redis数据类型
1、String字符串
1.1、简介
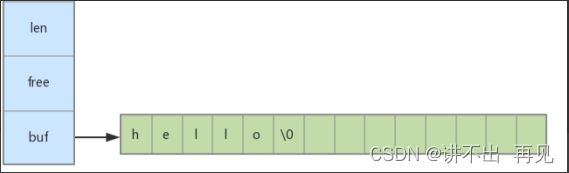
字符串类型是最常用的,底层结构是一个动态字符串,包含3个核心组件:
第一个,字符数组用于存储字符串,最大不能超过512M;
第二个,已使用长度,表示字符串真实占用了字符数组的长度;
第三个,剩余长度,表示字符数组未被使用的长度。
字符数组的长度是动态变化的,当需要扩容时,如果字符串长度小于1M,则会加倍扩大字符数组长度,直到能存下,如果字符串长度超过1M,则会以1M的大小进行扩容,直到能存下。
而缩容是不会主动触发的,只有当key被删除了,字符数组的空间才会被收回,或者当redis重启时,才会将字符数组的长度初始化成实际字符串的长度。
struct sdshdr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度
int free;
// 数据空间
char buf[];
}; 
感悟:
第一,给key设置合理的过期时间,使得redis能够有机会优化内部的存储占用;
第二,即便字符串的最大存储长度有512M,但是要避免长数据的存储,以免造成大value问题;
第三,尽量规范业务数据,使得数据之间的长度差距不要太大,避免频繁的扩容,或者浪费剩余空间;
1.2、常用命令
APPEND key value // 将 value 追加到 key 的值后。
SET key value [EX seconds] [PX milliseconds] [NX | XX] // 设置
GET key // 返回 key 的 value。
STRLEN key // 返回 key 对应的字符串长度。
SETRANGE key offset value // 用 value 参数覆写(overwrite)给定 key 所储存的字符串值,从偏移量 offset 开始。如果 offset 超出了范围,则原字符串和 offset 之间的空白将由 "\x00" 填充。
SETBIT key offset value // (以 ascll 码为准)将字符串的 offset 位设置为 value,偏移量从 0 开始,value 只能是 1 或者 0。
GETBIT key offset // 返回字符串的 offset 位上的比特值。
MSETNX key value key1 value1 .... // 当所有的 key 都不存在时,才会执行指令。
MSET key value key1 value1 ... // 设置多个
MGET key key2 ... // 获取多个 key 的 value,如果 key 不存在,则 value 为空。
INCRBYFLOAT key increment // 给 key 的 value 值加上浮点数 increment,increment 既可以是浮点数,也可以是整数,最多只能表示小数点的后十七位。
INCRBY key increment // 给 key 的 value 值加上 increment,increment 只能是整数。
INCR key // 自增1。
GETSET key value // 设置 key 的值为 value, 并且返回 key 的旧值。
GETRANGE key start stop // 返回 key 的值的 [start,stop] 区间的子串。
DECRBY key decrement // 将 key 的 value 值减去 decrement, decrement 只能是整数。
DECR key // 自减 1 。
BITCOUNT key [start] [end] // 统计 key 的 value 值里有多少个为 1 的比特位。
BITOP operation destkey key [key ...] // 对若干个 key 的 value 值进行按位逻辑运算,有 AND 、 OR 、 NOT 、 XOR。
2、Hash 哈希
2.1、简介
Hash数据类型是指 key-value 对的 value 存储的也是一个一个 key-value 对,这种特性适合存储对象,最多存储2^32-1个。
2.2、压缩列表
当对象中的所有键值的长度小于64字节(这个阈值可以通过参数hash-max-ziplist-value 来进行控制), 对象中的键值对数量小于512个(这个阈值可以通过参数hash-max-ziplist-entries 来进行控制)时,底层用 zipList (压缩列表)结构进行存储,如下图所示。
