Elasticsearch 8.9 flush刷新缓存中的数据到磁盘源码
- 一、相关API的handler
-
- 1、接收HTTP请求的hander
- 2、每一个数据节点(node)执行分片刷新的action是TransportShardFlushAction
- 二、对indexShard执行刷新请求
-
- 1、首先获取读锁,再获取刷新锁,如果获取不到根据参数决定是否直接返回还是等待
- 2、在刷新之后translog需要滚动生成新的,这样不会影响正在进行的写入和删除时方便
- 3、把IndexWriter中的数据持久化磁盘
- 4、开始处理translog.log
-
- (1) 首先把内存中的translog全部写入磁盘
- (2) 删除磁盘中的对应的translog文件
- 5、更新最后刷新时间和刷新最后提交的段信息
- 三、通过源码得到一些结论
下面的图来自ElasticSearch——刷盘原理流程,这篇文章主要讲的是人工通过
flush命令把批量写入内存segment的数据刷新进磁盘,不涉及到在translog.log和Lucene的数据结构。
通过这个流程知道ES如何把数据刷新进磁盘的,主要是下图的下半部分中fsync部分
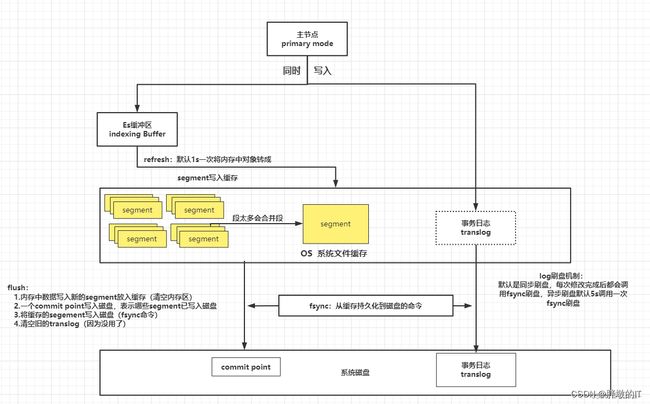
图片中主节点同时写入Es缓冲区和translog部分,请看Elasticsearch 8.9 Bulk批量给索引增加数据源码
图片中refresh部分,请看Elasticsearch 8.9 refresh刷Es缓冲区的数据到Lucene,更新segemnt,使数据可见
一、相关API的handler
在ActionModule.java中
registerHandler.accept(new RestFlushAction());
actions.register(FlushAction.INSTANCE, TransportFlushAction.class);
actions.register(TransportShardFlushAction.TYPE, TransportShardFlushAction.class);
1、接收HTTP请求的hander
public class RestFlushAction extends BaseRestHandler {
@Override
public List<Route> routes() {
return List.of(
new Route(GET, "/_flush"),
new Route(POST, "/_flush"),
new Route(GET, "/{index}/_flush"),
new Route(POST, "/{index}/_flush")
);
}
@Override
public String getName() {
return "flush_action";
}
@Override
public RestChannelConsumer prepareRequest(final RestRequest request, final NodeClient client) throws IOException {
FlushRequest flushRequest = new FlushRequest(Strings.splitStringByCommaToArray(request.param("index")));
flushRequest.indicesOptions(IndicesOptions.fromRequest(request, flushRequest.indicesOptions()));
flushRequest.force(request.paramAsBoolean("force", flushRequest.force()));
flushRequest.waitIfOngoing(request.paramAsBoolean("wait_if_ongoing", flushRequest.waitIfOngoing()));
return channel -> client.admin().indices().flush(flushRequest, new RestToXContentListener<>(channel));
}
}
上面会执行下面这个,至于怎么到这里的,可以看Elasticsearch 8.9 Master节点处理请求源码
/**
* Flush Action.
