第二课丨学会区分iloc和loc切割数据☀
iloc函数介绍
iloc函数是pandas库中的一个函数,用于根据行列索引选取数据。它的语法是df.iloc[row_index, column_index],其中df是数据框,row_index和column_index分别是行索引和列索引。行索引和列索引可以是整数、切片、布尔数组或者整数数组。
使用iloc函数可以方便地选取数据框中的某些行或列,比如选取前5行和前3列的数据可以写成df.iloc[:5, :3]。此外,iloc函数还支持负数索引,表示从后往前数的位置,比如选取倒数第3行和倒数第2列的数据可以写成df.iloc[-3, -2]。
下面将举例iloc函数的应用。
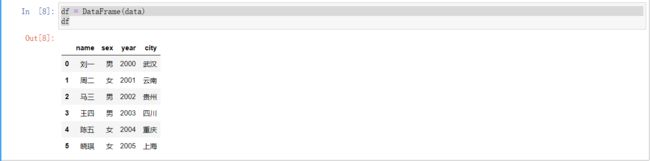
例如:创建一个学生姓名,性别,出生年份,生源地的dataframe对象,首先创建一个字典对象,然后将字典传入给DataFrame()构建函数。
from pandas import Series,DataFrame
import pandas as pd
import numpy as npdata={
'name':['刘一','周二','马三','王四','陈五','晓琪'],
'sex':['男','女','男','男','女','女'],
'year':['2000','2001','2002','2003','2004','2005'],
'city':['武汉','云南','贵州','四川','重庆','上海']
}df = DataFrame(data)
df输出结果为:
df.iloc[a,b],其中df是DataFrame数据结构的数据,a是行索引(如0,1,2,3,...),b是列索引(如name,sex,year,city)。
例如输入df.iloc[1,2],则结果就是:'2001'
df.iloc[:,b],意思是输出b列的所有行,其中‘:’是表示所有的意思。
例如输入df.iloc[:,0],则结果就是:

3.iloc[a:b,c]:取行索引从a到b-1,列索引为c的数据。注意:在a:b中取的值是大于等于a,小于b的值,例如0:2就是取第一,二行的数据。
例如输入df.iloc[0:2,3],则结果就是:

4.iloc[a:b,c:d]:取行索引从a到b-1,列索引从c到d-1的数据。
例如输入df.iloc[0:3,0:2],则结果就是:

5.iloc[a]:取取行索引为a,所有列索引的数据。(注意:5与2的用法和结果不一样)
例如输入df.iloc[0],则结果就是:

loc函数介绍
loc函数和iloc函数有异曲同工之处。
相同之处在于loc和iloc都采用x,y轴在定位数据,或者说它们都在用行和列定位数据。而区别在于loc使用标签,不仅仅是从列的中文上,还有行的索引上。iloc定位数据是依赖于位置的,无论是行还是列,iloc都在用位置作为标识来寻找数据。
不同之处在于当loc和iloc同时表述[1]的时候,loc说的是那个index叫做1的数据;而iloc是从0数起到1。iloc前面的i,所代表的的就是index。
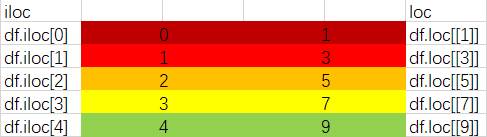
当loc和iloc同时表述[1]的时候,loc说的是那个index叫做1的数据;而iloc是从0数起到1。iloc前面的i,所代表的的就是index。
那么介绍完了iloc和loc函数,现在用波士顿房价为例,切割前十行的数据和最后一行的数据。
波士顿房价的切割实例
代码如下:
#导入sklearn的数据库
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn. metrics import mean_squared_error
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
import pandas as pd
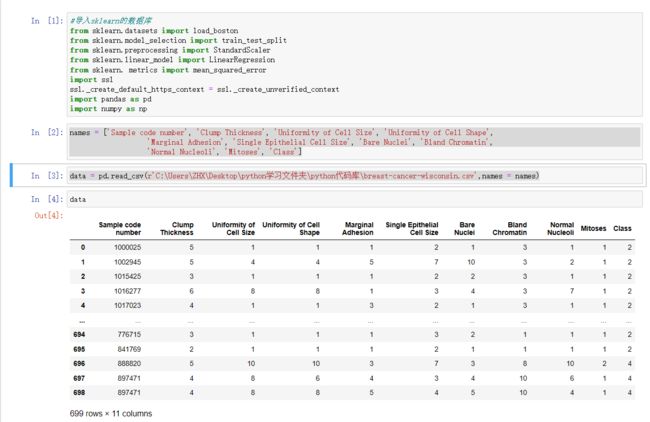
import numpy as npnames = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']data = pd.read_csv(r'C:\Users\ZHX\Desktop\python学习文件夹\python代码库\breast-cancer-wisconsin.csv',names = names)
data'C:\Users\ZHX\Desktop\python学习文件夹\python代码库\breast-cancer-wisconsin.csv'是波士顿房价文件的地址。
输出结果为:
然后我们在进行缺失值处理。
data=data.replace(to_replace='?',value=np.NAN)
data = data.dropna()
data.describe()
最后利用loc或者iloc函数进行切割数据。
data_x =data.loc[:,['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses']]
data_x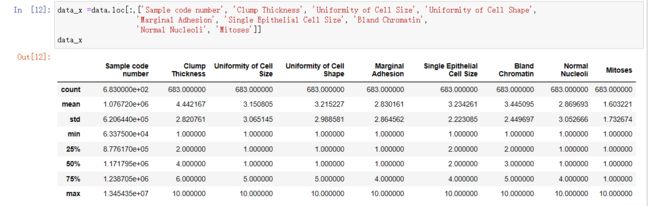
data_y = data.loc[:,['Class']]
data_y
这样就切割出了前十个数据和最后一个数据。
学习loc和iloc函数也是机器学习中基础的部分。在以后的机器学习中会用到loc和iloc函数,学会这俩种切割数据的方法,会使我们在进行切割数据的时候更快捷。