zlbytes:表示占用总字节数;
zltail:表示尾结点举例起始地址的偏移量;
zllen:entry的数量,即对象的键值对数量;
entry:表示存储的对象的键值对,也分为 key,value;
zlend:尾结点 oxFF,表示压缩列表的结束;
压缩列表结构的优点:存储很紧凑,节省空间; 缺点:只适合存储体积小,量小的哈希对象,因为它对 entry 的查询是线性的,时间复杂度为 O(n)。

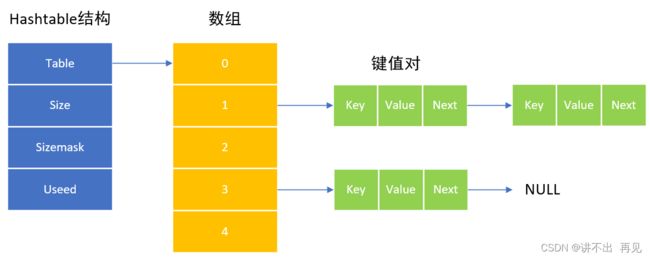
2.3、哈希表
当对象中的所有键值的长度不小于64字节,或者键值对数量不小于512个时,底层用 hashtable 结构存储,如下图所示。
table:哈希数组;
size:数组长度;
sizemask:掩码,其和键的哈希值一起被使用,用来计算键应该存储在table数组的哪个位置上,等于 size - 1;
used:已经存储了多少个键值对;
优点:时间复杂度为 O(1); 缺点:空间使用率低,且扩容机制比较复杂且耗时;
扩容、缩容机制:
负载因子 = used / size;
当服务器目前没有执行BGSAVE或BGREWRITEAOF命令,并且负载因子大于等于1。 或者,当服务器正在执行BGSAVE或BGREWRITEAOF命令,并且负载因子大于等于5。 此时触发扩容;
当负载因子小于0.1时,触发缩容;
扩容是新创建一个数组,长度是原数组长度的2倍,然后将原哈希表里的数据重新哈希计算,然后存储到新的数组中,形成新的哈希表。
缩容是创建一个新数组,长度是原数组的一半,也是将原数据都重哈希存入新哈希表。
重哈希过程,是一个渐进式rehash的过程,当数据量小时,rehash瞬间就完成了,但是当数据量很大时,rehash的执行时间会很久,容易卡顿redis服务,所以redis 采用了渐进式 rehash 方法,在执行其它命令时,顺带完成一条数据的迁移,就这样一点一点地将原数据迁移到新哈希表里,在迁移过程中,如果有新的数据要存入此哈希对象中,那么就存入新哈希表里,如果有查询数据的,就先查询原哈希表,如果没有找到,再查询新哈希表。
思考:为什么扩容的时候要考虑BGSAVE或BGREWRITEAOF命令呢?
个人答案:BGSAVE和BGREWRITEAOF命令会fork出一个子进程, 将redis数据分别以RDB方式、AOF方式持久化到磁盘,关键就在子进程,为了尽快创建出子进程,操作系统一般会让子进程共享父进程的一些内存空间(不用为子进程创建和初始化一份独立的内存空间了), 但是只以读的方式共享,如果父进程要对某一页内存进行写操作时,操作系统会为子进程完全复制出一页该页内存内容,这就增加了额外的工作了,消耗系统资源和时间,因此,执行BGSAVE或BGREWRITEAOF命令过程中,要尽量减少父进程的写操作,提高扩容的触发条件(负载因子)。
感悟:
第一,当数据量少时,可以考虑使用哈希类型存储,因为数据量非常大时,存在大value问题,且hashtable对内存的使用率不高;
第二,数据量略微大时,且使用了hash结构存储,要考虑这个数据量是否变化差异很大,一会儿剩很少,一会儿增到很多,避免频繁地切换底层存储结构(压缩列表,hashtable),避免频繁的扩容、缩容。
第三,数据量大时,底层使用了hashtable结构,当负载因子非常接近1时,或者在 BGSAVE或BGREWRITEAOF命令期间,非常接近5时,极容易出现较多哈希冲突,形成较多链表,那读性能就会退化。
2.4、常用命令
HSET key field value //设置哈希对象中的 field 字段值为 value,如果字段 filed 不存在,则就添加,如果字段 field 存在,则更新
HGET key field //获取哈希对象中的 field 字段值,没有该字段,则返回空。
HMSET key field1 value1 field2 value2 .... //一次设置多个<字段名, 字段值>。
HMGET key field1 field2 ... // 一次获取多个字段的值。
HGETALL key //获取这个哈希对象的所有<字段名, 字段值>。
HEXISTS key field //判断哈希对象的该字段是否存在,如果存在,返回1,否则其它情况一律返回0。