*/
public class TransportFlushAction extends TransportBroadcastReplicationAction<
FlushRequest,
FlushResponse,
ShardFlushRequest,
ReplicationResponse> {
@Inject
public TransportFlushAction(
ClusterService clusterService,
TransportService transportService,
NodeClient client,
ActionFilters actionFilters,
IndexNameExpressionResolver indexNameExpressionResolver
) {
super(
FlushAction.NAME,
FlushRequest::new,
clusterService,
transportService,
client,
actionFilters,
indexNameExpressionResolver,
TransportShardFlushAction.TYPE, //注意这个
ThreadPool.Names.FLUSH
);
}
//省略代码
}
这里需要注意上面的TransportShardFlushAction.TYPE
这里看一下它的父类TransportBroadcastReplicationAction
public abstract class TransportBroadcastReplicationAction<
Request extends BroadcastRequest<Request>,
Response extends BaseBroadcastResponse,
ShardRequest extends ReplicationRequest<ShardRequest>,
ShardResponse extends ReplicationResponse> extends HandledTransportAction<Request, Response> {
private final ActionType<ShardResponse> replicatedBroadcastShardAction;
public TransportBroadcastReplicationAction(
String name,
Writeable.Reader<Request> requestReader,
ClusterService clusterService,
TransportService transportService,
NodeClient client,
ActionFilters actionFilters,
IndexNameExpressionResolver indexNameExpressionResolver,
ActionType<ShardResponse> replicatedBroadcastShardAction,
String executor
) {
//省略代码
//这里即上面的TransportShardFlushAction.TYPE
this.replicatedBroadcastShardAction = replicatedBroadcastShardAction;
}
@Override
protected void doExecute(Task task, Request request, ActionListener<Response> listener) {
clusterService.threadPool().executor(executor).execute(ActionRunnable.wrap(listener, createAsyncAction(task, request)));
}
private CheckedConsumer<ActionListener<Response>, Exception> createAsyncAction(Task task, Request request) {
return new CheckedConsumer<ActionListener<Response>, Exception>() {
//省略代码
@Override
public void accept(ActionListener<Response> listener) {
final ClusterState clusterState = clusterService.state();
final List<ShardId> shards = shards(request, clusterState);
final Map<String, IndexMetadata> indexMetadataByName = clusterState.getMetadata().indices();
//遍历分片
try (var refs = new RefCountingRunnable(() -> finish(listener))) {
for (final ShardId shardId : shards) {
// NB This sends O(#shards) requests in a tight loop; TODO add some throttling here?
shardExecute(
task,
request,
shardId,
ActionListener.releaseAfter(new ReplicationResponseActionListener(shardId, indexMetadataByName), refs.acquire())
);
}
}
}
//省略代码
};
}
protected void shardExecute(Task task, Request request, ShardId shardId, ActionListener<ShardResponse> shardActionListener) {
assert Transports.assertNotTransportThread("may hit all the shards");
ShardRequest shardRequest = newShardRequest(request, shardId);
shardRequest.setParentTask(clusterService.localNode().getId(), task.getId());
//通过执行replicatedBroadcastShardAction,即TransportShardFlushAction.class来实现分片的刷新
client.executeLocally(replicatedBroadcastShardAction, shardRequest, shardActionListener);
}
}
2、每一个数据节点(node)执行分片刷新的action是TransportShardFlushAction
public class TransportShardFlushAction extends TransportReplicationAction<ShardFlushRequest, ShardFlushRequest, ReplicationResponse> {
