Kubernetes架构及核心部件
文章目录
- 1、Kubernetes集群概述
-
- 1.1、概述
- 1.2、通过声明式API即可
- 2、Kubernetes 集群架构
-
- 2.1、Master 组件
-
- 2.1.1、API Server
- 2.1.2、集群状态存储
- 2.1.3、控制器管理器
- 2.1.4、调度器
- 2.2、Worker Node 组件
-
- 2.2.1、kubelet
- 2.2.2、容器运行时环境
- 2.2.3、kube-proxy
- 2.3、图解架构
- 3、核心扩展部件
-
- 3.1、网络插件
- 3.2、CoreDNS
- 3.3、Dashboard
- 3.4、容器资源监控系统
- 3.5、集群日志系统
- 3.6、Ingress Controller
- 4、小小疑问
-
- 4.1、声明式API和命令式API
- 4.2、区分kubectl和kubelet
- 参考
1、Kubernetes集群概述
1.1、概述
Kubernetes 是一个容器编排平台,它使用共享网络将多个主机(物理服务器或虚拟机)构建成集群。分为 Master Node(主节点)和Worker Node(工作节点),Master负责管理整个集群,Worker 负责接收请求并以Pod(容器集合)形式运行工作负载。下图为Kubernetes 集群工作模式示意图。
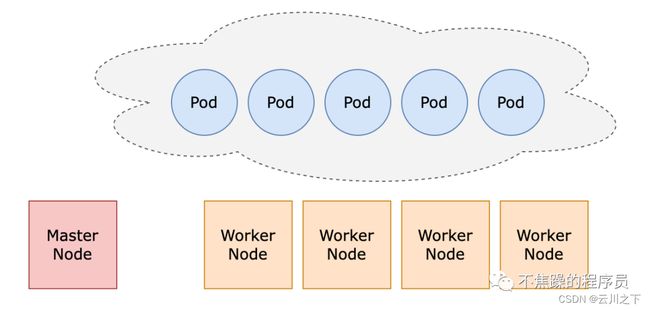
Master是集群的网关和中枢,负责为客户端提供API接口调用、确保各资源对象不断地接近用户期望的状态、并以最优的方式调度Pod到指定Node,以及编排其他组件之间的通信等任务,它是客户端访问集群的唯一入口。生产环境通常部署多个Master,为了冗余和负载均衡。
Worker Node负责接收来自 Master 下发的指令并相应创建或销毁Pod 对象,以及路由、流量转发等任务。在生产环境中,随着微服务的增多或者业务应用的扩容,Worker会随之增多。
概括来说,Kubernetes将所有工作节点的资源(CPU、磁盘、内存、网络等)集合在一起形成了一台更加强大的“服务器”,通过Master上的API接口暴露集群的计算和存储接口,再由 Master通过调度算法将客户端请求的工作负载指派至特定的Node上,并且Master 会自动处理因Worker Node的添加、故障、或移除等变动对 Pod 的影响。
Kubernetes是构建在底层主机集群之上的“云原生应用操作系统”,而容器是运行在其上的进程。
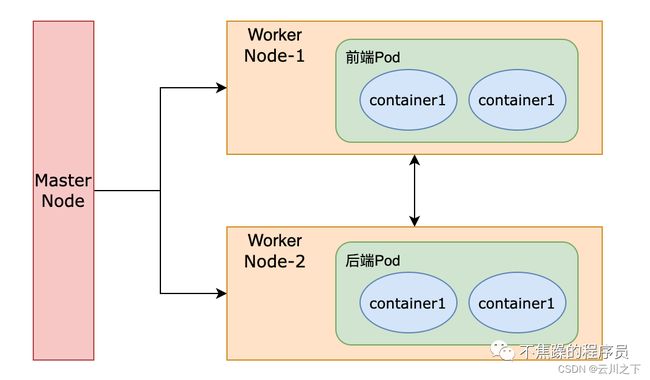
Kubernetes 中每个对象都使用 “名称”作为其唯一标识符,出于名称的隔离和复用、资源隔离的目的,使用“Namespace” 作为作用域。
1.2、通过声明式API即可
在开发云原生应用时,主要使用声明式API,这种方式简单易用,程序员朋友可以更好地集中精力开发业务。
在运行应用时,用户只需要通过 API声明业务应用的最终状态(例如为 Nginx 应用运行 6个实例等),Kubernetes 便能完成后续的所有任务,包括应用本身的运行实例数量、路由策略、访问策略以及存储等。
以下为某个声明式yaml的示例,Kubernetes 也支持使用命令行工具 kubectl 提交请求。
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: test
labels:
app: busybox
spec:
containers:
- name: busybox
image: busybox
2、Kubernetes 集群架构
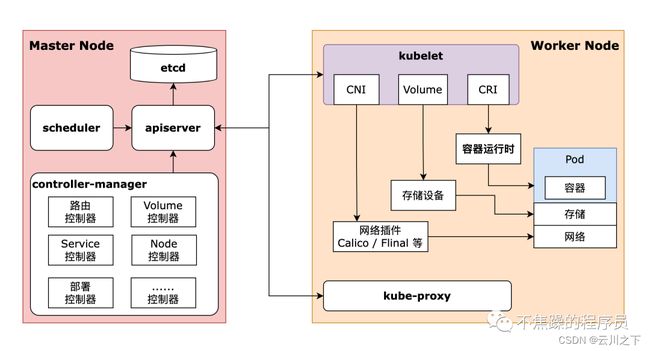
Kubernetes 属于Server-Client架构,Master Node主要由API Server(kube-apiserver)、 Controller-Manager(Kube-controller-manager)和 Scheduler(kube-scheduler)这3个组件,以及一个用于存储集群状态的 etcd 存储服务组成,它们构成整个集群的控制平面;