HDEL key field1 field2 .... // 删除哈希对象的相关<字段名, 字段值>。
HINCRBY key field increment //为哈希表 key 中的域 field 的值加上增量 increment 。增量也可以为负数,相当于对给定域进行减法操作。如果 key 不存在,一个新的哈希表被创建并执行 HINCRBY命令。如果域 field 不存在,那么在执行命令前,域的值被初始化为 0 。对一个储存字符串值的域 field 执行 HINCRBY 命令将造成一个错误。
HINCRBYFLOAT key field increment //为哈希表 key 中的域 field 的值加上浮点数增量 increment 。
HKEYS key //获取这个哈希对象的所有字段名 field。
HLEN key //获取这个哈希对象的所有字段数量。
HSETNX key field value //若 field 已经存在,则什么都不做,如果不存在,则添加<字段,字段值>。
HVALS key //获取这个哈希对象的所有字段的值。
HSCAN key cursor [MATCH pattern] [COUNT count] //遍历哈希对象的字段,可以设置从什么位置开始遍历,设置正则匹配,每次遍历的元素个数。和 SCAN 命令是一个意思,只是 HSCAN 命令只是针对一个哈希对象遍历的。
3、List 列表
3.1、简介
List列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边) 一个列表最多可以包含 2^32 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
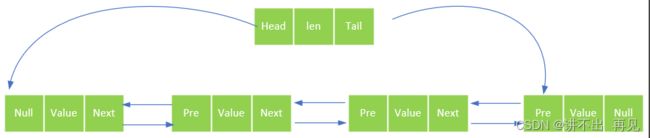
当存入列表的任意一个字符串长度都小于 list_max_ziplist_value (默认值为 64 ),并且列表包含的数据量小于 list_max_ziplist_entries (默认值为 512 )时,列表底层使用压缩列表存储。否则使用双向链表存储,如下图所示。
有一个特殊节点,记录了链表头,链表尾,和链表长度;
其它都是普通链表节点,记录了上一个节点指针,下一个节点指针,和数据值。
优点:可以保持数据的顺序性;
缺点:只适应于队列场景,因为从列表头或者列表尾读写数据的时间复杂度为O(1),但是越往列表中走,时间复杂度越大,所以不适合对列表中的数据进行随机读写。
感悟:列表也不能存在太多的数据,避免大value问题。
3.2、常用命令
提前说明:关于列表的操作,如果涉及指定下标索引值的参数,非负数表示从左边开始数,负数表示从右边开始数。
LPUSH key val0 val1 val2 .... //如果列表key没有,就会自动创建,从列表的左边依次加入列表
RPUSH key val0 val1 val2 .... //从列表右边依次加入列表
LPUSHX key value //向左边列表头插入一个元素,仅仅只能一个元素,如果列表不存在,则什么都不做,返回0,否则插入元素
RPUSHX key value //向右边列表头插入一个元素
LPOP key //获取列表最左边的头元素并将其移除列表
RPOP key //获取列表最右边的头元素并将其移除列表
LLEN key //查看列表的长度
LRANGE key start stop //获取列表中 [start, stop] 区间的元素,闭区间。 列表从左边数,下标以0开始,从右边数,下标以 -1 开始,正数代表从左边数,负数代表从右边数,比如 0 代表左边第一个元素, -1代表右边第一个元素。
1、如果 start 和 stop 都是非负数。
如果 start <= stop ,则从左边数,获取[start, stop] 区间的元素。
如果 start > stop,则返回空。
2、如果 start 和 stop 都是负数。
如果 start <= stop,则从右边数,获取区间元素,比如 LRANGE key -1 -2 表示获取从右边数的第一个和第二个元素。
如果 start > stop, 则返回空。
3、如果 start 和 stop 一正一负。
则看start 的实际位置是否在 stop 的实际位置之前,如果是则返回区间元素, 如果不是,返回空。
LREM key count value //表示删除列表前 count 个元素中值为 value 的元素。