//主分片执行刷新
@Override
protected void shardOperationOnPrimary(
org.elasticsearch.action.admin.indices.flush.ShardFlushRequest shardRequest,
IndexShard primary,
ActionListener<PrimaryResult<ShardFlushRequest, ReplicationResponse>> listener
) {
ActionListener.completeWith(listener, () -> {
primary.flush(shardRequest.getRequest());
logger.trace("{} flush request executed on primary", primary.shardId());
return new PrimaryResult<>(shardRequest, new ReplicationResponse());
});
}
//副本分片执行刷新
@Override
protected void shardOperationOnReplica(ShardFlushRequest request, IndexShard replica, ActionListener<ReplicaResult> listener) {
ActionListener.completeWith(listener, () -> {
replica.flush(request.getRequest());
logger.trace("{} flush request executed on replica", replica.shardId());
return new ReplicaResult();
});
}
}
其中shardOperationOnReplica 是TransportReplicationAction下的onResponse方法触发
public abstract class TransportReplicationAction<
Request extends ReplicationRequest<Request>,
ReplicaRequest extends ReplicationRequest<ReplicaRequest>,
Response extends ReplicationResponse> extends TransportAction<Request, Response> {
//省略代码
private final class AsyncReplicaAction extends AbstractRunnable implements ActionListener<Releasable> {
@Override
public void onResponse(Releasable releasable) {
assert replica.getActiveOperationsCount() != 0 : "must perform shard operation under a permit";
try {
shardOperationOnReplica(
replicaRequest.getRequest(),
replica,
ActionListener.wrap((replicaResult) -> replicaResult.runPostReplicaActions(ActionListener.wrap(r -> {
final ReplicaResponse response = new ReplicaResponse(
replica.getLocalCheckpoint(),
replica.getLastSyncedGlobalCheckpoint()
);
releasable.close(); // release shard operation lock before responding to caller
if (logger.isTraceEnabled()) {
logger.trace(
"action [{}] completed on shard [{}] for request [{}]",
transportReplicaAction,
replicaRequest.getRequest().shardId(),
replicaRequest.getRequest()
);
}
setPhase(task, "finished");
onCompletionListener.onResponse(response);
}, e -> {
Releasables.closeWhileHandlingException(releasable); // release shard operation lock before responding to caller
responseWithFailure(e);
})), e -> {
Releasables.closeWhileHandlingException(releasable); // release shard operation lock before responding to caller
AsyncReplicaAction.this.onFailure(e);
})
);
// TODO: Evaluate if we still need to catch this exception
} catch (Exception e) {
Releasables.closeWhileHandlingException(releasable); // release shard operation lock before responding to caller
AsyncReplicaAction.this.onFailure(e);
}
}
}
}
二、对indexShard执行刷新请求
/**
* 对引擎执行给定的刷新请求。
*
* @param request the flush request
* @return false if waitIfOngoing==false and an ongoing request is detected, else true.
* If false is returned, no flush happened.
*/
public boolean flush(FlushRequest request) {
final boolean waitIfOngoing = request.waitIfOngoing();
final boolean force = request.force();
logger.trace("flush with {}", request);
verifyNotClosed();
final long time = System.nanoTime();
// TODO: Transition this method to async to support async flush 将此方法转换为异步以支持异步刷新
PlainActionFuture<Engine.FlushResult> future = PlainActionFuture.newFuture();
getEngine().flush(force, waitIfOngoing, future);
