的车距测量方法研究[J].汽车工程师.2021,(6).DOI:10.3969/j.issn.1674-6546.2021.06.009 .
[3]乐英,赵志成.基于背景差分法的多运动目标检测与分割[J].中国工程机械学报.2020,(4).
[4]李林,赵凯月,赵晓永,等.基于卷积神经网络的污损遮挡号牌分类[J].计算机科学.2020,(z1).DOI:10.11896/jsjkx.191100089 .
[5]程瑶,赵雷,成珊,等.基于机器视觉的车距检测系统设计[J].计量学报.2020,(1).DOI:10.3969/j.issn.1000-1158.2020.01.03 .
[6]王晓霞.基于立体视觉的安全车距新型识别技术的研究[J].汽车实用技术.2020,(14).DOI:10.16638/j.cnki.1671-7988.2020.14.021 .
[7]罗敏,刘洞波,文浩轩,等.基于背景差分法和帧间差分法的车辆运动目标检测[J].湖南工程学院学报(自然科学版).2019,(4).DOI:10.3969/j.issn.1671-119X.2019.04.011 .
[8]屈治华,邵毅明,邓天民.基于特征光流的多运动目标检测跟踪算法与评价[J].科学技术与工程.2018,(22).
[9]蒋玉亭,那田,汪世财,等.一种基于机器视觉的前方车辆距离检测方法[J].合肥工业大学学报(自然科学版).2018,(4).DOI:10.3969/j.issn.1003-5060.2018.04.016 .
[10]姚春莲,冯胜男,张芳芳,等.利用车牌面积进行车距测量的研究[J].系统仿真学报.2017,(11).DOI:10.16182/j.issn1004731x.joss.201711031 .