Spark Structured Streaming使用教程
文章目录
-
- 1、输入数据源
- 2、输出模式
- 3、sink输出结果
- 4、时间窗口
-
- 4.1、时间窗口
- 4.2、时间水印(Watermarking)
- 5、使用例子
Structured Streaming是一个基于Spark SQL引擎的可扩展和容错流处理引擎,Spark SQL引擎将负责增量和连续地运行它,并在流数据继续到达时更新最终结果。
Structured Streaming把持续不断的流式数据当做一个不断追加的表,这使得新的流处理模型与批处理模型非常相似。您将把流计算表示为在静态表上的标准批处理查询,Spark将其作为无界输入表上的增量查询运行。
1、输入数据源
- File source - 以数据流的形式读取写入目录中的文件。文件将按照文件修改时间的先后顺序进行处理。如果设置了latestFirst,则顺序将相反。支持的文件格式为text, CSV, JSON, ORC, Parquet。请参阅DataStreamReader接口的文档,了解最新的列表,以及每种文件格式支持的选项。注意,监视目录的文件改变,只能是原子性的改变,比如把文件放入该目录,而不是持续写入该目录中的某个文件。
- Kafka source - 从Kafka读取数据。它兼容Kafka代理版本0.10.0或更高版本。查看Kafka集成指南了解更多细节。
- Socket source (用于测试) - 从套接字连接读取UTF8文本数据。监听服务器套接字位于驱动程序。请注意,这应该仅用于测试,因为它不提供端到端的容错保证。
- Rate source (用于测试) - 以每秒指定的行数生成数据,每个输出行包含一个时间戳和值。其中timestamp为包含消息发送时间的timestamp类型,value为包含消息计数的Long类型,从0开始作为第一行。该源代码用于测试和基准测试。
2、输出模式
- 我们可以定义每次结果表中的数据更新时,以何种方式,将哪些数据写入外部存储。有3种模式:
- complete mode:所有数据都会被写入外部存储。具体如何写入,是根据不同的外部存储自身来决定的。
- append mode:只有新的数据,以追加的方式写入外部存储。只有当我们确定,result table中已有的数据是肯定不会被改变时,才应该使用append mode。
- update mode:只有被更新的数据,包括增加的和修改的,会被写入外部存储中。
aggDF
.writeStream()
.outputMode("complete")
.format("console")
.start();
3、sink输出结果
- File sink - 将输出存储到一个目录。
输出模式支持Append
writeStream
.format("parquet") // can be "orc", "json", "csv", etc.
.option("path", "path/to/destination/dir")
.start()
- Kafka sink - 将输出存储到Kafka中的一个或多个主题。
输出模式支持Append, Update, Complete
writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "updates")
.start()
- Console sink (用于测试) - 每次有触发器时,将输出打印到控制台/标准输出。支持两种输出模式:Append和Complete。这应该用于在低数据量上进行调试,因为在每次触发后都会收集整个输出并将其存储在驱动程序的内存中。
输出模式支持Append, Update, Complete
writeStream
.format("console")
.start()
- Memory sink (用于测试) - 输出以内存表的形式存储在内存中。支持两种输出模式:Append和Complete。这应该用于低数据量的调试目的,因为整个输出被收集并存储在驱动程序的内存中。因此,请谨慎使用。
输出模式支持Append, Complete
输出以内存表的形式存储在内存中。支持两种输出模式:Append和Complete。这应该用于低数据量的调试目的,因为整个输出被收集并存储在驱动程序的内存中。因此,请谨慎使用。
- 自定义输出Foreach和ForeachBatch - Foreach:针对每条数据的输出;ForeachBatch:针对每批次的数据输出。
输出模式支持Append, Update, Complete
// Foreach
streamingDatasetOfString.writeStream().foreach(
new ForeachWriter() {
@Override public boolean open(long partitionId, long version) {
// Open connection
}
@Override public void process(String record) {
// Write string to connection
}
@Override public void close(Throwable errorOrNull) {
// Close the connection
}
}
).start();
// ForeachBatch
streamingDatasetOfString.writeStream().foreachBatch(
new VoidFunction2, Long>() {
public void call(Dataset dataset, Long batchId) {
// Transform and write batchDF
}
}
).start();
4、时间窗口
4.1、时间窗口
在业务场景中,经常会遇到按时间段进行聚合操作,Spark提供了基于滑动窗口的事件时间集合操作,每个时间段作为一个分组,并对每个组内的每行数据进行聚合操作。
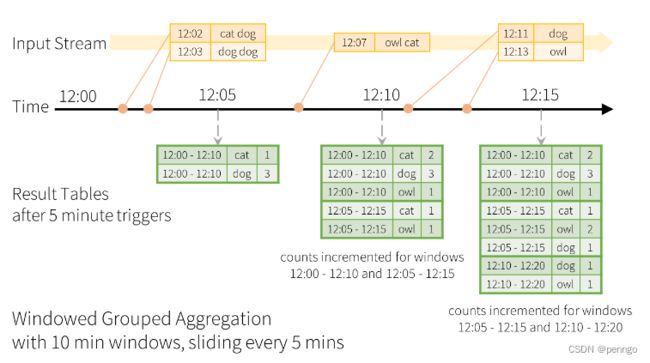
可以使用groupBy()和window()操作来表示窗口聚合。
Dataset words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
Dataset windowedCounts = words.groupBy(
functions.window(words.col("timestamp"), "10 minutes", "5 minutes"),
words.col("word")
).count();
4.2、时间水印(Watermarking)
WaterMarking的作用主要是为了解决:延迟到达的数据是否丢弃,系统可以删除过期的数据。
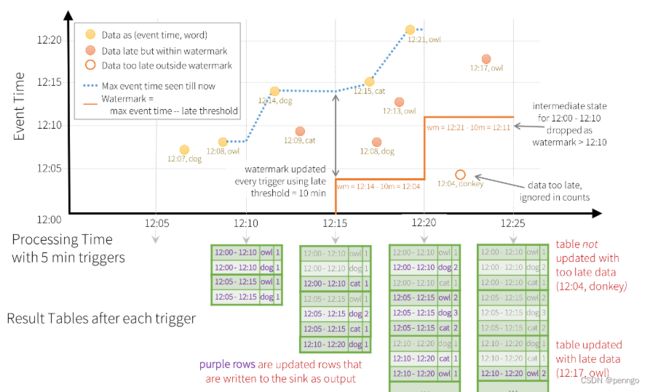
Dataset words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
Dataset windowedCounts = words
.withWatermark("timestamp", "10 minutes") // 延迟10分钟后到达的数据将会被丢弃
.groupBy(
window(col("timestamp"), "10 minutes", "5 minutes"),
col("word"))
.count();