Engine.FlushResult flushResult = future.actionGet();
flushMetric.inc(System.nanoTime() - time);
return flushResult.flushPerformed();
}
/**
刷新引擎的状态,包括事务日志、清除内存以及将 Lucene 索引中的文档写入磁盘。此方法将在调用线程上同步刷新。但是,根据引擎实现的不同,在触发侦听器之前,无法保证完全的耐用性。
*
* @param force 如果为 true则即使不需要提交任何更改,也会执行 Lucene 提交
* @param waitIfOngoing 如果为 true,则此调用将阻止,直到所有当前正在运行的刷新都完成。否则,此调用将返回而不阻塞。
* @param listener 在达到完全耐久性后通知。如果 waitIfOngoing==false 并且检测到正在进行的请求,则不会发生刷新,侦听器将完成,并带有指示没有刷新和未知生成的标记
*/
public abstract void flush(boolean force, boolean waitIfOngoing, ActionListener<FlushResult> listener) throws EngineException;
其中实际调用的是Engine的子类InternalEngine
1、首先获取读锁,再获取刷新锁,如果获取不到根据参数决定是否直接返回还是等待
@Override
public void flush(boolean force, boolean waitIfOngoing, ActionListener<FlushResult> listener) throws EngineException {
//省略代码
final long generation;
//获取读锁(readLock.acquire())
try (ReleasableLock lock = readLock.acquire()) {
ensureOpen();
//尝试获取刷新锁(flushLock)
if (flushLock.tryLock() == false) {
//如果无法立即获取到锁,则根据 waitIfOngoing 的值决定是等待刷新完成还是立即返回。
// if we can't get the lock right away we block if needed otherwise barf
if (waitIfOngoing == false) {
logger.trace("detected an in-flight flush, not blocking to wait for it's completion");
listener.onResponse(FlushResult.NO_FLUSH);
return;
}
logger.trace("waiting for in-flight flush to finish");
//如果成功获取到刷新锁
flushLock.lock();
logger.trace("acquired flush lock after blocking");
} else {
logger.trace("acquired flush lock immediately");
}
try {
//仅当下面这四种情况才进行刷新操作
//(1) Lucene 有未提交的文档,
//或 (2) 被调用方强制执行,
//或 (3) 新创建的提交指向不同的 translog 生成(可以释放 translog),
//或 (4) 上次提交中的本地检查点信息过时
boolean hasUncommittedChanges = hasUncommittedChanges(); 检查是否有未提交的文档变更(hasUncommittedChanges())
if (hasUncommittedChanges
|| force //是否需要强制刷新(force)
|| shouldPeriodicallyFlush() //是否需要定期刷新(shouldPeriodicallyFlush())
//或者本地检查点信息是否过时
|| getProcessedLocalCheckpoint() > Long.parseLong(
lastCommittedSegmentInfos.userData.get(SequenceNumbers.LOCAL_CHECKPOINT_KEY)
)) {
//确保可以执行刷新(ensureCanFlush())
ensureCanFlush();
//获取最后一个写入的事务日志位置(getTranslogLastWriteLocation())
Translog.Location commitLocation = getTranslogLastWriteLocation();
try {
//如果当前 translog 不为空,则将其滚动到新生成。这不会提交 translog。这样正在进行的写入和刷新磁盘用的translog就不冲突
translog.rollGeneration();
logger.trace("starting commit for flush; commitTranslog=true");
long lastFlushTimestamp = relativeTimeInNanosSupplier.getAsLong();
//记录即将生成的区段,以便实时版本地图存档记录在刷新时转到存档的文档 ID 的正确区段生成。
// 否则,如果在提交 IndexWriter 后立即对新文档进行索引更新,并且刷新将它们移动到存档中,则一旦我们在搜索分片上看到该段生成,
// 我们就会将它们从存档中清除,但这些更改不包括在提交中,因为它们发生在提交之后
//提交索引写入器
preCommitSegmentGeneration.set(lastCommittedSegmentInfos.getGeneration() + 1);
//执行刷新操作
commitIndexWriter(indexWriter, translog);
logger.trace("finished commit for flush");
//我们需要刷新以清除旧版本值
refresh("version_table_flush", SearcherScope.INTERNAL, true);
translog.trimUnreferencedReaders();
//更新最后一次刷新的时间戳
this.lastFlushTimestamp = lastFlushTimestamp;
} catch (AlreadyClosedException e) {
failOnTragicEvent(e);
throw e;
} catch (Exception e) {
throw new FlushFailedEngineException(shardId, e);
}
//刷新最后提交的段信息(refreshLastCommittedSegmentInfos()
refreshLastCommittedSegmentInfos();
//获取刷新后的段信息
generation = lastCommittedSegmentInfos.getGeneration();
//调用刷新监听器的 afterFlush 方法
flushListener.afterFlush(generation, commitLocation);