而Worker Node则主要包含 kubelet、kube-proxy及容器运行时(以前Docker是常用的实现)3个组件,它们承载运行各类应用容器。各组件如下图所示:
2.1、Master 组件
Master是集群的大脑,它维护了Kubernetes 的所有对象记录,负责管理对象状态、并响应集群中各种资源对象的管理操作,以及确保各资源对象的 实际状态 与 所需状态 相匹配。控制平面各组件及其主要功能如下:
2.1.1、API Server
API Server 是Kubernetes 控制平面的前端,支持不同类型应用的生命周期编排,包括部署、缩放和滚动更新等。它还是整个集群的网关接口,用于接收、校验以及响应所有的REST请求,并将结果状态存储到(etcd)中。
2.1.2、集群状态存储
Kubernetes集群的所有状态信息都需要存储于etcd 中。etcd 是分布式键值存储,可用于服务发现、共享配置以及一致性保障 (如数据库主节点选择、分布式等)。
etcd还为其存储的数据提供了监听 (warch)机制,用于监听和推送变更。API Server是Kubernetes集群中唯一能够与etcd通信的组件,它封装了这种监听机制,并借此同其他各组件高效协同。这一点类似于多个应用服务器借助zookeeper协同。
2.1.3、控制器管理器
控制器负责实现客户端通过 API Server 提交的请求,它驱动API 对象的当前状态逼近期望状态。Kubernetes 提供了驱动 Node、Pod 、 Server、Endpoint、ServiceAccount 和 Token 等数十种类型对象的控制器。
2.1.4、调度器
Kubernetes 系统上的调度是指为 API Server 接收到的每一个Pod 创建请求,并在集群中为其匹配出一个最佳工作节点。kube-scheduler 是默认调度器程序,它调度时的考量因素包括:硬件、软件与策略约束、亲和与反亲和、污点等特征。
2.2、Worker Node 组件
Worker Node 组件是集群的体力劳动者,为了保证有足够的资源运行成百上千个容器化应用,一个集群通常会有多个 Worker Node 。每个Node 会定期向 Master 报告自身的状态变动,并接受 Master 的管理。
2.2.1、kubelet
kubelet 是 Kubernetes 中最重要的组件之一,是运行于每个 Node之上的“节点代理”服务,负责接收并执行 Master 发来的指令,以及管理当前 Node 上 Pod 对象的容器等任务。它支持从 API Server 接收 Pod 资源定义,并通过 容器运行时 去创建、启动和监视容器。
kubelet 会持续监视当前节点上各Pod 的健康状态,并在任何 Pod 出现问题时将其重建。同时也会及时跟Master通信,将自身情况上报于Master。
2.2.2、容器运行时环境
Pod 是一组容器集合,真正负责运行容器的是底层的 容器运行时 。kubelet 通过 CRI(容器运行时接口)可支持多种类型的 OCI 容器运行时,例如 docker、containerd、CRI-O、runC、Kata等。
2.2.3、kube-proxy
kube-proxy 是需要运行于集群中每个节点之上的服务进程,它把 API Server 上的Service 资源对象转换为当前节点上的 iptables 或(与)ipvs 规则,这些规则 能够将那些 发往Service 对象 ClusterIP 的流量 分发至它后端的 Pod 端点之上。
kube-proxy是 Kubernetes的核心网络组件,它本质上更像是Pod 的代理及负载均衡器,负责确保集群中 Node、Service 和Pod 对象之间的通信。
2.3、图解架构
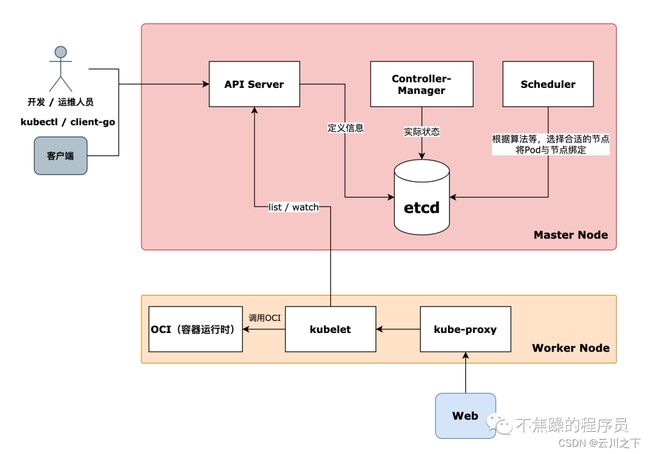