5、使用例子
package com.penngo.spark;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.*;
import org.apache.spark.sql.streaming.StreamingQuery;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import org.roaringbitmap.art.Art;
import java.io.Serializable;
import java.sql.Timestamp;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import static org.apache.spark.sql.functions.col;
import static org.apache.spark.sql.functions.window;
public class SparkStructStream {
private static final DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
public static class DataTxt implements Serializable {
private String text;
private Timestamp time;
public DataTxt(String text, LocalDateTime time) {
this.text = text;
this.time = Timestamp.valueOf(time);
}
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
public Timestamp getTime() {
return time;
}
public void setTime(Timestamp time) {
this.time = time;
}
}
public static void socket(SparkSession spark) throws Exception{
// 运行:nc -lk 9999
Dataset<Row> lines = spark
.readStream()
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load();
Dataset<DataTxt> words = lines
.as(Encoders.STRING())
.map((MapFunction<String, DataTxt>) x -> {
String[] strs = x.split(",");
LocalDateTime date = LocalDateTime.parse(strs[1],formatter);
Arrays.asList(x.split(",")).iterator();
DataTxt data = new DataTxt(strs[0], date);
return data;
}, Encoders.bean(DataTxt.class));
Dataset<Row> wordCounts = words.toDF()
.withWatermark("time", "10 minutes") // 延迟10分钟后到达的数据将会被丢弃
.groupBy(
window(col("time"), "10 minutes", "5 minutes"),
col("text"))
.count();
wordCounts.writeStream().outputMode("append")
.foreach(new ForeachWriter<Row>() {
@Override public boolean open(long partitionId, long version) {
// System.out.println("open==========partitionId:" + partitionId + ",version:" + version);
return true;
}
@Override public void process(Row record) {
// Write string to connection
System.out.println("recordxxxxxxxxxxxxxxxxxx:======" + record);
}
@Override public void close(Throwable errorOrNull) {
// Close the connection
// System.out.println("close==========errorOrNull:" + errorOrNull);
}
})
// .format("console")
.start().awaitTermination();
}
public static void kafka(SparkSession spark) throws Exception{
// Subscribe to 1 topic
Dataset<Row> df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "192.168.245.1:9092")
.option("subscribe", "topic-news")
.option("startingOffsets","latest")
.option("maxOffsetsPerTrigger",1000)
.load();
df = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)");
df.printSchema();
df.writeStream().outputMode("append")
.format("console")
.start().awaitTermination();
}
public static void main(String[] args) throws Exception{
Logger.getLogger("org.apache.spark").setLevel(Level.WARN);
Logger.getLogger("org.apache.eclipse.jetty.server").setLevel(Level.OFF);
Logger.getLogger("org.apache.kafka").setLevel(Level.WARN);
System.setProperty("hadoop.home.dir", "/usr/local/hadoop-3.3.6");
System.setProperty("HADOOP_USER_NAME", "root");
SparkSession spark = SparkSession
.builder()
.appName("SparkStructStream")
.master("local[*]")
.getOrCreate();
// socket(spark);
kafka(spark);
}
}
参考自官方文档:https://spark.apache.org/docs/3.1.2/structured-streaming-programming-guide.html