} else {
//如果不满足刷新条件,则直接获取最后提交的段信息的代数。
generation = lastCommittedSegmentInfos.getGeneration();
}
} catch (FlushFailedEngineException ex) {
maybeFailEngine("flush", ex);
listener.onFailure(ex);
return;
} catch (Exception e) {
listener.onFailure(e);
return;
} finally {
//释放刷新锁
flushLock.unlock();
logger.trace("released flush lock");
}
}
if (engineConfig.isEnableGcDeletes()) {
pruneDeletedTombstones();
}
//等待提交的持久性完成,并通过回调函数返回刷新结果
waitForCommitDurability(generation, listener.map(v -> new FlushResult(true, generation)));
}
2、在刷新之后translog需要滚动生成新的,这样不会影响正在进行的写入和删除时方便
/*
*如果当前 translog 生成不为空,则将其滚动到新生成。这不会提交 translog。
* @throws IOException if an I/O exception occurred during any file operations
*/
public void rollGeneration() throws IOException {
syncBeforeRollGeneration();
//检查当前操作数是否为0,并且主要期限与当前的主要期限相同。如果满足条件,则直接返回,不执行后续操作
if (current.totalOperations() == 0 && primaryTermSupplier.getAsLong() == current.getPrimaryTerm()) {
return;
}
//使用writeLock.acquire()获取写锁,确保代码块中的操作是以独占方式进行的。
try (Releasable ignored = writeLock.acquire()) {
//调用ensureOpen()方法确保资源处于打开状态
ensureOpen();
try {
//将当前的Translog关闭并转换为TranslogReader对象。
final TranslogReader reader = current.closeIntoReader();
//,将reader添加到readers集合中
readers.add(reader);
//使用断言确认检查点文件中的generation与当前的generation相匹配。
assert Checkpoint.read(location.resolve(CHECKPOINT_FILE_NAME)).generation == current.getGeneration();
//将检查点文件复制到指定的位置
copyCheckpointTo(location.resolve(getCommitCheckpointFileName(current.getGeneration())));
//创建一个新的Translog文件,并更新检查点数据
current = createWriter(current.getGeneration() + 1);
logger.trace("current translog set to [{}]", current.getGeneration());
} catch (final Exception e) {
tragedy.setTragicException(e);
closeOnTragicEvent(e);
throw e;
}
}
}
3、把IndexWriter中的数据持久化磁盘
/**
* 把索引写入器(IndexWriter)数据持久化到磁盘,
* 用到了lucene 索引与 translog 关联的 translog uuid,这样会把这个uuid及之前的数据写入到磁盘
* @param writer the index writer to commit
* @param translog the translog
*/
protected void commitIndexWriter(final IndexWriter writer, final Translog translog) throws IOException {
//确保可以执行刷新操作
ensureCanFlush();
try {
//获取本地检查点(localCheckpoint)
final long localCheckpoint = localCheckpointTracker.getProcessedCheckpoint();
//设置一个回调函数,用来设置索引写入器的提交数据,
writer.setLiveCommitData(() -> {
/*
* 上面捕获的用户数据(例如本地检查点)包含在 Lucene 刷新段之前必须评估的数据,包括本地检查点和其他值。
* 最大序列号是不同的,我们永远不希望最大序列号小于进入 Lucene 提交的最后一个序列号,否则在从此提交点恢复并随后将新文档写入索引时,我们将面临对两个不同文档重复使用序列号的风险。
* 由于我们只知道哪些 Lucene 文档在 {@link IndexWritercommit()} 调用刷新所有文档后进入最终提交,因此我们将最大序列号的计算推迟到提交数据迭代器的调用时间(在所有文档刷新到 Lucene 之后发生)。
*/
//创建一个包含提交数据的映射(commitData),包括事务日志的UUID、本地检查点、最大序列号等信息。
final Map<String, String> commitData = Maps.newMapWithExpectedSize(8);
// translog.getTranslogUUID()返回用于将 lucene 索引与 translog 关联的 translog uuid。
commitData.put(Translog.TRANSLOG_UUID_KEY, translog.getTranslogUUID());
commitData.put(SequenceNumbers.LOCAL_CHECKPOINT_KEY, Long.toString(localCheckpoint));
commitData.put(SequenceNumbers.MAX_SEQ_NO, Long.toString(localCheckpointTracker.getMaxSeqNo()));
commitData.put(MAX_UNSAFE_AUTO_ID_TIMESTAMP_COMMIT_ID, Long.toString(maxUnsafeAutoIdTimestamp.get()));
commitData.put(HISTORY_UUID_KEY, historyUUID);
final String currentForceMergeUUID = forceMergeUUID;
if (currentForceMergeUUID != null) {