1、count > 0 表示从左边数,
2、count < 0 表示从右边数,
3、count = 0 表示列表的全部元素。
BLPOP key1 key2 ... timeout //阻塞获取第一个不为空的列表的最左元素,并将该元素移除,如果全为空,则阻塞,直到某个列表有新元素加入,或者直到 timeout 超时时间结束。
1、timeout = 0 时,表示无限阻塞下去,除非某个列表不为空。
2、timeout > 0 时,表示超时时间也可以解除阻塞状态,并返回空给客户端。
BRPOP key1 key2 ... timeout //阻塞获取第一个不为空的列表的最右元素,和 BLPOP 功能类似。
BRPOPLPUSH sourcekey destinationkey timeout // 阻塞获取 sourcekey 列表的最右边的元素,timeout 为超时时间,如果能够在超时时间内获取到元素,则将该元素返回给客户端,并将其添加到 destinationkey 列表的最左边,如果从 sourcekey 列表中获取不到元素,则返回给客户端空,并且不做任何其它操作。
RPOPLPUSH sourcekey destinationkey //非阻塞方式获取 sourcekey 列表的最右边的元素,将该元素返回给客户端,并将其添加到 destinationkey 列表的最左边,如果从 sourcekey 列表中获取不到元素,则返回给客户端空,并且不做任何其它操作。
LINDEX key index //获取下标为 index 的元素。如果 index 超出范围,则返回空,如果 index 为非负数,则从左边数,否则从右边数。
LINSERT key BEFORE|AFTER pivot value // 将 value 插入 pivot 之前或者之后,如果 key 为空或者不存在,则什么都不做,返回0,如果 key 存在且不为空,pivot 存在,则返回插入后列表长度,如果 pivot 不存在,则什么都不做,返回 -1。
LSET key index value //将列表的 index 位置处设置为 value 值,成功返回OK,如果 index 超出范围或者列表不存在,则返回错误信息。
LTRIM key start stop // 将列表的 [start, stop] 区间保留下来,其它的元素删除,成功返回ok。
4、Set 集合
4.1、简介
Set 是一个无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,最大可以存储2^32-1个数据。 底层存储结构可是 intset 或者 hashtable。
当集合中所有元素都是整数类型时,且元素数量小于512个时,使用intset结构存储。
否则,使用hashtable结构存储,集合的元素是 hashtable 中的 key,value = null。
4.2、intset 结构
intset 是一个升序的整数数组,包含3个核心组件:
1、contents:int 数组,用于存储集合的数据;
2、length:集合中实际包含的数据量;
3、encoding:编码格式,有三种,INSET_ENC_INT16(用16位存储整数)、INSET_ENC_INT32(用32位存储整数)、INSET_ENC_INT64(用64位存储整数);
至于使用哪种编码格式,取决于集合中最大整数所需要的位数,当有新的更长的元素加入数组时,数组会自动进行位数升级,比如数组从16位整数升级为32位整数,但是只能升级,升级之后就不能降级了。
编码格式的升级就意味着要重新创建数据,并将原数组的数据迁移到新数据中。
当查询集合中的元素时,使用的是二分查找,当插入数据时,也是先查看数据是否存在,如果不存在,则找到合适的插入位置,再插入;
优点:实现了Set数据类型的唯一性,存储还算紧凑,设计简单。
缺点:读时间复杂度为O(log N),写数据时,容易引起编码格式的升级,且在数组中插入数据,容易导致大量数据往后挪移。
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;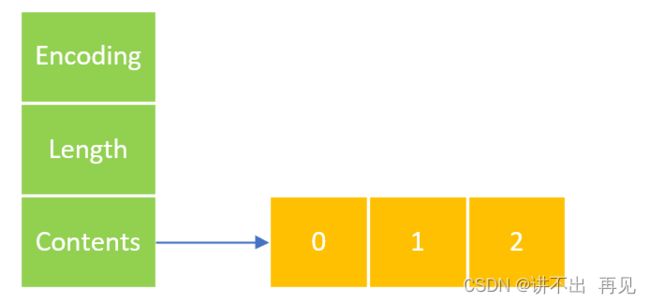
4.3、常用命令
SADD key value1 value2 ... // 向集合中添加若干个元素,如果元素已经存在,则忽略,返回实际添加成功的元素个数。