如上图所示:
- 开发/运维人员可以通过kubectl命令,或者使用由Kubernetes提供的客户端SDK,调用apiserver提供的接口。
- 调用apiserver接口后,Kubernetes将资源定义信息存入到etcd数据库,资源定义信息就是期望状态。
- 收到定义信息后,controller-manager会努力将期望状态变为实际状态,并且会把实际状态写入到etcd数据库中。
- 如果定义信息没有被scheduler模块调度,那么实际状态就是待调度,当scheduler把pod调度到用户指定的节点时,这时实际状态则就是真实的Pod运行状态了。
- 当scheduler把 “pod应该调度到哪个节点” 的信息写入到etcd数据库时,这时节点上的kubelet会利用list-watch机制收到这个信息,然后kubelet根据收到的信息运行pod的定义信息,并且把pod运行起来。
- 每个节点上都会有kube-proxy服务,包括master节点,利用kube-proxy模块,可以作为集群的流量入口。
- 每个节点必须安装好容器运行时(比如docker、containerd),因为最终把容器进程跑起来的还是要靠 容器运行时 。
3、核心扩展部件
常用的核心扩展部件包括如下几个:
3.1、网络插件
网络插件是必要部件,常用的有Flannel、Calico等。我主要使用Calico ,云厂商一般是结合VPC有自己的一套实现。
3.2、CoreDNS
Kubernetes使用DNS应用程序实现名称解析和服务发现功能,它自1.11 版本起默认使用 CoreDNS。之前的版本中用到的是kube-dns。
3.3、Dashboard
一套WebUI,用于可视化 Kubernetes集群。Dashboard可用于获取集群中资源对象的详细信息,例如集群中的 Node、Namespace、 Volume、ClusterRole 和Job 等,也可以创建或者修改这些资源对象。
3.4、容器资源监控系统
监控系统是分布式应用的重要基础设施,Kubernetes常用的指标监控部件有Metrics-Server、Prometheus 等。
3.5、集群日志系统
日志系统是构建可观测分布式应用的基础设施,有助于帮助开发人员发现和定位问题。Kubernetes 常用的日志系统是由ElasticSearch、Fluentd 和 Kibana(EFK) 组合提供的解决方案,或者使用ELK等方案。
3.6、Ingress Controller
Ingress资源是 Kubernetes 将集群外部 HTTP流量引入到集群内部的资源类型,它仅用于控制流量的规则和配置的集合,它不能进行“流量穿透”,要通过Ingress控制器发挥作用。常用的Ingress控制器有Nginx等。
在以上这些附件中,CoreDNS、监控系统、日志系统和 Ingress 控制器,这种基础支撑类服务一般安装在集群内部。而Dashboard是提高用户效率和体验的可视化工具,一般在集群外部独立安装。
4、小小疑问
4.1、声明式API和命令式API
一个注重结果,一个注重过程。
声明式(declarative)编程:着重于最终结果,如何达成结果则要依赖于给定语言的基础组件能力,程序员只需要指定做什么而非如何去做;声明式编程常用于数据库和配置管理软件中,关系型数据库的SQL语言便是最典型的代表之一。
命令式(imperative)编程:称为过程式编程更合适,它需要由程序员指定做事情的具体步骤,更注重如何达成结果的过程。
4.2、区分kubectl和kubelet
初学者经常分不清kubectl和kubelet的区别,通过上文可以知道:
kubectl是一个Kubernetes轻量级的客户端,用于调用Api-Server的接口,一般安装在Master节点。
kubelet是安装在每个Node节点上的代理,用于与Master高效通信,以及完成Master下发的任务、以及上报任务和自身的情况。
参考
Kubernetes架构及核心部件