commitData.put(FORCE_MERGE_UUID_KEY, currentForceMergeUUID);
}
commitData.put(Engine.MIN_RETAINED_SEQNO, Long.toString(softDeletesPolicy.getMinRetainedSeqNo()));
commitData.put(ES_VERSION, Version.CURRENT.toString());
logger.trace("committing writer with commit data [{}]", commitData);
//将提交数据返回给索引写入器
return commitData.entrySet().iterator();
});
//禁用大合并后的定期刷新(shouldPeriodicallyFlushAfterBigMerge)
shouldPeriodicallyFlushAfterBigMerge.set(false);
//提交索引写入器,将数据写入磁盘
writer.commit();
} catch (final Exception ex) {
try {
failEngine("lucene commit failed", ex);
} catch (final Exception inner) {
ex.addSuppressed(inner);
}
throw ex;
} catch (final AssertionError e) {
//省略代码
}
}
在Bulk批量给索引增加数据源码 中,后面的文档添加到Lucene的这个方法indexIntoLucene 里面就是写入了indexWriter 这里commit会直接写入到磁盘
其中indexWriter的全路径org.apache.lucene.index.IndexWriter;
4、开始处理translog.log
在上面rollGeneration()方法就把最后一个translog放入了readers,也为删除做准备
//Translog 列表保证按 Translog 生成的顺序排列,
private final List<TranslogReader> readers = new ArrayList<>();
/**
* Trims unreferenced translog generations by asking {@link TranslogDeletionPolicy} for the minimum
* required generation
* 通过要求 {@link TranslogDeletionPolicy} 提供所需的最小生成来修剪未引用的 translog 生成
*/
public void trimUnreferencedReaders() throws IOException {
//首先获取读取锁,并检查是否有可以修剪的读取器
try (ReleasableLock ignored = readLock.acquire()) {
//如果已关闭或者最小引用的代数与最小文件代数相同,则不进行修剪操作。
if (closed.get()) {
// 我们可能会因一些悲惨事件而关闭,不要删除任何内容
return;
}
if (getMinReferencedGen() == getMinFileGeneration()) {
return;
}
}
// 将大部分数据写入磁盘,以减少写入锁的持有时间
sync();
//获取写入锁,并再次检查是否已关闭或者最小引用的代数与最小文件代数相同。
try (ReleasableLock ignored = writeLock.acquire()) {
if (closed.get()) {
// we're shutdown potentially on some tragic event, don't delete anything
//我们可能会因一些悲惨事件而关闭,不要删除任何内容
return;
}
final long minReferencedGen = getMinReferencedGen();
//代码遍历读取器列表,
for (Iterator<TranslogReader> iterator = readers.iterator(); iterator.hasNext();) {
TranslogReader reader = iterator.next();
if (reader.getGeneration() >= minReferencedGen) {
break;
}
//删除不再被引用的读取器
iterator.remove();
IOUtils.closeWhileHandlingException(reader);
//translogPath是translog
final Path translogPath = reader.path();
logger.trace("delete translog file [{}], not referenced and not current anymore", translogPath);
//打开translog时使用检查点来了解应从哪些文件中恢复。现在,我们更新检查点以忽略要删除的文件。
// 请注意,recoverFromFiles 中有一个规定,允许我们同步检查点但在删除文件之前崩溃的情况。立即同步,以确保最多有一个未引用的生成。
//将所有缓冲的运算写入磁盘和 fsync 文件。current是TranslogWriter
current.sync();
//并删除相关文件
deleteReaderFiles(reader);
}
assert readers.isEmpty() == false || current.generation == minReferencedGen
: "all readers were cleaned but the minReferenceGen ["
+ minReferencedGen
+ "] is not the current writer's gen ["
+ current.generation
+ "]";
} catch (final Exception ex) {
closeOnTragicEvent(ex);
throw ex;
}
}
(1) 首先把内存中的translog全部写入磁盘
/**
* Sync's the translog.
*/
public void sync() throws IOException {
try (ReleasableLock lock = readLock.acquire()) {
if (closed.get() == false) {
current.sync();
}
} catch (final Exception ex) {
closeOnTragicEvent(ex);
throw ex;
}
}
/**
*将所有缓冲的运算写入磁盘和 fsync 文件。
* 同步过程中的任何异常都将被解释为悲剧性异常,写入器将在引发异常之前关闭。
*/
public void sync() throws IOException {
//这里一个是最大,一个是-2L,直接就是强制把translog从内存中刷进磁盘
syncUpTo(Long.MAX_VALUE, SequenceNumbers.UNASSIGNED_SEQ_NO);
}
/**