SREM key value1 value2 .... // 删除集合中的元素,如果元素不存在,则忽略,返回实际删除成功的元素个数。
SCARD key //返回集合中的元素个数。
SDIFF key 或者 SDIFF key1 key2 ... // 如果只有一个聚合,就返回集合中的全部元素,如果是多个集合,那就是返回第一个集合中与其它所有集合都不同的元素(即 第一个集合与所有集合的差集)。
SDIFFSTORE destination key key2 ... // 作用和 SDIFF 一样,只是将差集存储到 destination 集合中去。
SINTER key1 key2 ... // 返回这些集合的交集,如果其中有空集(不存在的集合被视为空集),那么结果也为空集。
SINTERSTORE destination key key2 .. //将集合的交集存到 destination 集合中。
SISMENBER key value //判断 value 是否是集合的元素,是,返回1,不是,返回-1。
SMEMBERS key // 返回集合中的所有元素。
SMOVE source destination member // 将集合的一个元素移到另一个集合中去。
SPOP key // 从集合中返回一个随机元素,并从集合中移除。
SRANDMEMBER key // 从集合中返回一个随机元素,不从集合中移除。
SREM member1 member2 ... // 删除集合中的若干个元素。
SUNION key1 key2 ... // 返回若干个集合的并集。
SUNIONSTORE destination key1 key2 ... // 将若干个集合的并集存入另一个集合 destination。
SSCAN key cursor [MATCH pattern] [COUNT count] // 扫描,和scan一样,只是扫描的对象是集合而已。
5、Zset 有序集合
5.1、简介
Zset 是一个有序集合,类似于 set,每个元素都是唯一的,不同的是,Zset的元素都有一个分值,且所有元素都是按照分值进行升序排序的。
当Zset包含的元素个数小于zset-max-ziplist-entries (默认为128),且所有元素的长度都小于 zset-max-ziplist-value (默认为64字节)时,底层使用压缩列表结构存储,否则,使用 hashtable + 跳表 形式进行存储。
hashtable 和 跳表只是使用了同一份集合元素的指针,并不是两份数据。
hashtable 存在的目的是使得查询集合中某个元素的时间复杂度为 O(1),并且保证 Zset 中元素的唯一性。
跳表存在的目的是为了保持 Zset 的有序性,且让元素的插入、删除、修改的时间复杂度平均在 O(log N)。
5.2、跳表结构
typedf struct zskiplist{
struct zskiplistNode *header; //头节点
struct zskiplistNode *tail; //尾节点
unsigned long length; // 跳表中元素个数
int level; //目前表内节点的最大层数
} zskiplist;
typedf struct zskiplistNode{
sds ele; // 具体的数据
double score; // 分数
struct zskiplistNode *backward; //指向前一个节点,用于倒序遍历
struct zskiplistLevel{
struct zskiplistNode *forward; //指向下一个节点
unsigned int span; // 第几层
}level[]; //层级数组
}zskiplistNode; 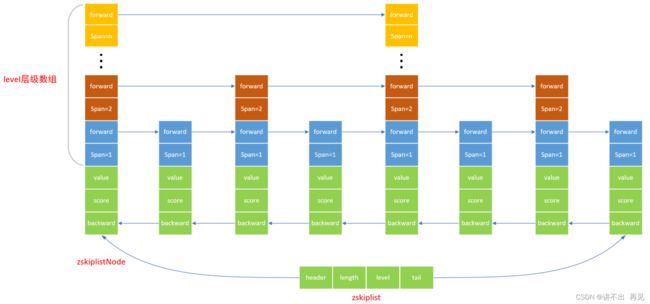
5.2.1、跳表查询
当查询数据时,从上往下找,比如查询 Zset 中是否包含 14,先从第二层开始找,发现 14 介于 9 和 59 之间,于是从第二层的 9 往下走,到达第一层的 9,继续找,发现 14 就等于第一层 9 的后一个节点,于是得出结论,Zset 包含 14,查询路线如图中红色箭头所示。

5.2.2、跳表插入
往跳表里插入一个数据时,比如在上图例子中,插入一个 5 ,只需在第一层中插入即可,插入一个 9,需要在第一层和第二层都插入,那怎么决定一个数据应该插入几层呢,并且插入在什么位置呢?
