redis 常见问题分析
目录
redis 使用分析
一、redis 双写一致性分析
常见方式
1、先写数据库,后写缓存
2、先写数据库,后删缓存
3、先删缓存,再写数据库
4、延迟双删
二、redis 常见异常分析
一、缓存穿透
1、概念
2、解决方案
二、缓存雪崩
1、概念
2、解决方案
redis 使用分析
redis 使用场景: 1、配置文件,数据文件加载 2、web场景中的web页面缓存 3、业务场景中例如短信验证码等 4、可以做消息队列服务器使用,redis 5.0支持
一、redis 双写一致性分析
在数据做出修改时,应当先修改redis数据,还是先修改mysql数据? 在原有集合数据进行增减操作时,无操作顺序要求,redis和mysql的数据是一致的,在数据覆盖时,如果选择了错误的修改顺序,那么,redis和数据库mysql数据结果不一致
常见方式
1、先写数据库,后写缓存
并发,多线程下,可能存在一下问题: 1、数据覆盖操作,如果不按照顺序执行,数据结果不一致 2、数据库更新成功,缓存更新失败,数据结果不一致 可以在此键加上缓存时间,但是缓存生效期间,数据不一致
2、先写数据库,后删缓存
删除数据的原因很简单,VO|BO数据,是来自多表计算得出,属于聚合数据,无法直接更新缓存,只能删除缓存后,得到最新数据。
PO 数据库行级数据,可以直接写入redis VO 视图对象 BO 业务对象
并发,多线程下,可能存在一下问题: 数据库更新成功,缓存删除失败,数据结果不一致
3、先删缓存,再写数据库
LRU(The Least Recently Used,最近最久未使用算法):如果一个数据在最近一段时间没有被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最久没有访问的数据最先被置换(淘汰)。 LFU(Least Frequently Used ,最近最少使用算法):如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。
并发,多线程下,可能存在一下问题: 准备更新数据库时,缓存中的key不存在或已经被LRU和LFU淘汰,已经从旧数据中重新读取,数据结果不一致
4、延迟双删
在修改数据库数据前,需要先删除一次redis:此时是为了保证在数据库数据修改和redis数据被删除的间隔时间内,如有命中,保证此数据也不存在redis中。如果没有这一次删除,当数据库数据已经被修改了,但是还是可以从redis中读出旧数据,导致数据不一致。 第二次删除则是在修改数据库数据后,此时需要再次删除redis中对应数据一次,这一次是为了删除 第一次redis删除和数据库数据修改之间,如果有请求,那么旧数据又会重新缓存到redis中,然而数据在数据库中在接下来就会被修改,如果没有这一次删除,redis中则会存在数据库中旧的数据。 那么第二次为什么需要在数据库修改后延迟一定时间再删除redis呢? 为了等待之前的一次读取数据库,并等待其数据写入到缓存,最后删除这次脏数据,所以是一次数据从数据库中发到服务器+缓存写入的时间
二、redis 常见异常分析
一、缓存穿透
1、概念
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
为了避免缓存穿透其实有很多种解决方案。下面介绍几种。
2、解决方案
(1)布隆过滤器
布隆过滤器是一种数据结构,垃圾网站和正常网站加起来全世界至少也有几十亿个。网警要过滤这些垃圾网站,总不能到数据库里面一个一个去比较吧,这就可以使用布隆过滤器。假设我们存储一亿个垃圾网站地址。
可以先有一亿个二进制比特,然后网警用八个不同的随机数产生器(F1,F2, …,F8) 产生八个信息指纹(f1, f2, …, f8)。接下来用一个随机数产生器把这八个信息指纹映射到 1 到1亿中的八个自然数 g1, g2, …,g8。最后把这八个位置的二进制全部设置为一。过程如下:
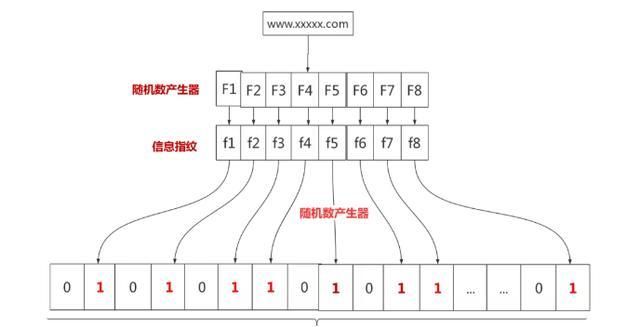
有一天网警查到了一个可疑的网站,想判断一下是否是XX网站,首先将可疑网站通过哈希映射到1亿个比特数组上的8个点。如果8个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。
那这个布隆过滤器是如何解决redis中的缓存穿透呢?很简单首先也是对所有可能查询的参数以hash形式存储,当用户想要查询的时候,使用布隆过滤器发现不在集合中,就直接丢弃,不再对持久层查询。
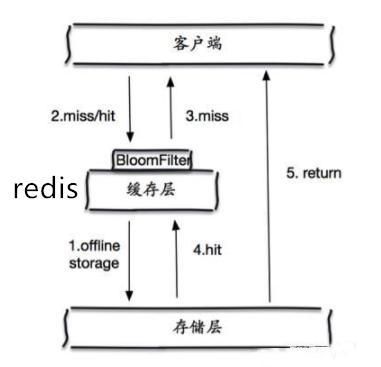
这个形式很简单。
(2)、缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;
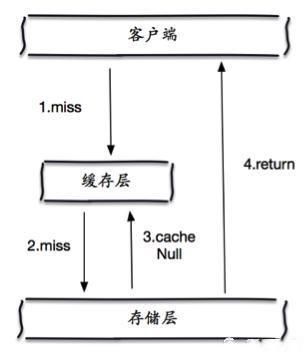
但是这种方法会存在两个问题:
如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
二、缓存雪崩
1、概念
缓存雪崩是指,缓存层出现了错误,不能正常工作了。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
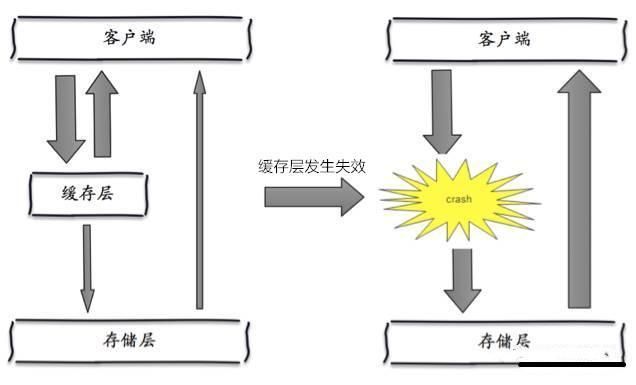
2、解决方案
(1)redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。
(2)限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
(3)数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。