*将数据同步到指定的偏移量和全局检查点,确保数据的持久性。如果满足一定条件,会执行同步操作
* @return true if this call caused an actual sync operation
*/
final boolean syncUpTo(long offset, long globalCheckpointToPersist) throws IOException {
//检查lastSyncedCheckpoint的偏移量和全局检查点是否小于指定的偏移量和全局检查点,并且需要进行同步操作
if ((lastSyncedCheckpoint.offset < offset || lastSyncedCheckpoint.globalCheckpoint < globalCheckpointToPersist) && syncNeeded()) {
//省略代码
//获取一个同步锁
synchronized (syncLock) { // only one sync/checkpoint should happen concurrently but we wait
if ((lastSyncedCheckpoint.offset < offset || lastSyncedCheckpoint.globalCheckpoint < globalCheckpointToPersist)
&& syncNeeded()) {
//双重检查锁定 - 除非我们必须这样做,否则我们不想 fsync,现在我们有了锁,我们应该再次检查,因为如果这个代码很忙,我们可能已经足够 fsync 了
final Checkpoint checkpointToSync;
final List<Long> flushedSequenceNumbers;
final ReleasableBytesReference toWrite;
//再获取一个写锁
try (ReleasableLock toClose = writeLock.acquire()) {
synchronized (this) {
ensureOpen();
checkpointToSync = getCheckpoint();
//获取最新的写入数据buffer。
toWrite = pollOpsToWrite();
//如果没有未同步的序列号,则设置flushedSequenceNumbers为null;
if (nonFsyncedSequenceNumbers.isEmpty()) {
flushedSequenceNumbers = null;
} else {
//否则,将nonFsyncedSequenceNumbers赋值给flushedSequenceNumbers
flushedSequenceNumbers = nonFsyncedSequenceNumbers;
//nonFsyncedSequenceNumbers重新初始化为一个空的列表
nonFsyncedSequenceNumbers = new ArrayList<>(64);
}
}
try {
//写入管道操作,下面channel.force会强制刷盘
writeAndReleaseOps(toWrite);
assert channel.position() == checkpointToSync.offset;
} catch (final Exception ex) {
closeWithTragicEvent(ex);
throw ex;
}
}
//现在在同步块之外执行实际的 fsync,以便我们可以继续写入缓冲区等。
try {
assert lastSyncedCheckpoint.offset != checkpointToSync.offset || toWrite.length() == 0;
if (lastSyncedCheckpoint.offset != checkpointToSync.offset) {
//则调用channel.force(false)方法来强制刷新通道的数据到磁盘。
channel.force(false);
}
//更新检查点
//将checkpointToSync写入到指定的checkpointChannel和checkpointPath中
Checkpoint.write(checkpointChannel, checkpointPath, checkpointToSync);
} catch (final Exception ex) {
closeWithTragicEvent(ex);
throw ex;
}
if (flushedSequenceNumbers != null) {
//则遍历flushedSequenceNumbers列表,并对每个元素调用persistedSequenceNumberConsumer::accept方法处理。
flushedSequenceNumbers.forEach(persistedSequenceNumberConsumer::accept);
}
assert lastSyncedCheckpoint.offset <= checkpointToSync.offset
: "illegal state: " + lastSyncedCheckpoint.offset + " <= " + checkpointToSync.offset;
lastSyncedCheckpoint = checkpointToSync; // write protected by syncLock
return true;
}
}
}
return false;
}
其中 toWrite = pollOpsToWrite(); 就是下面这个,至于buffer是什么?
可以看一下Elasticsearch 8.9 Bulk批量给索引增加数据源码 中的 public Translog.Location add(final BytesReference data, final long seqNo)方法体中会把给this.buffer赋值
private synchronized ReleasableBytesReference pollOpsToWrite() {
ensureOpen();
if (this.buffer != null) {
//则将 buffer 赋值给 toWrite 变量,并将 buffer 置为 null,同时将 bufferedBytes 置为 0。
ReleasableBytesStreamOutput toWrite = this.buffer;
this.buffer = null;
this.bufferedBytes = 0;
//创建一个新的 ReleasableBytesReference 对象,该对象的字节为 toWrite.bytes(),并将 toWrite 作为释放引用
return new ReleasableBytesReference(toWrite.bytes(), toWrite);
} else {
//返回一个空的 ReleasableBytesReference 对象
return ReleasableBytesReference.empty();
}
}
下面就是正常的把数据写入到writeToFile
//将给定的 ReleasableBytesReference 对象写入到文件中,上面有channel.force会强制把Channels刷盘