决定插入层的方式:抛硬币,如果是正面,就继续抛,直到出现背面,那么正面出现的次数就是层数;
插入在什么位置:按照跳表查询的方式,确定插入的位置;
举个例子,如下图所示:
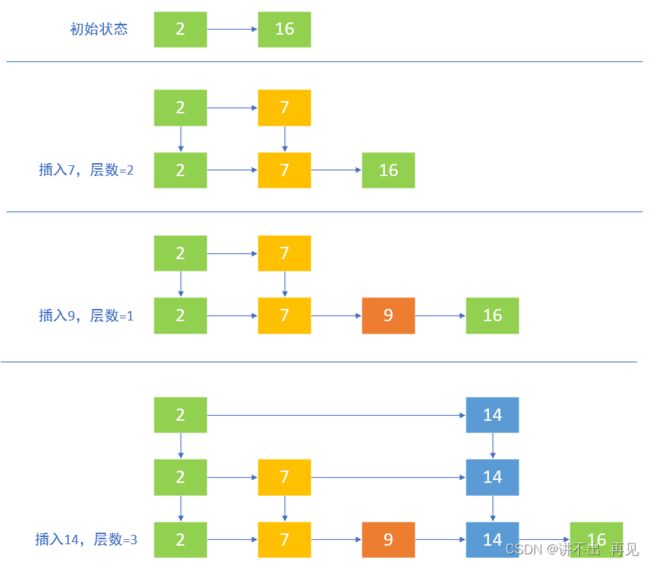
5.2.3、跳表删除
当跳表删除一个数据时,先找到数据的位置,再将该数据在每一层节点都删除了,举个例子,如下图所示:
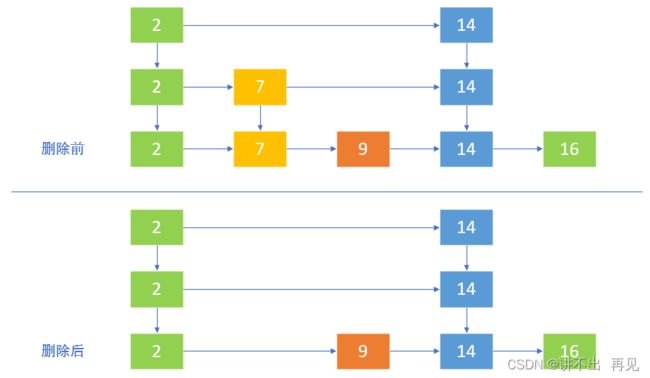
5.2.4、跳表修改
修改跳表中的某一个数据时,先找到数据的位置,如果修改数据后,不会影响 Zset 的有序性,则直接修改,否则,将该数据先进行删除,再进行添加。
5.3、常用命令
ZADD key score member score1 member1 score2 member2 ... //添加若干个元素,每个元素都有分值。
ZCARD key //返回集合的元素个数。
ZCOUNT key min max // 返回集合中分值在 [min, max] 区间的元素个数。
ZINCRBY key increment member //在集合里的元素 member 的分值上加 increment 。
ZRANGE key start stop [WITHSCORES] // 返回集合中下标 [start, stop] 区间的元素(不包含分值),如果带上 WITHSCORES 参数就会将分值一起返回。
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] //返回分值在 [min, max] 区间的元素,WITHSCORES 参数就会将分值一起返回,LIMIT offset count 的意思是在 [min, max] 区间的元素里面,从第 offset 个元素开始,只获取 count 个元素,然后返回这 count 个元素。
ZRANK key member // 查看元素 member 在集合中按分值排名第几,0表示第一。
ZREM key member [member ...] // 删除集合中的指定元素。
ZREMRANGEBYRANK key start stop // 删除集合中按分值排名在 [start, stop] 区间的元素。
ZREMRANGEBYSCORE key min max // 删除集合中分值在 [min, max] 区间的元素。
ZREVRANGE key start stop [WITHSCORES] // 返回集合中排名在 [start, stop] 区间的元素的逆序列。
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] //返回集合中分值在 [min, max] 区间的元素的逆序列。
ZREVRANK key member // 返回 member 在集合中按照分值逆序排名中的名次,0 表示倒数第一。
ZSCORE key member //返回集合中member元素的分值
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] //将 numkeys 数量的有序集合做并集,并且将并集存入集合 destination 中, WEIGHTS 参数是可选的,表示每个集合对应的乘法因子,每个集合的每个元素的分值都要乘上对应的 weight ,默认 weight 为 1 , AGGREGATE 也是可选的,指定聚合方式,默认是 SUM 方式,表示元素的并集,分值相加, MIN 表示取分值最小的, MAX 表示取分值最大的。
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] // 交集,和 ZUNIONSTORE 指令类似。
ZSCAN key cursor [MATCH pattern] [COUNT count] // 扫描,和 scan 一样,针对的目标是有序集合。