private void writeAndReleaseOps(ReleasableBytesReference toWrite) throws IOException {
try (ReleasableBytesReference toClose = toWrite) {
assert writeLock.isHeldByCurrentThread();
final int length = toWrite.length();
//检查 toWrite 的长度是否为0,如果是,则直接返回
if (length == 0) {
return;
}
//试从 diskIoBufferPool 中获取一个 ioBuffer,用于写入操作。
ByteBuffer ioBuffer = diskIoBufferPool.maybeGetDirectIOBuffer();
//如果获取不到 ioBuffer,则说明当前线程不使用直接缓冲区,代码会直接将数据写入到文件中,而不是先复制到 ioBuffer 中。
if (ioBuffer == null) {
// not using a direct buffer for writes from the current thread so just write without copying to the io buffer
BytesRefIterator iterator = toWrite.iterator();
BytesRef current;
while ((current = iterator.next()) != null) {
Channels.writeToChannel(current.bytes, current.offset, current.length, channel);
}
return;
}
//如果成功获取到 ioBuffer,代码会使用迭代器遍历 toWrite 中的数据,并将数据逐个写入到 ioBuffer 中。
BytesRefIterator iterator = toWrite.iterator();
BytesRef current;
while ((current = iterator.next()) != null) {
int currentBytesConsumed = 0;
while (currentBytesConsumed != current.length) {
int nBytesToWrite = Math.min(current.length - currentBytesConsumed, ioBuffer.remaining());
ioBuffer.put(current.bytes, current.offset + currentBytesConsumed, nBytesToWrite);
currentBytesConsumed += nBytesToWrite;
//如果 ioBuffer 的空间已满,
if (ioBuffer.hasRemaining() == false) {
//则将 ioBuffer 翻转(从写模式切换到读模式)
ioBuffer.flip();
//然后调用 writeToFile 方法将数据写入到文件中,
writeToFile(ioBuffer);
//并清空 ioBuffer。
ioBuffer.clear();
}
}
}
//再次翻转 ioBuffer
ioBuffer.flip();
//并调用 writeToFile 方法将剩余的数据写入到文件中。
writeToFile(ioBuffer);
}
}
(2) 删除磁盘中的对应的translog文件
/**
* 删除与读取器关联的所有文件。package-private,以便此时能够模拟节点故障
*/
void deleteReaderFiles(TranslogReader reader) {
IOUtils.deleteFilesIgnoringExceptions(
reader.path(),
reader.path().resolveSibling(getCommitCheckpointFileName(reader.getGeneration()))
);
}
/** 删除所有给定的文件,禁止所有抛出的 {@link IOException}。某些文件可能为 null,如果是这样,则忽略它们。
*
* @param files the paths of files to delete
*/
public static void deleteFilesIgnoringExceptions(final Path... files) {
for (final Path name : files) {
if (name != null) {
// noinspection EmptyCatchBlock
try {
Files.delete(name);
} catch (final IOException ignored) {
}
}
}
}
5、更新最后刷新时间和刷新最后提交的段信息
//刷新最后提交的段信息(refreshLastCommittedSegmentInfos()
refreshLastCommittedSegmentInfos();
//获取刷新后的段信息
generation = lastCommittedSegmentInfos.getGeneration();
//调用刷新监听器的 afterFlush 方法
flushListener.afterFlush(generation, commitLocation);
private void refreshLastCommittedSegmentInfos() {
/*
* 在某些情况下,如果引擎由于意外事件关闭,我们无法获取写锁并等待独占访问。
* 这可能会减少对存储的引用计数,从而关闭存储。为了保证能够使用存储,我们需要增加引用计数
*/
store.incRef();
try {
//读取存储中的最后提交的段信息,并将结果赋给lastCommittedSegmentInfos变量。
lastCommittedSegmentInfos = store.readLastCommittedSegmentsInfo();
} catch (Exception e) {
//读取过程中发生异常,代码会检查引擎是否已关闭。如果引擎未关闭,则记录一个警告日志,并检查异常是否是Lucene的损坏异常。
// 如果是损坏异常,代码会抛出FlushFailedEngineException异常
if (isClosed.get() == false) {
logger.warn("failed to read latest segment infos on flush", e);
if (Lucene.isCorruptionException(e)) {
throw new FlushFailedEngineException(shardId, e);
}
}
} finally {
//代码会减少对存储的引用计数,以确保引用计数的正确性和资源释放。
store.decRef();
}
}
三、通过源码得到一些结论
1、translog也会刷进磁盘,不只是在内存中存在,异步方式会定时刷translog到磁盘
2、等segment刷进磁盘后,会把对应translog.log磁盘文件删除,所以translog说是临时文件,没有问题,
3、translog的删除方式是先刷到磁盘,直接通过删除文件的方式删除translog